
# Transactional Topologies
**請注意**: Transactional topologies 已經摒棄 -- 使用 [Trident](Trident-tutorial.html) 框架替代。
* * *
Storm [guarantees data processing](Guaranteeing-message-processing.html) (保證數據處理)至少一次。關于 Storm 問的最多的問題就是 "當 tuples 重發時,你會如何做呢?你會重復計算嗎?"
Storm 0.7.0 版本介紹了 transactional topologies.使得你可以在復雜的計算中做到 exactly once 的消息語義.所以你可以以一種完全精準的,可伸縮,容錯的方式執行程序。
和 [Distributed RPC](Distributed-RPC.html)一樣,transactional topologies 并不是Storm的一種功能,而是基于 Storm 原語(streams,spouts,bolts,topologies)構建的高級抽象。
這一頁用來解釋 transactional topology 抽象,如何使用API,并提供API實現的細節。
## Concepts
我們一起來構建 transactional topologies (事務性拓撲)的第一步.我們先從簡單的方法開始,不斷的完善達到我們想要的設計。
### Design 1
transactional topologies (事務性拓撲) 背后核心的思想就是對數據的處理提供嚴格的順序性.嚴格的順序性就是說,在處理tuples的時候,topology(拓撲)將當前 tuple 成功處理完后才可以進行下一個 tuple 處理。
每個tuple 都和一個 transaction id 關聯.當 tuple 失敗需要重新處理的時候,tuple 會綁定相同的 transaction id 重新發送.tuple 的transaction id 是自增長的,所以第一個 tuple 的 transaction id 是`1`,第二個就是`2`,以此類推.
tuples的嚴格順序性使得你在 tuple 重新處理的時候可以保證 exactly-once語義.我們來看一個例子。
假設你想要計算 stream中 tuples的總數.原來你可能只會將 count 總數存儲在數據庫中,但是你現在將 count 總數和最新的 transaction id 存儲在數據庫中。在程序更新 db 中的count的時候,只有_當數據庫中的transaction id和當前處理的 tuple 的transaction id 不同的時候_,才會更新 count 總數.考慮下面兩種場景:
1. _數據庫中的 transaction id 和當前 transaction id 不同:_ 因為 transactions(事務)的嚴格順序性,我們可以確定當前的 tuple 并不代表 count 總數。所以我們安全的自增 count,并更新 transaction id。
2. _數據庫中的 transaction id 和當前 transaction id 相同:_ 那么我們知道這個 tuple 已經被并入計數,可以跳過更新.這個 tuple 一定在第一次更新數據庫之后失敗過,在第二次處理成功后匯報之前.
這種合理的和強一致性的事務保證了如果tuple失敗了重新處理,保存在數據庫中的count也是準確的. 將 transaction id 存儲到數據庫和將 value 發送到kafka 設計是一樣的,可以看 [this design document](http://incubator.apache.org/kafka/07/design.html).
另外,topology 可以在相同的事務中的更新許多狀態源,并保證 exactly-once 語義.如果有失敗,成功更新的會跳過重試,失敗更新的會進行重試. 例如,你要處理 tweeted urls 的stream,你可以存儲每一個 url 的 tweet 數量,也可以存儲每一個 domain(域名)的 tweet 數量.
上面這種設計對在某一時刻處理一個 tuple 有一個比較嚴重的問題。必須等待每個 tuple 處理完成后,才可以進行下一個處理,這是非常低效的.這種設計需要大量的數據庫調用(至少每個 tuple 一次),這個設計很少用到并行,所以它不是可擴展的.
### Design 2
相對于一次只能處理一個 tuple,更好的方式就是在每個 transaction(事務)中批處理 tuples.所以如果你要做一個全局的計數,每次增加的是整個 batch 的數量.如果 batch 失敗了,你需要重新處理這個失敗的 batch . 相比于之前你要對每一個 tuple 分配一個 transaction id,現在是對每個 batch 分配一個 transaction id。并且處理 batch 也是嚴格有序的.下面是這個設計的圖表:
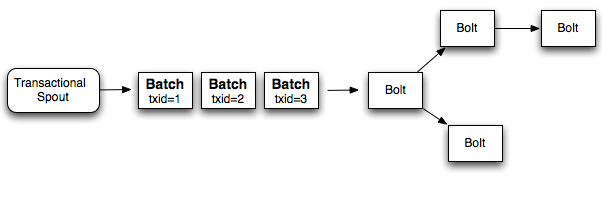
所以如果你每一個 batch 處理 1000 個 tuples,相比于 design 1(設計1)你會少做 1000x 數量級的 數據庫操作.另外,這種設計利用了 Storm 的并行計算特性,每一個batch都可以并行計算.
