
做應用開發的同學常常覺得數據庫由 DBA 運維,自己會寫 SQL 就可以了,數據庫原理不需要學習。其實即使是寫 SQL 也需要了解數據庫原理,比如我們都知道,SQL 的查詢條件盡量包含索引字段,但是為什么呢?這樣做有什么好處呢?你也許會說,使用索引進行查詢速度快,但是為什么速度快呢?
此外,我們在 Java 程序中訪問數據庫的時候,有兩種提交 SQL 語句的方式,一種是通過 Statement 直接提交 SQL;另一種是先通過 PrepareStatement 預編譯 SQL,然后設置可變參數再提交執行。
Statement 直接提交的方式如下:
statement.executeUpdate("UPDATE Users SET stateus = 2 WHERE userID=233");
PrepareStatement 預編譯的方式如下:
PreparedStatement updateUser = con.prepareStatement("UPDATE Users SET stateus = ? WHERE userID = ?");
updateUser.setInt(1, 2);
updateUser.setInt(2,233);
updateUser.executeUpdate();
看代碼,似乎第一種方式更加簡單,但是編程實踐中,主要用第二種。使用 MyBatis 等 ORM 框架時,這些框架內部也是用第二種方式提交 SQL。那為什么要舍簡單而求復雜呢?
要回答上面這些問題,都需要了解數據庫的原理,包括數據庫的架構原理與數據庫文件的存儲原理。
## 數據庫架構與 SQL 執行過程
我們先看看數據庫架構原理與 SQL 執行過程。
關系數據庫系統 RDBMS 有很多種,但是這些關系數據庫的架構基本上差不多,包括支持 SQL 語法的 Hadoop 大數據倉庫,也基本上都是相似的架構。一個 SQL 提交到數據庫,經過連接器將 SQL 語句交給語法分析器,生成一個抽象語法樹 AST;AST 經過語義分析與優化器,進行語義優化,使計算過程和需要獲取的中間數據盡可能少,然后得到數據庫執行計劃;執行計劃提交給具體的執行引擎進行計算,將結果通過連接器再返回給應用程序。

應用程序提交 SQL 到數據庫執行,首先需要建立與數據庫的連接,數據庫連接器會為每個連接請求分配一塊專用的內存空間用于會話上下文管理。建立連接對數據庫而言相對比較重,需要花費一定的時間,因此應用程序啟動的時候,通常會初始化建立一些數據庫連接放在連接池里,這樣當處理外部請求執行 SQL 操作的時候,就不需要花費時間建立連接了。
這些連接一旦建立,不管是否有 SQL 執行,都會消耗一定的數據庫內存資源,所以對于一個大規模互聯網應用集群來說,如果啟動了很多應用程序實例,這些程序每個都會和數據庫建立若干個連接,即使不提交 SQL 到數據庫執行,也就會對數據庫產生很大的壓力。
所以應用程序需要對數據庫連接進行管理,一方面通過連接池對連接進行管理,空閑連接會被及時釋放;另一方面微服務架構可以大大減少數據庫連接,比如對于用戶數據庫來說,所有應用都需要連接到用戶數據庫,而如果劃分一個用戶微服務并獨立部署一個比較小的集群,那么就只有這幾個用戶微服務實例需要連接用戶數據庫,需要建立的連接數量大大減少。
連接器收到 SQL 以后,會將 SQL 交給語法分析器進行處理,語法分析器工作比較簡單機械,就是根據 SQL 語法規則生成對應的抽象語法樹。
如果 SQL 語句中存在語法錯誤,那么在生成語法樹的時候就會報錯,比如,下面這個例子中 SQL 語句里的 where 拼寫錯誤,MySQL 就會報錯。
mysql> explain select \* from users whee id = 1;
ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'id = 1' at line 1
