## 一、簡介
Hive 是一個構建在 Hadoop 之上的數據倉庫,它可以將結構化的數據文件映射成表,并提供類 SQL 查詢功能,用于查詢的 SQL 語句會被轉化為 MapReduce 作業,然后提交到 Hadoop 上運行。
**Hive的表對應HDFS的目錄(或文件夾);Hive表中的數據對應HDFS的文件**。
**特點**:
1. 簡單、容易上手 (提供了類似 sql 的查詢語言 hql),使得精通 sql 但是不了解 Java 編程的人也能很好地進行大數據分析;
2. 靈活性高,可以自定義用戶函數 (UDF) 和存儲格式;
3. 為超大的數據集設計的計算和存儲能力,集群擴展容易;
4. 統一的元數據管理,可與 presto/impala/sparksql 等共享數據;
5. 執行延遲高,不適合做數據的實時處理,但適合做海量數據的離線處理。]
## 二、Hive的體系架構
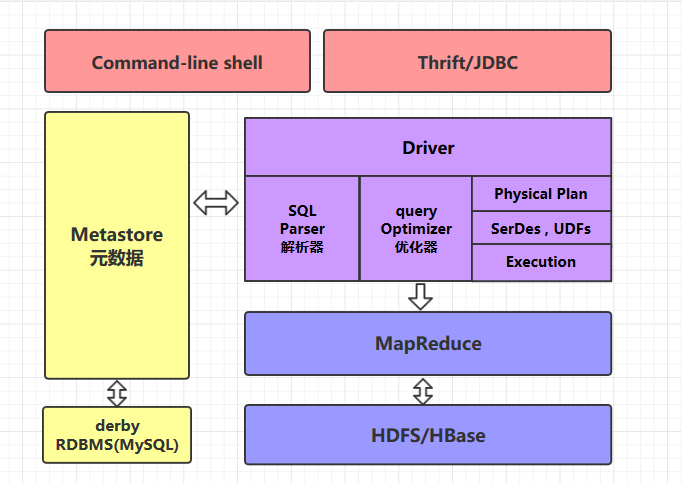
### 2.1 command-line shell & thrift/jdbc
可以用 command-line shell 和 thrift/jdbc 兩種方式來操作數據:
* **command-line shell**:通過 hive 命令行的的方式來操作數據;
* **thrift/jdbc**:通過 thrift 協議按照標準的 JDBC 的方式操作數據。
### 2.2 Metastore
在 Hive 中,表名、表結構、字段名、字段類型、表的分隔符等統一被稱為元數據。所有的元數據默認存儲在 Hive 內置的 derby 數據庫中,但由于 derby 只能有一個實例,也就是說不能有多個命令行客戶端同時訪問,所以在實際生產環境中,通常使用 MySQL 代替 derby。
Hive 進行的是統一的元數據管理,就是說你在 Hive 上創建了一張表,然后在 presto/impala/sparksql 中都是可以直接使用的,它們會從 Metastore 中獲取統一的元數據信息,同樣的你在 presto/impala/sparksql 中創建一張表,在 Hive 中也可以直接使用。
### 2.3 HQL的執行流程
Hive 在執行一條 HQL 的時候,會經過以下步驟:
1. 語法解析:Antlr 定義 SQL 的語法規則,完成 SQL 詞法,語法解析,將 SQL 轉化為抽象 語法樹 AST Tree;
2. 語義解析:遍歷 AST Tree,抽象出查詢的基本組成單元 QueryBlock;
3. 生成邏輯執行計劃:遍歷 QueryBlock,翻譯為執行操作樹 OperatorTree;
4. 優化邏輯執行計劃:邏輯層優化器進行 OperatorTree 變換,合并不必要的 ReduceSinkOperator,減少 shuffle 數據量;
5. 生成物理執行計劃:遍歷 OperatorTree,翻譯為 MapReduce 任務;
6. 優化物理執行計劃:物理層優化器進行 MapReduce 任務的變換,生成最終的執行計劃。
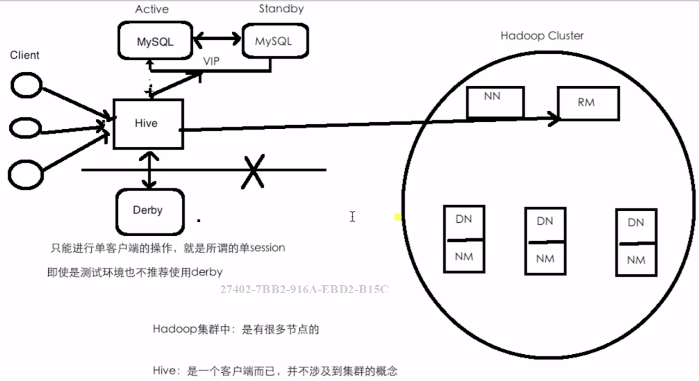
### 三、部署架構
### 四、下載
[cdh下載地址](http://archive.cloudera.com/cdh5/cdh/5/)
`wget http://archive.cloudera.com/cdh5/cdh/5/hive-1.1.0-cdh5.15.1.tar.gz`
* 解壓到~/app/
### 五、修改配置
**1. hive-env.sh**
進入安裝目錄下的 `conf/` 目錄,拷貝 Hive 的環境配置模板 `flume-env.sh.template`
~~~shell
cp hive-env.sh.template hive-env.sh
~~~
修改 `hive-env.sh`,指定 Hadoop 的安裝路徑:
~~~shell
HADOOP_HOME=/usr/app/hadoop-2.6.0-cdh5.15.2
~~~
**2\. hive-site.xml**
新建 hive-site.xml 文件,內容如下,主要是配置存放元數據的 MySQL 的地址、驅動、用戶名和密碼等信息:
<?xml version="1.0"?>
```shell
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<connfiguration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://bizzbee:3306/hadoop_hive?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
</property>
```
* 拷貝數據庫驅動
將 MySQL 驅動包拷貝到 Hive 安裝目錄的 `lib` 目錄下, MySQL 驅動的下載地址為:[https://dev.mysql.com/downloads/connector/j/](https://dev.mysql.com/downloads/connector/j/) , 在本倉庫的[resources](https://github.com/heibaiying/BigData-Notes/tree/master/resources) 目錄下我也上傳了一份,有需要的可以自行下載。
* 然后就自己安裝一個mysql
* 具體參考[我的mysql56安裝筆記](http://www.hmoore.net/bizzbee/linux_a/1231732)
* 啟動hive ---啟動之前要確定hdfs和yarn的狀態,以及是否成功安裝mysql。
```
[bizzbee@bizzbee hive-1.1.0-cdh5.15.1]$ bin/hive
```