雖然這種設計優于 design 1(設計1),但是它仍然不能有效的利用資源.topology中的workers會花費大量的時間等待其他部分的計算完成。例如,一個 topology(拓撲)像下面這樣:

當 bolt 1 完成部分處理后,它所在的 worker 將是空閑的,直到剩余的 bolt 完成后,下一個 batch 才會從spout發送出來.
### Design 3 (Storm's design)
一個關鍵的實現就是并不是所有處理 batch 的工作都要嚴格有序。例如,當計算一個全局計數,需要計算兩部分:
1. 計算每一個 batch 的局部 count
2. 通過局部 count 更新數據庫里的全局 count
第二部分在計算 batch 過程中需要嚴格有序,但是沒有理由不并行計算第一部分。所以當 batch 1 正在更新數據庫時,batch 2到10 可以計算他們的局部 count.
Storm 不同之處在于將 batch 計算分成兩部分來完成:
1. 處理階段:這個階段是可以并行處理 batches 的。
2. 提交階段:提交階段,batches是嚴格有序的.所以 batch 2必須等到 batch 1提交成功后才可以進行提交.
這兩個階段合起來稱之為 “transaction”(事務)。許多 batch 在某一時間內處于處理階段,但只有一個 batch 處于提交階段。如果處理階段或者提交失敗有失敗的話,將重新處理 batch(兩個階段都會重新處理).
## Design details
當使用 transactional topologies ,Storm 為你提供以下信息:
1. _Manages state:_ Storm 執行 transactional topologies 的時候,將所有的狀態存儲到 zookeeper.其中包括當前的 transaction id,也包括定義每個 batch 參數的 metadata信息.
2. _Coordinates the transactions:_ Storm會管理一切必要的事情,來確定 transaction 什么時候處理或者提交.
3. _Fault detection:_ Storm利用acking框架來有效地確定批處理成功處理,成功提交或失敗的時間。Storm 然后會適當地重新處理 batch 。你不必做任何暗示或anchoring - Strom管理所有這一切。
4. _First class batch processing API_: Storm 在常規螺栓之上層疊一個API,以允許批量處理 tuples。 Storm管理所有協調,以確定任務何時已經接收到該特定事務的所有 tuples。Storm 也將照顧清理每筆交易的任何累計狀態(如部分計數)。
最后需要注意的是, transactional topologies(事務拓撲)需要一個可以重播一批精確信息的 source queue.像 [Kestrel](https://github.com/robey/kestrel) 是無法做到的. [Apache Kafka](http://incubator.apache.org/kafka/index.html) 非常適合當這個 spout, , 而且 [storm-kafka](https://github.com/apache/storm/tree/master/external/storm-kafka) 包含一個用于 Kafka 的事務性 spout 實現.
## The basics through example
你通過使用 [TransactionalTopologyBuilder](javadocs/org/apache/storm/transactional/TransactionalTopologyBuilder.html) 構建 transactional topologies .下面是一個 topology(拓撲)的 transactional topology 定義,用來計算輸入 tuples 的總數. 代碼來自于 storm-starter 的[TransactionalGlobalCount](http://github.com/apache/storm/blob/master%0A/examples/storm-starter/src/jvm/org/apache/storm/starter/TransactionalGlobalCount.java) .
