
# Distributed RPC
distributed RPC(分布式RPC) (DRPC) 的設計目的是充分利用Storm的計算能力實現高密度的并行實時計算。Storm topology(拓撲)接受若干個函數參數作為輸入,然后輸出這些函數調用的結果。
嚴格的來說,DRPC不能夠算作Storm的一個特性,因為它是一種基于Storm 原語(Stream,Spout,Bolt,Topology)實現的設計模式。DRPC可以脫離Storm,打包出來作為一個獨立的庫,但是它和Storm集成在一起更有用。
### High level 概述
Distributed RPC通過 "DRPC sever"(Storm包含了這個實現)來進行協調。DRPC server 負責接收 RPC 請求,發送請求到 Storm 對應的 topology(拓撲),再從 Storm topology(拓撲)上得到結果,最后發送給等待的客戶端。從客戶端的角度來看,DRPC調用和普通的RPC調用沒有什么區別。例如,以下是一個使用參數 "[http://twitter.com",調用](http://twitter.com%22%EF%BC%8C%E8%B0%83%E7%94%A8) "reach" 函數計算結果的例子:
```
DRPCClient client = new DRPCClient("drpc-host", 3772);
String result = client.execute("reach", "http://twitter.com");
```
Distributed RPC 工作流如下:
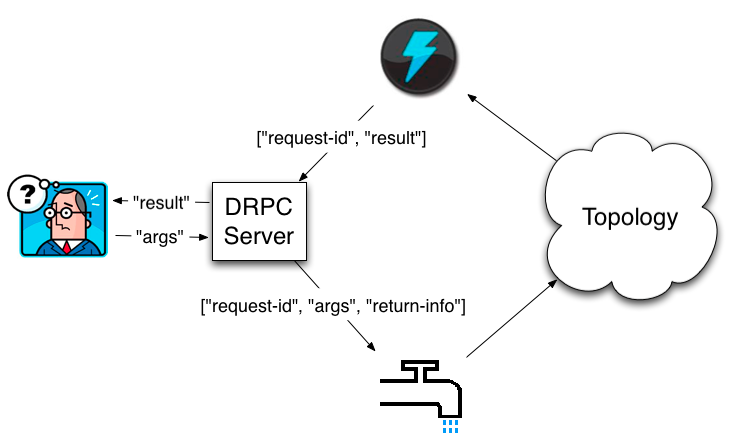
客戶端發送要調用的函數名稱和函數所需參數到 DRPC server。實現該函數的 topology(拓撲)使用一個 DRPCSpout 從 DRPC server 接收一個 function invocation stream (函數調用流)。DRPC sever 每一個函數調用都會給予一個唯一性的 id , topology(拓撲)計算完結果,使用一個叫做 `ReturnResults` 的 bolt 連接到DRPC server,根據函數調用的 id 將結果返回。 DRPC sever 使用 id 來匹配client等待的是哪個結果,unblock 等待的client,將結果返回。
### LinearDRPCTopologyBuilder
Storm 有一個 topology(拓撲) 構造器叫 [LinearDRPCTopologyBuilder](javadocs/org/apache/storm/drpc/LinearDRPCTopologyBuilder.html),可以自動化 DRPC 所涉及的幾乎所有步驟,這些包括:
1. 建立 spout
2. 返回結果到 DRPC server
3. 給 bolts 提供聚合 tuples 的功能
我們一起來看一個簡單的例子。下面實現了一個DRPC togology(拓撲),返回輸入參數添加一個"!"。
```
public static class ExclaimBolt extends BaseBasicBolt {
public void execute(Tuple tuple, BasicOutputCollector collector) {
String input = tuple.getString(1);
collector.emit(new Values(tuple.getValue(0), input + "!"));
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("id", "result"));
}
}
public static void main(String[] args) throws Exception {
LinearDRPCTopologyBuilder builder = new LinearDRPCTopologyBuilder("exclamation");
builder.addBolt(new ExclaimBolt(), 3);
// ...
