# PythonProgramming.net Python 金融教程
## 一、入門和獲取股票數據
您好,歡迎來到 Python 金融系列教程。在本系列中,我們將使用 Pandas 框架來介紹將金融(股票)數據導入 Python 的基礎知識。從這里開始,我們將操縱數據,試圖搞出一些公司的投資系統,應用一些機器學習,甚至是一些深度學習,然后學習如何回溯測試一個策略。我假設你知道 Python 基礎。如果您不確定,請點擊基礎鏈接,查看系列中的一些主題,并進行判斷。如果在任何時候你卡在這個系列中,或者對某個主題或概念感到困惑,請隨時尋求幫助,我將盡我所能提供幫助。
我被問到的一個常見問題是,我是否使用這些技術投資或交易獲利。我主要是為了娛樂,并且練習數據分析技巧而玩財務數據,但實際上這也影響了我今天的投資決策。在寫這篇文章的時候,我并沒有用編程來進行實時算法交易,但是我已經有了實際的盈利,但是在算法交易方面還有很多工作要做。最后,如何操作和分析財務數據,以及如何測試交易狀態的知識已經為我節省了大量的金錢。
這里提出的策略都不會使你成為一個超富有的人。如果他們愿意,我可能會把它們留給自己!然而,知識本身可以為你節省金錢,甚至可以使你賺錢。
好吧,讓我們開始吧。首先,我正在使用 Python 3.5,但你應該能夠獲取更高版本。我會假設你已經安裝了Python。如果你沒有 64 位的 Python,但有 64 位的操作系統,去獲取 64 位的 Python,稍后會幫助你。如果你使用的是 32 位操作系統,那么我對你的情況感到抱歉,不過你應該沒問題。
用于啟動的所需模塊:
1. NumPy
1. Matplotlib
1. Pandas
1. Pandas-datareader
1. BeautifulSoup4
1. scikit-learn / sklearn
這些是現在做的,我們會在其他模塊出現時處理它們。 首先,讓我們介紹一下如何使用 pandas,matplotlib 和 Python 處理股票數據。
如果您想了解 Matplotlib 的更多信息,請查看 Matplotlib 數據可視化系列教程。
如果您想了解 Pandas 的更多信息,請查看 Pandas 數據分析系列教程。
首先,我們將執行以下導入:
```py
import datetime as dt
import matplotlib.pyplot as plt
from matplotlib import style
import pandas as pd
import pandas_datareader.data as web
```
`Datetime`讓我們很容易處理日期,`matplotlib`用于繪圖,Pandas 用于操縱數據,`pandas_datareader`是我寫這篇文章時最新的 Pandas io 庫。
現在進行一些啟動配置:
```py
style.use('ggplot')
start = dt.datetime(2000, 1, 1)
end = dt.datetime(2016, 12, 31)
```
我們正在設置一個風格,所以我們的圖表看起來并不糟糕。 在金融領域,即使你虧本,你的圖表也是非常重要的。 接下來,我們設置一個開始和結束`datetime `對象,這將是我們要獲取股票價格信息的日期范圍。
現在,我們可以從這些數據中創建一個數據幀:
```py
df = web.DataReader('TSLA', "yahoo", start, end)
```
如果您目前不熟悉`DataFrame`對象,可以查看 Pandas 的教程,或者只是將其想象為電子表格或存儲器/ RAM 中的數據庫表。 這只是一些行和列,并帶有一個索引和列名乘。 在我們的這里,我們的索引可能是日期。 索引應該是與所有列相關的東西。
`web.DataReader('TSLA', "yahoo", start, end)`這一行,使用`pandas_datareader`包,尋找股票代碼`TSLA`(特斯拉),從 yahoo 獲取信息,從我們選擇的起始和結束日期起始或結束。 以防你不知道,股票是公司所有權的一部分,代碼是用來在證券交易所引用公司的“符號”。 大多數代碼是 1-4 個字母。
所以現在我們有一個`Pandas.DataFrame`對象,它包含特斯拉的股票交易信息。 讓我們看看我們在這里有啥:
```py
print(df.head())
```
```
Open High Low Close Volume Adj Close
Date
2010-06-29 19.000000 25.00 17.540001 23.889999 18766300 23.889999
2010-06-30 25.790001 30.42 23.299999 23.830000 17187100 23.830000
2010-07-01 25.000000 25.92 20.270000 21.959999 8218800 21.959999
2010-07-02 23.000000 23.10 18.709999 19.200001 5139800 19.200001
2010-07-06 20.000000 20.00 15.830000 16.110001 6866900 16.110001
```
`.head()`是可以用`Pandas DataFrames`做的事情,它會輸出前`n`行??,其中`n`是你傳遞的可選參數。如果不傳遞參數,則默認值為 5。我們絕對會使用`.head()`來快速瀏覽一下我們的數據,以確保我們在正路上。看起來很棒!
以防你不知道:
+ 開盤價 - 當股市開盤交易時,一股的價格是多少?
+ 最高價 - 在交易日的過程中,那一天的最高價是多少?
+ 最低價 - 在交易日的過程中,那一天的最低價是多少?
+ 收盤價 - 當交易日結束時,最終的價格是多少?
+ 成交量 - 那一天有多少股交易?
調整收盤價 - 這一個稍微復雜一些,但是隨著時間的推移,公司可能決定做一個叫做股票拆分的事情。例如,蘋果一旦股價超過 1000 美元就做了一次。由于在大多數情況下,人們不能購買股票的一小部分,股票價格 1000 美元相當限制投資者。公司可以做股票拆分,他們說每股現在是 2 股,價格是一半。任何人如果以 1,000 美元買入 1 股蘋果股份,在拆分之后,蘋果的股票翻倍,他們將擁有 2 股蘋果(AAPL),每股價值 500 美元。調整收盤價是有幫助的,因為它解釋了未來的股票分割,并給出分割的相對價格。出于這個原因,調整價格是你最有可能處理的價格。
## 二、處理數據和繪圖
歡迎閱讀 Python 金融系列教程的第 2 部分。 在本教程中,我們將使用我們的股票數據進一步拆分一些基本的數據操作和可視化。 我們將使用的起始代碼(在前面的教程中已經介紹過)是:
```py
import datetime as dt
import matplotlib.pyplot as plt
from matplotlib import style
import pandas as pd
import pandas_datareader.data as web
style.use('ggplot')
start = dt.datetime(2000,1,1)
end = dt.datetime(2016,12,31)
df = web.DataReader('TSLA', 'yahoo', start, end)
```
我們可以用這些`DataFrame`做些什么? 首先,我們可以很容易地將它們保存到各種數據類型中。 一個選項是`csv`:
```py
df.to_csv('TSLA.csv')
```
我們也可以將數據從 CSV 文件讀取到`DataFrame`中,而不是將數據從 Yahoo 財經 API 讀取到`DataFrame`中:
```py
df = pd.read_csv('tsla.csv', parse_dates=True, index_col=0)
```
現在,我們可以繪制它:
```py
df.plot()
plt.show()
```
很酷,盡管我們真正能看到的唯一的東西就是成交量,因為它比股票價格大得多。 我們怎么可能僅僅繪制我們感興趣的東西?
```py
df['Adj Close'].plot()
plt.show()
```
你可以看到,你可以在`DataFrame`中引用特定的列,如:`df['Adj Close']`,但是你也可以一次引用多個,如下所示:
```py
df[['High','Low']]
```
在下一個教程中,我們將介紹這些數據的一些基本操作,以及一些更基本的可視化。
## 三、基本的股票數據操作
歡迎閱讀 Python 金融系列教程的第 3 部分。 在本教程中,我們將使用我們的股票數據進一步拆分一些基本的數據操作和可視化。 我們將要使用的起始代碼(在前面的教程中已經介紹過)是:
```py
import datetime as dt
import matplotlib.pyplot as plt
from matplotlib import style
import pandas as pd
import pandas_datareader.data as web
style.use('ggplot')
df = pd.read_csv('tsla.csv', parse_dates=True, index_col=0)
```
Pandas 模塊配備了一堆可用的內置函數,以及創建自定義 Pandas 函數的方法。 稍后我們將介紹一些自定義函數,但現在讓我們對這些數據執行一個非常常見的操作:移動均值。
簡單移動均值的想法是選取時間窗口,并計算該窗口內的均值。 然后我們把這個窗口移動一個周期,然后再做一次。 在我們這里,我們將計算 100 天滾動均值。 因此,這將選取當前價格和過去 99 天的價格,加起來,除以 100,之后就是當前的 100 天移動均值。 然后我們把窗口移動一天,然后再做同樣的事情。 在 Pandas 中這樣做很簡單:
```py
df['100ma'] = df['Adj Close'].rolling(window=100).mean()
```
如果我們有一列叫做`100ma`,執行`df['100ma']`允許我們重新定義包含現有列的內容,否則創建一個新列,這就是我們在這里做的。 我們說`df['100ma']`列等同于應用滾動方法的`df['Adj Close']`列,窗口為 100,這個窗口將是` mean()`(均值)操作。
現在,我們執行:
```py
print(df.head())
```
```
Date Open High Low Close Volume \
Date
2010-06-29 2010-06-29 19.000000 25.00 17.540001 23.889999 18766300
2010-06-30 2010-06-30 25.790001 30.42 23.299999 23.830000 17187100
2010-07-01 2010-07-01 25.000000 25.92 20.270000 21.959999 8218800
2010-07-02 2010-07-02 23.000000 23.10 18.709999 19.200001 5139800
2010-07-06 2010-07-06 20.000000 20.00 15.830000 16.110001 6866900
Adj Close 100ma
Date
2010-06-29 23.889999 NaN
2010-06-30 23.830000 NaN
2010-07-01 21.959999 NaN
2010-07-02 19.200001 NaN
2010-07-06 16.110001 NaN
```
發生了什么? 在`100ma`列中,我們只看到`NaN`。 我們選擇了 100 移動均值,理論上需要 100 個之前的數據點進行計算,所以我們在這里沒有任何前 100 行的數據。 `NaN`的意思是“不是一個數字”。 有了 Pandas,你可以決定對缺失數據做很多事情,但現在,我們只需要改變最小周期參數:
```
Date Open High Low Close Volume \
Date
2010-06-29 2010-06-29 19.000000 25.00 17.540001 23.889999 18766300
2010-06-30 2010-06-30 25.790001 30.42 23.299999 23.830000 17187100
2010-07-01 2010-07-01 25.000000 25.92 20.270000 21.959999 8218800
2010-07-02 2010-07-02 23.000000 23.10 18.709999 19.200001 5139800
2010-07-06 2010-07-06 20.000000 20.00 15.830000 16.110001 6866900
Adj Close 100ma
Date
2010-06-29 23.889999 23.889999
2010-06-30 23.830000 23.860000
2010-07-01 21.959999 23.226666
2010-07-02 19.200001 22.220000
2010-07-06 16.110001 20.998000
```
好吧,可以用,現在我們想看看它! 但是我們已經看到了簡單的圖表,那么稍微復雜一些呢?
```py
ax1 = plt.subplot2grid((6,1), (0,0), rowspan=5, colspan=1)
ax2 = plt.subplot2grid((6,1), (5,0), rowspan=1, colspan=1,sharex=ax1)
```
如果你想了解`subplot2grid`的更多信息,請查看 Matplotlib 教程的子圖部分。
基本上,我們說我們想要創建兩個子圖,而這兩個子圖都在`6x1`的網格中,我們有 6 行 1 列。 第一個子圖從該網格上的`(0,0)`開始,跨越 5 行,并跨越 1 列。 下一個子圖也在`6x1`網格上,但是從`(5,0)`開始,跨越 1 行和 1 列。 第二個子圖帶有`sharex = ax1`,這意味著`ax2`的`x`軸將始終與`ax1`的`x`軸對齊,反之亦然。 現在我們只是繪制我們的圖形:
```py
ax1.plot(df.index, df['Adj Close'])
ax1.plot(df.index, df['100ma'])
ax2.bar(df.index, df['Volume'])
plt.show()
```
在上面,我們在第一個子圖中繪制了的`close`和`100ma`,第二個圖中繪制`volume`。 我們的結果:
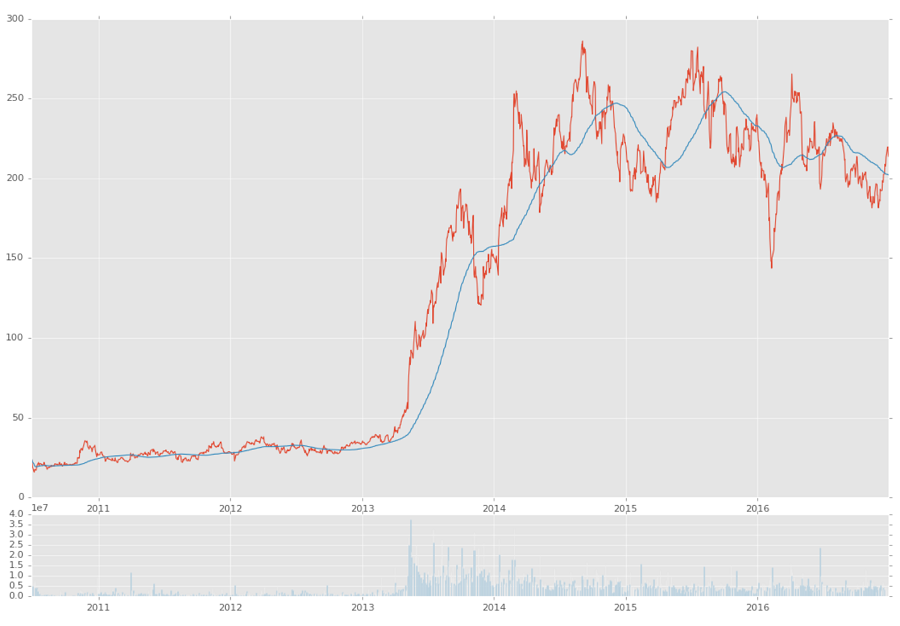
到這里的完整代碼:
```py
import datetime as dt
import matplotlib.pyplot as plt
from matplotlib import style
import pandas as pd
import pandas_datareader.data as web
style.use('ggplot')
df = pd.read_csv('tsla.csv', parse_dates=True, index_col=0)
df['100ma'] = df['Adj Close'].rolling(window=100, min_periods=0).mean()
print(df.head())
ax1 = plt.subplot2grid((6,1), (0,0), rowspan=5, colspan=1)
ax2 = plt.subplot2grid((6,1), (5,0), rowspan=1, colspan=1, sharex=ax1)
ax1.plot(df.index, df['Adj Close'])
ax1.plot(df.index, df['100ma'])
ax2.bar(df.index, df['Volume'])
plt.show()
```
在接下來的幾個教程中,我們將學習如何通過 Pandas 數據重采樣制作燭臺圖,并學習更多使用 Matplotlib 的知識。
## 四、更多股票操作
歡迎閱讀 Python 金融教程系列的第 4 部分。 在本教程中,我們將基于`Adj Close`列創建燭臺/ OHLC 圖,我將介紹重新采樣和其他一些數據可視化概念。
名為燭臺圖的 OHLC 圖是一個圖表,將開盤價,最高價,最低價和收盤價都匯總成很好的格式。 并且它使用漂亮的顏色,還記得我告訴你有關漂亮的圖表的事情嘛?