```
MemoryTransactionalSpout spout = new MemoryTransactionalSpout(DATA, new Fields("word"), PARTITION_TAKE_PER_BATCH);
TransactionalTopologyBuilder builder = new TransactionalTopologyBuilder("global-count", "spout", spout, 3);
builder.setBolt("partial-count", new BatchCount(), 5)
.shuffleGrouping("spout");
builder.setBolt("sum", new UpdateGlobalCount())
.globalGrouping("partial-count");
```
`TransactionalTopologyBuilder` 將構造函數的輸入作為 transactional topology 的id,還有 topology 內的 spout id,一個事務性的 spout,還有事務性 spout 的并行度.transactional topology 的id 是用來在Zookeeper中存儲 topology 的處理狀態用的,以便如果重新啟動 topology后,將從停止的地方繼續運行.
transactional topology 有一個 `TransactionalSpout`,`TransactionalSpout`在`TransactionalTopologyBuilder` 構造器中定義.在這個例子中,`MemoryTransactionalSpout` 用于從內存中分區的數據源(`DATA`變量)中讀取數據。第二個參數定義數據的字段,第三個參數指定了每批 tuples 發出的 tuple最大數量.用于定義自己的 transactional spouts 將在本教程后面討論。
然后就是 bolts,這個 topology(拓撲)并行計劃全局 count.第一個 Bolt `BatchCount` 使用 shuffle grouping 隨機分割 input stream。第二個 Bolt `UpdateGlobalCount` 使用 global grouping,并將局部 count相加來獲取 batch count. 如果有需要,它會更新數據庫中的全局 count.
下面是 `BatchCount` 的定義:
```
public static class BatchCount extends BaseBatchBolt {
Object _id;
BatchOutputCollector _collector;
int _count = 0;
@Override
public void prepare(Map conf, TopologyContext context, BatchOutputCollector collector, Object id) {
_collector = collector;
_id = id;
}
@Override
public void execute(Tuple tuple) {
_count++;
}
@Override
public void finishBatch() {
_collector.emit(new Values(_id, _count));
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("id", "count"));
}
}
```
BatchCount 在每一個 bacth 被處理的時候,都會實例化.真正運行 bolt 的是 [BatchBoltExecutor](https://github.com/apache/storm/blob/0.7.0/src/jvm/org/apache/storm/coordination/BatchBoltExecutor.java) ,用來管理這些對象的創建和清理.
`prepare` 方法使用 Storm config,topology上下文,output collector,這個批次 tuples的id來進行參數設置。在transactional topologies(事務拓撲)中,id將是一個 [TransactionAttempt](javadocs/org/apache/storm/transactional/TransactionAttempt.html) 對象。這個 batch bolt 的后巷可以在 distributed rpc 中使用,也可以使用不同類型的id. `BatchBolt` 也可以使用 id 的類型配置參數,因此如果你打算在 transactional topologies(事務拓撲)中使用 batch bolt,你可以繼承`BaseTransactionalBolt`:
```
public abstract class BaseTransactionalBolt extends BaseBatchBolt<TransactionAttempt> {
}
```
所有在transactional topology(事務拓撲)中發送的 tuples 必須讓 `TransactionAttempt` 作為第一個字段,這可以讓Storm 知道 tuple屬于哪個 batch.所以當你發送 tuple的時候,必須保證這個要求.
`TransactionAttempt` 包含兩個值:"transaction id"和 "attempt id". "transaction id" 是batch的唯一性標識,同一個batch無論重復多少次處理,都不會改變. "attempt id" 是 batch中 tuple的唯一標識,Storm用來區分相同 batch中不同的tuples。 沒有 attempt id, Storm 可能會從 bacth發送之前開始重新處理。這是很可怕的.
每個 batch 發送的時候,transaction id 都加1.所以,第一個 batch 的id是1,第二個就是2,以此類推.
batch中的每個 tuple都會調用 `execute` 方法. 在每次調用這個方法的時候,你應該在本地實例變量中累計 batch 的狀態. `BatchCount` bolt 通過本地 counter 對每個 tuple 自增.
最后,當任務接受到指定的 batch 的所有tuples時,會調用 `finishBatch` 方法.當調用此方法時,`BatchCount` 會向 output stream 發出局部的count.
