
# 資源感知調度器 (Resource Aware Scheduler)
## 介紹
本文檔的目的是為 Storm 分布式實時計算系統提供資源感知調度程序的描述。 本文檔將為您提供 Storm 中資源感知調度程序的高級描述。 以下是 Hadoop Summit 2016 演示文稿中概述的一些好處是在 Storm 上使用資源感知調度器:
[http://www.slideshare.net/HadoopSummit/resource-aware-scheduling-in-apache-storm](http://www.slideshare.net/HadoopSummit/resource-aware-scheduling-in-apache-storm)
## Table of Contents
1. [使用資源感知調度器](#Using-Resource-Aware-Scheduler)
2. [API 概述](#API-Overview)
1. [設置內存要求](#Setting-Memory-Requirement)
2. [設置 CPU 要求](#Setting-CPU-Requirement)
3. [設置每個 worker (JVM) 進程的堆大小](#Limiting-the-Heap-Size-per-Worker-(JVM)Process)
4. [在節點上設置可用資源](#Setting-Available-Resources-on-Node)
5. [其他配置](#Other-Configurations)
3. [Topology 優先級和每個用戶資源](#Topology-Priorities-and-Per-User-Resource)
1. [設置](#Setup)
2. [指定 Topology 優先級](#Specifying-Topology-Priority)
3. [指定 Scheduling 策略](#Specifying-Scheduling-Strategy)
4. [指定 Topology 優先策勒](#Specifying-Topology-Prioritization-Strategy)
5. [指定 Eviction 策略](#Specifying-Eviction-Strategy)
4. [分析資源使用情況](#Profiling-Resource-Usage)
5. [對原始 DefaultResourceAwareStrategy 的增強](#Enhancements-on-original-DefaultResourceAwareStrategy)
## 使用資源感知調度器
用戶可以通過在 _conf/storm.yaml_ 中設置以下內容來切換到使用資源感知調度器
```
storm.scheduler: “org.apache.storm.scheduler.resource.ResourceAwareScheduler”
```
## API 概述
要使用 Trident,請參閱 [Trident RAS API](Trident-RAS-API.html)
對于 Storm Topology,用戶現在可以指定運行組件的單個實例所需的 Topology 組件(即: Spout 或 Bolt)的資源量。 用戶可以通過使用以下 API 調用來指定 Topology 組件的資源需求。
### 設置內存要求
API 設置組件內存要求:
```
public T setMemoryLoad(Number onHeap, Number offHeap)
```
參數:
* Number onHeap - 此組件的實例將以兆字節消耗的堆內存量
* Number offHeap - 此組件的一個實例將以兆字節消耗的堆內存量
用戶還必須選擇只要指定堆內存要求,如果組件沒有關閉堆內存需要。
```
public T setMemoryLoad(Number onHeap)
```
參數:
* Number onHeap - 此組件的一個實例將占用的堆內存量
如果沒有為 offHeap 提供值,將使用 0.0。 如果沒有為 onHeap 提供任何值,或者從未為??調用的組件 API,則將使用默認值。
使用示例:
```
SpoutDeclarer s1 = builder.setSpout("word", new TestWordSpout(), 10);
s1.setMemoryLoad(1024.0, 512.0);
builder.setBolt("exclaim1", new ExclamationBolt(), 3)
.shuffleGrouping("word").setMemoryLoad(512.0);
