
# Guaranteeing Message Processing
Storm 通過 [Trident](Trident-tutorial.html) 對保證消息處理提供了不同的 level ,包括 best effort(盡力而為),at least once (至少一次)和exactly once(至少一次). 這張頁面描述如何保證至少處理一次.
### What does it mean for a message to be "fully processed"?(一條信息被完全處理是什么意思)
一個 tuple 從 spout 流出,可能會導致數以千計的 tuple 被創建.例如,下面 streaming word count的 topology(拓撲):
```
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("sentences", new KestrelSpout("kestrel.backtype.com",
22133,
"sentence_queue",
new StringScheme()));
builder.setBolt("split", new SplitSentence(), 10)
.shuffleGrouping("sentences");
builder.setBolt("count", new WordCount(), 20)
.fieldsGrouping("split", new Fields("word"));
```
這個topology從 Kestrel queue 讀取一行行的句子, 將句子按照空格分割成一個個的單詞,然后再發送之前計算的單詞數量. 從 Spout 中流出的一個tuple 會觸發創建許多 tuples: 一個tuple 對應句子的中 word,一個tuple對應每個 word 的 count。消息樹像下面這樣:
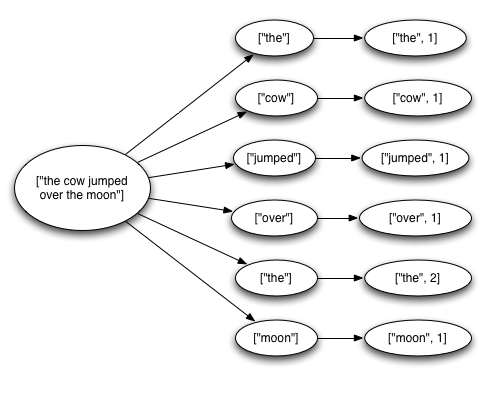
當 tuple tree 用完后且每個在 tree中的消息都被處理后,Storm 就認為從 spout 流出的 tuple 被完全處理了.
當一個 tuple tree 沒有在特定的時間內完全處理,tuple就被認為是失敗的。可以在指定的 topology(拓撲)上使用 [Config.TOPOLOGY_MESSAGE_TIMEOUT_SECS](javadocs/org/apache/storm/Config.html#TOPOLOGY_MESSAGE_TIMEOUT_SECS) 來配置這個超時時間,并且默認為30秒。
### What happens if a message is fully processed or fails to be fully processed?(如果消息完全處理或未能完全處理,會發生什么)
為了理解這個問題,我們來看一下 tuple 從 spout 流出后的聲明周期。作為參考,這里是spouts實現的接口 (有關更多信息,請參閱J [Javadoc](javadocs/org/apache/storm/spout/ISpout.html) ):
```
public interface ISpout extends Serializable {
void open(Map conf, TopologyContext context, SpoutOutputCollector collector);
void close();
void nextTuple();
void ack(Object msgId);
void fail(Object msgId);
}
```
首先 Storm 請求一個 `Spout` 中的 tuple,使用 `Spout` 中的 `nextTuple` 方法. `Spout` 使用 `SpoutOutputCollector` 提供的 `open` 方法,發送 tuple 輸出到 output streams的其中一個.當發送 tuple 的時候, `Spout` 會提供一個 "message id",用于以后標識 tuple .例如,`KestrelSpout` 從kestrel queue中讀取消息,在發送消息的時候會提供一個 "message id"。發送一個 message 到 `SpoutOutputCollector` 像下面這樣:
```
_collector.emit(new Values("field1", "field2", 3) , msgId);
```
下一步,tuple被發送到消費的 bolts中,Storm 開始監控創建的 the tree of messages。如果 Storm 檢測到 tuple被完全處理,Storm 會在原來的 Spout 上根據message id 調用 ack 方法.同樣的,如果處理 tuple超時了,Storm會在 `Spout` 上調用 `fail` 方法.由于 tuple ack或者fail,都原來創建這個tuple 的 Spout task調用.所以如果一個 `Spout` 在集群上運行很多任務,tuple 不會被多個 `Spout` 任務 acked 或者 failed.