之前的教程中,目前為止的起始代碼:
```py
import datetime as dt
import matplotlib.pyplot as plt
from matplotlib import style
import pandas as pd
import pandas_datareader.data as web
style.use('ggplot')
df = pd.read_csv('tsla.csv', parse_dates=True, index_col=0)
```
不幸的是,即使創建 OHLC 數據是這樣,Pandas 沒有內置制作燭臺圖的功能。 有一天,我確信這個圖表類型將會可用,但是,現在不是。 沒關系,我們會實現它! 首先,我們需要做兩個新的導入:
```py
from matplotlib.finance import candlestick_ohlc
import matplotlib.dates as mdates
```
第一個導入是來自 matplotlib 的 OHLC 圖形類型,第二個導入是特殊的`mdates`類型,它在對接中是個麻煩,但這是 matplotlib 圖形的日期類型。 Pandas 自動為你處理,但正如我所說,我們沒有那么方便的燭臺。
首先,我們需要適當的 OHLC 數據。 我們目前的數據確實有 OHLC 值,除非我錯了,特斯拉從未有過拆分,但是你不會總是這么幸運。 因此,我們將創建我們自己的 OHLC 數據,這也將使我們能夠展示來自 Pandas 的另一個數據轉換:
```py
df_ohlc = df['Adj Close'].resample('10D').ohlc()
```
我們在這里所做的是,創建一個新的數據幀,基于`df ['Adj Close']`列,使用 10 天窗口重采樣,并且重采樣是一個 OHLC(開高低關)。我們也可以用`.mean()`或`.sum()`計算 10 天的均值,或 10 天的總和。請記住,這 10 天的均值是 10 天均值,而不是滾動均值。由于我們的數據是每日數據,重采樣到 10 天的數據有效地縮小了我們的數據大小。這就是你規范多個數據集的方式。有時候,您可能會在每個月的第一天記錄一次數據,在每個月末記錄其他數據,最后每周記錄一些數據。您可以將該數據幀重新采樣到月底,并有效地規范化所有東西!這是一個更先進的 Padas 功能,如果你喜歡,你可以更多了解 Pandas 的序列。
我們想要繪制燭臺數據以及成交量數據。我們不需要將成交量數據重采樣,但是我們應該這樣做,因為與我們的`10D`價格數據相比,這個數據太細致了。
```py
df_volume = df['Volume'].resample('10D').sum()
```
我們在這里使用`sum`,因為我們真的想知道在這 10 天內交易總量,但也可以用平均值。 現在如果我們這樣做:
```py
print(df_ohlc.head())
```
```
open high low close
Date
2010-06-29 23.889999 23.889999 15.800000 17.459999
2010-07-09 17.400000 20.639999 17.049999 20.639999
2010-07-19 21.910000 21.910000 20.219999 20.719999
2010-07-29 20.350000 21.950001 19.590000 19.590000
2010-08-08 19.600000 19.600000 17.600000 19.150000
```
這是預期,但是,我們現在要將這些信息移動到 matplotlib,并將日期轉換為`mdates`版本。 由于我們只是要在 Matplotlib 中繪制列,我們實際上不希望日期成為索引,所以我們可以這樣做:
```py
df_ohlc = df_ohlc.reset_index()
```
現在`dates `只是一個普通的列。 接下來,我們要轉換它:
```py
df_ohlc['Date'] = df_ohlc['Date'].map(mdates.date2num)
```
現在我們打算配置圖形:
```py
fig = plt.figure()
ax1 = plt.subplot2grid((6,1), (0,0), rowspan=5, colspan=1)
ax2 = plt.subplot2grid((6,1), (5,0), rowspan=1, colspan=1,sharex=ax1)
ax1.xaxis_date()
```
除了`ax1.xaxis_date()`之外,你已經看到了一切。 這對我們來說,是把軸從原始的`mdate`數字轉換成日期。
現在我們可以繪制燭臺圖:
```py
candlestick_ohlc(ax1, df_ohlc.values, width=2, colorup='g')
```
之后是成交量:
```py
ax2.fill_between(df_volume.index.map(mdates.date2num),df_volume.values,0)
```
`fill_between`函數將繪制`x`,`y`,然后填充之間的內容。 在我們的例子中,我們選擇 0。
```py
plt.show()
```
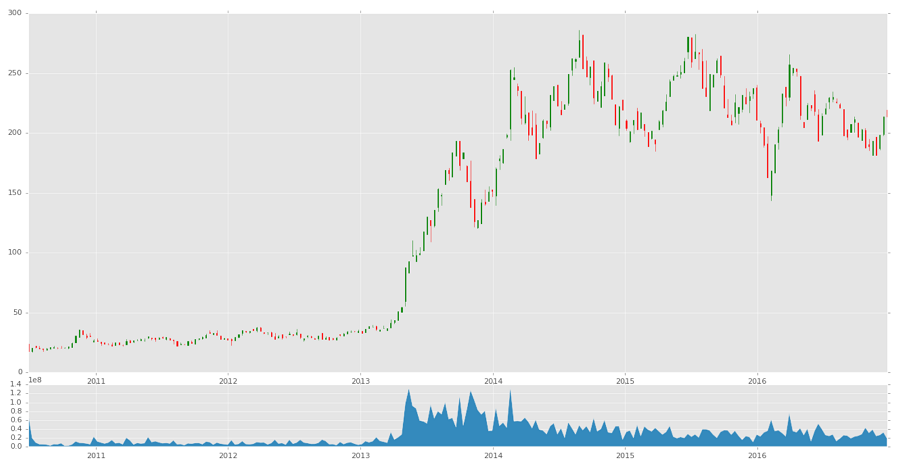
這個教程的完整代碼:
```py
import datetime as dt
import matplotlib.pyplot as plt
from matplotlib import style
from matplotlib.finance import candlestick_ohlc
import matplotlib.dates as mdates
import pandas as pd
import pandas_datareader.data as web
style.use('ggplot')
df = pd.read_csv('tsla.csv', parse_dates=True, index_col=0)
df_ohlc = df['Adj Close'].resample('10D').ohlc()
df_volume = df['Volume'].resample('10D').sum()
df_ohlc.reset_index(inplace=True)
df_ohlc['Date'] = df_ohlc['Date'].map(mdates.date2num)
ax1 = plt.subplot2grid((6,1), (0,0), rowspan=5, colspan=1)
ax2 = plt.subplot2grid((6,1), (5,0), rowspan=1, colspan=1, sharex=ax1)
ax1.xaxis_date()
candlestick_ohlc(ax1, df_ohlc.values, width=5, colorup='g')
ax2.fill_between(df_volume.index.map(mdates.date2num), df_volume.values, 0)
plt.show()
```
在接下來的幾個教程中,我們將把可視化留到后面一些,然后專注于獲取并處理數據。
## 五、自動獲取 SP500 列表
歡迎閱讀 Python 金融教程系列的第 5 部分。在本教程和接下來的幾章中,我們將著手研究如何能夠獲取大量價格信息,以及如何一次處理所有這些數據。
首先,我們需要一個公司名單。我可以給你一個清單,但實際上獲得股票清單可能只是你可能遇到的許多挑戰之一。在我們的案例中,我們需要一個 SP500 公司的 Python 列表。
無論您是在尋找道瓊斯公司,SP500 指數還是羅素 3000 指數,這些公司的信息都有可能在某個地方發布。您需要確保它是最新的,但是它可能還不是完美的格式。在我們的例子中,我們將從維基百科獲取這個列表:`http://en.wikipedia.org/wiki/List_of_S%26P_500_companies`。
維基百科中的代碼/符號組織在一張表里面。為了解決這個問題,我們將使用 HTML 解析庫,Beautiful Soup。如果你想了解更多,我有一個使用 Beautiful Soup 進行網頁抓取的簡短的四部分教程。
首先,我們從一些導入開始:
```py
import bs4 as bs
import pickle
import requests
```
`bs4`是 Beautiful Soup,`pickle `是為了我們可以很容易保存這個公司的名單,而不是每次我們運行時都訪問維基百科(但要記住,你需要及時更新這個名單!),我們將使用 `requests `從維基百科頁面獲取源代碼。
這是我們函數的開始:
```py
def save_sp500_tickers():
resp = requests.get('http://en.wikipedia.org/wiki/List_of_S%26P_500_companies')
soup = bs.BeautifulSoup(resp.text, 'lxml')
table = soup.find('table', {'class': 'wikitable sortable'})
```
首先,我們訪問維基百科頁面,并獲得響應,其中包含我們的源代碼。 為了處理源代碼,我們想要訪問`.text`屬性,我們使用 BeautifulSoup 將其轉為`soup`。 如果您不熟悉 BeautifulSoup 為您所做的工作,它基本上將源代碼轉換為一個 BeautifulSoup 對象,馬上就可以看做一個典型的 Python 對象。
有一次維基百科試圖拒絕 Python 的訪問。 目前,在我寫這篇文章的時候,代碼不改變協議頭也能工作。 如果您發現原始源代碼(`resp.text`)似乎不返回相同的頁面,像您在家用計算機上看到的那樣,請添加以下內容并更改`resp var`代碼:
```py
headers = {'User-Agent': 'Mozilla/5.0 (X11; Linux i686) AppleWebKit/537.17 (KHTML, like Gecko) Chrome/24.0.1312.27 Safari/537.17'}
resp = requests.get('http://en.wikipedia.org/wiki/List_of_S%26P_500_companies',
headers=headers)
```
一旦我們有了`soup`,我們可以通過簡單地搜索`wikitable sortable`類來找到股票數據表。 我知道指定這個表的唯一原因是,因為我之前在瀏覽器中查看了源代碼。 可能會有這樣的情況,你想解析一個不同的網站的股票列表,也許它是在一個表中,也可能是一個列表,或者可能是一些`div`標簽。 這都是一個非常具體的解決方案。 從這里開始,我們僅僅遍歷表格:
```py
tickers = []
for row in table.findAll('tr')[1:]:
ticker = row.findAll('td')[0].text
tickers.append(ticker)
```
對于每一行,在標題行之后(這就是為什么我們要執行`[1:]`),我們說股票是“表格數據”(`td`),我們抓取它的`.text`, 將此代碼添加到我們的列表中。
現在,如果我們可以保存這個列表,那就好了。 我們將使用`pickle`模塊來為我們序列化 Python 對象。
```py
with open("sp500tickers.pickle","wb") as f:
pickle.dump(tickers,f)
return tickers
```
我們希望繼續并保存它,因此我們無需每天多次請求維基百科。 在任何時候,我們可以更新這個清單,或者我們可以編程一個月檢查一次...等等。
目前為止的完整代碼:
```py
import bs4 as bs
import pickle
import requests
def save_sp500_tickers():
resp = requests.get('http://en.wikipedia.org/wiki/List_of_S%26P_500_companies')
soup = bs.BeautifulSoup(resp.text, 'lxml')
table = soup.find('table', {'class': 'wikitable sortable'})
tickers = []
for row in table.findAll('tr')[1:]:
ticker = row.findAll('td')[0].text
tickers.append(ticker)
with open("sp500tickers.pickle","wb") as f:
pickle.dump(tickers,f)
return tickers
save_sp500_tickers()
```
現在我們已經知道了代碼,我們已經準備好提取所有的信息,這是我們將在下一個教程中做的事情。
## 六、獲取 SP500 中所有公司的價格數據
歡迎閱讀 Python 金融教程系列的第 6 部分。 在之前的 Python 教程中,我們介紹了如何獲取我們感興趣的公司名單(在我們的案例中是 SP500),現在我們將獲取所有這些公司的股票價格數據。
目前為止的代碼:
```py
def save_sp500_tickers():
resp = requests.get('http://en.wikipedia.org/wiki/List_of_S%26P_500_companies')
soup = bs.BeautifulSoup(resp.text, 'lxml')
table = soup.find('table', {'class': 'wikitable sortable'})
tickers = []
for row in table.findAll('tr')[1:]:
ticker = row.findAll('td')[0].text
tickers.append(ticker)
with open("sp500tickers.pickle","wb") as f:
pickle.dump(tickers,f)
return tickers
```
我們打算添加一些新的導入:
```py
import datetime as dt
import os
import pandas as pd
import pandas_datareader.data as web
```
我們將使用`datetime`為 Pandas `datareader`指定日期,`os`用于檢查并創建目錄。 你已經知道 Pandas 干什么了!
我們的新函數的開始:
```py
def get_data_from_yahoo(reload_sp500=False):
if reload_sp500:
tickers = save_sp500_tickers()
else:
with open("sp500tickers.pickle","rb") as f:
tickers = pickle.load(f)
```
在這里,我將展示一個簡單示例,可以處理是否重新加載 SP500 列表。 如果我們讓它這樣,這個程序將重新抓取 SP500,否則將只使用我們的`pickle`。 現在我們準備抓取數據。
現在我們需要決定我們要處理的數據。 我傾向于嘗試解析網站一次,并在本地存儲數據。 我不會事先知道我可能用數據做的所有事情,但是我知道如果我不止一次地抓取它,我還可以保存它(除非它是一個巨大的數據集,但不是)。 因此,對于每一種股票,我們抓取所有雅虎可以返回給我們的東西,并保存下來。 為此,我們將創建一個新目錄,并在那里存儲每個公司的股票數據。 首先,我們需要這個初始目錄:
```py
if not os.path.exists('stock_dfs'):
os.makedirs('stock_dfs')
```
您可以將這些數據集存儲在與您的腳本相同的目錄中,但在我看來,這會變得非常混亂。 現在我們準備好提取數據了。 你已經知道如何實現,我們在第一個教程中完成了!
```py
start = dt.datetime(2000, 1, 1)
end = dt.datetime(2016, 12, 31)
for ticker in tickers:
if not os.path.exists('stock_dfs/{}.csv'.format(ticker)):
df = web.DataReader(ticker, "yahoo", start, end)
df.to_csv('stock_dfs/{}.csv'.format(ticker))
else:
print('Already have {}'.format(ticker))
```
你可能想要為這個函數傳入`force_data_update`參數,因為現在它不會重新提取它已經訪問的數據。 由于我們正在提取每日數據,所以您最好至少重新提取最新的數據。 也就是說,如果是這樣的話,最好對每個公司使用數據庫而不是表格,然后從 Yahoo 數據庫中提取最新的值。 但是現在我們會保持簡單!