```
該 topology 結構請求的整個內存為 16.5 GB。這是從10個 spout,堆內存為 1GB,每個堆內存為0.5 GB,每個堆內存為3個 bolt 0.5 GB。
### 設置 CPU 要求
設置組件 CPU 要求的 API:
```
public T setCPULoad(Double amount)
```
參數:
* Number amount – 該組件實例將使用的CPU數量
目前,一個組件需要或在節點上可用的 CPU 資源量由 一個 point 系統表示。 CPU 使用是一個難以定義的概念。根據手頭的任務,不同的 CPU 架構執行不同。 它們非常復雜,在單個精確的便攜式數字中表達所有這些都是不可能的。 相反,我們采取了一種配置方法的慣例,主要關注 CPU 使用率的粗略水平,同時仍然提供了指定更細粒度的可能性。
按照慣例,CPU 內核通常會得到100分。如果您覺得您的處理器或多或少功能強大,您可以相應地進行調整。 CPU 綁定的重任務將獲得100分,因為它們可以消耗整個內核。中等任務應該得到50,輕型任務25和小任務10。在某些情況下,您有一個任務可以產生其他線程來幫助處理。 這些任務可能需要超過100點才能表達他們正在使用的 CPU 數量。如果遵循這些約定,單個線程任務的常見情況,報告的 Capacity * 100應該是任務需要的 CPU 點數。
使用示例:
```
SpoutDeclarer s1 = builder.setSpout("word", new TestWordSpout(), 10);
s1.setCPULoad(15.0);
builder.setBolt("exclaim1", new ExclamationBolt(), 3)
.shuffleGrouping("word").setCPULoad(10.0);
builder.setBolt("exclaim2", new HeavyBolt(), 1)
.shuffleGrouping("exclaim1").setCPULoad(450.0);
```
### 設置每個 worker (JVM) 進程的堆大小
```
public void setTopologyWorkerMaxHeapSize(Number size)
```
參數:
* Number size – worker 進程將以兆字節來分配內存范圍
在每個 topology 基礎上分配給單個 worker 程序的內存資源量,用戶可以通過使用上述 API 來限制資源感知調度器。 該 API 已經到位,以便用戶可以將 executor 傳播給多個 worker。然而,將 executor 傳播給多個 worker 可能會增加通信延遲,因為 executor 將無法使用 Disruptor Queue 進行進程內通信。
使用示例:
```
Config conf = new Config();
conf.setTopologyWorkerMaxHeapSize(512.0);
```
### 在節點上設置可用資源
storm 管理員可以通過修改位于該節點的 storm home 目錄中的 _conf/storm.yaml_ 文件來指定節點資源可用性。
storm 管理員可以指定一個節點有多少可用內存(兆字節),將以下內容添加到 _storm.yaml_ 中
```
supervisor.memory.capacity.mb: [amount<Double>]
```
storm 管理員還可以指定節點有多少可用 CPU 資源,將以下內容添加到 _storm.yaml_ 中
```
supervisor.cpu.capacity: [amount<Double>]
```
注意:用戶可以為可用 CPU 指定的數量使用如前所述的點系統來表示。
使用示例:
```
supervisor.memory.capacity.mb: 20480.0
supervisor.cpu.capacity: 100.0
```
### 其他配置
用戶可以在 _conf/storm.yaml_ 中為資源意識調度程序設置一些默認配置:
```
//default value if on heap memory requirement is not specified for a component
topology.component.resources.onheap.memory.mb: 128.0
//default value if off heap memory requirement is not specified for a component
