## 環境搭建
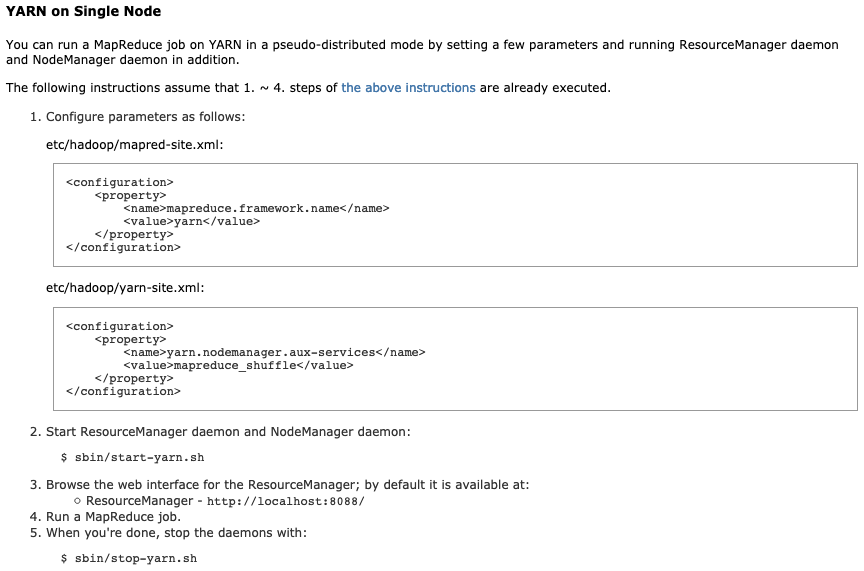
> 根據官網填寫這兩個文件配置之后,就可以啟動。
```
[bizzbee@tencent2 sbin]$ jps
9984 NameNode
27617 ResourceManager
28002 Jps
10092 DataNode
27709 NodeManager
```
## 在yarn啟動后,遇到的問題。
### 1. 執行mapreduce自帶的example 的時候,遇到的拒絕連接的問題。
* 這個問題弄了好幾天,最終確定應該是云服務器配置不夠導致執行的時候 namenode掛掉了。
* namenode掛掉了,所以連接失敗了。目前我市那么認為的。
### 2. 然后使用win虛擬機重新搭建了系統。
* 系統是centos7 ,網絡已開始沒有網,詳情看VM虛擬機聯網的問題那一篇。
* centos重啟之后默認網絡是關閉的,所以需要設置重啟后也開啟網絡。
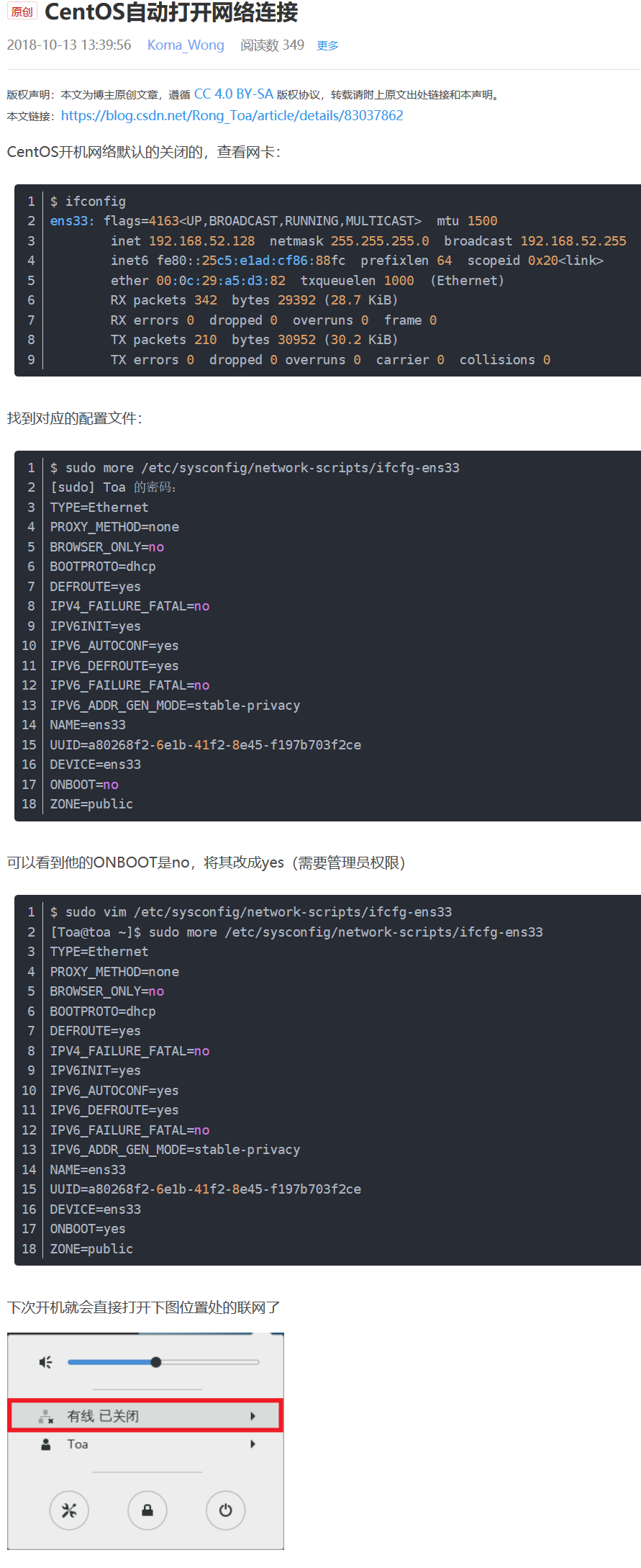
* 也是記得關閉防火墻,并且設置重啟后也關閉防火墻。
### 3. 打包本地項目到服務器上跑。
* 到項目的根目錄,也就是pom.xml文件所在的目錄。執行打包命令`mvn clean package -DskipTests`
* 進入到target目錄,把生成的jar包上傳服務器。(我之前居然不知道scp命令。)
`scp hadoop-train-v2-1.0-SNAPSHOT.jar bizzbee@192.168.31.249:~/work/`
* 然后在服務器上執行運行jar 包命令。(有一些準備,比如測試文件之類的要上傳好。)
```
hadoop jar hadoop-train-v2-1.0-SNAPSHOT.jar com.bizzbee.bigdata.hadoop.mr.access.AccessYranApp /bizzbee/input/access.log /bizzbee/output/access.resu
```
* 注意!!有可能出現報錯。
```
19/10/15 21:38:08 INFO mapreduce.Job: map 0% reduce 0%
19/10/15 21:38:17 INFO mapreduce.Job: map 100% reduce 0%