目前為止的代碼:
```py
import bs4 as bs
import datetime as dt
import os
import pandas as pd
import pandas_datareader.data as web
import pickle
import requests
def save_sp500_tickers():
resp = requests.get('http://en.wikipedia.org/wiki/List_of_S%26P_500_companies')
soup = bs.BeautifulSoup(resp.text, 'lxml')
table = soup.find('table', {'class': 'wikitable sortable'})
tickers = []
for row in table.findAll('tr')[1:]:
ticker = row.findAll('td')[0].text
tickers.append(ticker)
with open("sp500tickers.pickle","wb") as f:
pickle.dump(tickers,f)
return tickers
#save_sp500_tickers()
def get_data_from_yahoo(reload_sp500=False):
if reload_sp500:
tickers = save_sp500_tickers()
else:
with open("sp500tickers.pickle","rb") as f:
tickers = pickle.load(f)
if not os.path.exists('stock_dfs'):
os.makedirs('stock_dfs')
start = dt.datetime(2000, 1, 1)
end = dt.datetime(2016, 12, 31)
for ticker in tickers:
# just in case your connection breaks, we'd like to save our progress!
if not os.path.exists('stock_dfs/{}.csv'.format(ticker)):
df = web.DataReader(ticker, "yahoo", start, end)
df.to_csv('stock_dfs/{}.csv'.format(ticker))
else:
print('Already have {}'.format(ticker))
get_data_from_yahoo()
```
運行它。如果雅虎阻攔你的話,你可能想添加`import time`和`time.sleep(0.5)`或一些東西。 在我寫這篇文章的時候,雅虎并沒有阻攔我,我能夠毫無問題地完成這個任務。 但是這可能需要你一段時間,尤其取決于你的機器。 好消息是,我們不需要再做一遍! 同樣在實踐中,因為這是每日數據,但是您可能每天都執行一次。
另外,如果你的互聯網速度很慢,你不需要獲取所有的代碼,即使只有 10 個就足夠了,所以你可以用`ticker [:10]`或者類似的東西來加快速度。
在下一個教程中,一旦你下載了數據,我們將把我們感興趣的數據編譯成一個大的 Pandas`DataFrame`。
## 七、將所有 SP500 價格組合到一個`DataFrame`
歡迎閱讀 Python 金融系列教程的第 7 部分。 在之前的教程中,我們抓取了整個 SP500 公司的雅虎財經數據。 在本教程中,我們將把這些數據放在一個`DataFrame`中。
目前為止的代碼:
```py
import bs4 as bs
import datetime as dt
import os
import pandas as pd
import pandas_datareader.data as web
import pickle
import requests
def save_sp500_tickers():
resp = requests.get('http://en.wikipedia.org/wiki/List_of_S%26P_500_companies')
soup = bs.BeautifulSoup(resp.text, 'lxml')
table = soup.find('table', {'class': 'wikitable sortable'})
tickers = []
for row in table.findAll('tr')[1:]:
ticker = row.findAll('td')[0].text
tickers.append(ticker)
with open("sp500tickers.pickle","wb") as f:
pickle.dump(tickers,f)
return tickers
def get_data_from_yahoo(reload_sp500=False):
if reload_sp500:
tickers = save_sp500_tickers()
else:
with open("sp500tickers.pickle","rb") as f:
tickers = pickle.load(f)
if not os.path.exists('stock_dfs'):
os.makedirs('stock_dfs')
start = dt.datetime(2000, 1, 1)
end = dt.datetime(2016, 12, 31)
for ticker in tickers:
# just in case your connection breaks, we'd like to save our progress!
if not os.path.exists('stock_dfs/{}.csv'.format(ticker)):
df = web.DataReader(ticker, "yahoo", start, end)
df.to_csv('stock_dfs/{}.csv'.format(ticker))
else:
print('Already have {}'.format(ticker))
```
雖然我們擁有了所有的數據,但是我們可能要一起評估數據。 為此,我們將把所有的股票數據組合在一起。 目前的每個股票文件都帶有:開盤價,最高價,最低價,收盤價,成交量和調整收盤價。 至少在最開始,我們現在幾乎只對調整收盤價感興趣。
```py
def compile_data():
with open("sp500tickers.pickle","rb") as f:
tickers = pickle.load(f)
main_df = pd.DataFrame()
```
首先,我們獲取我們以前生成的代碼,并從一個叫做`main_df`的空`DataFrame`開始。 現在,我們準備讀取每個股票的數據幀:
```py
for count,ticker in enumerate(tickers):
df = pd.read_csv('stock_dfs/{}.csv'.format(ticker))
df.set_index('Date', inplace=True)
```
您不需要在這里使用 Python 的`enumerate `,我只是使用它,以便知道我們在讀取所有數據的過程中的哪里。 你可以迭代代碼。 到了這里,我們*可以*使用有趣的數據來生成額外的列,如:
```py
df['{}_HL_pct_diff'.format(ticker)] = (df['High'] - df['Low']) / df['Low']
df['{}_daily_pct_chng'.format(ticker)] = (df['Close'] - df['Open']) / df['Open']
```
但是現在,我們不會因此而煩惱。 只要知道這可能是一條遵循之路。 相反,我們真的只是對`Adj Close`列感興趣:
```py
df.rename(columns={'Adj Close':ticker}, inplace=True)
df.drop(['Open','High','Low','Close','Volume'],1,inplace=True)
```
現在我們已經得到了這一列(或者像上面那樣的額外列,但是請記住,在這個例子中,我們沒有計算`HL_pct_diff`或`daily_pct_chng`)。 請注意,我們已將`Adj Close`列重命名為任何股票名稱。 我們開始構建共享數據幀:
```py
if main_df.empty:
main_df = df
else:
main_df = main_df.join(df, how='outer')
```
如果`main_df`中沒有任何內容,那么我們將從當前的`df`開始,否則我們將使用 Pandas 的`join`。
仍然在這個`for`循環中,我們將添加兩行:
```py
if count % 10 == 0:
print(count)
```
這將只輸出當前的股票數量,如果它可以被 10 整除。`count % 10`計算被除數除以 10 的余數。所以,如果我們計算`count % 10 == 0`,并且如果當前計數能被 10 整除,余數為零,我們只有看到`if`語句為真。
我們完成了`for`循環的時候:
```py
print(main_df.head())
main_df.to_csv('sp500_joined_closes.csv')
```
目前為止的函數及其調用:
```py
with open("sp500tickers.pickle","rb") as f:
tickers = pickle.load(f)
main_df = pd.DataFrame()
for count,ticker in enumerate(tickers):
df = pd.read_csv('stock_dfs/{}.csv'.format(ticker))
df.set_index('Date', inplace=True)
df.rename(columns={'Adj Close':ticker}, inplace=True)
df.drop(['Open','High','Low','Close','Volume'],1,inplace=True)
if main_df.empty:
main_df = df
else:
main_df = main_df.join(df, how='outer')
if count % 10 == 0:
print(count)
print(main_df.head())
main_df.to_csv('sp500_joined_closes.csv')
compile_data()
```
目前為止的完整代碼:
```py
import bs4 as bs
import datetime as dt
import os
import pandas as pd
import pandas_datareader.data as web
import pickle
import requests
def save_sp500_tickers():
resp = requests.get('http://en.wikipedia.org/wiki/List_of_S%26P_500_companies')
soup = bs.BeautifulSoup(resp.text, 'lxml')
table = soup.find('table', {'class': 'wikitable sortable'})
tickers = []
for row in table.findAll('tr')[1:]:
ticker = row.findAll('td')[0].text
tickers.append(ticker)
with open("sp500tickers.pickle","wb") as f:
pickle.dump(tickers,f)
return tickers
def get_data_from_yahoo(reload_sp500=False):
if reload_sp500:
tickers = save_sp500_tickers()
else:
with open("sp500tickers.pickle","rb") as f:
tickers = pickle.load(f)
if not os.path.exists('stock_dfs'):
os.makedirs('stock_dfs')
start = dt.datetime(2000, 1, 1)
end = dt.datetime(2016, 12, 31)
for ticker in tickers:
# just in case your connection breaks, we'd like to save our progress!
if not os.path.exists('stock_dfs/{}.csv'.format(ticker)):
df = web.DataReader(ticker, "yahoo", start, end)
df.to_csv('stock_dfs/{}.csv'.format(ticker))
else:
print('Already have {}'.format(ticker))
def compile_data():
with open("sp500tickers.pickle","rb") as f:
tickers = pickle.load(f)
main_df = pd.DataFrame()
for count,ticker in enumerate(tickers):
df = pd.read_csv('stock_dfs/{}.csv'.format(ticker))
df.set_index('Date', inplace=True)
df.rename(columns={'Adj Close':ticker}, inplace=True)
df.drop(['Open','High','Low','Close','Volume'],1,inplace=True)
if main_df.empty:
main_df = df
else:
main_df = main_df.join(df, how='outer')
if count % 10 == 0:
print(count)
print(main_df.head())
main_df.to_csv('sp500_joined_closes.csv')
compile_data()
```
在下一個教程中,我們將嘗試查看,是否可以快速找到數據中的任何關系。
## 八、創建大型 SP500 公司相關性表
歡迎閱讀 Python 金融教程系列的第 8 部分。 在之前的教程中,我們展示了如何組合 SP500 公司的所有每日價格數據。 在本教程中,我們將看看是否可以找到任何有趣的關聯數據。 為此,我們希望將其可視化,因為它是大量數據。 我們將使用 Matplotlib,以及 Numpy。
目前為止的代碼:
```py
import bs4 as bs
import datetime as dt
import os
import pandas as pd
import pandas_datareader.data as web
import pickle
import requests
def save_sp500_tickers():
resp = requests.get('http://en.wikipedia.org/wiki/List_of_S%26P_500_companies')
soup = bs.BeautifulSoup(resp.text, 'lxml')
table = soup.find('table', {'class': 'wikitable sortable'})
tickers = []
for row in table.findAll('tr')[1:]:
ticker = row.findAll('td')[0].text
tickers.append(ticker)
with open("sp500tickers.pickle","wb") as f:
pickle.dump(tickers,f)
return tickers
def get_data_from_yahoo(reload_sp500=False):
if reload_sp500:
tickers = save_sp500_tickers()
else:
with open("sp500tickers.pickle","rb") as f:
tickers = pickle.load(f)
if not os.path.exists('stock_dfs'):
os.makedirs('stock_dfs')
start = dt.datetime(2000, 1, 1)
end = dt.datetime(2016, 12, 31)
for ticker in tickers:
# just in case your connection breaks, we'd like to save our progress!
if not os.path.exists('stock_dfs/{}.csv'.format(ticker)):
df = web.DataReader(ticker, "yahoo", start, end)
df.to_csv('stock_dfs/{}.csv'.format(ticker))
else:
print('Already have {}'.format(ticker))
def compile_data():
with open("sp500tickers.pickle","rb") as f:
tickers = pickle.load(f)
main_df = pd.DataFrame()
for count,ticker in enumerate(tickers):
df = pd.read_csv('stock_dfs/{}.csv'.format(ticker))
df.set_index('Date', inplace=True)
df.rename(columns={'Adj Close':ticker}, inplace=True)
df.drop(['Open','High','Low','Close','Volume'],1,inplace=True)
if main_df.empty:
main_df = df
else:
main_df = main_df.join(df, how='outer')
if count % 10 == 0:
print(count)
print(main_df.head())
main_df.to_csv('sp500_joined_closes.csv')
compile_data()
```
現在我們打算添加下列導入并設置樣式:
```py
import matplotlib.pyplot as plt
from matplotlib import style
import numpy as np
style.use('ggplot')
```
下面我們開始構建 Matplotlib 函數:
```py
def visualize_data():
df = pd.read_csv('sp500_joined_closes.csv')
```
到了這里,我們可以繪制任何公司:
```py
df['AAPL'].plot()
plt.show()
```
...但是我們沒有瀏覽所有東西,就繪制單個公司! 相反,讓我們來看看所有這些公司的相關性。 在 Pandas 中建立相關性表實際上是非常簡單的:
```py
df_corr = df.corr()
print(df_corr.head())
```
這就是它了。`.corr()`會自動查看整個`DataFrame`,并確定每列與每列的相關性。 我已經看到付費的網站也把它做成服務。 所以,如果你需要一些副業的話,那么你可以用它!