}
```
正如你所看到的,我們需要做的事情非常少。當創建 `LinearDRPCTopologyBuilder` 的時候,你告訴它相應topology(拓撲)的 DRPC 函數名稱。一個單一的 DRPC sever 可以協調很多函數,函數與函數之間使用函數名稱進行區分。你聲明的第一個bolt 會得到一個二維的 tuple,tuple的第一個參數是 request id ,第二個字段是請求的參數。 `LinearDRPCTopologyBuilder` 希望最后一個 bolt 會輸出一個二維的[id,result]格式的輸出流。最后,所有中間結果產生的 tuples 必須包含 request id 作為第一個字段。
在這個例子中,`ExclaimBolt` 簡單的在 tuple 的第二個 field 后添加了一個 "!" 符合。`LinearDRPCTopologyBuilder` 幫我們協調處理了這些事情:連接 DRPC server,并將結果返回。
### DRPC 本地模式
DRPC 可以以本地模式運行,下面是以本地模式運行上面例子的代碼:
```
LocalDRPC drpc = new LocalDRPC();
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("drpc-demo", conf, builder.createLocalTopology(drpc));
System.out.println("Results for 'hello':" + drpc.execute("exclamation", "hello"));
cluster.shutdown();
drpc.shutdown();
```
首先你創建一個 `LocalDRPC` 對象。這個對象在進程內模擬了一個 DRPC server,就像 `LocalCluster` 在進程內模擬一個storm集群。然后創建 `LocalCluster` 對象在本地模式運行topology(拓撲)。`LinearDRPCTopologyBuilder` 有單獨的方法創建本地 topology(拓撲)和遠程的topolgy(拓撲)。在本地模式里面,`LocalDRPC` 對象不會和任何端口綁定,所以 topology(拓撲)需要知道對象和哪個 DRPC 交互。這就是為什么`createLocalTopology` 需要一個 `LocalDRPC` 作為輸入。
啟動 `topology`(拓撲)后,你可以使用 `LocalDRPC` 的 `execute` 方法做 DRPC 調用。
### DRPC遠程模式
在一個真實集群上面使用DRPC也是非常簡單的,有三個步驟:
1. 啟動 DRPC servers
2. 配置 DRPC severs 的地址
3. 提交 DRPC topologies(DRPC 拓撲)到Storm集群。
可以使用 `storm` 腳本啟動一個DRPC server,就像啟動 Nimbus 和 UI 節點一樣。
```
bin/storm drpc
```
下一步,你可以配置 Storm 集群知道 DRPC sever(s) 的地址。`DRPCSpout` 需要知道這個DRPC地址,從而得到函數調用的請求。這個可以配置 `storm.yaml` 文件或者通過代碼配置在 topology(拓撲)參數中。通過 storm.yaml 配置像下面這樣:
```
drpc.servers:
- "drpc1.foo.com"
- "drpc2.foo.com"
```
最后,你使用 `StormSubmitter` 運行 DRPC topologies(拓撲),和你提交其他 topologies 一樣。如果要以遠程調用的方式運行上面的例子,用下面的代碼:
```
StormSubmitter.submitTopology("exclamation-drpc", conf, builder.createRemoteTopology());
```
`createRemoteTopology` 是用來創建符合 Storm cluster 的 topologies(拓撲).
### 一個更復雜的例子
上面的例子只是用來說明 DRPC 的概念。我們來看一個更復雜的例子,需要使用 Storm 并行計算的 DRPC 功能。我們將看到這個例子是用來計算 Twitter 上每個URL的訪問量(reach)。
一個URL的訪問量(reach)是每個在Twitter上的URL暴露給不同的人的數量。為了計算訪問量,你需要:
1. 得到所有 tweet 這個 URL 的人。
2. 得到步驟1中所有人的粉絲
3. 對所有粉絲進行去重
4. 對步驟3的粉絲求和。
單個 URL 的訪問量計算會涉及成千上萬次數據庫調用以及數以百萬的粉絲記錄。這是一個很大很大的計算量。正如你即將看到的,在 Storm 上實現這個功能是很簡單的。在單機上,訪問量可能需要幾分鐘才能完成;在 Storm 集群上,即使是很難計算的 URLs 也會在幾秒內計算出訪問量。
一個訪問量的 topology 的例子定義在 storm-starter:[這里](http://github.com/apache/storm/blob/master%0A/examples/storm-starter/src/jvm/org/apache/storm/starter/ReachTopology.java)。下面是你如何定義這個訪問量的topology。
```
LinearDRPCTopologyBuilder builder = new LinearDRPCTopologyBuilder("reach");
builder.addBolt(new GetTweeters(), 3);
builder.addBolt(new GetFollowers(), 12)
.shuffleGrouping();
builder.addBolt(new PartialUniquer(), 6)
.fieldsGrouping(new Fields("id", "follower"));
builder.addBolt(new CountAggregator(), 2)
.fieldsGrouping(new Fields("id"));
```
這個topolgoy(拓撲)執行有四個步驟:
1. `GetTweeters` 得到tweet指定URL的用戶列表。這個Bolt將輸入流 `[id, url]` 轉換成輸出流 `[id, tweeter]`。每個 `url` tuple 被映射成多個`tweeter` tuples。
2. `GetFollowers` 得到步驟1 tweeters的followers。該Bolt將輸入流 `[id, tweeter]` 轉換成 `[id, follower]`。在所有的任務中,當有人是多個 tweet 相同 url 的粉絲,那么 follower 的tuple就會重復。
3. `PartialUniquer` 按照follower id 對followers流進行分組。相同的follower進入同一個任務。所以`PartialUniquer` 的每個任務會收到完全獨立的followers結果集。一旦 `PartialUniquer` 接受到針對request id 的所有 follower tuple,就會發出它 followers 子集的計數。
4. 最后,`CountAggregator` 獲取到每一個 `PartialUniquer` 任務中接受到部分結果,累加結果后計算出訪問量。
我們來看一下 `PartialUniquer` bolt:
```
public class PartialUniquer extends BaseBatchBolt {
BatchOutputCollector _collector;
Object _id;
Set<String> _followers = new HashSet<String>();
@Override
public void prepare(Map conf, TopologyContext context, BatchOutputCollector collector, Object id) {
_collector = collector;
_id = id;
}
@Override
public void execute(Tuple tuple) {
_followers.add(tuple.getString(1));
}
@Override
public void finishBatch() {
_collector.emit(new Values(_id, _followers.size()));
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("id", "partial-count"));
}
}
```
`PartialUniquer` 繼承 `BaseBatchBolt` 實現了 `IBatchBolt` 接口。一個 batch bolt 提供了將一批tuples 作為整體進行處理的API。每一個 request id 都會創建一個新的 batch bolt 實例,Storm會在適合時候負責清理實例。
當 `PartialUniquer` 在 `execute` 方法中接受到一個 follower tuple,將 follower 添加到 request id 對應的 `HashSet`。
Batch bolt 提供了 `finishBatch` 方法,當這個任務的batch 所有的 tuples 處理完后進行調用。這次調用中,`PartialUniquer` 發送一個 tuple,包含 followers id 去重后的數量。
在內部實現上,`CoordinatedBolt` 用于檢測指定的 bolt 是否已經收到指定 request id 的所有 tuples 元組。`CoordinatedBolt` 使用 direct streams 管理這個協調過程。
topology 的其他部分是容易理解。正如你看到,訪問量計算的每一個步驟都是并行的,通過DRPC實現也是非常容易的。
### Non-linear DRPC topologies(拓撲)
`LinearDRPCTopologyBuilder` 只處理 "linear" DRPC 拓撲,計算過程可以像計算訪問量一樣分解成一系列步驟。不難想象,這需要一個更加復雜的 topology(拓撲),帶有分支和合并的 bolts。現在,要完成這種計算,你需要放棄直接使用 `CoordinatedBolt`。請務必在郵件列表中討論關于 non-linear DRPC topologies(拓撲)的應用場景,以便為 DRPC topologies(拓撲)提供更一般的抽象。
### LinearDRPCTopologyBuilder 是如何運行的。
* DRPCSpout 發出 [args, return-info],其中 return-info 包含 DRPC Server的主機和端口號,以及 DRPC Server 為該次請求生成的唯一id號
* 構造一個 Storm 拓撲包含以下部分:
* DRPCSpout
* PrepareRequest(生成一個請求id,為return info創建一個流,為args創建一個流)
* CoordinatedBolt wrappers和direct groupings
* JoinResult(將結果與return info拼接起來)
* ReturnResult(連接到DRPC Server,返回結果)
* LinearDRPCTopologyBuilder是建立在Storm基本元素之上的高層抽象。
### Advanced
* KeyedFairBolt 用于組織同一時刻多個請求的處理過程
* 如何直接使用 `CoordinatedBolt`
- Storm 基礎
- 概念
- Scheduler(調度器)
- Configuration
- Guaranteeing Message Processing
- 守護進程容錯
- 命令行客戶端
- Storm UI REST API
- 理解 Storm Topology 的 Parallelism(并行度)
- FAQ
- Layers on Top of Storm
- Storm Trident
- Trident 教程
- Trident API 綜述
- Trident State
- Trident Spouts
- Trident RAS API
- Storm SQL
- Storm SQL 集成
- Storm SQL 示例
- Storm SQL 語言參考
- Storm SQL 內部實現
- Flux
- Storm 安裝和部署
- 設置Storm集群
- 本地模式
- 疑難解答
- 在生產集群上運行 Topology
- Maven
- 安全地運行 Apache Storm
- CGroup Enforcement
- Pacemaker
- 資源感知調度器 (Resource Aware Scheduler)
- 用于分析 Storm 的各種內部行為的 Metrics
- Windows 用戶指南
- Storm 中級
- 序列化
- 常見 Topology 模式
- Clojure DSL
- 使用沒有jvm的語言編輯storm
- Distributed RPC
- Transactional Topologies
- Hooks
- Storm Metrics
- Storm 狀態管理
- Windowing Support in Core Storm
- Joining Streams in Storm Core
- Storm Distributed Cache API
- Storm 調試
- 動態日志級別設置
- Storm Logs
- 動態員工分析
- 拓撲事件檢查器
- Storm 與外部系統, 以及其它庫的集成
- Storm Kafka Integration
- Storm Kafka 集成(0.10.x+)
- Storm HBase Integration
- Storm HDFS Integration
- Storm Hive 集成
- Storm Solr 集成
- Storm Cassandra 集成
- Storm JDBC 集成
- Storm JMS 集成
- Storm Redis 集成
- Azue Event Hubs 集成
- Storm Elasticsearch 集成
- Storm MQTT(Message Queuing Telemetry Transport, 消息隊列遙測傳輸) 集成
- Storm MongoDB 集成
- Storm OpenTSDB 集成
- Storm Kinesis 集成
- Storm Druid 集成
- Storm and Kestrel
- Container, Resource Management System Integration
- Storm 高級
- 針對 Storm 定義一個不是 JVM 的 DSL
- 多語言協議
- Storm 內部實現
- 翻譯進度