19/10/15 21:38:19 INFO mapreduce.Job: Task Id : attempt_1571141976287_0003_r_000000_3, Status : FAILED
Error: org.apache.hadoop.mapreduce.task.reduce.Shuffle$ShuffleError: error in shuffle in fetcher#5
at org.apache.hadoop.mapreduce.task.reduce.Shuffle.run(Shuffle.java:134)
at org.apache.hadoop.mapred.ReduceTask.run(ReduceTask.java:376)
at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:164)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1924)
at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:158)
Caused by: java.io.IOException: Exceeded MAX_FAILED_UNIQUE_FETCHES; bailing-out.
at org.apache.hadoop.mapreduce.task.reduce.ShuffleSchedulerImpl.checkReducerHealth(ShuffleSchedulerImpl.java:392)
at org.apache.hadoop.mapreduce.task.reduce.ShuffleSchedulerImpl.copyFailed(ShuffleSchedulerImpl.java:307)
at org.apache.hadoop.mapreduce.task.reduce.Fetcher.copyFromHost(Fetcher.java:366)
at org.apache.hadoop.mapreduce.task.reduce.Fetcher.run(Fetcher.java:198)
```
* 原因和解決辦法如下。

* 總結一下是因為`haddop.tmp.dir`是自定義的,而`yarn.nodemanager.local-dirs`的路徑應該在`haddop.tmp.dir`里面,如截圖所示。如果不添加的話,用系統默認的地址,就不再`haddop.tmp.dir`的里面了。