我們當然可以保存這個,如果我們想要的話:
```py
df_corr.to_csv('sp500corr.csv')
```
相反,我們要繪制它。 為此,我們要生成一個熱力圖。 Matplotlib 中沒有內置超級簡單的熱力圖,但我們有工具可以制作。 為此,首先我們需要實際的數據來繪制:
```py
data1 = df_corr.values
```
這會給我們這些數值的 NumPy 數組,它們是相關性的值。 接下來,我們將構建我們的圖形和坐標軸:
```py
fig1 = plt.figure()
ax1 = fig1.add_subplot(111)
```
現在我們使用`pcolor`來繪制熱力圖:
```py
heatmap1 = ax1.pcolor(data1, cmap=plt.cm.RdYlGn)
```
這個熱力圖使用一系列的顏色來制作,這些顏色可以是任何東西到任何東西的范圍,顏色比例由我們使用的`cmap`生成。 你可以在這里找到顏色映射的所有選項。 我們將使用`RdYlGn`,它是一個顏色映射,低端為紅色,中間為黃色,較高部分為綠色,這將負相關表示為紅色,正相關為綠色,無關聯為黃色。 我們將添加一個邊欄,是個作為“比例尺”的顏色條:
```py
fig1.colorbar(heatmap1)
```
接下來,我們將設置我們的`x`和`y`軸刻度,以便我們知道哪個公司是哪個,因為現在我們只是繪制了數據:
```py
ax1.set_xticks(np.arange(data1.shape[1]) + 0.5, minor=False)
ax1.set_yticks(np.arange(data1.shape[0]) + 0.5, minor=False)
```
這樣做只是為我們創建刻度。 我們還沒有任何標簽。
現在我們添加:
```py
ax1.invert_yaxis()
ax1.xaxis.tick_top()
```
這會翻轉我們的`yaxis`,所以圖形更容易閱讀,因為`x`和`y`之間會有一些空格。 一般而言,matplotlib 會在圖的一端留下空間,因為這往往會使圖更容易閱讀,但在我們的情況下,卻沒有。 然后我們也把`xaxis`翻轉到圖的頂部,而不是傳統的底部,同樣使這個更像是相關表應該的樣子。 現在我們實際上將把公司名稱添加到當前沒有名字的刻度中:
```py
column_labels = df_corr.columns
row_labels = df_corr.index
ax1.set_xticklabels(column_labels)
ax1.set_yticklabels(row_labels)
```
在這里,我們可以使用兩邊完全相同的列表,因為`column_labels`和`row_lables`應該是相同的列表。 但是,對于所有的熱力圖而言,這并不總是正確的,所以我決定將其展示為,數據幀的任何熱力圖的正確方法。 最后:
```py
plt.xticks(rotation=90)
heatmap1.set_clim(-1,1)
plt.tight_layout()
#plt.savefig("correlations.png", dpi = (300))
plt.show()
```
我們旋轉`xticks`,這實際上是代碼本身,因為通常他們會超出區域。 我們在這里有超過 500 個標簽,所以我們要將他們旋轉 90 度,所以他們是垂直的。 這仍然是一個圖表,它太大了而看不清所有東西,但沒關系。 `heatmap1.set_clim(-1,1)`那一行只是告訴`colormap`,我們的范圍將從`-1`變為正`1`。應該已經是這種情況了,但是我們想確定一下。 沒有這一行,它應該仍然是你的數據集的最小值和最大值,所以它本來是非常接近的。
所以我們完成了! 到目前為止的函數:
```py
def visualize_data():
df = pd.read_csv('sp500_joined_closes.csv')
#df['AAPL'].plot()
#plt.show()
df_corr = df.corr()
print(df_corr.head())
df_corr.to_csv('sp500corr.csv')
data1 = df_corr.values
fig1 = plt.figure()
ax1 = fig1.add_subplot(111)
heatmap1 = ax1.pcolor(data1, cmap=plt.cm.RdYlGn)
fig1.colorbar(heatmap1)
ax1.set_xticks(np.arange(data1.shape[1]) + 0.5, minor=False)
ax1.set_yticks(np.arange(data1.shape[0]) + 0.5, minor=False)
ax1.invert_yaxis()
ax1.xaxis.tick_top()
column_labels = df_corr.columns
row_labels = df_corr.index
ax1.set_xticklabels(column_labels)
ax1.set_yticklabels(row_labels)
plt.xticks(rotation=90)
heatmap1.set_clim(-1,1)
plt.tight_layout()
#plt.savefig("correlations.png", dpi = (300))
plt.show()
visualize_data()
```
以及目前為止的完整代碼:
```py
import bs4 as bs
import datetime as dt
import matplotlib.pyplot as plt
from matplotlib import style
import numpy as np
import os
import pandas as pd
import pandas_datareader.data as web
import pickle
import requests
style.use('ggplot')
def save_sp500_tickers():
resp = requests.get('http://en.wikipedia.org/wiki/List_of_S%26P_500_companies')
soup = bs.BeautifulSoup(resp.text, 'lxml')
table = soup.find('table', {'class': 'wikitable sortable'})
tickers = []
for row in table.findAll('tr')[1:]:
ticker = row.findAll('td')[0].text
tickers.append(ticker)
with open("sp500tickers.pickle","wb") as f:
pickle.dump(tickers,f)
return tickers
def get_data_from_yahoo(reload_sp500=False):
if reload_sp500:
tickers = save_sp500_tickers()
else:
with open("sp500tickers.pickle","rb") as f:
tickers = pickle.load(f)
if not os.path.exists('stock_dfs'):
os.makedirs('stock_dfs')
start = dt.datetime(2000, 1, 1)
end = dt.datetime(2016, 12, 31)
for ticker in tickers:
# just in case your connection breaks, we'd like to save our progress!
if not os.path.exists('stock_dfs/{}.csv'.format(ticker)):
df = web.DataReader(ticker, "yahoo", start, end)
df.to_csv('stock_dfs/{}.csv'.format(ticker))
else:
print('Already have {}'.format(ticker))
def compile_data():
with open("sp500tickers.pickle","rb") as f:
tickers = pickle.load(f)
main_df = pd.DataFrame()
for count,ticker in enumerate(tickers):
df = pd.read_csv('stock_dfs/{}.csv'.format(ticker))
df.set_index('Date', inplace=True)
df.rename(columns={'Adj Close':ticker}, inplace=True)
df.drop(['Open','High','Low','Close','Volume'],1,inplace=True)
if main_df.empty:
main_df = df
else:
main_df = main_df.join(df, how='outer')
if count % 10 == 0:
print(count)
print(main_df.head())
main_df.to_csv('sp500_joined_closes.csv')
def visualize_data():
df = pd.read_csv('sp500_joined_closes.csv')
#df['AAPL'].plot()
#plt.show()
df_corr = df.corr()
print(df_corr.head())
df_corr.to_csv('sp500corr.csv')
data1 = df_corr.values
fig1 = plt.figure()
ax1 = fig1.add_subplot(111)
heatmap1 = ax1.pcolor(data1, cmap=plt.cm.RdYlGn)
fig1.colorbar(heatmap1)
ax1.set_xticks(np.arange(data1.shape[1]) + 0.5, minor=False)
ax1.set_yticks(np.arange(data1.shape[0]) + 0.5, minor=False)
ax1.invert_yaxis()
ax1.xaxis.tick_top()
column_labels = df_corr.columns
row_labels = df_corr.index
ax1.set_xticklabels(column_labels)
ax1.set_yticklabels(row_labels)
plt.xticks(rotation=90)
heatmap1.set_clim(-1,1)
plt.tight_layout()
#plt.savefig("correlations.png", dpi = (300))
plt.show()
visualize_data()
```
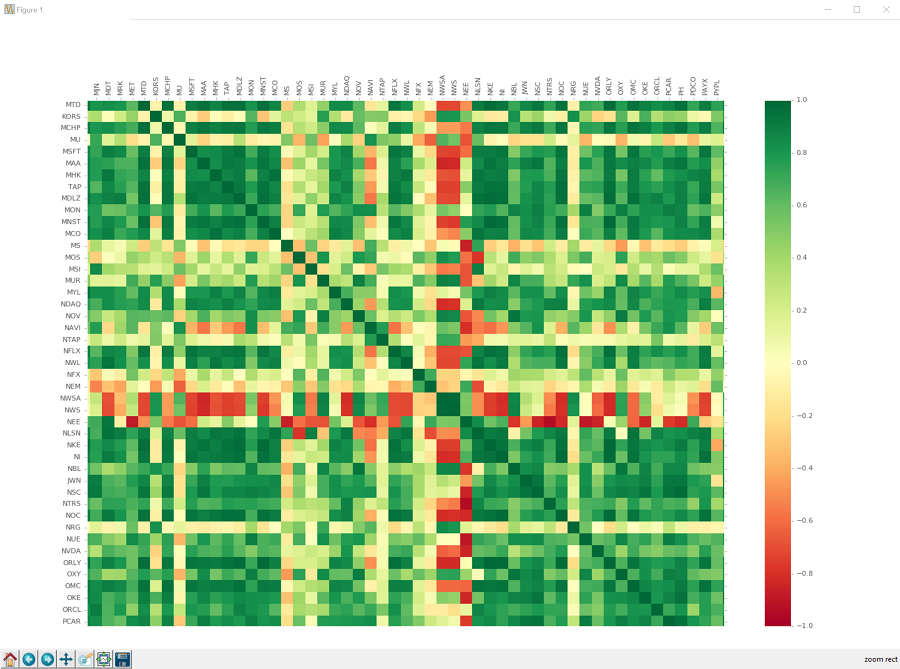
我們的勞動果實:

這是很大一個果實。
所以我們可以使用放大鏡來放大:

如果你單擊它,你可以單擊并拖動要放大的框。 這個圖表上的框很難看清楚,只知道它在那里。 點擊,拖動,釋放,你應該放大了,看到像這樣的東西:
你可以從這里移動,使用十字箭頭按鈕:
您也可以通過點擊主屏幕按鈕返回到原始的完整圖形。您也可以使用前進和后退按鈕“前進”和“后退”到前一個視圖。您可以通過點擊軟盤來保存它。我想知道我們使用軟盤的圖像來描繪保存東西,有多久了。多久之后人們完全不知道軟盤是什么?
好吧,看看相關性,我們可以看到有很多關系。毫不奇怪,大多數公司正相關。有相當多的公司與其他公司有很強的相關性,還有相當多的公司是非常負相關的。甚至有一些公司與大多數公司呈負相關。我們也可以看到有很多公司完全沒有關聯。機會就是,投資于一群長期以來沒有相關性的公司,將是一個多元化的合理方式,但我們現在還不知道。
不管怎樣,這個數據已經有很多關系了。人們必須懷疑,一臺機器是否能夠純粹依靠這些關系來識別和交易。我們可以輕松成為百萬富豪嗎?!我們至少可以試試!
## 九、處理數據,為機器學習做準備
歡迎閱讀 Python 金融教程系列的第 9 部分。在之前的教程中,我們介紹了如何拉取大量公司的股票價格數據,如何將這些數據合并為一個大型數據集,以及如何直觀地表示所有公司之間的一種關系。現在,我們將嘗試采用這些數據,并做一些機器學習!
我們的想法是,看看如果我們獲得所有當前公司的數據,并把這些數據扔給某種機器學習分類器,會發生什么。我們知道,隨著時間的推移,各個公司彼此有著不同的練習,所以,如果機器能夠識別并且擬合這些關系,那么我們可以從今天的價格變化中,預測明天會發生什么事情。咱們試試吧!
首先,所有機器學習都是接受“特征集”,并嘗試將其映射到“標簽”。無論我們是做 K 最近鄰居還是深度神經網絡學習,這都是一樣的。因此,我們需要將現有的數據轉換為特征集和標簽。
我們的特征可以是其他公司的價格,但是我們要說的是,特征是所有公司當天的價格變化。我們的標簽將是我們是否真的想買特定公司。假設我們正在考慮 Exxon(XOM)。我們要做的特征集是,考慮當天所有公司的百分比變化,這些都是我們的特征。我們的標簽將是 Exxon(XOM)在接下來的`x`天內漲幅是否超過`x`%,我們可以為`x`選擇任何我們想要的值。首先,假設一家公司在未來 7 天內價格上漲超過 2%,如果價格在這 7 天內下跌超過 2%,那么就賣出。
這也是我們可以比較容易做出的一個策略。如果算法說了買入,我們可以買,放置 2% 的止損(基本上告訴交易所,如果價格跌破這個數字/或者如果你做空公司,價格超過這個數字,那么退出我的位置)。否則,公司一旦漲了 2% 就賣掉,或者保守地在 1% 賣掉,等等。無論如何,你可以比較容易地從這個分類器建立一個策略。為了開始,我們需要為我們的訓練數據放入未來的價格。
我將繼續編寫我們的腳本。如果這對您是個問題,請隨時創建一個新文件并導入我們使用的函數。
目前為止的完整代碼:
```py
import bs4 as bs
import datetime as dt
import matplotlib.pyplot as plt
from matplotlib import style
import numpy as np
import os
import pandas as pd
import pandas_datareader.data as web
import pickle
import requests
style.use('ggplot')
def save_sp500_tickers():
resp = requests.get('http://en.wikipedia.org/wiki/List_of_S%26P_500_companies')
soup = bs.BeautifulSoup(resp.text, 'lxml')
table = soup.find('table', {'class': 'wikitable sortable'})
tickers = []
for row in table.findAll('tr')[1:]:
ticker = row.findAll('td')[0].text
tickers.append(ticker)
with open("sp500tickers.pickle","wb") as f:
pickle.dump(tickers,f)
return tickers
def get_data_from_yahoo(reload_sp500=False):
if reload_sp500:
tickers = save_sp500_tickers()
else:
with open("sp500tickers.pickle","rb") as f:
tickers = pickle.load(f)
if not os.path.exists('stock_dfs'):
os.makedirs('stock_dfs')
start = dt.datetime(2000, 1, 1)
end = dt.datetime(2016, 12, 31)
for ticker in tickers:
# just in case your connection breaks, we'd like to save our progress!
if not os.path.exists('stock_dfs/{}.csv'.format(ticker)):
df = web.DataReader(ticker, "yahoo", start, end)
df.to_csv('stock_dfs/{}.csv'.format(ticker))
else:
print('Already have {}'.format(ticker))
def compile_data():
with open("sp500tickers.pickle","rb") as f:
tickers = pickle.load(f)
main_df = pd.DataFrame()
for count,ticker in enumerate(tickers):
df = pd.read_csv('stock_dfs/{}.csv'.format(ticker))
df.set_index('Date', inplace=True)
df.rename(columns={'Adj Close':ticker}, inplace=True)
df.drop(['Open','High','Low','Close','Volume'],1,inplace=True)
if main_df.empty:
main_df = df
else:
main_df = main_df.join(df, how='outer')
if count % 10 == 0:
print(count)
print(main_df.head())
main_df.to_csv('sp500_joined_closes.csv')
def visualize_data():
df = pd.read_csv('sp500_joined_closes.csv')
#df['AAPL'].plot()
#plt.show()
df_corr = df.corr()
print(df_corr.head())
df_corr.to_csv('sp500corr.csv')
data1 = df_corr.values
fig1 = plt.figure()
ax1 = fig1.add_subplot(111)
heatmap1 = ax1.pcolor(data1, cmap=plt.cm.RdYlGn)
fig1.colorbar(heatmap1)
ax1.set_xticks(np.arange(data1.shape[1]) + 0.5, minor=False)
ax1.set_yticks(np.arange(data1.shape[0]) + 0.5, minor=False)
ax1.invert_yaxis()
ax1.xaxis.tick_top()
column_labels = df_corr.columns
row_labels = df_corr.index
ax1.set_xticklabels(column_labels)
ax1.set_yticklabels(row_labels)
plt.xticks(rotation=90)
heatmap1.set_clim(-1,1)
plt.tight_layout()
#plt.savefig("correlations.png", dpi = (300))
plt.show()
```
繼續,讓我們開始處理一些數據,這將幫助我們創建我們的標簽:
```py
def process_data_for_labels(ticker):
hm_days = 7
df = pd.read_csv('sp500_joined_closes.csv', index_col=0)
tickers = df.columns.values.tolist()
df.fillna(0, inplace=True)
```
這個函數接受一個參數:問題中的股票代碼。 每個模型將在一家公司上訓練。 接下來,我們想知道我們需要未來多少天的價格。 我們在這里選擇 7。 現在,我們將讀取我們過去保存的所有公司的收盤價的數據,獲取現有的代碼列表,現在我們將為缺失值數據填入 0。 這可能是你將來要改變的東西,但是現在我們將用 0 來代替。 現在,我們要抓取未來 7 天的百分比變化:
```py
for i in range(1,hm_days+1):
df['{}_{}d'.format(ticker,i)] = (df[ticker].shift(-i) - df[ticker]) / df[ticker]
```
這為我們的特定股票創建新的數據幀的列,使用字符串格式化創建自定義名稱。 我們獲得未來值的方式是使用`.shift`,這基本上會使列向上或向下移動。 在這里,我們移動一個負值,這將選取該列,如果你可以看到它,它會把這個列向上移動`i`行。 這給了我們未來值,我們可以計算百分比變化。
最后:
```py
df.fillna(0, inplace=True)
return tickers, df
```
我們在這里準備完了,我們將返回代碼和數據幀,并且我們正在創建一些特征集,我們的算法可以用它來嘗試擬合和發現關系。
我們的完整處理函數:
```py
def process_data_for_labels(ticker):
hm_days = 7
df = pd.read_csv('sp500_joined_closes.csv', index_col=0)
tickers = df.columns.values.tolist()
df.fillna(0, inplace=True)
for i in range(1,hm_days+1):
df['{}_{}d'.format(ticker,i)] = (df[ticker].shift(-i) - df[ticker]) / df[ticker]
df.fillna(0, inplace=True)
return tickers, df
```
在下一個教程中,我們將介紹如何創建我們的“標簽”。
## 十、十一、為機器學習標簽創建目標
歡迎閱讀 Python 金融系列教程的第 10 部分(和第 11 部分)。 在之前的教程中,我們開始構建我們的標簽,試圖使用機器學習和 Python 來投資。 在本教程中,我們將使用我們上一次教程的內容,在準備就緒時實際生成標簽。
目前為止的代碼:
```py
import bs4 as bs
import datetime as dt
import matplotlib.pyplot as plt
from matplotlib import style
import numpy as np
import os
import pandas as pd
import pandas_datareader.data as web
import pickle
import requests
style.use('ggplot')
def save_sp500_tickers():
resp = requests.get('http://en.wikipedia.org/wiki/List_of_S%26P_500_companies')
soup = bs.BeautifulSoup(resp.text, 'lxml')
table = soup.find('table', {'class': 'wikitable sortable'})
tickers = []
for row in table.findAll('tr')[1:]:
ticker = row.findAll('td')[0].text
tickers.append(ticker)
with open("sp500tickers.pickle","wb") as f:
pickle.dump(tickers,f)
return tickers
def get_data_from_yahoo(reload_sp500=False):
if reload_sp500:
tickers = save_sp500_tickers()
else:
with open("sp500tickers.pickle","rb") as f:
tickers = pickle.load(f)
if not os.path.exists('stock_dfs'):
os.makedirs('stock_dfs')
start = dt.datetime(2000, 1, 1)
end = dt.datetime(2016, 12, 31)
for ticker in tickers:
# just in case your connection breaks, we'd like to save our progress!
if not os.path.exists('stock_dfs/{}.csv'.format(ticker)):
df = web.DataReader(ticker, "yahoo", start, end)
df.to_csv('stock_dfs/{}.csv'.format(ticker))
else:
print('Already have {}'.format(ticker))
def compile_data():
with open("sp500tickers.pickle","rb") as f:
tickers = pickle.load(f)
main_df = pd.DataFrame()
for count,ticker in enumerate(tickers):
df = pd.read_csv('stock_dfs/{}.csv'.format(ticker))
df.set_index('Date', inplace=True)
df.rename(columns={'Adj Close':ticker}, inplace=True)
df.drop(['Open','High','Low','Close','Volume'],1,inplace=True)
if main_df.empty:
main_df = df
else:
main_df = main_df.join(df, how='outer')
if count % 10 == 0:
print(count)
print(main_df.head())
main_df.to_csv('sp500_joined_closes.csv')
def visualize_data():
df = pd.read_csv('sp500_joined_closes.csv')
#df['AAPL'].plot()
#plt.show()
df_corr = df.corr()
print(df_corr.head())
df_corr.to_csv('sp500corr.csv')
data1 = df_corr.values
fig1 = plt.figure()
ax1 = fig1.add_subplot(111)
heatmap1 = ax1.pcolor(data1, cmap=plt.cm.RdYlGn)
fig1.colorbar(heatmap1)
ax1.set_xticks(np.arange(data1.shape[1]) + 0.5, minor=False)
ax1.set_yticks(np.arange(data1.shape[0]) + 0.5, minor=False)
ax1.invert_yaxis()
ax1.xaxis.tick_top()
column_labels = df_corr.columns
row_labels = df_corr.index
ax1.set_xticklabels(column_labels)
ax1.set_yticklabels(row_labels)
plt.xticks(rotation=90)
heatmap1.set_clim(-1,1)
plt.tight_layout()
#plt.savefig("correlations.png", dpi = (300))
plt.show()
def process_data_for_labels(ticker):
hm_days = 7
df = pd.read_csv('sp500_joined_closes.csv', index_col=0)
tickers = df.columns.values.tolist()
df.fillna(0, inplace=True)
for i in range(1,hm_days+1):
df['{}_{}d'.format(ticker,i)] = (df[ticker].shift(-i) - df[ticker]) / df[ticker]
df.fillna(0, inplace=True)
return tickers, df
```
現在我們要創建一個創建標簽的函數。 我們在這里有很多選擇。 你可能希望有一些東西,它們指導購買,出售或持有,或者只是買或賣。 我要讓我們實現前者。 基本上,如果價格在未來 7 天上漲超過 2%,那么我們會說這是買入。 如果在接下來的 7 天內下跌超過 2%,這是賣出。 如果這兩者都不是,那么它就沒有足夠的動力,我們將會堅持我們的位置。 如果我們有這個公司的股份,我們什么都不做,我們堅持我們的位置。 如果我們沒有該公司的股份,我們什么都不做,我們只是等待。 我們的函數是:
```py
def buy_sell_hold(*args):
cols = [c for c in args]
requirement = 0.02
for col in cols:
if col > requirement:
return 1
if col < -requirement:
return -1
return 0
```
我們在這里使用`args`,所以我們可以在這里接受任意數量的列。 這里的想法是我們要把這個函數映射到 Pandas `DataFrame`的列,這個列將成為我們的“標簽”。 `-1`是賣出,0 是持有,1 是買入。 `*args`將是那些未來的價格變化列,我們感興趣的是,是否我們能看到超過 2% 的雙向移動。 請注意,這不是一個完美的函數。 例如,價格可能上漲 2%,然后下降 2%,我們可能沒有為此做好準備,但現在就這樣了。
那么,讓我們來生成我們的特征和標簽! 對于這個函數,我們將添加下面的導入:
```py
from collections import Counter
```
這將讓我們在我們的數據集和算法預測中,看到類別的分布。 我們不想將高度不平衡的數據集扔給機器學習分類器,我們也想看看我們的分類器是否只預測一個類別。 我們下一函數是:
```py
def extract_featuresets(ticker):
tickers, df = process_data_for_labels(ticker)
df['{}_target'.format(ticker)] = list(map( buy_sell_hold,
df['{}_1d'.format(ticker)],
df['{}_2d'.format(ticker)],
df['{}_3d'.format(ticker)],
df['{}_4d'.format(ticker)],
df['{}_5d'.format(ticker)],
df['{}_6d'.format(ticker)],
df['{}_7d'.format(ticker)] ))
```
這個函數將接受任何股票代碼,創建所需的數據集,并創建我們的“目標”列,這是我們的標簽。 根據我們的函數和我們當如的列,目標列將為每行設置一個`-1`,`0`或`1`。 現在,我們可以得到分布:
```py
vals = df['{}_target'.format(ticker)].values.tolist()
str_vals = [str(i) for i in vals]
print('Data spread:',Counter(str_vals))
```
清理我們的數據:
```py
df.fillna(0, inplace=True)
df = df.replace([np.inf, -np.inf], np.nan)
df.dropna(inplace=True)
```
我們可能有一些完全丟失的數據,我們將用 0 代替。接下來,我們可能會有一些無限的數據,特別是如果我們計算了從 0 到任何東西的百分比變化。 我們將把無限值轉換為`NaN`,然后我們將放棄`NaN`。 我們幾乎已經準備好了,但現在我們的“特征”就是當天股票的價格。 只是靜態的數字,真的沒有什么可說的。 相反,更好的指標是當天每個公司的百分比變化。 這里的想法是,有些公司的價格會先于其他公司變化,而我們也可能從中獲利。 我們會將股價轉換為百分比變化:
```py
df_vals = df[[ticker for ticker in tickers]].pct_change()
df_vals = df_vals.replace([np.inf, -np.inf], 0)
df_vals.fillna(0, inplace=True)
```
再次,小心無限的數字,然后填充其他缺失的數據,現在,最后,我們準備創建我們的特征和標簽:
```py
X = df_vals.values
y = df['{}_target'.format(ticker)].values
return X,y,df
```
大寫字母`X`包含我們的特征集(SP500 中每個公司的每日變化百分比)。 小寫字母`y`是我們的“目標”或我們的“標簽”。 基本上我們試圖將我們的特征集映射到它。
好吧,我們有了特征和標簽,我們準備做一些機器學習,這將在下一個教程中介紹。
## 十二、SP500 上的機器學習
歡迎閱讀 Python 金融系列教程的第 12 部分。 在之前的教程中,我們介紹了如何獲取數據并創建特征集和標簽,然后我們可以將其扔給機器學習算法,希望它能學會將一家公司的現有價格變化關系映射到未來的價格變化。
在我們開始之前,我們目前為止的起始代碼到:
```py
import bs4 as bs
from collections import Counter
import datetime as dt
import matplotlib.pyplot as plt
from matplotlib import style
import numpy as np
import os
import pandas as pd
import pandas_datareader.data as web
import pickle
import requests
style.use('ggplot')
def save_sp500_tickers():
resp = requests.get('http://en.wikipedia.org/wiki/List_of_S%26P_500_companies')
soup = bs.BeautifulSoup(resp.text, 'lxml')
table = soup.find('table', {'class': 'wikitable sortable'})
tickers = []
for row in table.findAll('tr')[1:]:
ticker = row.findAll('td')[0].text
tickers.append(ticker)
with open("sp500tickers.pickle","wb") as f:
pickle.dump(tickers,f)
return tickers
def get_data_from_yahoo(reload_sp500=False):
if reload_sp500:
tickers = save_sp500_tickers()
else:
with open("sp500tickers.pickle","rb") as f:
tickers = pickle.load(f)
if not os.path.exists('stock_dfs'):
os.makedirs('stock_dfs')
start = dt.datetime(2000, 1, 1)
end = dt.datetime(2016, 12, 31)
for ticker in tickers:
# just in case your connection breaks, we'd like to save our progress!
if not os.path.exists('stock_dfs/{}.csv'.format(ticker)):
df = web.DataReader(ticker, "yahoo", start, end)
df.to_csv('stock_dfs/{}.csv'.format(ticker))
else:
print('Already have {}'.format(ticker))
def compile_data():
with open("sp500tickers.pickle","rb") as f:
tickers = pickle.load(f)
main_df = pd.DataFrame()
for count,ticker in enumerate(tickers):
df = pd.read_csv('stock_dfs/{}.csv'.format(ticker))
df.set_index('Date', inplace=True)
df.rename(columns={'Adj Close':ticker}, inplace=True)
df.drop(['Open','High','Low','Close','Volume'],1,inplace=True)
if main_df.empty:
main_df = df
else:
main_df = main_df.join(df, how='outer')
if count % 10 == 0:
print(count)
print(main_df.head())
main_df.to_csv('sp500_joined_closes.csv')
def visualize_data():
df = pd.read_csv('sp500_joined_closes.csv')
#df['AAPL'].plot()
#plt.show()
df_corr = df.corr()
print(df_corr.head())
df_corr.to_csv('sp500corr.csv')
data1 = df_corr.values
fig1 = plt.figure()
ax1 = fig1.add_subplot(111)
heatmap1 = ax1.pcolor(data1, cmap=plt.cm.RdYlGn)
fig1.colorbar(heatmap1)
ax1.set_xticks(np.arange(data1.shape[1]) + 0.5, minor=False)
ax1.set_yticks(np.arange(data1.shape[0]) + 0.5, minor=False)
ax1.invert_yaxis()
ax1.xaxis.tick_top()
column_labels = df_corr.columns
row_labels = df_corr.index
ax1.set_xticklabels(column_labels)
ax1.set_yticklabels(row_labels)
plt.xticks(rotation=90)
heatmap1.set_clim(-1,1)
plt.tight_layout()
#plt.savefig("correlations.png", dpi = (300))
plt.show()
def process_data_for_labels(ticker):
hm_days = 7
df = pd.read_csv('sp500_joined_closes.csv', index_col=0)
tickers = df.columns.values.tolist()
df.fillna(0, inplace=True)
for i in range(1,hm_days+1):
df['{}_{}d'.format(ticker,i)] = (df[ticker].shift(-i) - df[ticker]) / df[ticker]
df.fillna(0, inplace=True)
return tickers, df
def buy_sell_hold(*args):
cols = [c for c in args]
requirement = 0.02
for col in cols:
if col > requirement:
return 1
if col < -requirement:
return -1
return 0
def extract_featuresets(ticker):
tickers, df = process_data_for_labels(ticker)
df['{}_target'.format(ticker)] = list(map( buy_sell_hold,
df['{}_1d'.format(ticker)],
df['{}_2d'.format(ticker)],
df['{}_3d'.format(ticker)],
df['{}_4d'.format(ticker)],
df['{}_5d'.format(ticker)],
df['{}_6d'.format(ticker)],
df['{}_7d'.format(ticker)] ))
vals = df['{}_target'.format(ticker)].values.tolist()
str_vals = [str(i) for i in vals]
print('Data spread:',Counter(str_vals))
df.fillna(0, inplace=True)
df = df.replace([np.inf, -np.inf], np.nan)
df.dropna(inplace=True)
df_vals = df[[ticker for ticker in tickers]].pct_change()
df_vals = df_vals.replace([np.inf, -np.inf], 0)
df_vals.fillna(0, inplace=True)
X = df_vals.values
y = df['{}_target'.format(ticker)].values
return X,y,df
```
我們打算添加以下導入:
```py
from sklearn import svm, cross_validation, neighbors
from sklearn.ensemble import VotingClassifier, RandomForestClassifier
```
Sklearn 是一個機器學習框架。 如果你沒有它,請確保你下載它:`pip install scikit-learn`。`svm import`是支持向量機,`cross_validation`可以讓我們輕松地創建打亂的訓練和測試樣本,`neighbors`是 K 最近鄰。 然后,我們引入了`VotingClassifier`和`RandomForestClassifier`。投票分類器正是它聽起來的樣子。 基本上,這是一個分類器,它可以讓我們結合許多分類器,并允許他們分別對他們認為的特征集的類別進行“投票”。 隨機森林分類器只是另一個分類器。 我們將在投票分類器中使用三個分類器。
我們現在準備做一些機器學習,所以讓我們開始我們的函數:
```py
def do_ml(ticker):
X, y, df = extract_featuresets(ticker)
```
我們已經有了我們的特征集和標簽,現在我們想把它們打亂,訓練,然后測試:
```py
X_train, X_test, y_train, y_test = cross_validation.train_test_split(X,
y,
test_size=0.25)
```
這對我們來說是在打亂我們的數據(所以它沒有任何特定的順序),然后為我們創建訓練和測試樣本。 我們不想在我們相同的訓練數據上“測試”這個算法。 如果我們這樣做了,我們可能會比現實中做得更好。 我們想要在從來沒有見過的數據上測試算法,看看我們是否真的有了一個可行的模型。
現在我們可以從我們想要的任何分類器中進行選擇,現在讓我們選擇 K 最近鄰:
```py
clf = neighbors.KNeighborsClassifier()
```
現在我們可以在我們的數據上`fit`(訓練)分類器:
```py
clf.fit(X_train, y_train)
```
這行會接受我們的`X`數據,擬合我們的`Y`數據,對于我們擁有的每一對`X`和`Y`。 一旦完成,我們可以測試它:
```py
confidence = clf.score(X_test, y_test)
```
這將需要一些特征集`X_test`來預測,并查看它是否與我們的標簽`y_test`相匹配。 它會以小數形式返回給我們百分比精度,其中`1.0`是 100%,`0.1`是 10% 準確。 現在我們可以輸出一些更有用的信息:
```py
print('accuracy:',confidence)
predictions = clf.predict(X_test)
print('predicted class counts:',Counter(predictions))
print()
print()
```
這將告訴我們準確性是什么,然后我們可以得到`X_testdata`的準確度,然后輸出分布(使用`Counter`),所以我們可以看到我們的模型是否只是對一個類進行分類,這是很容易發生的事情。
如果這個模型確實是成功的,我們可以用`pickle`保存它,并隨時加載它,為它提供一些特征集,并用`clf.predict`得到一個預測結果,這將從單個特征集預測單個值, 從特征集列表中預測值列表。
好的,我們已經準備好了! 我們的目標是什么? 隨機挑選的東西應該是 33% 左右,因為我們在理論上總共有三選擇,但實際上我們的模型是不可能真正平衡的。 讓我們看一些例子,然后運行:
```py
do_ml('XOM')
do_ml('AAPL')
do_ml('ABT')
```
```
Data spread: Counter({'1': 1713, '-1': 1456, '0': 1108})
accuracy: 0.375700934579
predicted class counts: Counter({0: 404, -1: 393, 1: 273})
Data spread: Counter({'1': 2098, '-1': 1830, '0': 349})
accuracy: 0.4
predicted class counts: Counter({-1: 644, 1: 339, 0: 87})
Data spread: Counter({'1': 1690, '-1': 1483, '0': 1104})
accuracy: 0.33738317757
predicted class counts: Counter({-1: 383, 0: 372, 1: 315})
```
所以這些都比 33% 好,但是訓練數據也不是很完美。 例如,我們可以看看第一個:
```
Data spread: Counter({'1': 1713, '-1': 1456, '0': 1108})
accuracy: 0.375700934579
predicted class counts: Counter({0: 404, -1: 393, 1: 273})
```
在這種情況下,如果模型只預測“買不買”? 這應該是 1,713 正確比上 4,277,這實際上是比我們得到的更好的分數。 那另外兩個呢? 第二個是 AAPL,如果只是預測購買,至少在訓練數據上是 49%。 如果只是在訓練數據上預測購買與否,ABT 的準確率為 37%。
所以,雖然我們的表現比 33% 好,但目前還不清楚這種模型是否比只說“購買”更好。 在實際交易中,這一切都可以改變。 例如,如果這種模型說了某件事是買入的話,期望在 7 天內上漲 2%,但是直到 8 天才會出現 2% 的漲幅,并且,該算法一直說買入或者 持有,那么這個模型就會受到懲罰。 在實際交易中,這樣做還是可以的。 如果這個模型結果非常準確,情況也是如此。 實際上,交易模型完全可以是完全不同的東西。
接下來,讓我們嘗試一下投票分類器。 所以,不是`clf = neighbors.KNeighborsClassifier()`,我們這樣做:
```py
clf = VotingClassifier([('lsvc',svm.LinearSVC()),
('knn',neighbors.KNeighborsClassifier()),
('rfor',RandomForestClassifier())])
```
新的輸出:
```py
Data spread: Counter({'1': 1713, '-1': 1456, '0': 1108})
accuracy: 0.379439252336
predicted class counts: Counter({-1: 487, 1: 417, 0: 166})
Data spread: Counter({'1': 2098, '-1': 1830, '0': 349})
accuracy: 0.471028037383
predicted class counts: Counter({1: 616, -1: 452, 0: 2})
Data spread: Counter({'1': 1690, '-1': 1483, '0': 1104})
accuracy: 0.378504672897
predicted class counts: Counter({-1: 524, 1: 394, 0: 152})
```
在所有股票上,我們都有改進! 這很好看。 我們還特別注意,使用所有算法的默認值。 這些算法中的每一個都有相當多的參數,我們可以花一些時間來調整,來獲得更高的效果,并且至少可以打敗“對一切東西都預測買入”。 也就是說,機器學習是一個巨大的話題,需要花費幾個月時間才能講完所有東西。 如果你想自己學習更多的算法,以便你可以調整它們,看看機器學習系列教程。 我們涵蓋了一堆機器學習算法,它們背后是如何工作的,如何應用它們,然后如何使用原始的 Python 自己制作它們。 在你完成整個系列課程的時候,你應該能夠很好地配置機器學習來應對各種挑戰。
目前為止的所有代碼:
```py
import bs4 as bs
from collections import Counter
import datetime as dt
import matplotlib.pyplot as plt
from matplotlib import style
import numpy as np
import os
import pandas as pd
import pandas_datareader.data as web
import pickle
import requests
from sklearn import svm, cross_validation, neighbors
from sklearn.ensemble import VotingClassifier, RandomForestClassifier
style.use('ggplot')
def save_sp500_tickers():
resp = requests.get('http://en.wikipedia.org/wiki/List_of_S%26P_500_companies')
soup = bs.BeautifulSoup(resp.text, 'lxml')
table = soup.find('table', {'class': 'wikitable sortable'})
tickers = []
for row in table.findAll('tr')[1:]:
ticker = row.findAll('td')[0].text
tickers.append(ticker)
with open("sp500tickers.pickle","wb") as f:
pickle.dump(tickers,f)
return tickers
def get_data_from_yahoo(reload_sp500=False):
if reload_sp500:
tickers = save_sp500_tickers()
else:
with open("sp500tickers.pickle","rb") as f:
tickers = pickle.load(f)
if not os.path.exists('stock_dfs'):
os.makedirs('stock_dfs')
start = dt.datetime(2000, 1, 1)
end = dt.datetime(2016, 12, 31)
for ticker in tickers:
# just in case your connection breaks, we'd like to save our progress!
if not os.path.exists('stock_dfs/{}.csv'.format(ticker)):
df = web.DataReader(ticker, "yahoo", start, end)
df.to_csv('stock_dfs/{}.csv'.format(ticker))
else:
print('Already have {}'.format(ticker))
def compile_data():
with open("sp500tickers.pickle","rb") as f:
tickers = pickle.load(f)
main_df = pd.DataFrame()
for count,ticker in enumerate(tickers):
df = pd.read_csv('stock_dfs/{}.csv'.format(ticker))
df.set_index('Date', inplace=True)
df.rename(columns={'Adj Close':ticker}, inplace=True)
df.drop(['Open','High','Low','Close','Volume'],1,inplace=True)
if main_df.empty:
main_df = df
else:
main_df = main_df.join(df, how='outer')
if count % 10 == 0:
print(count)
print(main_df.head())
main_df.to_csv('sp500_joined_closes.csv')
def visualize_data():
df = pd.read_csv('sp500_joined_closes.csv')
#df['AAPL'].plot()
#plt.show()
df_corr = df.corr()
print(df_corr.head())
df_corr.to_csv('sp500corr.csv')
data1 = df_corr.values
fig1 = plt.figure()
ax1 = fig1.add_subplot(111)
heatmap1 = ax1.pcolor(data1, cmap=plt.cm.RdYlGn)
fig1.colorbar(heatmap1)
ax1.set_xticks(np.arange(data1.shape[1]) + 0.5, minor=False)
ax1.set_yticks(np.arange(data1.shape[0]) + 0.5, minor=False)
ax1.invert_yaxis()
ax1.xaxis.tick_top()
column_labels = df_corr.columns
row_labels = df_corr.index
ax1.set_xticklabels(column_labels)
ax1.set_yticklabels(row_labels)
plt.xticks(rotation=90)
heatmap1.set_clim(-1,1)
plt.tight_layout()
#plt.savefig("correlations.png", dpi = (300))
plt.show()
def process_data_for_labels(ticker):
hm_days = 7
df = pd.read_csv('sp500_joined_closes.csv', index_col=0)
tickers = df.columns.values.tolist()
df.fillna(0, inplace=True)
for i in range(1,hm_days+1):
df['{}_{}d'.format(ticker,i)] = (df[ticker].shift(-i) - df[ticker]) / df[ticker]
df.fillna(0, inplace=True)
return tickers, df
def buy_sell_hold(*args):
cols = [c for c in args]
requirement = 0.02
for col in cols:
if col > requirement:
return 1
if col < -requirement:
return -1
return 0
def extract_featuresets(ticker):
tickers, df = process_data_for_labels(ticker)
df['{}_target'.format(ticker)] = list(map( buy_sell_hold,
df['{}_1d'.format(ticker)],
df['{}_2d'.format(ticker)],
df['{}_3d'.format(ticker)],
df['{}_4d'.format(ticker)],
df['{}_5d'.format(ticker)],
df['{}_6d'.format(ticker)],
df['{}_7d'.format(ticker)] ))
vals = df['{}_target'.format(ticker)].values.tolist()
str_vals = [str(i) for i in vals]
print('Data spread:',Counter(str_vals))
df.fillna(0, inplace=True)
df = df.replace([np.inf, -np.inf], np.nan)
df.dropna(inplace=True)
df_vals = df[[ticker for ticker in tickers]].pct_change()
df_vals = df_vals.replace([np.inf, -np.inf], 0)
df_vals.fillna(0, inplace=True)
X = df_vals.values
y = df['{}_target'.format(ticker)].values
return X,y,df
def do_ml(ticker):
X, y, df = extract_featuresets(ticker)
X_train, X_test, y_train, y_test = cross_validation.train_test_split(X,
y,
test_size=0.25)
#clf = neighbors.KNeighborsClassifier()
clf = VotingClassifier([('lsvc',svm.LinearSVC()),
('knn',neighbors.KNeighborsClassifier()),
('rfor',RandomForestClassifier())])
clf.fit(X_train, y_train)
confidence = clf.score(X_test, y_test)
print('accuracy:',confidence)
predictions = clf.predict(X_test)
print('predicted class counts:',Counter(predictions))
print()
print()
return confidence
# examples of running:
do_ml('XOM')
do_ml('AAPL')
do_ml('ABT')
```
你也可以在所有代碼上運行它:
```py
from statistics import mean
with open("sp500tickers.pickle","rb") as f:
tickers = pickle.load(f)
accuracies = []
for count,ticker in enumerate(tickers):
if count%10==0:
print(count)
accuracy = do_ml(ticker)
accuracies.append(accuracy)
print("{} accuracy: {}. Average accuracy:{}".format(ticker,accuracy,mean(accuracies)))
```
這將需要一段時間。 我繼續做下去,結果平均準確率為 46.279%。 不錯,但是從我這里看,結果對于任何形式的策略仍然是可疑的。
在接下來的教程中,我們將深入測試交易策略。
## 十三、使用 Quantopian 測試交易策略
歡迎閱讀 Python 金融系列教程的第 13 部分。在本教程中,我們將開始談論策略回測。回測領域和正確執行的要求是相當大的。基本上,我們需要創建一個系統,接受歷史價格數據并在該環境中模擬交易,然后給我們結果。這聽起來可能很簡單,但為了分析策略,我們需要跟蹤一系列指標,比如我們賣出什么,什么時候交易,我們的 Beta 和 Alpha 是什么,以及其他指標如 drawdown,夏普比,波動率,杠桿等等。除此之外,我們通常希望能夠看到所有這些。所以,我們可以自己寫所有這些,也可以用一個平臺來幫助我們...