topology.component.resources.offheap.memory.mb: 0.0
//default value if CPU requirement is not specified for a component
topology.component.cpu.pcore.percent: 10.0
//default value for the max heap size for a worker
topology.worker.max.heap.size.mb: 768.0
```
## Topology 優先級和每個用戶資源
資源感知調度器或 RAS 還具有 multitenant 功能,因為許多 Storm 用戶通常共享 Storm 集群。 資源感知調度器可以在每個用戶的基礎上分配資源。 每個用戶可以保證一定數量的資源來運行他或她的 topology,并且資源感知調度器將盡可能滿足這些保證。 當 Storm 群集具有額外的免費資源時,資源感知調度器將能夠以公平的方式為用戶分配額外的資源。topology 的重要性也可能有所不同。 topology 可用于實際生產或僅用于實驗,因此資源感知調度器將在確定調度 topology 的順序或何時驅逐 topology 時考慮 topology 的重要性。
### 設置
可以指定用戶的資源保證 _conf/user-resource-pools.yaml_。以下列格式指定用戶的資源保證:
```
resource.aware.scheduler.user.pools:
[UserId]
cpu: [Amount of Guarantee CPU Resources]
memory: [Amount of Guarantee Memory Resources]
```
_user-resource-pools.yaml_ 可以是什么樣的示例:
```
resource.aware.scheduler.user.pools:
jerry:
cpu: 1000
memory: 8192.0
derek:
cpu: 10000.0
memory: 32768
bobby:
cpu: 5000.0
memory: 16384.0
```
請注意,指定數量的保證 CPU 和內存可以是整數或雙倍
### 指定 Topology 優先級
topology 優先級的范圍可以從0-29開始。topology 優先級將被劃分為可能包含一系列優先級的幾個優先級。 例如,我們可以創建一個優先級映射:
```
PRODUCTION => 0 – 9
STAGING => 10 – 19
DEV => 20 – 29
```
因此,每個優先級包含10個子優先級。用戶可以使用以下 API 設置 topology 的優先級
```
conf.setTopologyPriority(int priority)
```
參數: * priority - 表示 topology 優先級的整數
請注意,0-29范圍不是硬限制。因此,用戶可以設置高于29的優先級數。然而,優先級數越高的屬性越低,重要性仍然保持不變
### 指定 Scheduling 策略
用戶可以在每個 topology 基礎上指定要使用的調度策略。 用戶可以實現 IStrategy 界面,并定義新的策略來安排特定的 topology。 這個可插拔接口是因為我們實現不同的 topology 可能具有不同的調度需求而創建的。 用戶可以使用 API ??在 topology 定義中設置 topology 策略:
```
public void setTopologyStrategy(Class<? extends IStrategy> clazz)
```
參數:
* clazz - 實現 IStrategy 接口的策略類
使用示例:
```
conf.setTopologyStrategy(org.apache.storm.scheduler.resource.strategies.scheduling.DefaultResourceAwareStrategy.class);
```
提供默認調度。DefaultResourceAwareStrategy 是基于 Storm 中的資源感知調度原始文件中的調度算法實現的:
Peng, Boyang, Mohammad Hosseini, Zhihao Hong, Reza Farivar, 和 Roy Campbell。"R-storm: storm 中的資源感知調度"。 在第16屆年度中間件會議論文集,第149-161頁。ACM,2015。
[http://dl.acm.org/citation.cfm?id=2814808](http://dl.acm.org/citation.cfm?id=2814808)