下面是 `UpdateGlobalCount` 的定義:
```
public static class UpdateGlobalCount extends BaseTransactionalBolt implements ICommitter {
TransactionAttempt _attempt;
BatchOutputCollector _collector;
int _sum = 0;
@Override
public void prepare(Map conf, TopologyContext context, BatchOutputCollector collector, TransactionAttempt attempt) {
_collector = collector;
_attempt = attempt;
}
@Override
public void execute(Tuple tuple) {
_sum+=tuple.getInteger(1);
}
@Override
public void finishBatch() {
Value val = DATABASE.get(GLOBAL_COUNT_KEY);
Value newval;
if(val == null || !val.txid.equals(_attempt.getTransactionId())) {
newval = new Value();
newval.txid = _attempt.getTransactionId();
if(val==null) {
newval.count = _sum;
} else {
newval.count = _sum + val.count;
}
DATABASE.put(GLOBAL_COUNT_KEY, newval);
} else {
newval = val;
}
_collector.emit(new Values(_attempt, newval.count));
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("id", "sum"));
}
}
```
`UpdateGlobalCount` 對于 transactional topologies 是特殊的,所以它繼承`BaseTransactionalBolt` 類.在 `execute` 方法中,`UpdateGlobalCount` 通過將局部 batch累加在一起得到此 batch 的count.有趣的事情發生在 `finishBatch` 方法中.
首先,你會看到這個 Bolt 實現了 `ICommitter` 接口.這就告訴Storm `finishBatch` 方法是事務提交階段的一部分.所以調用 `finishBatch` 將會按照 transaction id 嚴格有序(另一方面,execute的調用可能發生在處理階段或者提交階段)。將 Bolt 標記為 committer的另外一種方式就是 在 `TransactionalTopologyBuilder` 中使用`setCommitterBolt` 方法,而不是 `setBolt`。
`UpdateGlobalCount` 中的 `finishBatch` 的代碼從數據庫獲取當前值,并將 transaction id 與此批次的 transaction id 進行比較。如果他們是一樣的,它什么都不做。否則,數據庫中的值就增加此batch 的局部 count。
在 [TransactionalWords](http://github.com/apache/storm/blob/master%0A/examples/storm-starter/src/jvm/org/apache/storm/starter/TransactionalWords.java) 類中的storm-start中可以找到更多涉及到更新多個數據庫的transactional topology示例.
## Transactional Topology API
本節概述了事務拓撲API的不同部分。
### Bolts
transactional topology(事務拓撲)中有三種 Bolt:
1. [BasicBolt](javadocs/org/apache/storm/topology/base/BaseBasicBolt.html): 這個 Bolt 不處理 batches of tuples,只基于單個tuple輸入發送tuples.
2. [BatchBolt](javadocs/org/apache/storm/topology/base/BaseBatchBolt.html): 這個 Bolt 處理 batches of tuples,對于每個 tuple 調用`execute`,并在處理完 batch后調用 `finishBatch` 方法。
3. BatchBolt's that are marked as committers: 這個 Bolt 和常規的 `Batch Bolt` 之間的唯一區別是調用finishBatch時。Committer bolt 已經在提交階段調用`finishBatch` 方法。提交階段只有在所有先前 batch 成功提交之后才能保證發生,并且將重新嘗試,直到 topology(拓撲)結構中的所有 Bolt 成功完成批處理的提交。有兩種方式使 BatchBolt成為 committer,通過使`BatchBolt` 實現 [ICommitter](javadocs/org/apache/storm/transactional/ICommitter.html) 標記接口,或者通過在 `TransactionalTopologyBuilder` 中使用`setCommiterBolt` 方法.
#### Processing phase vs. commit phase in bolts
為了確定 transaction(事務)的處理階段和提交階段之間的差異,我們來看一個示例 topology(拓撲):
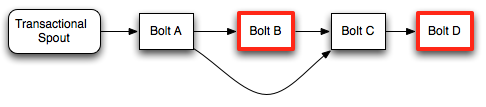
在這種 topology(拓撲)中,只有具有紅色輪廓的 Bolts 才是 committers。
在處理階段,Bolt A將從 Spout 處理完整的 batch ,調用 `finishBatch` 并將 tuples 發送到 Bolt B和C.Bolt B是一個 committer,因此它將處理所有的 tuple,但是不會調用 `finishBatch`。 Bolt C也不會有`finishBatch` 調用,因為它不知道它是否已經收到Bolt B的所有tuple(因為Bolt B正在等待事務提交)。最后,Bolt D將在其 `execute` 方法的調用期間接收 Bolt C 的tuple.
