## MapReduce 編程模型
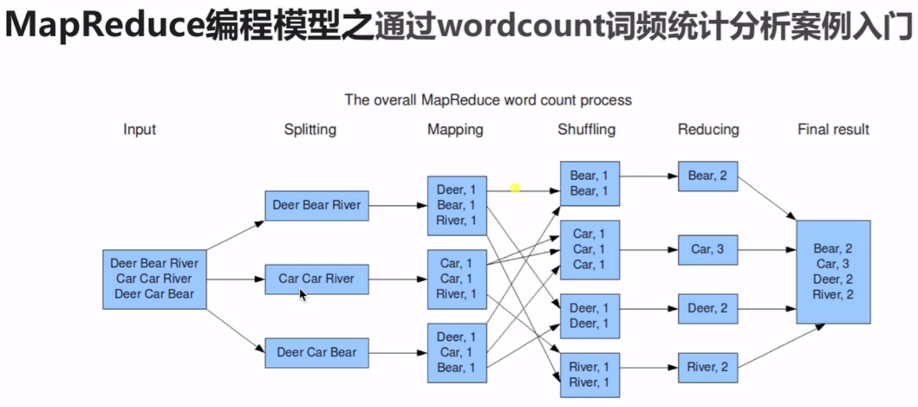
> 業務被分成map階段和reduce階段。
## Mapreduce執行步驟
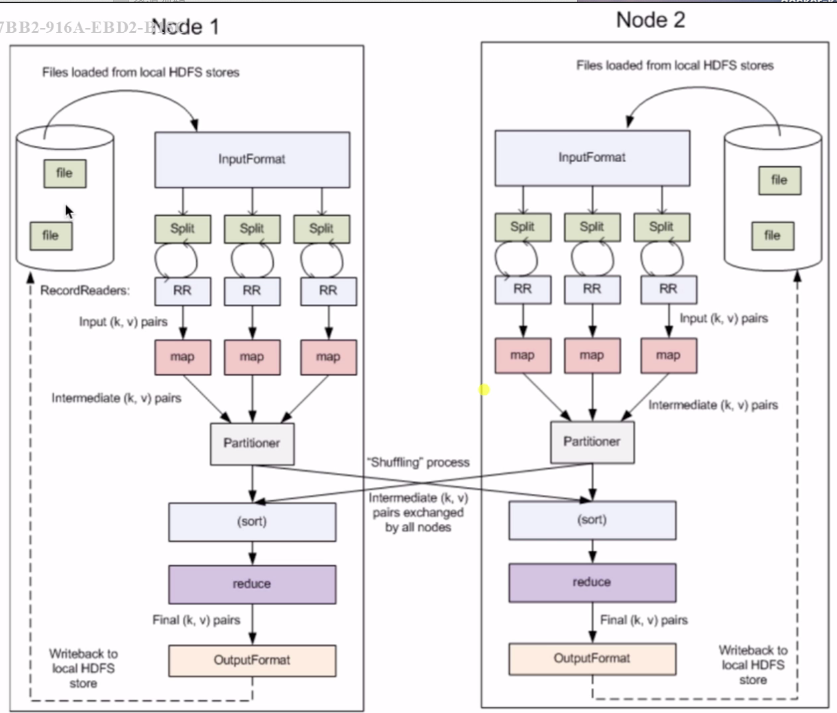
## 自定義mapper步驟
~~~
package com.bizzbee.bigdata.hadoop.mr.wc;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/*
* Mapper是一個范型類
* Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>
* KEYIN:map 任務讀數據的key類型 long
* VALUEIN :map讀數據的value類型 string
*
* 詞頻統計
* hello world welcome
* hello welcome
*
* 輸出--》(word,1)
*
* KEYOUT key輸出類型 String
* VALUEOUT value輸出類型 integer
*
*
*因為Long String Integer是Java里面的數據類型。
* Hadoop自定義類型:序列化和反序列化
*
*
* */
public class WordCountMapper extends Mapper<LongWritable, Text,Text, IntWritable> {
/*
* 重寫map方法
* */
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//每一行數據用tab分割拆開
String[] words = value.toString().split("\t");
for(String word:words){
context.write(new Text(word),new IntWritable(1));
}
}
}
~~~
## 自定義reduce
~~~
package com.bizzbee.bigdata.hadoop.mr.wc;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.Iterator;
/*
* 輸入: (hello,1)(hello,1)
* (welcome,1)
* map輸出到reduce,是按照相同的key分發到一個reduce上去執行。
*
* reduce1:(hello,1)(hello,1)(hello,1)==》(hello,<1,1,1>)
* */
public class WordCountReducer extends Reducer<Text, IntWritable, Text,IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int count =0;
Iterator<IntWritable> iterator = values.iterator();
while (iterator.hasNext()){
IntWritable value = iterator.next();
//get就是把IntWritable轉換回int
count +=value.get();
}
context.write(key,new IntWritable(count));
}
}
~~~
## 創建driver運行統計
~~~
package com.bizzbee.bigdata.hadoop.mr.wc;