**Please Note: 必須根據本文所述的原始調度策略進行增強。請參閱"原始 DefaultResourceAwareStrategy 的增強功能"一節"**
### 指定 Topology 優先策略
調度順序是可插拔接口,用戶可以在其中定義 topology 優先級的策略。 為了使用戶能夠定義自己的優先級策略,他或她需要實現 ISchedulingPriorityStrategy 界面。 用戶可以通過將 _Config.RESOURCE_AWARE_SCHEDULER_PRIORITY_STRATEGY_ 設置為指向實現策略的類來設置調度優先級策略。 例如:
```
resource.aware.scheduler.priority.strategy: "org.apache.storm.scheduler.resource.strategies.priority.DefaultSchedulingPriorityStrategy"
```
將提供默認策略。以下說明默認調度優先級策略的工作原理。
**DefaultSchedulingPriorityStrategy**
調度順序應基于用戶當前資源分配與其保證分配之間的距離。我們應優先考慮遠離資源保障的用戶。 這個問題的難點在于,用戶可能有多個資源保證,另一個用戶可以擁有另一套資源保證,那么我們怎么能以公平的方式來比較呢?我們用平均百分比的資源擔保作為比較方法。
例如:
| 用戶 | 資源保證 | 資源分配 |
| --- | --- | --- |
| A | <10 cpu,="" 50gb=""> | <2 40="" cpu,="" gb=""> |
| B | < 20 CPU, 25GB> | <15 10="" cpu,="" gb=""> |
用戶 A 的平均百分比滿足資源保證:
(2/10+40/50)/2 = 0.5
用戶 B 的資源保證的平均百分比滿足:
(15/20+10/25)/2 = 0.575
因此,在該示例中,用戶 A 具有比用戶 B 滿足的資源保證的平均百分比較小。因此,用戶 A 應優先分配更多資源,即調度用戶 A 提交的 topology。
在進行調度時,RAS 按用戶資源保證和平均百分比滿足資源保證的平均百分比,按用戶的平均百分比滿足資源保證的平均百分比排序,根據用戶的順序排序。 當用戶的資源保證完全滿足時,用戶滿足資源保證的平均百分比大于等于1。
### 指定 Eviction 策略
當集群中沒有足夠的可用資源來安排新的 topology 結構時,使用 eviction 策略。 如果集群已滿,我們需要一種 eviction topology 的機制,以便滿足用戶資源保證,并且可以在用戶之間公平分享其他資源。 驅逐 topology 的策略也是可插拔的界面,用戶可以在其中實現自己的 topology eviction 策略。 為了使用戶實現自己的 eviction 策略,他或她需要實現 IEvictionStrategy 接口并將 _Config.RESOURCE_AWARE_SCHEDULER_EVICTION_STRATEGY_ 設置為指向已實施的策略類。 例如:
```
resource.aware.scheduler.eviction.strategy: "org.apache.storm.scheduler.resource.strategies.eviction.DefaultEvictionStrategy"
```
提供了默認的 eviction 策略。以下說明默認 topology eviction 策略的工作原理
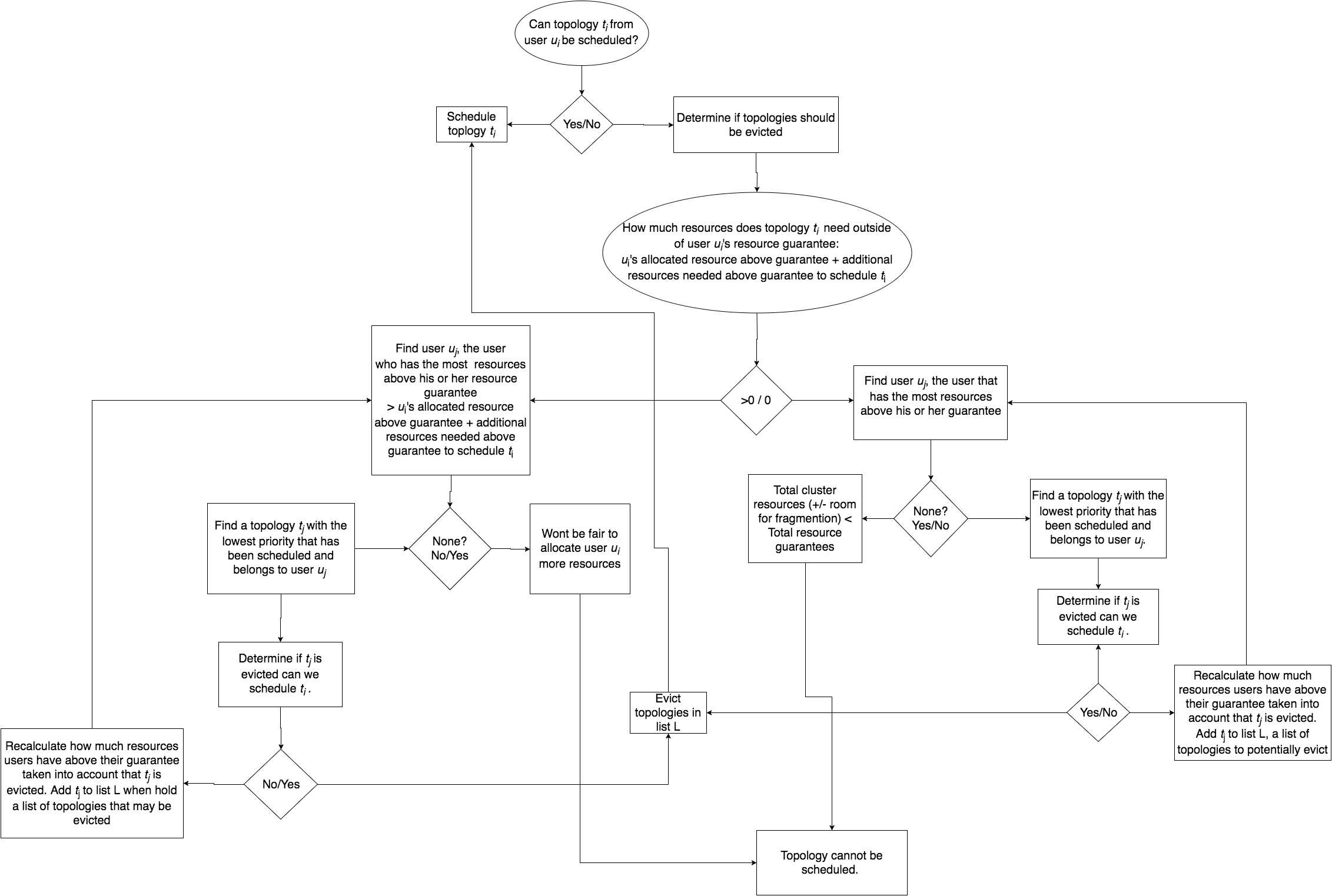
**DefaultEvictionStrategy**
為了確定是否應該發生 topology 遷移,我們應該考慮到我們正在嘗試調度 topology 的優先級,以及是否滿足 topology 所有者的資源保證。
我們不應該從沒有滿足他或她的資源保證的用戶中排除 topology。以下流程圖應描述 eviction 過程的邏輯。
## 分析資源使用情況
了解 topology 的資源使用情況:
要了解 topology 結構實際使用的 memory/CPU 數量,您可以將以下內容添加到 topology 啟動代碼中。
```
//Log all storm metrics
conf.registerMetricsConsumer(backtype.storm.metric.LoggingMetricsConsumer.class);
//Add in per worker CPU measurement
