
文件及硬盤管理是計算機操作系統的重要組成部分,讓微軟走上成功之路的正是微軟最早推出的個人電腦 PC 操作系統,這個操作系統就叫 DOS,即 Disk Operating System,硬盤操作系統。我們每天使用電腦都離不開硬盤,硬盤既有大小的限制,通常大一點的硬盤也不過幾 T,又有速度限制,快一點的硬盤也不過每秒幾百 M。
文件是存儲在硬盤上的,文件的讀寫訪問速度必然受到硬盤的物理限制,那么如何才能 1 分鐘完成一個 100T 大文件的遍歷呢?
想要知道這個問題的答案,我們就必須知道文件系統的原理。
做軟件開發時,必然要經常和文件系統打交道,而文件系統也是一個軟件,了解文件系統的設計原理,可以幫助我們更好地使用文件系統,另外設計文件系統時的各種考量,也對我們自己做軟件設計有諸多借鑒意義。
讓我們先從硬盤的物理結構說起。
## 硬盤
硬盤是一種可持久保存、多次讀寫數據的存儲介質。硬盤的形式主要兩種,一種是機械式硬盤,一種是固態硬盤。
機械式硬盤的結構,主要包含盤片、主軸、磁頭臂,主軸帶動盤片高速旋轉,當需要讀寫盤上的數據的時候,磁頭臂會移動磁頭到盤片所在的磁道上,磁頭讀取磁道上的數據。讀寫數據需要移動磁頭,這樣一個機械的動作,至少需要花費數毫秒的時間,這是機械式硬盤訪問延遲的主要原因。
如果一個文件的數據在硬盤上不是連續存儲的,比如數據庫的 B+ 樹文件,那么要讀取這個文件,磁頭臂就必須來回移動,花費的時間必然很長。如果文件數據是連續存儲的,比如日志文件,那么磁頭臂就可以較少移動,相比離散存儲的同樣大小的文件,連續存儲的文件的讀寫速度要快得多。
機械式硬盤的數據就存儲在具有磁性特質的盤片上,因此這種硬盤也被稱為磁盤,而固態硬盤則沒有這種磁性特質的存儲介質,也沒有電機驅動的機械式結構。
其中主控芯片處理端口輸入的指令和數據,然后控制閃存顆粒進行數據讀寫。由于固態硬盤沒有了機械式硬盤的電機驅動磁頭臂進行機械式物理移動的環節,而是完全的電子操作,因此固態硬盤的訪問速度遠快于機械式硬盤。