當 batch 提交時,將在Bolt B上調用 `finishBatch` 。一旦完成,Bolt C現在可以檢測到它已經接收到所有的 tuple,并將調用 `finishBatch`。最后,Bolt D將收到完整的 batch 并調用 `finishBatch`。
請注意,即使Bolt D是 committer,它在收到整個 batch 時也不必等待第二個提交消息。由于它在提交階段收到整個batch ,所以它將繼續并完成 transaction(事務)事務。
Committer bolts 在提交階段就像 batch bolts 那樣運行。committer bolts 和 batch bolts之間的唯一區別是committer bolts在 transaction(拓撲)的處理階段不會調用 `finishBatch`。
#### Acking
請注意,在使用transactional topologies(事務拓撲)時,您不必執行任何操作或 anchoring。Storm管理下面的所有這些。acking 策略被大量優化。
#### Failing a transaction
當使用常規 bolts 時,可以在 `OutputCollector` 上調用 `fail` 方法來使該 tuple 的成員的 tuples tree失敗。由于transactional topologies(事務拓撲) 隱藏了您的acking框架,因此它們提供了一種不同的機制來使 batch 失敗(并導致 batch 被重播)。只是拋出一個 [FailedException](javadocs/org/apache/storm/topology/FailedException.html). 與常規異常不同,這只會導致特定 batch 重播,并且不會使進程崩潰。
### Transactional spout
`TransactionalSpout` 接口與普通Spout接口完全不同。 `TransactionalSpout` 實現發送批量的 tuples,并且必須確保為相同的事務ID始終發出同一批 tuples。
topology(拓撲)拓撲正在執行時,transactional spout 看起來像這樣:
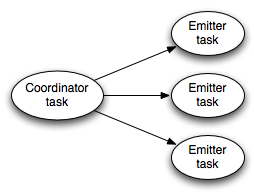
左邊的 coordinator(協調器) 是一個常規的Storm spout,每當一個批處理被發送到一個事務中時,它會發出一個 tuple。emitters(發射器)作為常規Storm bolt 執行,并負責發射 batch 的實際 tuples。emitters(發射器)使用 all grouping 訂閱 coordinator(協調器)的“batch emit” stream。
對于它發出的 tuple,需要是等冪的,需要一個 `TransactionalSpout` 來存儲少量的狀態。狀態存儲在Zookeeper中。
實現 `TransactionalSpout` 的細節在 [the Javadoc](javadocs/org/apache/storm/transactional/ITransactionalSpout.html) 中.
#### Partitioned Transactional Spout
一種常見的事務性出水口是從許多隊列經紀人的一組分區中讀取批次的。例如,這是 [TransactionalKafkaSpout](http://github.com/apache/storm/tree/master%0A/external/storm-kafka/src/jvm/org/apache/storm/kafka/TransactionalKafkaSpout.java) 的工作原理。 `IPartitionedTransactionalSpout`會自動執行管理每個分區的狀態的記賬工作,以確保冪等重播。有關詳細信息。 請參閱 [the Javadoc](javadocs/org/apache/storm/transactional/partitioned/IPartitionedTransactionalSpout.html)
### Configuration
transactional topologies(事務性拓撲)有兩個重要的配置位:
1. _Zookeeper:_ 默認情況下,transactional topologies(事務拓撲)將在用于管理Storm集群的Zookeeper實例中存儲狀態。您可以使用“transactional.zookeeper.servers”和“transactional.zookeeper.port”配置覆蓋此配置。
2. _Number of active batches permissible at once:_ 您必須對可以一次處理的 batches 數設置限制。您可以使用“topology.max.spout.pending”配置進行配置。如果您沒有設置此配置,它將默認為1。
## What if you can't emit the same batch of tuples for a given transaction id?
到目前為止,關于 transactional topologies(事務拓撲)的討論假設您可以隨時為相同的事務ID發出完全相同批次 tuple 。那么如果不可能,你該怎么辦?