Map<String, String> workerMetrics = new HashMap<String, String>();
workerMetrics.put("CPU", "org.apache.storm.metrics.sigar.CPUMetric");
conf.put(Config.TOPOLOGY_WORKER_METRICS, workerMetrics);
```
CPU 指標將需要您添加
```
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-metrics</artifactId>
<version>1.0.0</version>
</dependency>
```
作為 topology 依賴(1.0.0或更高版本)。
然后,您可以在 UI 上轉到 topology,打開系統 metrics,并找到 LoggingMetricsConsumer 正在寫入的日志。它會在日志中輸出結果。
```
1454526100 node1.nodes.com:6707 -1:__system CPU {user-ms=74480, sys-ms=10780}
1454526100 node1.nodes.com:6707 -1:__system memory/nonHeap {unusedBytes=2077536, virtualFreeBytes=-64621729, initBytes=2555904, committedBytes=66699264, maxBytes=-1, usedBytes=64621728}
1454526100 node1.nodes.com:6707 -1:__system memory/heap {unusedBytes=573861408, virtualFreeBytes=694644256, initBytes=805306368, committedBytes=657719296, maxBytes=778502144, usedBytes=83857888}
```
-1:__系統的度量通常是整個 worker 的 metrics 標準。 在上面的示例中,worker 正在 node1.nodes.com:6707 上運行。 這些 metrics 是每60秒收集一次。對于 CPU,您可以看到,在60秒鐘內,此 worker 使用74480 + 10780 = 85260 ms 的 CPU 時間。 這相當于85260/60000或約1.5內核。
內存使用情況類似,但是查看 usedBytes。 offHeap 是 64621728 或大約 62MB,onHeap 是 83857888 或大約 80MB,但你應該知道你已經在每個 worker 中設置了你的堆。 你如何劃分每個 bolt/spout? 這有點困難,可能需要一些嘗試和錯誤從你的結束。
## * 對原始 DefaultResourceAwareStrategy 的增強 *
如上文所述的默認資源感知調度策略有兩個主要的調度階段:
1. 任務選擇 - 計算拓撲中的順序 task/executor 應該被調度
2. 節點選擇 - 給定一個 task/executor,找到一個節點來安排 task/executor。
對兩個調度階段進行了改進
### 任務選擇增強
不是使用 topology 圖的寬度優先遍歷來創建組件及其 executor 的排序,而是使用一種新的啟發式方法,可以通過組件的進出邊緣數量(潛在連接)對組件進行排序。這被發現是一種更有效的方式來協調彼此通信的 executor,并減少網絡延遲。
### 節點選擇增強
節點選擇首先選擇哪個機架(服務器機架),然后選擇該機架上的哪個節點。選擇機架和節點的戰略要點是找到具有 "最多" 資源的機架,并在該機架中使用 "最多" 免費資源查找節點。 我們為此策略制定的假設是,擁有最多資源的節點或機架將具有最高的概率,允許我們調度在節點或機架上共同定位最多的 executor,以減少網絡通信延遲。
機架和節點將從最佳選擇排列到最差選擇。在找到執行者時,策略將在放棄之前迭代所有機架和節點,從最壞到最壞。機架和節點將按以下事項進行排序:
1. 已經在機架或節點上安排了多少個 executor -- 這樣做是為了使 executor 更緊密地安排已經安排并運行的 executor。如果 topology 部分崩潰,topology 的 executor 的一部分需要重新安排,我們希望將這些 executor 盡可能接近(網絡)重新安排到健康和運行的 executor。
2. 輔助資源可用性或機架或節點上的 "有效" 資源量 -- 請參閱下屬資源可用性部分