我們再通過 `KestrelSpout` 來看看 `Spout` 需要保證消息處理那些情況.當 `KestrelSpout` 從 Kestrel queue中讀取消息的時候,它只是 "open" 了message.這意味著消息并沒有真正從隊列出來,而是處于一種 “pending” 狀態,承認message 已經完成.在這種 pending 狀態的時候,message不會將消息發送到隊列的其他用 consumer.此外,如果客戶端斷開所有 pending 狀態的消息,那么客戶端將把消息放回到隊列.當一條 message opened后,Kestrel 向客戶端提供消息,并提供一個唯一性的id標識消息. 當發送 tuple 到 SpoutOutputCollector的時候,就用Kestrel 提供的id 作為 “message id”。當 KestrelSpout 調用 ack或者fail的時候,KestrelSpout會向Kestrel 發送一條ack 或者 fail消息,包括 message id,以讓Kestrel 將消息從隊列中取出,或者放回去.
### What is Storm's reliability API?
用戶想要保證Storm的可靠性,需要做兩件事.第一,當你在 tuple tree 中創建新的 link 的時候,你需要告訴 Storm.第二,當你處理完一個獨立的 tuple,也需要告訴Storm。 做到這兩件事情,Storm可以檢測到 tree of tuples 什么時候完全處理了,并且可以適當的 ack 或者 fail spout tuples。Storm 的API提供了一個簡單的方法來完成這兩項任務.
在 tuple tree中指定一個link 的方法叫做 _anchoring_. 當你發送一個新的 tuple 的時候就會執行 Anchoring 操作.我們使用下面的 bolt 作為一個例子.這個 bolt 將句子 tuple 分割成一個個 word tuple.
```
public class SplitSentence extends BaseRichBolt {
OutputCollector _collector;
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
_collector = collector;
}
public void execute(Tuple tuple) {
String sentence = tuple.getString(0);
for(String word: sentence.split(" ")) {
_collector.emit(tuple, new Values(word));
}
_collector.ack(tuple);
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}
```
通過指定輸入 tuple 作為emit 的第一個參數,每一個word tuple 就會被 anchored.由于 word tuple 被 anchor,如果 word tuple 下游處理失敗,tuple tree 的根節點會重新處理.相比之下,我們看一下 word tuple像下面這樣發送.
```
_collector.emit(new Values(word));
```
這種方式發送 word tuple 會導致 _unanchored_. 如果tuple在處理下游的時候失敗,根節點的 tuple不會重新處理.根據你的 topology(拓撲)需要來保證容錯保證,有時候發送一個 unanchored tuple 也比較適合.
輸出的tuple可以 anchor 多個input tuple,當join和聚合的時候,這是比較有用的.一個 multi-anchored 的tuple處理失敗后,多個tuple都會被重新處理.通過指定一系列 tuples,而不是單個tuple來完成 Multi-anchoring.例如:
```
List<Tuple> anchors = new ArrayList<Tuple>();
anchors.add(tuple1);
anchors.add(tuple2);
_collector.emit(anchors, new Values(1, 2, 3));
```
Multi-anchoring 會添加 output tuple 到 multiple tuple trees.這就可能會破壞樹形結構,創建了tuple DAGs,像這樣:
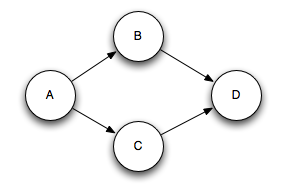
Storm 的實現適用于DAG和樹(pre-release 只適用于trees,稱為“tuple tree”)
Anchoring 是你如何指定 tuple tree的方式--在Storm可靠性 API 在 tuple tree中完成一個tuple后,會執行下一部分的處理. 在OutputCollector上使用ack和fail方法的時候來完成.如果你回顧了SplitSentence例子,你可以看到當所有的word tuple發送出去后,input tuple會被ack.
你可以使用 `OutputCollector` 的 `fail` 方法,立即設置 tuple tree的根節點spout tuple為失敗狀態.例如,你的應用可能數據庫異常,需要顯式的 fail input tuple。通過顯式的failing,spout tuple 可以比等待tuple超時速度更快.
你處理的每個tuple 必須acked或者failed.Storm使用內存監控每個tuple,所以如果你必須fail或者ack每個tuple,這個任務最終會out of memory.
許多bolts都會像下面這種模式讀取 input tuple,發送 tuples.在 `execute` 方法結束后acking tuple。bolts 有過濾或者一些簡單的功能.Storm有一個接口叫做BasicBolt,可以封裝這些模式.SplitSentence示例可以寫成BasicBolt,如下所示:
```
public class SplitSentence extends BaseBasicBolt {
public void execute(Tuple tuple, BasicOutputCollector collector) {
String sentence = tuple.getString(0);
for(String word: sentence.split(" ")) {
collector.emit(new Values(word));
}
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}
```
該實現比以前的實現更簡單,語義上相同。發送到 `BasicOutputCollector` 的 tuple 將自動 anchor 到輸入元組,并且在執行方法完成時自動acked。
相比之下,執行聚合或join的bolt可能會延遲ack input tuple。聚合和join會多重anchor output tuples。這些事情不在 `IBasicBolt` 的簡單模式之上.