但是,到目前為止固態硬盤的成本還是明顯高于機械式硬盤,因此在生產環境中,最主要的存儲介質依然是機械式硬盤。如果一個場景對數據訪問速度、存儲容量、成本都有較高要求,那么可以采用固態硬盤和機械式硬盤混合部署的方式,即在一臺服務器上既有固態硬盤,也有機械式硬盤,以滿足不同文件類型的存儲需求,比如日志文件存儲在機械式硬盤上,而系統文件和隨機讀寫的文件存儲在固態硬盤上。
## 文件系統
作為應用程序開發者,我們不需要直接操作硬盤,而是通過操作系統,以文件的方式對硬盤上的數據進行讀寫訪問。文件系統將硬盤空間以塊為單位進行劃分,每個文件占據若干個塊,然后再通過一個文件控制塊 FCB 記錄每個文件占據的硬盤數據塊。
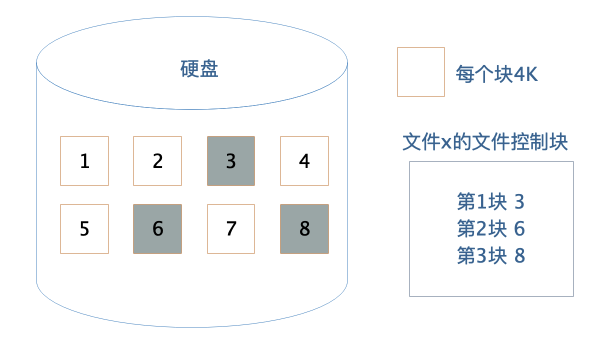
這個文件控制塊在 Linux 操作系統中就是 inode,要想訪問文件,就必須獲得文件的 inode 信息,在 inode 中查找文件數據塊索引表,根據索引中記錄的硬盤地址信息訪問硬盤,讀寫數據。
inode 中記錄著文件權限、所有者、修改時間和文件大小等文件屬性信息,以及文件數據塊硬盤地址索引。inode 是固定結構的,能夠記錄的硬盤地址索引數也是固定的,只有 15 個索引。其中前 12 個索引直接記錄數據塊地址,第 13 個索引記錄索引地址,也就是說,索引塊指向的硬盤數據塊并不直接記錄文件數據,而是記錄文件數據塊的索引表,每個索引表可以記錄 256 個索引;第 14 個索引記錄二級索引地址,第 15 個索引記錄三級索引地址,如下圖:
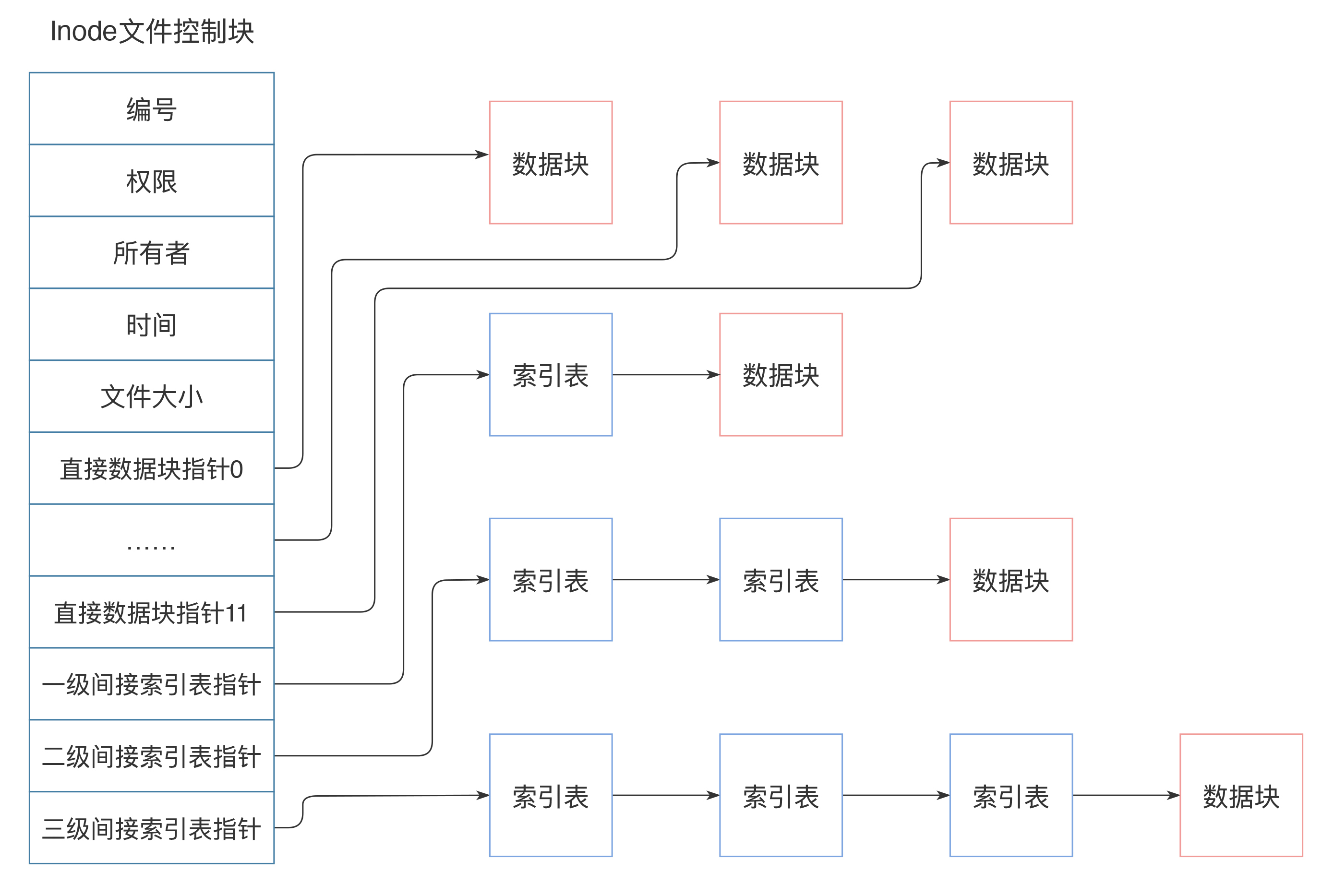
這樣,每個 inode 最多可以存儲 12+256+256\*256+256\*256\*256 個數據塊,如果每個數據塊的大小為 4k,也就是單個文件最大不超過 70G,而且即使可以擴大數據塊大小,文件大小也要受單個硬盤容量的限制。這樣的話,對于我們開頭提出的一分鐘完成 100T 大文件的遍歷,Linux 文件系統是無法完成的。
那么,有沒有更給力的解決方案呢?
## RAID
RAID,即獨立硬盤冗余陣列,將多塊硬盤通過硬件 RAID 卡或者軟件 RAID 的方案管理起來,使其共同對外提供服務。RAID 的核心思路其實是利用文件系統將數據寫入硬盤中不同數據塊的特性,將多塊硬盤上的空閑空間看做一個整體,進行數據寫入,也就是說,一個文件的多個數據塊可能寫入多個硬盤。