3. 所有資源可用性的平均值 -- 這僅僅是可用的平均百分比(分別在機架或集群上的可用資源分配的節點或機架上的可用資源)。只有當兩個對象(機架或節點)的 "有效資源" 相同時,才會使用這種情況。然后,我們將所有資源百分比的平均值作為排序指標。例如:
```
Avail Resources:
node 1: CPU = 50 Memory = 1024 Slots = 20
node 2: CPU = 50 Memory = 8192 Slots = 40
node 3: CPU = 1000 Memory = 0 Slots = 0
Effective resources for nodes:
node 1 = 50 / (50+50+1000) = 0.045 (CPU bound)
node 2 = 50 / (50+50+1000) = 0.045 (CPU bound)
node 3 = 0 (memory and slots are 0)
```
ode1 和 節點2 具有相同的有效資源,但是明確地說,節點2具有比節點1更多的資源(memory 和 slots),并且我們將首先選擇節點2,因為我們將能夠安排更多的 executor。這是階段2平均的
因此,排序遵循以下進展。 基于1)進行比較,如果相等,則基于2)進行比較,如果基于3)相等比較,并且如果相等,則通過基于比較節點或機架的 id 來通過任意分配排序來斷開連接。
**下屬資源可用性**
最初,RAS 的 getBestClustering 算法通過在機架中的所有節點上找到具有可用內存的最大可用總數 + 可用的最大可用機架,找到基于哪個機架具有 "最可用" 資源的 "最佳" 機架。 這種方法不是非常準確的,因為內存和 cpu 的使用不同,而且值不是正常的。 這種方法也沒有效果,因為它不考慮可用的插槽的數量,并且由于資源之一(內存,CPU 或 slots)的耗盡,無法識別不可調度的機架。 以前的方法也不考慮 worker 的失敗。當 topology 的 executor 未被分配并需要重新安排時,
找到 "最佳" 機架或節點的新 策略/算法,我配置從屬資源可用性排序(受主導資源公平性的啟發),通過下屬(不占優勢)資源可用性對機架和節點進行排序。
例如給出4個具有以下資源可用性的機架
```
//generate some that has alot of memory but little of cpu
rack-3 Avail [ CPU 100.0 MEM 200000.0 Slots 40 ] Total [ CPU 100.0 MEM 200000.0 Slots 40 ]
//generate some supervisors that are depleted of one resource
rack-2 Avail [ CPU 0.0 MEM 80000.0 Slots 40 ] Total [ CPU 0.0 MEM 80000.0 Slots 40 ]
//generate some that has a lot of cpu but little of memory
rack-4 Avail [ CPU 6100.0 MEM 10000.0 Slots 40 ] Total [ CPU 6100.0 MEM 10000.0 Slots 40 ]
//generate another rack of supervisors with less resources than rack-0
rack-1 Avail [ CPU 2000.0 MEM 40000.0 Slots 40 ] Total [ CPU 2000.0 MEM 40000.0 Slots 40 ]
//best rack to choose
rack-0 Avail [ CPU 4000.0 MEM 80000.0 Slots 40( ] Total [ CPU 4000.0 MEM 80000.0 Slots 40 ]
Cluster Overall Avail [ CPU 12200.0 MEM 410000.0 Slots 200 ] Total [ CPU 12200.0 MEM 410000.0 Slots 200 ]
```
很明顯,機架0是最平衡的最佳集群,可以安排最多的執行器,而機架2是機架2耗盡 cpu 資源的最差機架,因此即使有其他的可用資源
我們首先計算每個資源的所有機架的資源可用性百分比:
```
(resource available on rack) / (resource available in cluster)
```
我們做這個計算來歸一化值,否則資源值將不可比較。