考慮一下這個不可能的例子。假設您正在從分區消息代理讀取 tuple (流在許多機器上分區),單個事務將包含所有單個機器的 tuple 。現在假設其中一個節點在事務失敗的同時下降。沒有那個節點,就不可能重播剛剛為該事務ID播放的同一批 tuples。您的 topology(拓撲)拓撲中的處理將停止,因為它無法重播相同的批處理。唯一可能的解決方案是為該事務ID發出不同于之前發出的不同批處理。即使 batch 更改,仍然可以實現一次消息傳遞語義?
事實證明,您仍然可以使用非冪等的事務性端口在處理過程中實現完全一致的消息傳遞語義,盡管這在開發 topology(拓撲)中需要更多的工作。
如果 batch 可以更改給定的事務ID,那么我們迄今為止使用的邏輯“如果數據庫中的事務ID與當前事務的id相同,則跳過更新”不再有效。這是因為當前批次與上次 transaction 提交的 batch 不同,因此結果不一定相同。您可以通過在數據庫中存儲更多的狀態來解決此問題。我們再次使用在數據庫中存儲全局計數的示例,并假設批次的部分計數存儲在partialCount變量中。
而不是在數據庫中存儲一個如下所示的值:
```
class Value {
Object count;
BigInteger txid;
}
```
對于非冪等事務端口,您應該存儲一個如下所示的值:
```
class Value {
Object count;
BigInteger txid;
Object prevCount;
}
```
更新的邏輯如下:
1. 如果當前 batch 的 transaction id 與數據庫中的 transaction id 相同,請設置`val.count = val.prevCount + partialCount`。
2. 否則,設置`val.prevCount = val.count,val.count = val.count + partialCount和val.txid = batchTxid`。
這個邏輯是有效的,因為一旦你第一次提交一個特定的事務id,所有的事務id都不會再被提交。
transactional topologies (事務拓撲)有一些更細微的方面,使不透明的transactional spouts 口成為可能.
當 transaction 失敗時,處理階段中的所有后續 transaction 也被認為是失敗的。這些 transactions 將被重新排放和再處理。沒有這種行為,可能會發生以下情況:
1. Transaction A emits tuples 1-50
2. Transaction B emits tuples 51-100
3. Transaction A fails
4. Transaction A emits tuples 1-40
5. Transaction A commits
6. Transaction B commits
7. Transaction C emits tuples 101-150
在這種情況下,跳過 tuple 41-50。由于所有后續 transactions 失敗,將會發生:
1. Transaction A emits tuples 1-50
2. Transaction B emits tuples 51-100
3. Transaction A fails (and causes Transaction B to fail)
4. Transaction A emits tuples 1-40
5. Transaction B emits tuples 41-90
6. Transaction A commits
7. Transaction B commits
8. Transaction C emits tuples 91-140
通過失敗所有后續 transactions 失敗,不會跳過 tuples。這也表明 transactions spout的要求是它們總是發出最后一個 transactions 處理的位置.
一個非冪等的 transactional spout 更簡明地稱為“不透明的投資點”(不透明與冪冪相反)。 [IOpaquePartitionedTransactionalSpout](javadocs/org/apache/storm/transactional/partitioned/IOpaquePartitionedTransactionalSpout.html) 是一個用于實現不透明分區transactional spouts的接口,其中 [OpaqueTransactionalKafkaSpout](http://github.com/apache/storm/tree/master%0A/external/storm-kafka/src/jvm/org/apache/storm/kafka/OpaqueTransactionalKafkaSpout.java) 是一個示例。只要您使用本節所述的更新策略,`OpaqueTransactionalKafkaSpout`可以承受丟失的單個Kafka節點,而不會犧牲精度。
## Implementation
transactional topologies(事務拓撲)的實現非常優雅。管理提交協議,檢測故障和流水線批處理似乎很復雜,但一切事情都是對Storm 原語的簡單映射.