因為語法錯誤是在構建抽象語法樹的時候發現的,所以能夠知道,錯誤是發生在哪里。上面例子中,雖然語法分析器不能知道 whee 是一個語法拼寫錯誤,因為這個 whee 可能是表名 users 的別名,但是語法分析器在構建語法樹到了id=1這里的時候就出錯了,所以返回的報錯信息可以提示,在'id = 1'附近有語法錯誤。
語法分析器生成的抽象語法樹并不僅僅可以用來做語法校驗,它也是下一步處理的基礎。語義分析與優化器會對抽象語法樹進一步做語義優化,也就是在保證 SQL 語義不變的前提下,進行語義等價轉換,使最后的計算量和中間過程數據量盡可能小。
比如對于這樣一個 SQL 語句,其語義是表示從 users 表中取出每一個 id 和 order 表當前記錄比較,是否相等。
select f.id from orders f where f.user\_id = (select id from users);
事實上,這個 SQL 語句在語義上等價于下面這條 SQL 語句,表間計算關系更加清晰。
select f.id from orders f join users u on f.user\_id = u.id;
SQL 語義分析與優化器就是要將各種復雜嵌套的 SQL 進行語義等價轉化,得到有限幾種關系代數計算結構,并利用索引等信息進一步進行優化。可以說,各個數據庫最黑科技的部分就是在優化這里了。
語義分析與優化器最后會輸出一個執行計劃,由執行引擎完成數據查詢或者更新。MySQL 執行計劃的例子如下:

執行引擎是可替換的,只要能夠執行這個執行計劃就可以了。所以 MySQL 有多種執行引擎(也叫存儲引擎)可以選擇,缺省的是 InnoDB,此外還有 MyISAM、Memory 等,我們可以在創建表的時候指定存儲引擎。大數據倉庫 Hive 也是這樣的架構,Hive 輸出的執行計劃可以在 Hadoop 上執行。
## 使用 PrepareStatement 執行 SQL 的好處
好了,了解了數據庫架構與 SQL 執行過程之后,讓我們回到開頭的問題,應用程序為什么應該使用 PrepareStatement 執行 SQL?
這樣做主要有兩個好處。
一個是 PrepareStatement 會預先提交帶占位符的 SQL 到數據庫進行預處理,提前生成執行計劃,當給定占位符參數,真正執行 SQL 的時候,執行引擎可以直接執行,效率更好一點。
另一個好處則更為重要,PrepareStatement 可以防止 SQL 注入攻擊。假設我們允許用戶通過 App 輸入一個名字到數據中心查找用戶信息,如果用戶輸入的字符串是 Frank,那么生成的 SQL 是這樣的:
select \* from users where username = 'Frank';
但是如果用戶輸入的是這樣一個字符串:
Frank';drop table users;\--
那么生成的 SQL 就是這樣的:
select \* from users where username = 'Frank';drop table users;\--';
這條 SQL 提交到數據庫以后,會被當做兩條 SQL 執行,一條是正常的 select 查詢 SQL,一條是刪除 users 表的 SQL。黑客提交一個請求然后 users 表被刪除了,系統崩潰了,這就是 SQL 注入攻擊。
如果用 Statement 提交 SQL 就會出現這種情況。
但如果用 PrepareStatement 則可以避免 SQL 被注入攻擊。因為一開始構造 PrepareStatement 的時候就已經提交了查詢 SQL,并被數據庫預先生成好了執行計劃,后面黑客不管提交什么樣的字符串,都只能交給這個執行計劃去執行,不可能再生成一個新的 SQL 了,也就不會被攻擊了。
select \* from users where username = ?;
## 數據庫文件存儲原理
回到文章開頭提出的另一個問題,數據庫通過索引進行查詢能加快查詢速度,那么,為什么索引能加快查詢速度呢?