所以我們的例子:
```
rack-3 Avail [ CPU 0.819672131147541% MEM 48.78048780487805% Slots 20.0% ] effective resources: 0.00819672131147541
rack-2 Avail [ 0.0% MEM 19.51219512195122% Slots 20.0% ] effective resources: 0.0
rack-4 Avail [ CPU 50.0% MEM 2.4390243902439024% Slots 20.0% ] effective resources: 0.024390243902439025
rack-1 Avail [ CPU 16.39344262295082% MEM 9.75609756097561% Slots 20.0% ] effective resources: 0.0975609756097561
rack-0 Avail [ CPU 32.78688524590164% MEM 19.51219512195122% Slots 20.0% ] effective resources: 0.1951219512195122
```
機架的有效資源也是下屬資源,計算方法如下:
```
MIN(resource availability percentage of {CPU, Memory, # of free Slots}).
```
然后我們用有效的資源訂購機架。
因此我們的例子:
```
Sorted rack: [rack-0, rack-1, rack-4, rack-3, rack-2]
```
該 metric 用于對節點和機架進行排序。在分類機架時,我們考慮機架上和整個集群中可用的資源(包含所有機架)。在分類節點時,我們考慮節點上可用的資源和機架中可用的資源(機架中所有節點可用的所有資源的總和)
原始 Jira 為此增強: [STORM-1766](https://issues.apache.org/jira/browse/STORM-1766)
### 計劃改進
本節提供了一些關于性能優勢的實驗結果,其中包括在原始調度策略之上的增強功能。實驗基于運行模擬:
[https://github.com/jerrypeng/storm-scheduler-test-framework](https://github.com/jerrypeng/storm-scheduler-test-framework)
模擬中使用隨機 topology 和集群,以及由雅虎所有 storm 集群中運行的所有真實 topology 結構組成的綜合數據集。
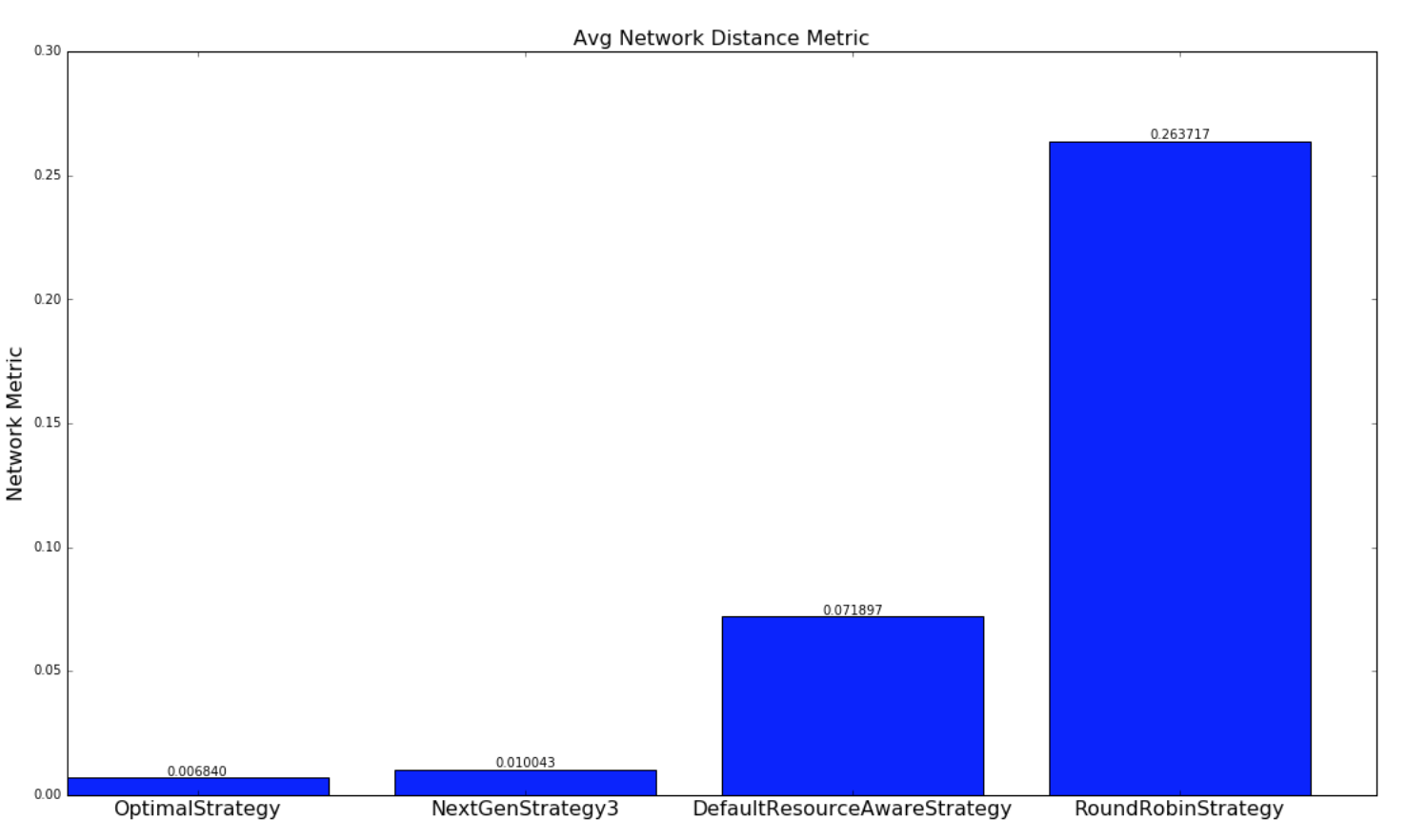
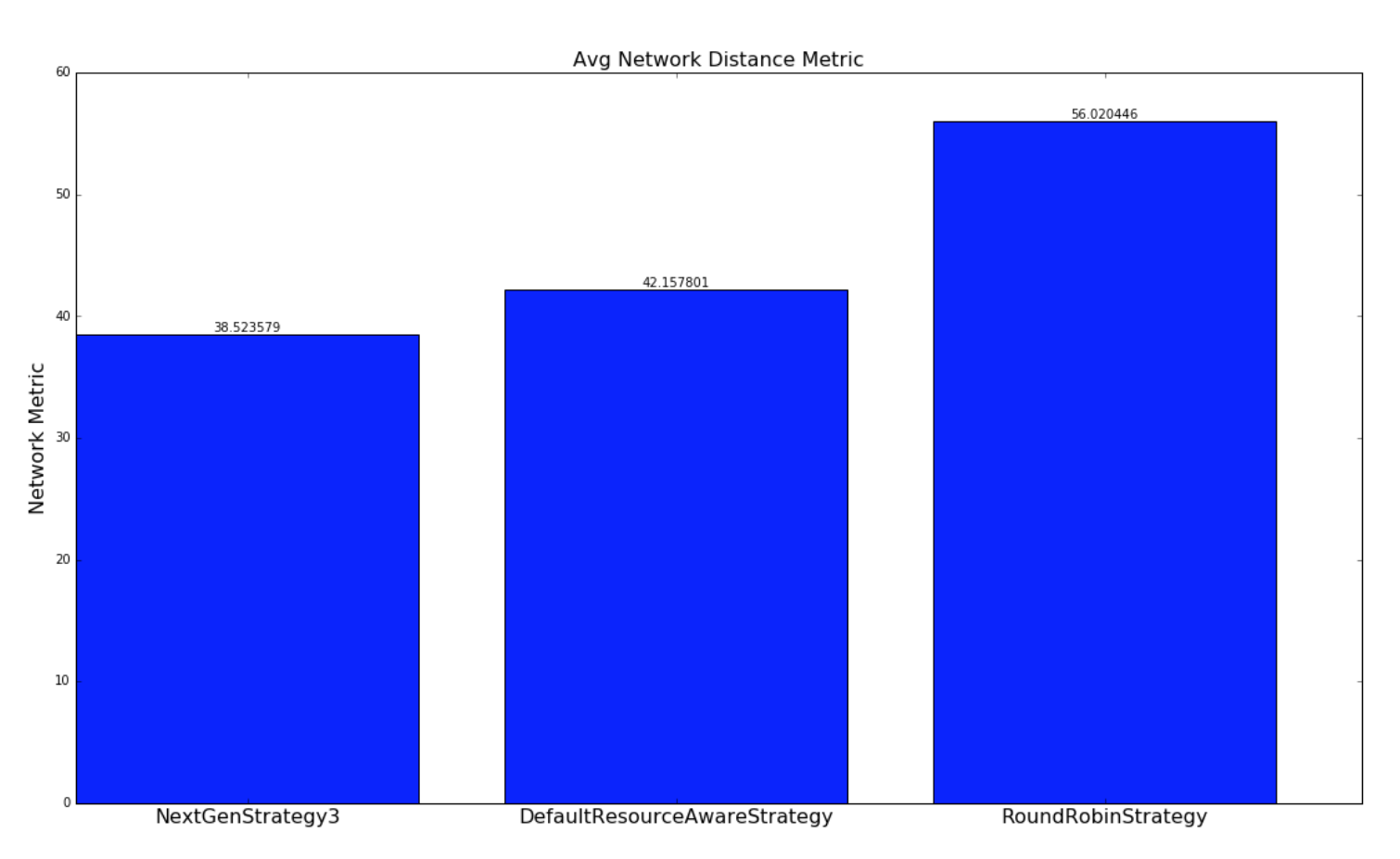
下圖提供了各種策略調度 topology 結構以最小化網絡延遲的比較。 通過每個調度策略為 topology 的每個調度計算一個網絡 metric。 網絡 metric 是根據 topology 中的每個 executor 對駐留在同一個工作程序(JVM進程)中的另一個 executor,在不同的 worker 但是相同的主機,不同的主機,不同的機架上進行的連接進行計算的。 我們所做的假設如下:
1. Intra-worker 之間的溝通是最快的
2. Intra-worker 之間的溝通很快
3. Inter-node 間通信速度較慢
4. Inter-rack 間通信是最慢的
對于此網絡 metric,數量越大,topology 結構對于此調度將具有更多的潛在網絡延遲。進行兩種實驗。 使用隨機生成的 topology 進行一組實驗,并隨機生成簇。 另一組實驗使用包含基于 topology 大小的 yahoo 和 semi-randomly 生成的集群中的所有運行 topology 的數據集執行。兩組實驗都運行數百萬次迭代,直到結果收斂。
對于涉及隨機生成的 topology 結構的實驗,實現了一種最優策略,如果存在解決方案,則會極大地找到最優解。本實驗中使用的 topology 和簇相對較小,以便最優策略遍歷解空間,以在合理的時間內找到最優解。 由于 topology 很大,并且運行時間不合理,所以這種策略并不適用于雅虎 topology,因為解決方案空間是 W ^ N(在工作中無關緊要),其中 W 是工作人員的數量, N 是執行者的數量。NextGenStrategy 代表具有這些增強功能的調度策略。DefaultResourceAwareStrategy 表示原始調度策略。RoundRobinStrategy 代表了一種 naive 策略,它簡單地以循環方式安排執行者,同時遵守資源約束。 下圖顯示了網絡度量的平均值。CDF 圖也進一步呈現。