數據流程如何工作:
transactional spout 是如何工作的
1. Transactional spout is a subtopology consisting of a coordinator spout and an emitter bolt
2. The coordinator is a regular spout with a parallelism of 1
3. The emitter is a bolt with a parallelism of P, connected to the coordinator's "batch" stream using an all grouping
4. When the coordinator determines it's time to enter the processing phase for a transaction, it emits a tuple containing the TransactionAttempt and the metadata for that transaction to the "batch" stream
5. Because of the all grouping, every single emitter task receives the notification that it's time to emit its portion of the tuples for that transaction attempt
6. Storm automatically manages the anchoring/acking necessary throughout the whole topology to determine when a transaction has completed the processing phase. The key here is that *the root tuple was created by the coordinator, so the coordinator will receive an "ack" if the processing phase succeeds, and a "fail" if it doesn't succeed for any reason (failure or timeout).
7. If the processing phase succeeds, and all prior transactions have successfully committed, the coordinator emits a tuple containing the TransactionAttempt to the "commit" stream.
8. All committing bolts subscribe to the commit stream using an all grouping, so that they will all receive a notification when the commit happens.
9. Like the processing phase, the coordinator uses the acking framework to determine whether the commit phase succeeded or not. If it receives an "ack", it marks that transaction as complete in zookeeper.
更多概念:
* Transactional spouts are a sub-topology consisting of a spout and a bolt
* the spout is the coordinator and contains a single task
* the bolt is the emitter
* the bolt subscribes to the coordinator with an all grouping
* serialization of metadata is handled by kryo. kryo is initialized ONLY with the registrations defined in the component configuration for the transactionalspout
* the coordinator uses the acking framework to determine when a batch has been successfully processed, and then to determine when a batch has been successfully committed.
* state is stored in zookeeper using RotatingTransactionalState
* commiting bolts subscribe to the coordinators commit stream using an all grouping
* CoordinatedBolt is used to detect when a bolt has received all the tuples for a particular batch.
* this is the same abstraction that is used in DRPC
* for commiting bolts, it waits to receive a tuple from the coordinator's commit stream before calling finishbatch
* so it can't call finishbatch until it's received all tuples from all subscribed components AND its received the commit stream tuple (for committers). this ensures that it can't prematurely call finishBatch
- Storm 基礎
- 概念
- Scheduler(調度器)
- Configuration
- Guaranteeing Message Processing
- 守護進程容錯
- 命令行客戶端
- Storm UI REST API
- 理解 Storm Topology 的 Parallelism(并行度)
- FAQ
- Layers on Top of Storm
- Storm Trident
- Trident 教程
- Trident API 綜述
- Trident State
- Trident Spouts
- Trident RAS API
- Storm SQL
- Storm SQL 集成
- Storm SQL 示例
- Storm SQL 語言參考
- Storm SQL 內部實現
- Flux
- Storm 安裝和部署
- 設置Storm集群
- 本地模式
- 疑難解答
- 在生產集群上運行 Topology
- Maven
- 安全地運行 Apache Storm
- CGroup Enforcement
- Pacemaker
- 資源感知調度器 (Resource Aware Scheduler)
- 用于分析 Storm 的各種內部行為的 Metrics
- Windows 用戶指南
- Storm 中級
- 序列化
- 常見 Topology 模式
- Clojure DSL
- 使用沒有jvm的語言編輯storm
- Distributed RPC
- Transactional Topologies
- Hooks
- Storm Metrics
- Storm 狀態管理
- Windowing Support in Core Storm
- Joining Streams in Storm Core
- Storm Distributed Cache API
- Storm 調試
- 動態日志級別設置
- Storm Logs
- 動態員工分析
- 拓撲事件檢查器
- Storm 與外部系統, 以及其它庫的集成
- Storm Kafka Integration
- Storm Kafka 集成(0.10.x+)
- Storm HBase Integration
- Storm HDFS Integration
- Storm Hive 集成
- Storm Solr 集成
- Storm Cassandra 集成
- Storm JDBC 集成
- Storm JMS 集成
- Storm Redis 集成
- Azue Event Hubs 集成
- Storm Elasticsearch 集成
- Storm MQTT(Message Queuing Telemetry Transport, 消息隊列遙測傳輸) 集成
- Storm MongoDB 集成
- Storm OpenTSDB 集成
- Storm Kinesis 集成
- Storm Druid 集成
- Storm and Kestrel
- Container, Resource Management System Integration
- Storm 高級
- 針對 Storm 定義一個不是 JVM 的 DSL
- 多語言協議
- Storm 內部實現
- 翻譯進度