根據硬盤組織和使用方式不同,常用 RAID 有五種,分別是 RAID 0、RAID 1、RAID 10、RAID 5 和 RAID 6。

RAID 0 將一個文件的數據分成 N 片,同時向 N 個硬盤寫入,這樣單個文件可以存儲在 N 個硬盤上,文件容量可以擴大 N 倍,(理論上)讀寫速度也可以擴大 N 倍。但是使用 RAID 0 的最大問題是文件數據分散在 N 塊硬盤上,任何一塊硬盤損壞,就會導致數據不完整,整個文件系統全部損壞,文件的可用性極大地降低了。
RAID 1 則是利用兩塊硬盤進行數據備份,文件同時向兩塊硬盤寫入,這樣任何一塊硬盤損壞都不會出現文件數據丟失的情況,文件的可用性得到提升。
RAID 10 結合 RAID 0 和 RAID 1,將多塊硬盤進行兩兩分組,文件數據分成 N 片,每個分組寫入一片,每個分組內的兩塊硬盤再進行數據備份。這樣既擴大了文件的容量,又提高了文件的可用性。但是這種方式硬盤的利用率只有 50%,有一半的硬盤被用來做數據備份。
RAID 5 針對 RAID 10 硬盤浪費的情況,將數據分成 N-1 片,再利用這 N-1 片數據進行位運算,計算一片校驗數據,然后將這 N 片數據寫入 N 個硬盤。這樣任何一塊硬盤損壞,都可以利用校驗片的數據和其他數據進行計算得到這片丟失的數據,而硬盤的利用率也提高到 N-1/N。
RAID 5 可以解決一塊硬盤損壞后文件不可用的問題,那么如果兩塊文件損壞?RAID 6 的解決方案是,用兩種位運算校驗算法計算兩片校驗數據,這樣兩塊硬盤損壞還是可以計算得到丟失的數據片。
實踐中,使用最多的是 RAID 5,數據被分成 N-1 片并發寫入 N-1 塊硬盤,這樣既可以得到較好的硬盤利用率,也能得到很好的讀寫速度,同時還能保證較好的數據可用性。使用 RAID 5 的文件系統比簡單的文件系統文件容量和讀寫速度都提高了 N-1 倍,但是一臺服務器上能插入的硬盤數量是有限的,通常是 8 塊,也就是文件讀寫速度和存儲容量提高了 7 倍,這遠遠達不到 1 分鐘完成 100T 文件的遍歷要求。
那么,有沒有更給力的解決方案呢?