### How do I make my applications work correctly given that tuples can be replayed?(如果重新處理 tuples,我如何使我的應用程序正常工作?)
與軟件設計一樣,答案是“depend”。如果你真的想要使用 [Trident](Trident-tutorial.html) 保證 exactly once 語義.在某些情況下,像許多分析行為一樣,丟棄數據是允許的,所以通過設置 ackers bolts 數量為0 Config.TOPOLOGY_ACKERS ,來禁用容錯.但在某些情況下,你想要確保所有的 tuple 至少處理一次,沒有任何內容被丟棄.This is especially useful if all operations are idenpotent or if deduping can happen aferwards.(廢話可以不看)
### How does Storm implement reliability in an efficient way?(Storm 如何以有效的方式實現可靠性?)
Storm 對于 Spout 的 tuple 都有一組特殊的 acker 任務用來跟蹤 DAG tuples。當一個acker 任務看到一個 DAG 完成后,就會發送一個消息到到創建這個 spout tuple 的任務.你可以通過 Config.TOPOLOGY_ACKERS 來設置 acker tasks的數量.Storm TOPOLOGY_ACKERS 配置默認是一個worker 一個任務.
理解Storm 可靠性實現最好的方式就是看 tuple 和 tuple DAG的聲明周期.當 topology中創建了一個 tuple,也可以在一個 spout或者bolt,會給予一個 64 bit 的id.這個id是 ackers用來跟蹤 tuple DAG里的每個 spout tuple。
spout 中的每個 tuple 都知道他們id,并存在于 tuple tree中.當你發送一個新的 tuple 到bolt 的時候,來自于 tuple anchors(錨點)的spout tuple ids會被復制到新的 tuple.當一個tuple被ack后,就會發送一條消息到 acker tasks,告知 tuple tree應該如何改變. 實際上,告訴acker的是“我已經完成了tree中的這個 spout tuple ,這里是 tree中 anchored(錨定) 我的 tuples”。
例如, tuples D和E是基于 tuple C創建的,下面是當 tuple C 被acked后,tree是如何改變的.
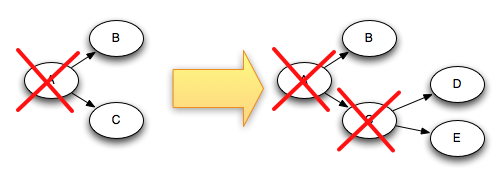
由于 tuple C 從 tree中移除的同時, tuple "D"和"E"都加入到tree中,所以 tree 永遠不可能完成.
Storm 跟蹤 tuple trees 有一些細節.如前面所述,你可以在 topology中定義任意數量的 acker 任務。這導致了以下問題:當一個元組在 topology 中被 acked后,它如何知道是哪個 acker 任務發送的該消息?
Storm 使用 mod hash的模式將spout tuple id映射到acker task.由于每一個tuple都會帶有tree中id,所以他們知道和那個 acker task 進行通信.
Storm的另一個細節就是如何讓 Acker 任務跟蹤他們正在跟蹤的每個 spout tuple的 spouts 任務。當一個spout任務發出一個新的元組時,它只需向相應的acker發送一條消息,告訴它它的任務id是負責這個新的元素的負責人。然后當acker看到樹已經完成時,它知道要發送那個任務id。
Acker tasks 不會顯式的跟蹤 tuple trees。對于具有成千上萬個節點(或者更多)的大型 tuple tree,跟蹤所有的 tuple trees 會占用很多內存.相反,ackers采用不同的策略,只需要每個 spout tuple 固定空間(大約20字節).這種跟蹤算法是Storm工作的關鍵,也是重大突破之一.
一個acker task 存儲spout tuple id映射到一組值的map,第一個值是創建這個 spout tuple 的任務id.第二個值是稱為 “ack val”的64位數. ack val 表示整個tuple tree的狀態,無論多大或多小,它簡化了在樹中創建或者acked 的所有tuple ids 的xor.