import com.bizzbee.bigdata.hadoop.hdfs.Constants;
import com.bizzbee.bigdata.hadoop.hdfs.ParamsUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.net.URI;
import java.util.Properties;
public class WordCountApp {
public static void main(String[] args) throws Exception{
//加載配置文件
Properties properties = ParamsUtils.getProperties();
//填寫hdfs上面的用戶,不加這句報錯
System.setProperty("HADOOP_USER_NAME","bizzbee");
Configuration configuration = new Configuration();
configuration.set("dfs.client.use.datanode.hostname", "true");
configuration.set("fs.defaultFS","hdfs://tencent2:8020");
Job job = Job.getInstance(configuration);
job.setJarByClass(WordCountApp.class);
// 設置Job對應的參數: 主類
job.setJarByClass(WordCountApp.class);
// 設置Job對應的參數: 設置自定義的Mapper和Reducer處理類
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
// 設置Job對應的參數: Mapper輸出key和value的類型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 設置Job對應的參數: Reduce輸出key和value的類型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 如果輸出目錄已經存在,則先刪除
FileSystem fileSystem = FileSystem.get(new URI("hdfs://tencent2:8020"),configuration, "bizzbee");
Path outputPath = new Path("/bizzbee/output/result");
if(fileSystem.exists(outputPath)) {
fileSystem.delete(outputPath,true);
}
// 設置Job對應的參數: Mapper輸出key和value的類型:作業輸入和輸出的路徑
FileInputFormat.setInputPaths(job, new Path("/bizzbee/input/article"));
FileOutputFormat.setOutputPath(job, outputPath);
// 提交job
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : -1);
}
}
~~~

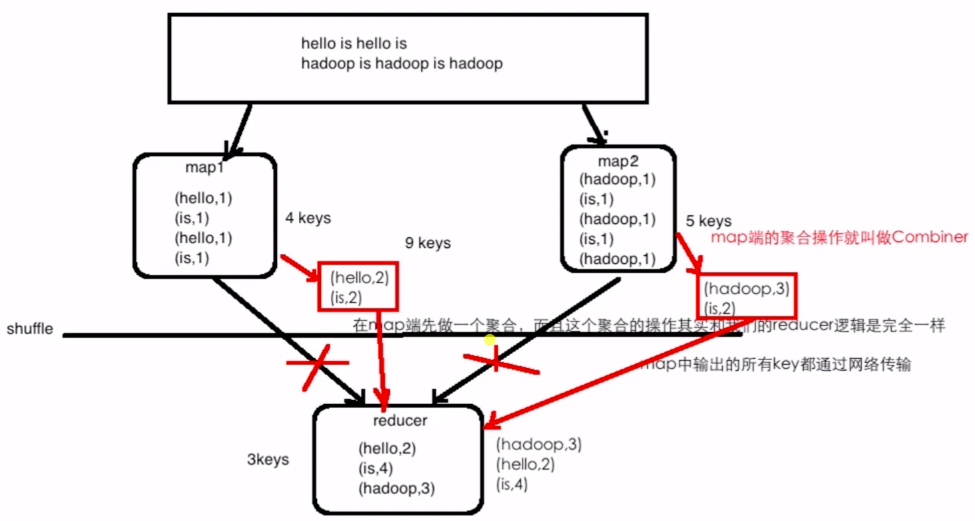
## combiner
combiner是在map階段線進行一次聚合操作。
優點:減少io,提高性能,可以節省網絡帶寬。
缺點:求平均數等幾種操作不可用。