## 分布式文件系統
我們再回過頭看下 Linux 的文件系統:文件的基本信息,也就是文件元信息記錄在文件控制塊 inode 中,文件的數據記錄在硬盤的數據塊中,inode 通過索引記錄數據塊的地址,讀寫文件的時候,查詢 inode 中的索引記錄得到數據塊的硬盤地址,然后訪問數據。
如果將數據塊的地址改成分布式服務器的地址呢?也就是查詢得到的數據塊地址不只是本機的硬盤地址,還可以是其他服務器的地址,那么文件的存儲容量就將是整個分布式服務器集群的硬盤容量,這樣還可以在不同的服務器上同時并行讀取文件的數據塊,文件訪問速度也將極大的加快。
這樣的文件系統就是分布式文件系統,分布式文件系統的思路其實和 RAID 是一脈相承的,就是將數據分成很多片,同時向 N 臺服務器上進行數據寫入。針對一片數據丟失就導致整個文件損壞的情況,分布式文件系統也是采用數據備份的方式,將多個備份數據片寫入多個服務器,以保證文件的可用性。當然,也可以采用 RAID 5 的方式通過計算校驗數據片的方式提高文件可用性。
我們以 Hadoop 分布式文件系統 HDFS 為例,看下分布式文件系統的具體架構設計。
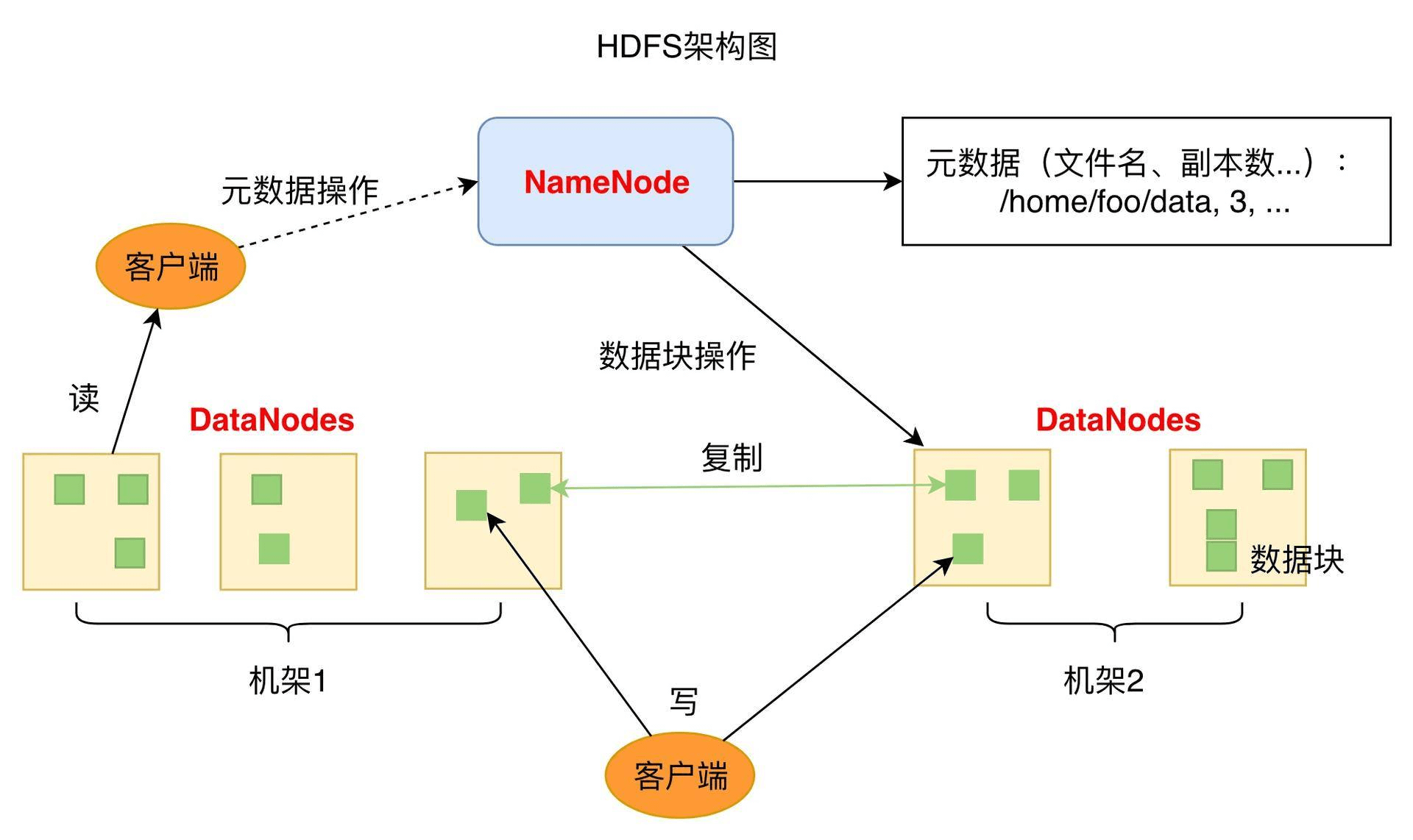
HDFS 的關鍵組件有兩個,一個是 DataNode,一個是 NameNode。
DataNode 負責文件數據的存儲和讀寫操作,HDFS 將文件數據分割成若干數據塊(Block),每個 DataNode 存儲一部分數據塊,這樣文件就分布存儲在整個 HDFS 服務器集群中。應用程序客戶端(Client)可以并行對這些數據塊進行訪問,從而使得 HDFS 可以在服務器集群規模上實現數據并行訪問,極大地提高了訪問速度。在實踐中,HDFS 集群的 DataNode 服務器會有很多臺,一般在幾百臺到幾千臺這樣的規模,每臺服務器配有數塊硬盤,整個集群的存儲容量大概在幾 PB 到數百 PB。