這就是為什么我們要介紹 Quantopian,這是一個平臺,可以讓我們輕松地使用 Python 編寫和回測交易策略。
Quantopian 所做的是,在 Python 的 Zipline 回測庫之上增加了一個 GUI 層,也帶有大量的數據源,其中很多都是完全免費的。如果您符合特定標準,您還可以通過將您的策略授權給他們,從 Quantopian 獲得資金。一般來說,`-0.3`到`+0.3`之間的 β 值是一個很好的起點,但是您還需要有其他健康的指標來競爭。稍后再介紹一下 Quantopian 的基礎知識。由于 Quantopian 主要由 Zipline,Alphalens 和 Pyfolio 等開源庫支持,如果您愿意,還可以在本地運行類似 Quantopian 的平臺。我發現大多數人都對此感興趣,來保持其算法的私密性。 Quantopian 不會查看您的算法,除非您授予他們權限,而社區只有在您分享算法時才會看到您的算法。我強烈建議你把自己和 Quantopian 的關系看作是一種合作關系,而不是競爭關系。如果您想出了一些高質量的策略,Quantopian 非常樂意與您合作,并且用資金投資您。在這種關系中,Quantopian 將平臺,資金和其他專家帶到這個領域來幫助你,在我看來這是一個相當不錯的交易。
首先,前往`quantopian.com`,如果你沒有帳戶就創建一個,并登錄。隨意點一點鼠標。 Quantopian 社區論壇是吸收一些知識的好地方。 Quantopian 也經常舉辦帶現金獎勵的比賽。我們將從算法開始。到了那里,選擇藍色的“新算法”按鈕。現在,我們將把我們大部分時間花在兩個地方,這可以在“我的代碼”按鈕下找到。首先,我們將訪問算法,并使用藍色的“新算法”按鈕創建一個新的算法。
當你創建算法時,你應該被帶到你的實時編輯算法頁面,并帶有克隆的算法,看起來像這樣(除了彩色框),以及 UI 的一些可能的更改。
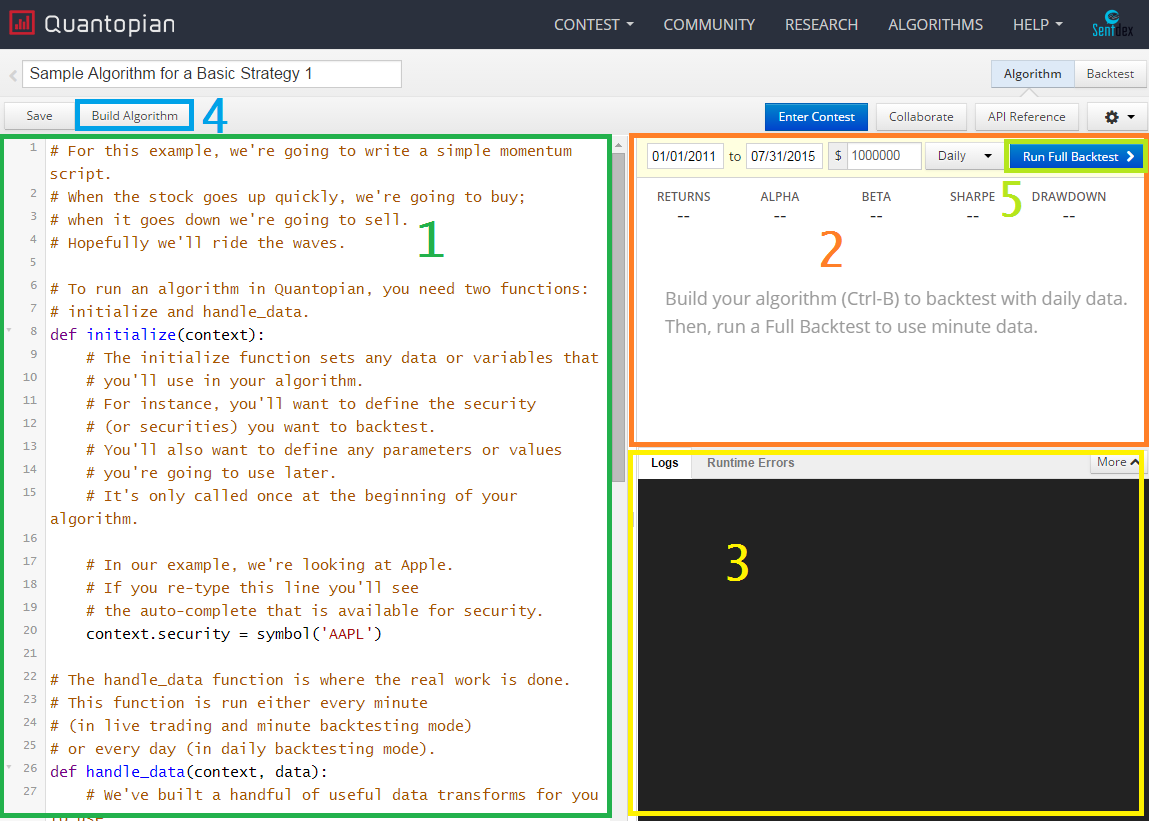
Python編輯器 - 這是您為算法編寫 Python 邏輯的地方。
構建算法結果 - 當您構建算法時,圖形結果將在這里出現。
日志/錯誤輸出 - 任何控制臺輸出/日志信息將在這里。 您的程序通常會輸出各種文本來調試,或者只是為了獲取更多信息。
構建算法 - 使用它來快速測試你寫的東西。 結果不會被保存,但是您可以在“內置算法結果”部分看到結果。
完整的回測 - 這將根據您當前的算法運行完整的回測。 完整的回測會提供更多分析,結果將被保存,并且生成這些結果的算法也會被保存,所以您可以返回去瀏覽回測,并查看生成特定結果的具體代碼。
起始示例代碼如下所示:
```py
"""
This is a template algorithm on Quantopian for you to adapt and fill in.
"""
from quantopian.algorithm import attach_pipeline, pipeline_output
from quantopian.pipeline import Pipeline
from quantopian.pipeline.data.builtin import USEquityPricing
from quantopian.pipeline.factors import AverageDollarVolume
def initialize(context):
"""
Called once at the start of the algorithm.
"""
# Rebalance every day, 1 hour after market open.
schedule_function(my_rebalance, date_rules.every_day(), time_rules.market_open(hours=1))
# Record tracking variables at the end of each day.
schedule_function(my_record_vars, date_rules.every_day(), time_rules.market_close())
# Create our dynamic stock selector.
attach_pipeline(make_pipeline(), 'my_pipeline')
def make_pipeline():
"""
A function to create our dynamic stock selector (pipeline). Documentation on
pipeline can be found here: https://www.quantopian.com/help#pipeline-title
"""
# Create a dollar volume factor.
dollar_volume = AverageDollarVolume(window_length=1)
# Pick the top 1% of stocks ranked by dollar volume.
high_dollar_volume = dollar_volume.percentile_between(99, 100)
pipe = Pipeline(
screen = high_dollar_volume,
columns = {
'dollar_volume': dollar_volume
}
)
return pipe
def before_trading_start(context, data):
"""
Called every day before market open.
"""
context.output = pipeline_output('my_pipeline')
# These are the securities that we are interested in trading each day.
context.security_list = context.output.index
def my_assign_weights(context, data):
"""
Assign weights to securities that we want to order.
"""
pass
def my_rebalance(context,data):
"""
Execute orders according to our schedule_function() timing.
"""
pass
def my_record_vars(context, data):
"""
Plot variables at the end of each day.
"""
pass
def handle_data(context,data):
"""
Called every minute.
"""
pass
```
這很好,但是可能還差一點才能開始。如果您的帳戶是新的,Quantopian 還提供了一些示例算法。隨意查看一下,但你可能會發現他們令人困惑。每個算法中只需要兩個函數:`initialize`和`handle_data`。初始化函數在腳本開始時運行一次。您將使用它來設置全局,例如規則,稍后使用的函數以及各種參數。接下來是`handle_data`函數,在市場數據上每分鐘運行一次。
讓我們編寫我自己的簡單策略來熟悉 Quantopian。我們將要實現一個簡單的移動均值交叉策略,看看它是如何實現的。
如果你不熟悉移動均值,他們所做的就是獲取一定數量的“窗口”數據。在每日價格的情況下,一個窗口將是一天。如果你計算 20 移動均值,這意味著 20 日均值。從這里來看,我們假設你有 20 移動均值和 50 移動均值。在一個圖上繪制它可能看起來像這樣:
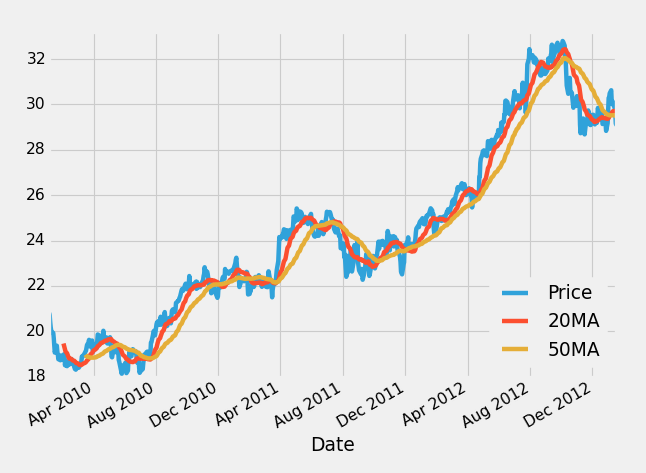
在這里,藍線是股價,紅線是 20 移動均值,黃線是 50 移動均值。這個想法是,20 個移動均值反應更快,當它移動到 50 移動均值上面時,這意味著價格可能會上漲,我們可能要投資。相反,如果 20 移動均值跌到 50 移動平均線下面,這可能意味著價格正在下降,我們可能要么出售或投資,甚至賣空公司,這是你打賭的地方。
就我們的目的而言,讓我們在 2015 年 10 月 7 日至 2016 年 10 月 7 日之間,對蘋果公司(AAPL)應用移動均值交叉策略。在此期間,AAPL 股價下跌,隨后上漲,凈變化很小。我們的交叉策略應該隨著價格的下跌而保持遠離或者做空(押注),然后在價格上漲的時候撲上來。做空公司需要向其他人借入股票,然后出售,然后幾天之后再重新買入股份。你的希望是股價下跌,你重新買回會便宜得多,并將股份還給原來的所有者,賺取差價。首先,我們來構建初始化方法:
```py
def initialize(context):
context.aapl = sid(24)
```
現在,我們只是要定義我們的蘋果股票。如果你真的開始輸入`sid(`,Quantopian 有很好的自動補全功能,你可以開始輸入公司名稱或代碼來找到他們的`sid`。使用`sid`的原因是,因為公司代碼可以在一段時間內改變。這是一種方法,確保你得到你想要得到的代碼,你也可以使用`symbol()`來使用代碼,并且讓你的代碼更容易閱讀,但這不推薦,因為股票代碼可以改變。
每次用 Zipline 或 Quantopian 創建算法時,都需要有`initialize`和`handle_data`方法。
初始化方法在算法啟動時運行一次(或者如果您正在實時運行算法,則每天運行一次)。 `handle_data`每分鐘運行一次。
在我們的初始化方法中,我們傳遞這個上下文參數。上下文是一個 Python 字典,我們將使用它來跟蹤,我們將全局變量用于什么。簡而言之,上下文變量用于跟蹤我們當前的投資環境,例如我們的投資組合和現金。
接下來,我們仍然需要我們的`handle_data`函數。該函數將`context `和`data`作為參數。
上下文參數已解釋了,數據變量用于跟蹤實際投資組合之外的環境。它跟蹤股票價格和其他我們可能投資的公司的信息,但是他們是我們正在跟蹤的公司。
`handle_data`函數的開頭:
```py
def handle_data(context,data):
# prices for aapl for the last 50 days, in 1 day intervals
hist = data.history(context.aapl,'price', 50, '1d')
```
我們可以使用`.history`方法,獲取過去的 50 天內蘋果公司的歷史價格,間隔為 1 天。 現在我們可以執行:
```py
# mean of the entire 200 day history
sma_50 = hist.mean()
# mean of just the last 50 days
sma_20 = hist[-20:].mean()
```
`sma_50`值就是我們剛剛拉取的歷史數據的均值。 `sma_20`是數據的最后 20 天。 請注意,這包含在`handle_data`方法中,該方法在每個周期運行,所以我們只需要跟蹤 50 和 20 簡單移動均值每天的值。
在下一個教程中,我們將討論下訂單。
## 十四、使用 Quantopian 下達交易訂單
歡迎閱讀 Python 金融系列教程的第 14 部分,使用 Quantopian。 在本教程中,我們將介紹如何實際下單(股票/賣出/做空)。
到目前為止,我們有以下代碼:
```py
def initialize(context):
context.aapl = sid(24)
def handle_data(context,data):
# prices for aapl for the last 50 days, in 1 day intervals
hist = data.history(context.aapl,'price', 50, '1d')
# mean of the entire 50 day history
sma_50 = hist.mean()
# mean of just the last 50 days
sma_20 = hist[-20:].mean()
```
我們到目前為止所做的,定義了什么是`context.aapl`,然后我們抓取了 AAPL 的歷史價格,并且使用這些價格生成了一些代碼,在每個時間間隔計算 50 和 20 簡單移動均值。 我們的計劃是制定一個簡單的移動均值交叉策略,我們幾乎準備完畢了。 邏輯應該簡單:如果 20SMA 大于 50SMA,那么價格在上漲,我們想在這時候買入! 如果 20SMA 低于 50SMA,那么價格將下跌,我們想做空這個公司(下注)。 讓我們建立一個訂單系統來反映這一點:
```py
if sma_20 > sma_50:
order_target_percent(context.aapl, 1.0)
elif sma_20 < sma_50:
order_target_percent(context.aapl, -1.0)
```
`order_target_percent`函數用于讓我們將一定比例的投資組合投資到一家公司。 在這種情況下,我們唯一考慮的公司是 Apple(AAPL),所以我們使用了 1.0(100%)。 下單有很多方法,這只是其中的一個。 我們可以做市場訂單,訂特定的金額,訂百分比,訂目標價值,當然也可以取消未成交的訂單。 在這種情況下,我們期望在每一步都簡單地買入/賣出 100% 的股份。 如果我們運行它,我們會得到:
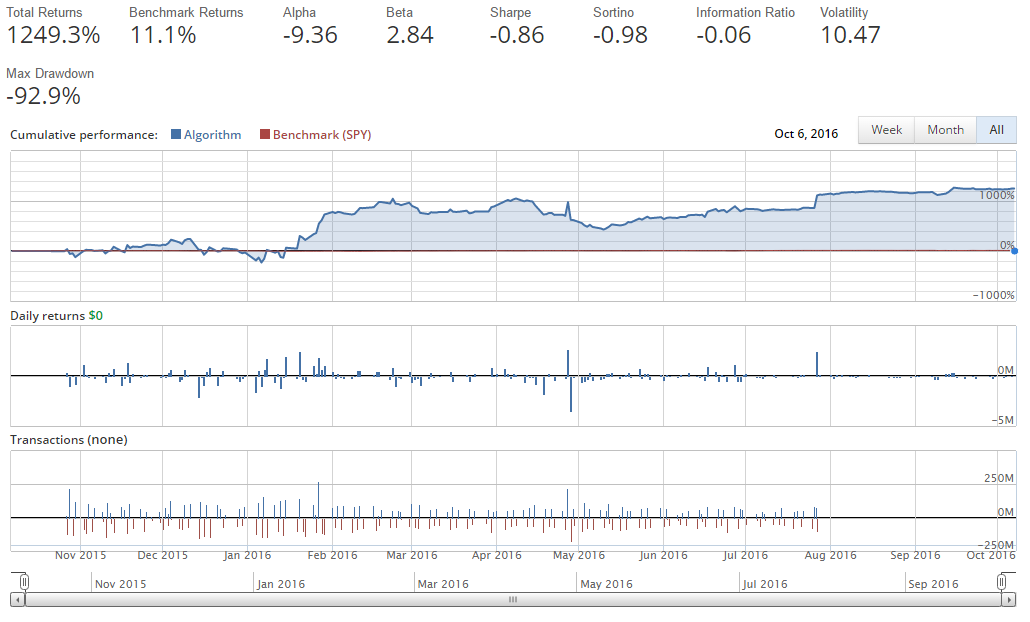
太棒了!我們會變富!
只是沒有用這個策略。
當你第一次寫一個算法,特別是在開始時,這樣的事情很可能發生。也許這對你有利,或者你失去了 1000% 的起始資金,你想知道發生了什么。在這種情況下,很容易發現它。首先,我們的回報是不可能的,而且,根據 Quantopian 的基本讀數,我們可以看到,當我們啟動資金是 100 萬美元時,我們現在正在做的交易達到數千萬美元,甚至數億美元。
那么這里發生了什么? Quantopian 是為了讓你做任何你想做的事情而建立的,對“貸款”沒有任何限制。當你借貸在金融世界投資時,通常被稱為杠桿。這個帳戶的杠桿嚴重,這正是我們所要求的。
學習如何診斷它,并在未來避免它非常重要!