| Random Topologies | Yahoo topologies |
| --- | --- |
|  |  |
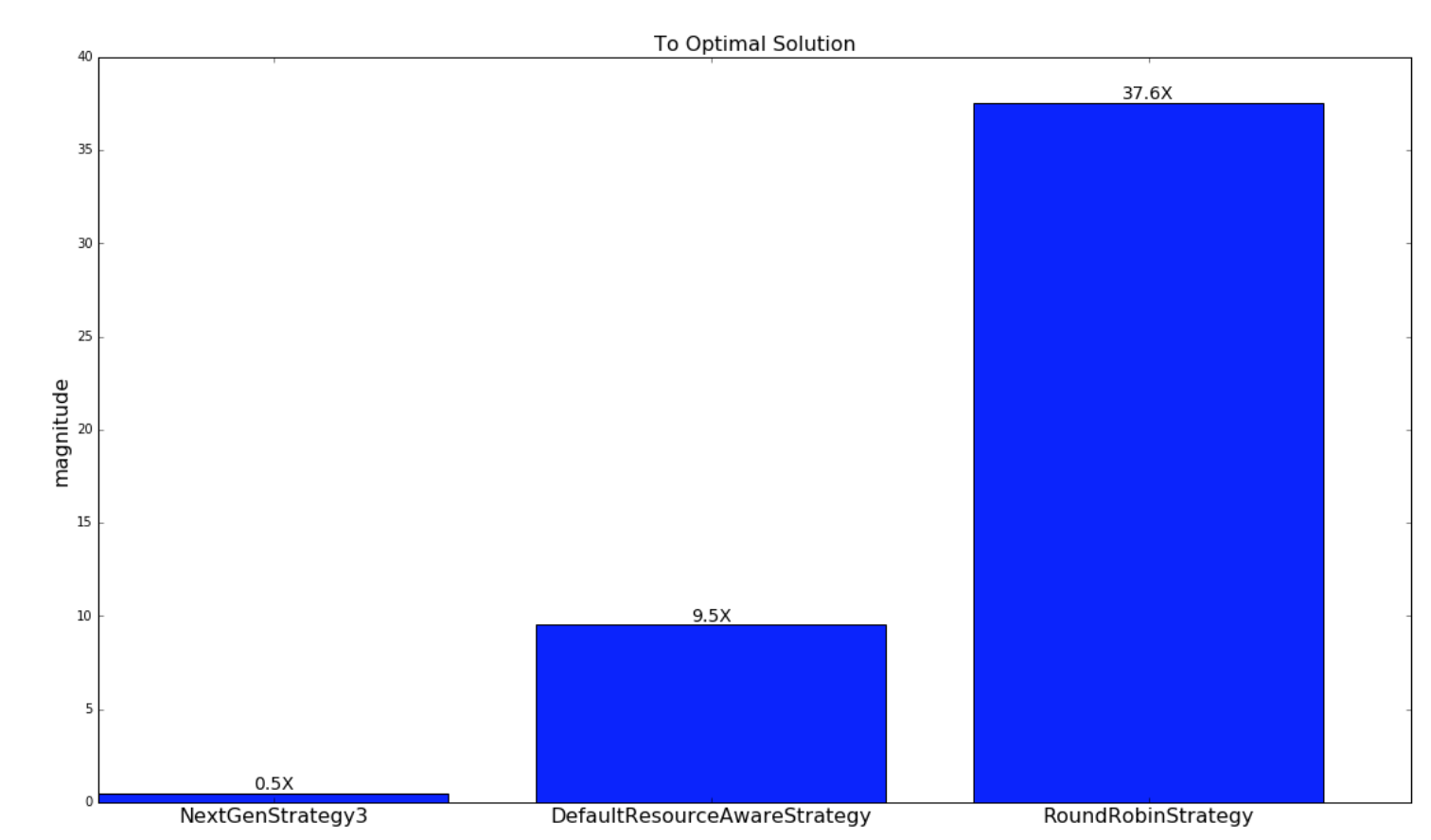
下一個圖表顯示了從各自的調度策略的調度到最優策略的調度的接近程度。如前所述,這僅適用于隨機生成的 topology 和集群。
| Random Topologies |
| --- |
|  |
下圖是網絡 metric 的 CDF:
| Random Topologies | Yahoo topologies |
| --- | --- |
| 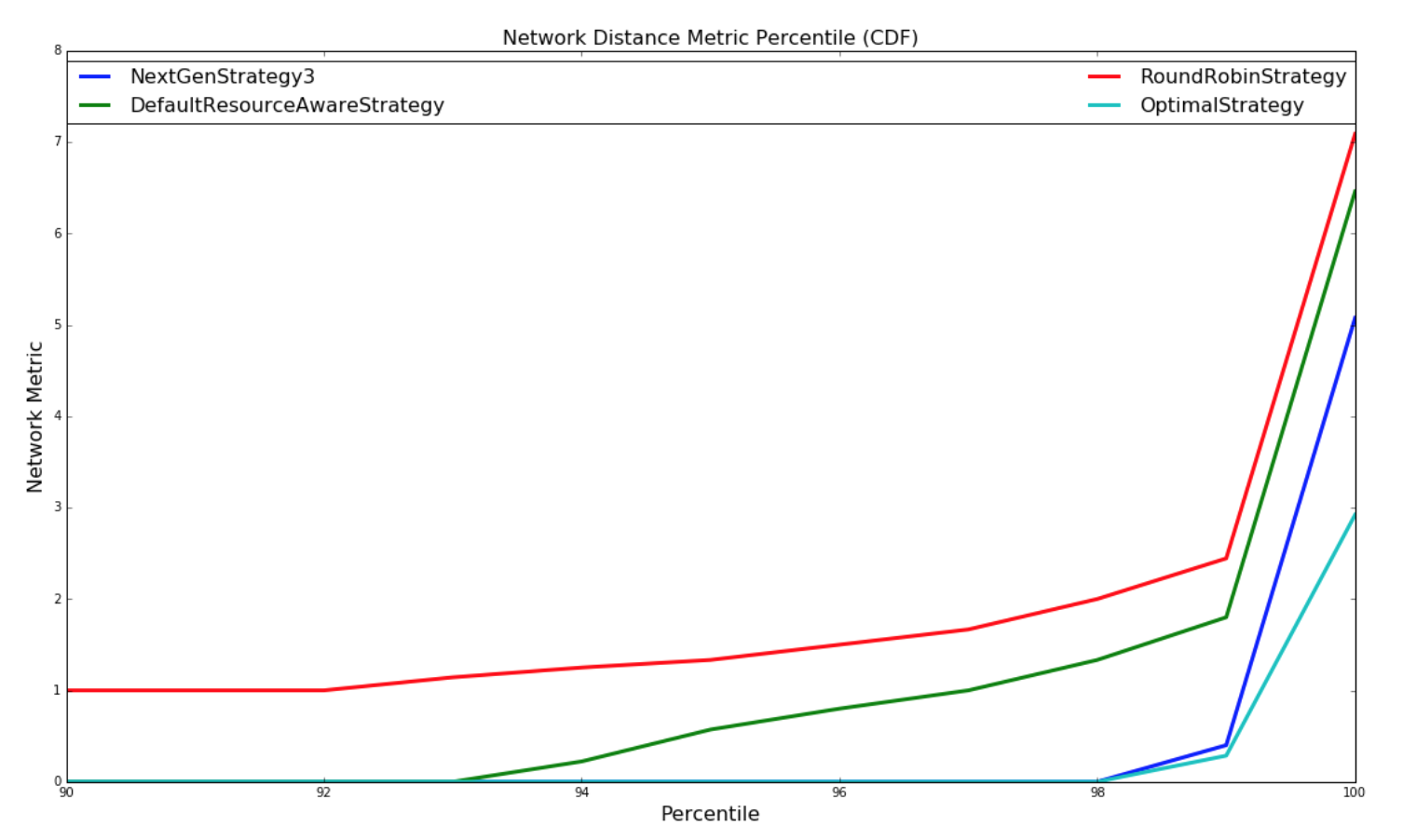 | 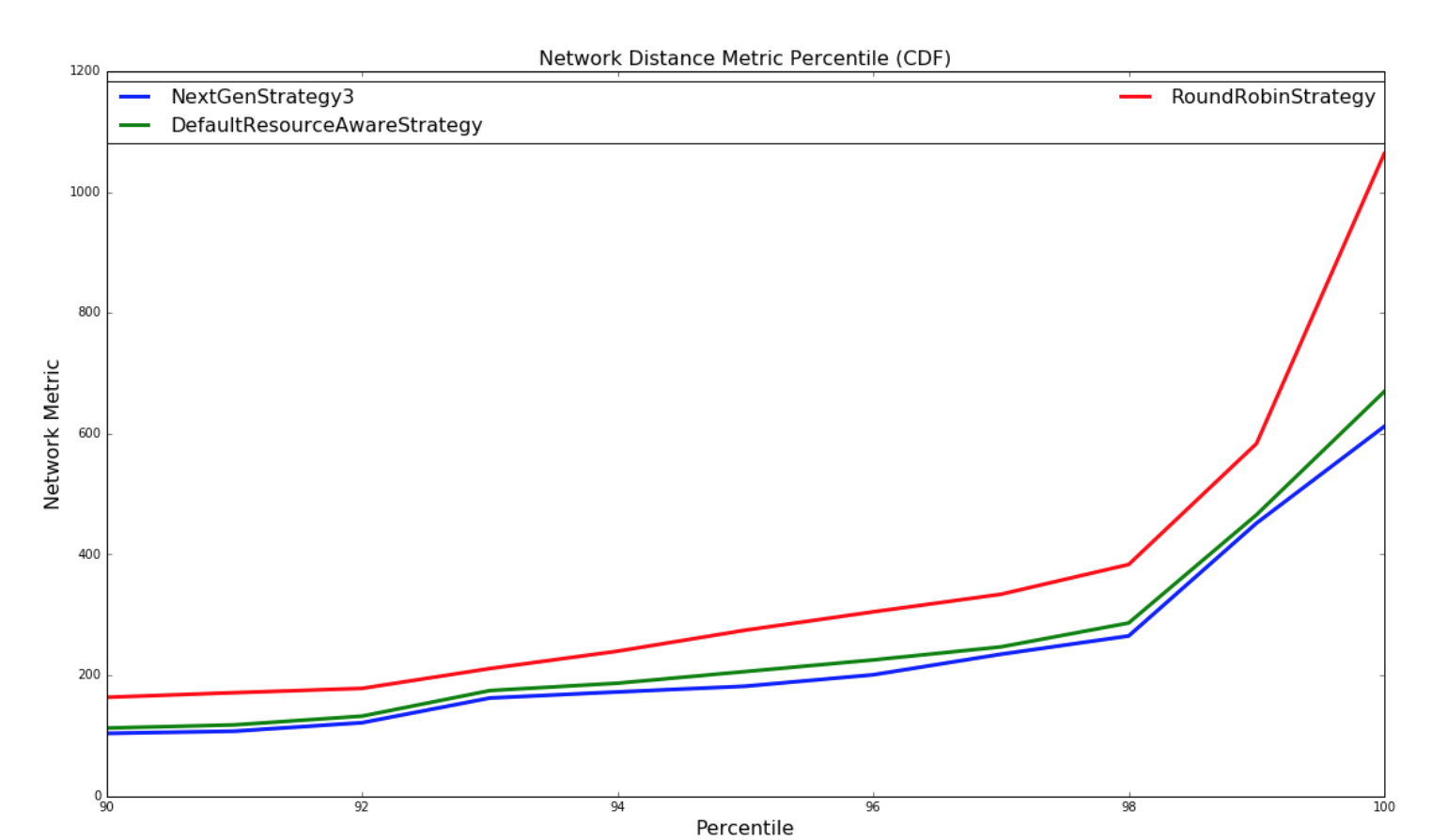 |
以下是策略運行多長時間的比較:
| Random Topologies | Yahoo topologies |
| --- | --- |
| 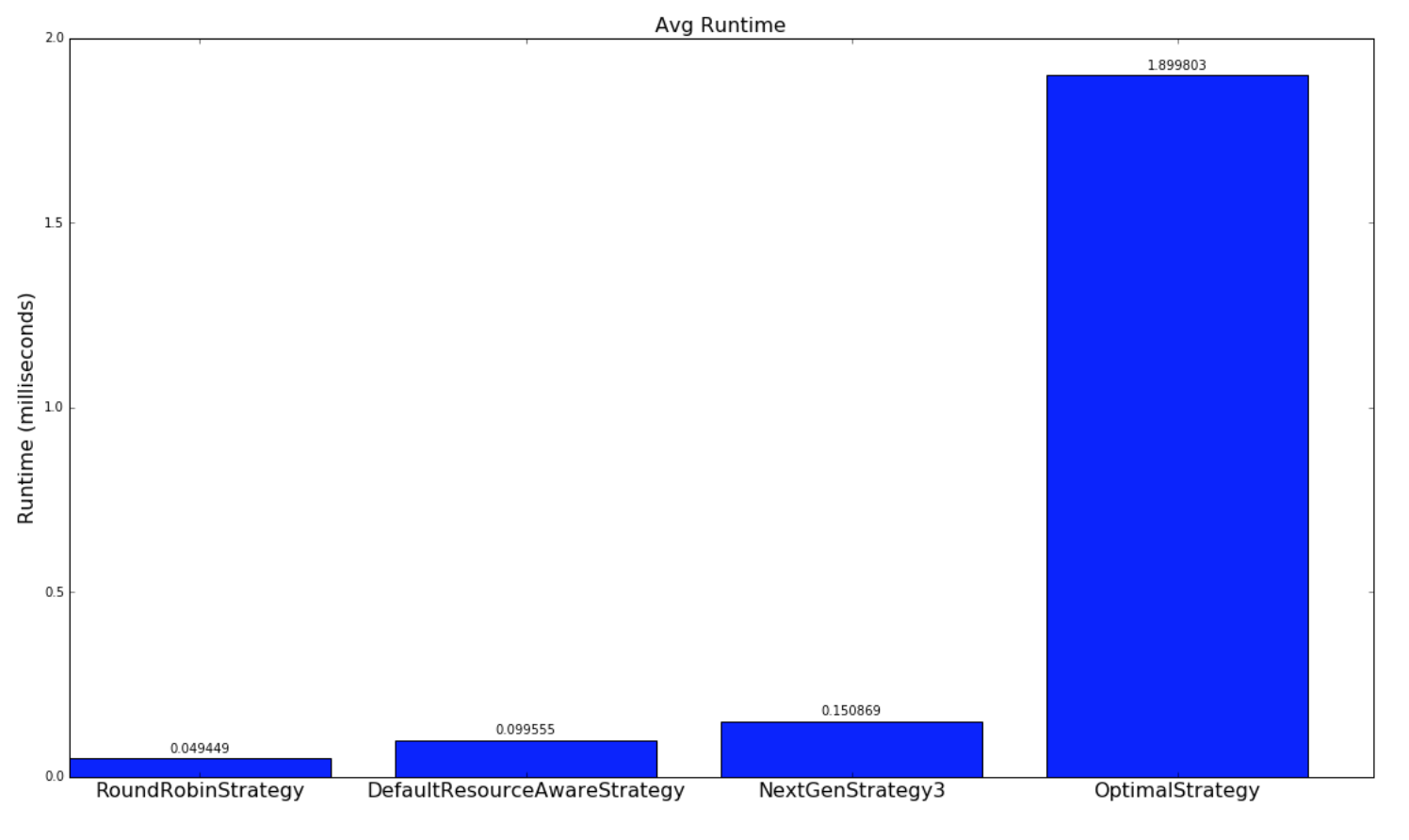 | 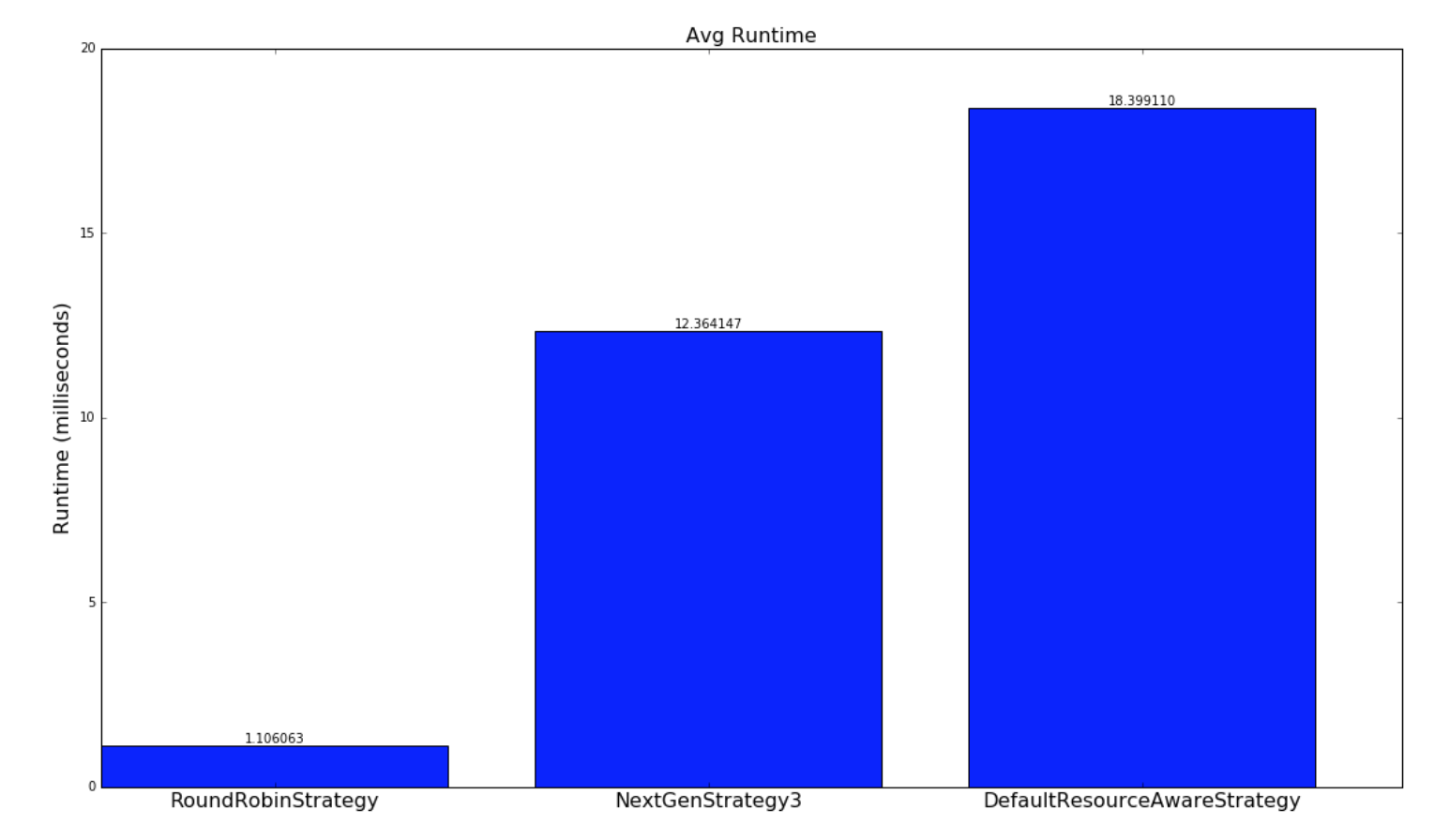 |
- Storm 基礎
- 概念
- Scheduler(調度器)
- Configuration
- Guaranteeing Message Processing
- 守護進程容錯
- 命令行客戶端
- Storm UI REST API
- 理解 Storm Topology 的 Parallelism(并行度)
- FAQ
- Layers on Top of Storm
- Storm Trident
- Trident 教程
- Trident API 綜述
- Trident State
- Trident Spouts
- Trident RAS API
- Storm SQL
- Storm SQL 集成
- Storm SQL 示例
- Storm SQL 語言參考
- Storm SQL 內部實現
- Flux
- Storm 安裝和部署
- 設置Storm集群
- 本地模式
- 疑難解答
- 在生產集群上運行 Topology
- Maven
- 安全地運行 Apache Storm
- CGroup Enforcement
- Pacemaker
- 資源感知調度器 (Resource Aware Scheduler)
- 用于分析 Storm 的各種內部行為的 Metrics
- Windows 用戶指南
- Storm 中級
- 序列化
- 常見 Topology 模式
- Clojure DSL
- 使用沒有jvm的語言編輯storm
- Distributed RPC
- Transactional Topologies
- Hooks
- Storm Metrics
- Storm 狀態管理
- Windowing Support in Core Storm
- Joining Streams in Storm Core
- Storm Distributed Cache API
- Storm 調試
- 動態日志級別設置
- Storm Logs
- 動態員工分析
- 拓撲事件檢查器
- Storm 與外部系統, 以及其它庫的集成
- Storm Kafka Integration
- Storm Kafka 集成(0.10.x+)
- Storm HBase Integration
- Storm HDFS Integration
- Storm Hive 集成
- Storm Solr 集成
- Storm Cassandra 集成
- Storm JDBC 集成
- Storm JMS 集成
- Storm Redis 集成
- Azue Event Hubs 集成
- Storm Elasticsearch 集成
- Storm MQTT(Message Queuing Telemetry Transport, 消息隊列遙測傳輸) 集成
- Storm MongoDB 集成
- Storm OpenTSDB 集成
- Storm Kinesis 集成
- Storm Druid 集成
- Storm and Kestrel
- Container, Resource Management System Integration
- Storm 高級
- 針對 Storm 定義一個不是 JVM 的 DSL
- 多語言協議
- Storm 內部實現
- 翻譯進度