數據庫索引使用 B+ 樹,我們先看下 B+ 樹這種數據結構。B+ 樹是一種 N 叉排序樹,樹的每個節點包含 N 個數據,這些數據按順序排好,兩個數據之間是一個指向子節點的指針,而子節點的數據則在這兩個數據大小之間。
如下圖。
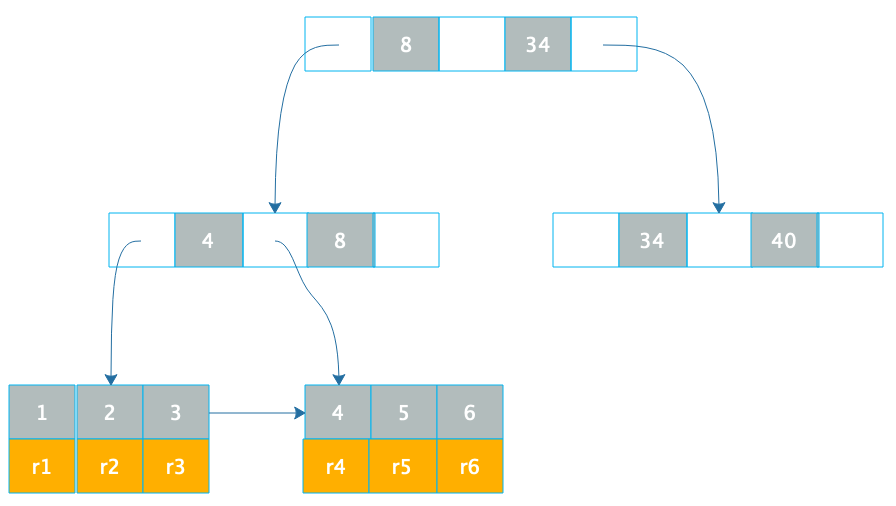
B+ 樹的節點存儲在磁盤上,每個節點存儲 1000 多個數據,這樣樹的深度最多只要 4 層,就可存儲數億的數據。如果將樹的根節點緩存在內存中,則最多只需要三次磁盤訪問就可以檢索到需要的索引數據。
B+ 樹只是加快了索引的檢索速度,如何通過索引加快數據庫記錄的查詢速度呢?
數據庫索引有兩種,一種是聚簇索引,聚簇索引的數據庫記錄和索引存儲在一起,上面這張圖就是聚簇索引的示意圖,在葉子節點,索引 1 和記錄行 r1 存儲在一起,查找到索引就是查找到數據庫記錄。像 MySQL 數據庫的主鍵就是聚簇索引,主鍵 ID 和所在的記錄行存儲在一起。MySQL 的數據庫文件實際上是以主鍵作為中間節點,行記錄作為葉子節點的一顆 B+ 樹。
另一種數據庫索引是非聚簇索引,非聚簇索引在葉子節點記錄的就不是數據行記錄,而是聚簇索引,也就是主鍵,如下圖。
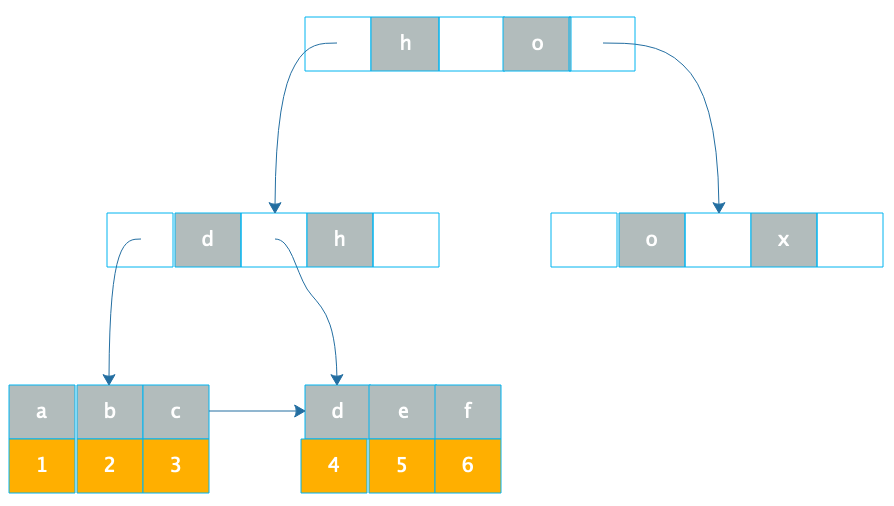
通過 B+ 樹在葉子節點找到非聚簇索引 a,和索引 a 在一起存儲的是主鍵 1,再根據主鍵 1 通過主鍵(聚簇)索引就可以找到對應的記錄 r1,這種通過非聚簇索引找到主鍵索引,再通過主鍵索引找到行記錄的過程也被稱作回表。
所以通過索引,可以快速查詢到需要的記錄,而如果要查詢的字段上沒有建索引,就只能掃描整張表了,查詢速度就會慢很多。
數據庫除了索引的 B+ 樹文件,還有一些比較重要的文件,比如事務日志文件。
數據庫可以支持事務,一個事務對多條記錄進行更新,要么全部更新,要么全部不更新,不能部分更新,否則像轉賬這樣的操作就會出現嚴重的數據不一致,可能會造成巨大的經濟損失。數據庫實現事務主要就是依靠事務日志文件。
在進行事務操作時,事務日志文件會記錄更新前的數據記錄,然后再更新數據庫中的記錄,如果全部記錄都更新成功,那么事務正常結束,如果過程中某條記錄更新失敗,那么整個事務全部回滾,已經更新的記錄根據事務日志中記錄的數據進行恢復,這樣全部數據都恢復到事務提交前的狀態,仍然保持數據一致性。
此外,像 MySQL 數據庫還有 binlog 日志文件,記錄全部的數據更新操作記錄,這樣只要有了 binlog 就可以完整復現數據庫的歷史變更,還可以實現數據庫的主從復制,構建高性能、高可用的數據庫系統,我將會在架構模塊進一步為你講述。