當acker任務看到“ack val”已經變為0時,它知道元組樹已經完成。由于 tuple ID是隨機64位數,因此“ack val” 突然變為0的機會非常小。從數學角度來看,每秒10K acks,就要花5萬年,直到出錯。即使如此,如果該 tuple 在拓撲中發生故障,則只會導致數據丟失。
現在,您了解可靠性算法,讓我們回顧一下所有故障情況,并了解如何在每種情況下避免數據丟失:
* **一個tuple沒有acked,因為對應的任務掛掉**: 在這種情況下,失敗的元組會超時并重新處理.
* **Acker 任務掛掉**: 這種情況下acker 跟蹤的所有的 spout tuples 都會超時并重新處理
* **Spout 任務掛掉**: 在這種情況下,spout 的來源負責重新播放消息.例如,當客戶端斷開連接時,像Kestrel和RabbitMQ這樣的隊列會將所有掛起的消息放回隊列。
正如你所看到的,Storm的可靠性機制是完全分布式,可擴展的和容錯的。
### Tuning reliability(調整可靠性)
Acker任務是輕量級的,所以在 topology(拓撲)中您不需要非常多的任務。您可以通過Storm UI(組件ID“__acker”)跟蹤其性能。如果吞吐量看起來不正確,則需要添加更多的acker任務.
如果可靠性對您不重要 -- 也就是說,您不關心在失敗情況下丟失 tuple,那么您可以通過不跟蹤 tuple tree來提高性能。沒有跟蹤tuple tree 將傳遞的消息數量減少一半,因為正常情況下,tuple tree 中的每個tuple都有一個確認消息。另外,它需要更少的id來保存在每個下游 tuple 中,從而減少帶寬使用。
有三種方法來消除可靠性。第一個是將Config.TOPOLOGY_ACKERS設置為0.在這種情況下,Storm會在 spout 發出一個tuple 后立即在 spout 上調用ack方法。元組樹不會被跟蹤。
第二種方法是通過消息消除消息的可靠性。您可以通過省略SpoutOutputCollector.emit方法中的消息標識來關閉單個 spout tuple 的跟蹤。
最后,如果您不關心topology(拓撲)中下游的tuple的特定子集是否被處理,則可以將其作為無保留的 tuple發出。由于它們沒有被錨定到任何 spout tuple,所以如果沒有出現,它們不會導致任何 spout tuple失敗。
- Storm 基礎
- 概念
- Scheduler(調度器)
- Configuration
- Guaranteeing Message Processing
- 守護進程容錯
- 命令行客戶端
- Storm UI REST API
- 理解 Storm Topology 的 Parallelism(并行度)
- FAQ
- Layers on Top of Storm
- Storm Trident
- Trident 教程
- Trident API 綜述
- Trident State
- Trident Spouts
- Trident RAS API
- Storm SQL
- Storm SQL 集成
- Storm SQL 示例
- Storm SQL 語言參考
- Storm SQL 內部實現
- Flux
- Storm 安裝和部署
- 設置Storm集群
- 本地模式
- 疑難解答
- 在生產集群上運行 Topology
- Maven
- 安全地運行 Apache Storm
- CGroup Enforcement
- Pacemaker
- 資源感知調度器 (Resource Aware Scheduler)
- 用于分析 Storm 的各種內部行為的 Metrics
- Windows 用戶指南
- Storm 中級
- 序列化
- 常見 Topology 模式
- Clojure DSL
- 使用沒有jvm的語言編輯storm
- Distributed RPC
- Transactional Topologies
- Hooks
- Storm Metrics
- Storm 狀態管理
- Windowing Support in Core Storm
- Joining Streams in Storm Core
- Storm Distributed Cache API
- Storm 調試
- 動態日志級別設置
- Storm Logs
- 動態員工分析
- 拓撲事件檢查器
- Storm 與外部系統, 以及其它庫的集成
- Storm Kafka Integration
- Storm Kafka 集成(0.10.x+)
- Storm HBase Integration
- Storm HDFS Integration
- Storm Hive 集成
- Storm Solr 集成
- Storm Cassandra 集成
- Storm JDBC 集成
- Storm JMS 集成
- Storm Redis 集成
- Azue Event Hubs 集成
- Storm Elasticsearch 集成
- Storm MQTT(Message Queuing Telemetry Transport, 消息隊列遙測傳輸) 集成
- Storm MongoDB 集成
- Storm OpenTSDB 集成
- Storm Kinesis 集成
- Storm Druid 集成
- Storm and Kestrel
- Container, Resource Management System Integration
- Storm 高級
- 針對 Storm 定義一個不是 JVM 的 DSL
- 多語言協議
- Storm 內部實現
- 翻譯進度