NameNode 負責整個分布式文件系統的元數據(MetaData)管理,也就是文件路徑名、訪問權限、數據塊的 ID 以及存儲位置等信息,相當于 Linux 系統中 inode 的角色。HDFS 為了保證數據的高可用,會將一個數據塊復制為多份(缺省情況為 3 份),并將多份相同的數據塊存儲在不同的服務器上,甚至不同的機架上。這樣當有硬盤損壞,或者某個 DataNode 服務器宕機,甚至某個交換機宕機,導致其存儲的數據塊不能訪問的時候,客戶端會查找其備份的數據塊進行訪問。
有了 HDFS,可以實現單一文件存儲幾百 T 的數據,再配合大數據計算框架 MapReduce 或者 Spark,可以對這個文件的數據塊進行并發計算。也可以使用 Impala 這樣的 SQL 引擎對這個文件進行結構化查詢,在數千臺服務器上并發遍歷 100T 的數據,1 分鐘都是綽綽有余的。
## 小結
文件系統從簡單操作系統文件,到 RAID,再到分布式文件系統,其設計思路其實是具有統一性的。這種統一性一方面體現在文件數據如何管理,也就是如何通過文件控制塊管理文件的數據,這個文件控制塊在 Linux 系統中就是 inode,在 HDFS 中就是 NameNode。
另一方面體現在如何利用更多的硬盤實現越來越大的文件存儲需求和越來越快的讀寫速度需求,也就是將數據分片后同時寫入多塊硬盤。單服務器我們可以通過 RAID 來實現,多服務器則可以將這些服務器組成一個文件系統集群,共同對外提供文件服務,這時候,數千臺服務器的數萬塊硬盤以單一存儲資源的方式對文件使用者提供服務,也就是一個文件可以存儲數百 T 的數據,并在一分鐘完成這樣一個大文件的遍歷
- 技能知識點
- 對死鎖問題的理解
- 文件系統原理:如何用1分鐘遍歷一個100TB的文件?