第一步幾乎總是記錄杠桿。現在我們來做:
```py
def initialize(context):
context.aapl = sid(24)
def handle_data(context,data):
hist = data.history(context.aapl,'price', 50, '1d')
sma_50 = hist.mean()
sma_20 = hist[-20:].mean()
if sma_20 > sma_50:
order_target_percent(context.aapl, 1.0)
elif sma_20 < sma_50:
order_target_percent(context.aapl, -1.0)
record(leverage = context.account.leverage)
```
有了記錄,我們可以跟蹤五個值。 這里,我們僅僅選擇一個。 我們正在查看我們的帳戶的杠桿,我們在`context.account.leverage`中自動跟蹤它。 你可以看到其他選項,只需通過`context`。 或`context.account`, 等等,來使用自動完成查看你的選擇是什么。 您也可以使用記錄來跟蹤其他值,這僅僅是一個例子。
只要運行一下,我們就能看到杠桿確實無法控制:
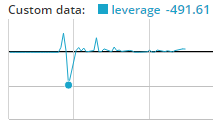
好的,所以我們已經杠桿過多。 究竟發生了什么? 好吧,對于一個人,這個`handle_data`函數每分鐘都運行。 因此,我們每分鐘都可以合理下單,在這里,它下單了投資組合的 100%。 我們認為我們是安全的,因為我們正在下單一個目標百分比。 如果目標百分比是 100%,那么我們為什么會得到這么多呢? 問題是,訂單實際填充可能需要時間。 因此,一個訂單正在等待填充,另一個正在同時進行!
我們可能想要避免的第一件事,就是使用`get_open_orders()`方法,如下所示:
```py
open_orders = get_open_orders()
if sma_20 > sma_50:
if context.aapl not in open_orders:
order_target_percent(context.aapl, 1.0)
elif sma_20 < sma_50:
if context.aapl not in open_orders:
order_target_percent(context.aapl, -1.0)
```
現在,在每個訂單之前,我們檢查是否有這個公司的未完成訂單。 讓我們來運行它。
需要注意的一點是,除非您閱讀文檔,否則確實沒有辦法知道存在`get_open_orders()`。 我會告訴你很多方法和函數,但是我當然不會把它們全部涵蓋。 一定要確保你瀏覽了 Quantopian API 文檔,看看你有什么可用的。 你不需要全部閱讀,只需瀏覽一遍,并閱讀注意到的函數。 函數/方法是紅色的,所以當你瀏覽的時候很容易捕捉它們。
這次運行的結果:
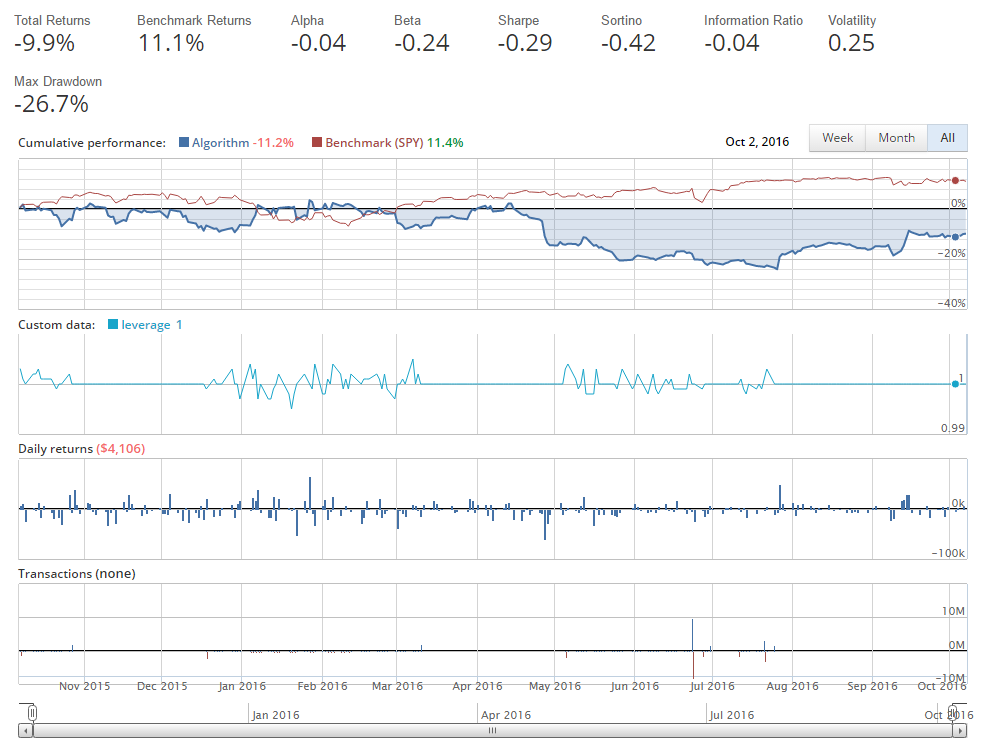
你看到的偏差是`1 +/- 0.0001`。 正如我們所希望的那樣,在這次的所有時間中,我們有效使杠桿保持為 1,但是......呃......那個回報不是非常好!
通過點擊左側導航欄中的“交易詳情”,我們可以看到一件事情,那就是我們每天都在做很多交易。 我們可以看到我們的一些交易量也相當大,有時差不多有 1000 萬美元。 這里發生了什么事? 我們也認為我們最好每天只進行一次交易。
相反,`handle_data`函數每分鐘運行一次,所以,我們實際上仍然可能每分鐘進行一次交易。 如果我們希望做的事情,不是每分鐘都在評估市場的話,我們實際上可能打算調度這個函數。 幸運的是,我們可以這樣做,這是下一個教程的主題!
## 十五、在 Quantopian 上調度函數
歡迎來到 Python 金融系列教程的第 15 部分,使用 Quantopian 和 Zipline。 在本教程中,我們將介紹`schedule_function`。
在我們的案例中,我們實際上只打算每天交易一次,而不是一天交易多次。 除了簡單的交易之外,另一種通常的做法是及時“重新平衡”投資組合。 也許每周,也許每天,也許每個月你想適當平衡,或“多元化”你的投資組合。 這個調度功能可以讓你實現它! 為了調度函數,可以在`initialize`方法中調用`schedule_function`函數。
```py
def initialize(context):
context.aapl = sid(24)
schedule_function(ma_crossover_handling, date_rules.every_day(), time_rules.market_open(hours=1))
```
在這里,我們要說的是,我們希望調度這個函數,`every_day`(每天)在`market_open`后一個小時運行。 像往常一樣,這里有很多選擇。 您可以在市場收盤前`x`小時(仍然使用正值)運行。 例如,如果您想在`market_close`之前 1 小時運行它,那將是`time_rules.market_close(hours=1)`。 您也可以在幾分鐘內調度,如:`time_rules.market_close(hours=0, minutes=1)`,這意味著在市場收盤前 1 分鐘運行這個函數。
現在,我們要做的是從handle_data函數中獲取以下代碼:
```py
hist = data.history(context.aapl,'price', 50, '1d')
sma_50 = hist.mean()
sma_20 = hist[-20:].mean()
open_orders = get_open_orders()
if sma_20 > sma_50:
if context.aapl not in open_orders:
order_target_percent(context.aapl, 1.0)
elif sma_20 < sma_50:
if context.aapl not in open_orders:
order_target_percent(context.aapl, -1.0)
...cut it and place it under a new function ma_crossover_handling
def ma_crossover_handling(context,data):
hist = data.history(context.aapl,'price', 50, '1d')
sma_50 = hist.mean()
sma_20 = hist[-20:].mean()
open_orders = get_open_orders()
if sma_20 > sma_50:
if context.aapl not in open_orders:
order_target_percent(context.aapl, 1.0)
elif sma_20 < sma_50:
if context.aapl not in open_orders:
order_target_percent(context.aapl, -1.0)
```
請注意,我們在這里傳遞上下文和數據。現在,運行完整的回測,您應該注意到這比以前要快得多。這是因為我們實際上并不是每分鐘重新計算移動均值,而是現在每天計算一次。這為我們節省了大量的計算。
但是請注意,我們的一些交易欄表明,我們正在買賣近 200 萬美元的股票,當時我們的資本應該是 100 萬美元,而我們做得還不夠好,已經翻了一番。
做空會造成這種情況。當我們在 Quantopian 上做空公司時,我們的股票是負的。例如,我們假設我們賣空 100 股蘋果。這意味著我們在蘋果有 -100 的股份。然后考慮我們想改變我們的股份,持有 100 股蘋果。實際上我們需要購買 100 股,來達到 0 股,之后再買 100 股達到`+100`。從`+100`到`-100`也是如此。這就是為什么我們擁有這些看似雙倍的交易,沒有杠桿。所以通過買入(長期)我們大約是`-7%`,并且根據移動平均交叉做空蘋果。如果我們只是買和賣,而不是買和做空,會發生什么?
```py
def initialize(context):
context.aapl = sid(24)
schedule_function(ma_crossover_handling, date_rules.every_day(), time_rules.market_open(hours=1))
def handle_data(context,data):
record(leverage=context.account.leverage)
def ma_crossover_handling(context,data):
hist = data.history(context.aapl,'price', 50, '1d')
sma_50 = hist.mean()
sma_20 = hist[-20:].mean()
open_orders = get_open_orders()
if sma_20 > sma_50:
if context.aapl not in open_orders:
order_target_percent(context.aapl, 1.0)
elif sma_20 < sma_50:
if context.aapl not in open_orders:
order_target_percent(context.aapl, 0.0)
```
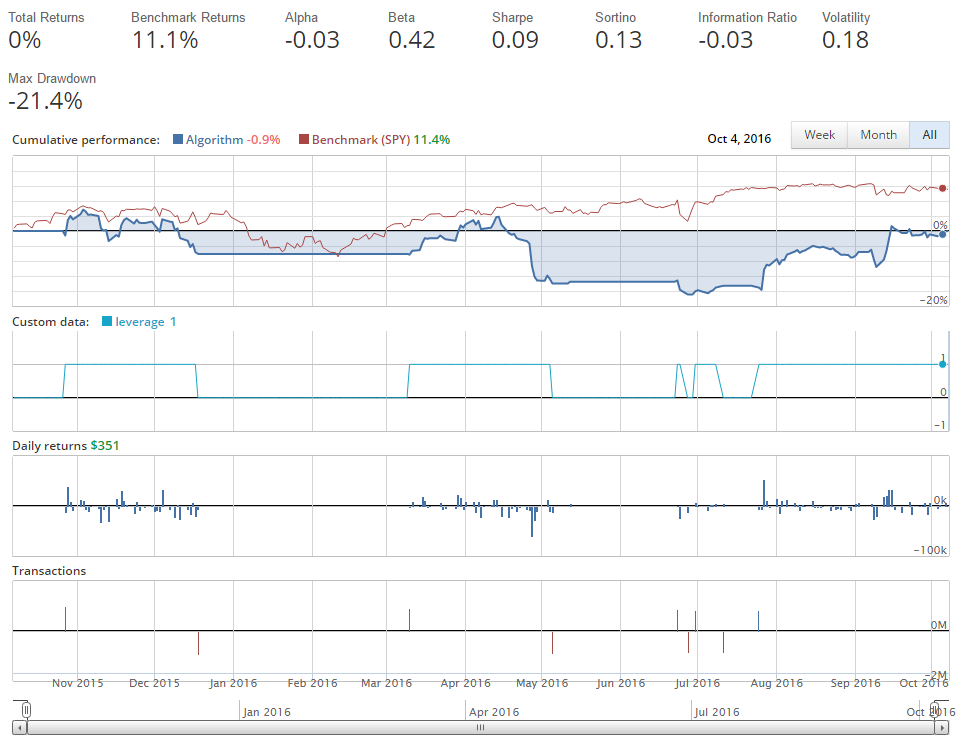
我們基本上原地運行。 通常在這個時候,人們開始考慮調整移動均值。 也許是 10 和 50,或者 2 和 50!
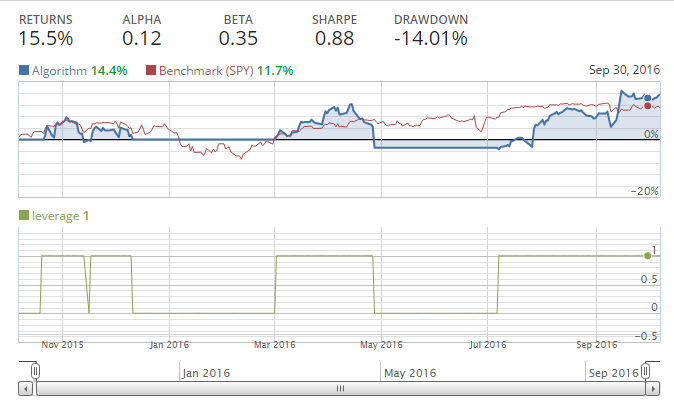
是的,2 和 50 是魔數!我們擊敗了市場。問題是,我們沒有這些隨機數字的真正理由,除了我們特地使我們的回測保持運行,直到我們成功。這是一種數據監聽的形式,是一個常見的陷阱,也是你想避免的。例如,選擇特定的移動均值來“最好地擬合”歷史數據,可能會導致未來的問題,因為這些數字用于歷史數據,而不是新的,沒有見過的數據。考慮一下蘋果公司多年來的變化。它從一個電腦公司,變成知名公司,MP3 播放器公司,再變成電話和電腦公司。由于公司本身也在變化,股票的行為可能會在未來持續變化。
相反,我們需要看看我們的策略,并意識到移動平均交叉策略是不好的。我們需要別的東西,而且我們需要一些有意義的東西作為策略,然后我們使用回測來驗證是否可行。我們不希望發現自己不斷地調整我們的策略,并好奇地回測,看看我們能否找到一些魔數。這對我們來說不太可能在未來好轉。
## 十六、Quantopian 研究入門
接下來的幾篇教程將使用 Jamie McCorriston 的“如何獲得分配:為 Quantopian 投資管理團隊網絡研討會代碼編寫算法”的稍微修改版本。
### 第一部分:研究環境入門
```py
from quantopian.interactive.data.sentdex import sentiment
```
上面,我們導入了 Sentdex 情緒數據集。 情緒數據集提供了大約 500 家公司從 2013 年 6 月開始的情緒數據,1 個月前可以在 Quantopian 上免費使用。 Sentdex 數據提供的信號范圍是 -3 到正 6,其中正 6 的程度和 -3 一樣,我個人認為正值的粒度更小。