- 數據庫原理:為什么PrepareStatement性能更好更安全?
- Java Web程序的運行時環境到底是怎樣的?
- 你真的知道自己要解決的問題是什么嗎?
- 如何解決問題
- 經驗分享
- GIT的HTTP方式免密pull、push
- 使用xhprof對php7程序進行性能分析
- 微信掃碼登錄和使用公眾號方式進行掃碼登錄
- 關于curl跳轉抓取
- Linux 下配置 Git 操作免登錄 ssh 公鑰
- Linux Memcached 安裝
- php7安裝3.4版本的phalcon擴展
- centos7下php7.0.x安裝phalcon框架
- 將字符串按照指定長度分割
- 搜索html源碼中標簽包的純文本
- 更換composer鏡像源為阿里云
- mac 隱藏文件顯示/隱藏
- 谷歌(google)世界各國網址大全
- 實戰文檔
- PHP7安裝intl擴展和linux安裝icu
- linux編譯安裝時常見錯誤解決辦法
- linux刪除文件后不釋放磁盤空間解決方法
- PHP開啟異步多線程執行腳本
- file_exists(): open_basedir restriction in effect. File完美解決方案
- PHP 7.1 安裝 ssh2 擴展,用于PHP進行ssh連接
- php命令行加載的php.ini
- linux文件實時同步
- linux下php的psr.so擴展源碼安裝
- php將字符串中的\n變成真正的換行符?
- PHP7 下安裝 memcache 和 memcached 擴展
- PHP 高級面試題 - 如果沒有 mb 系列函數,如何切割多字節字符串
- PHP設置腳本最大執行時間的三種方法
- 升級Php 7.4帶來的兩個大坑
- 不同域名的iframe下,fckeditor在chrome下的SecurityError,解決辦法~~
- Linux find+rm -rf 執行組合刪除
- 從零搭建Prometheus監控報警系統
- Bug之group_concat默認長度限制
- PHP生成的XML顯示無效的Char值27消息(PHP generated XML shows invalid Char value 27 message)
- XML 解析中,如何排除控制字符
- PHP各種時間獲取
- nginx配置移動自適應跳轉
- 已安裝nginx動態添加模塊
- auto_prepend_file與auto_append_file使用方法
- 利用nginx實現web頁面插入統計代碼
- Nginx中的rewrite指令(break,last,redirect,permanent)
- nginx 中 index try_files location 這三個配置項的作用
- linux安裝git服務器
- PHP 中運用 elasticsearch
- PHP解析Mysql Binlog
- 好用的PHP學習網(持續更新中)
- 一篇寫給準備升級PHP7的小伙伴的文章
- linux 安裝php7 -系統centos7
- Linux 下多php 版本共存安裝
- PHP編譯安裝時常見錯誤解決辦法,php編譯常見錯誤
- nginx upstream模塊--負載均衡
- 如何解決Tomcat服務器打開不了HOST Manager的問題
- PHP的內存泄露問題與垃圾回收
- Redis數據結構 - string字符串
- PHP開發api接口安全驗證
- 服務接口API限流 Rate Limit
- php內核分析---內存管理(一)
- PHP內存泄漏問題解析
- 【代碼片-1】 MongoDB與PHP -- 高級查詢
- 【代碼片-1】 php7 mongoDB 簡單封裝
- php與mysql系統中出現大量數據庫sleep的空連接問題分析
- 解決crond引發大量sendmail、postdrop進程問題
- PHP操作MongoDB GridFS 存儲文件,如圖片文件
- 淺談php安全
- linux上keepalived+nginx實現高可用web負載均衡
- 整理php防注入和XSS攻擊通用過濾