## 小結
做應用開發需要了解 RDBMS 的架構原理,但是關系數據庫系統非常龐大復雜,對于一般的應用開發者而言,全面掌握關系數據庫的各種實現細節,代價高昂,也沒有必要。我們只需要掌握數據庫的架構原理與執行過程,數據庫文件的存儲原理與索引的實現方式,以及數據庫事務與數據庫復制的基本原理就可以了。然后,在開發工作中針對各種數據庫問題去思考,其背后的原理是什么,應該如何處理。通過這樣不斷地思考學習,不但能夠讓使用數據庫方面的能力不斷提高,也能對數據庫軟件的設計理念也會有更深刻的認識,自己軟件設計與架構的能力也會得到加強。
- 技能知識點
- 對死鎖問題的理解
- 文件系統原理:如何用1分鐘遍歷一個100TB的文件?
- 數據庫原理:為什么PrepareStatement性能更好更安全?
- Java Web程序的運行時環境到底是怎樣的?
- 你真的知道自己要解決的問題是什么嗎?
- 如何解決問題
- 經驗分享
- GIT的HTTP方式免密pull、push
- 使用xhprof對php7程序進行性能分析
- 微信掃碼登錄和使用公眾號方式進行掃碼登錄
- 關于curl跳轉抓取
- Linux 下配置 Git 操作免登錄 ssh 公鑰
- Linux Memcached 安裝
- php7安裝3.4版本的phalcon擴展
- centos7下php7.0.x安裝phalcon框架
- 將字符串按照指定長度分割
- 搜索html源碼中標簽包的純文本
- 更換composer鏡像源為阿里云
- mac 隱藏文件顯示/隱藏
- 谷歌(google)世界各國網址大全
- 實戰文檔
- PHP7安裝intl擴展和linux安裝icu
- linux編譯安裝時常見錯誤解決辦法
- linux刪除文件后不釋放磁盤空間解決方法
- PHP開啟異步多線程執行腳本
- file_exists(): open_basedir restriction in effect. File完美解決方案
- PHP 7.1 安裝 ssh2 擴展,用于PHP進行ssh連接
- php命令行加載的php.ini
- linux文件實時同步
- linux下php的psr.so擴展源碼安裝
- php將字符串中的\n變成真正的換行符?
- PHP7 下安裝 memcache 和 memcached 擴展
- PHP 高級面試題 - 如果沒有 mb 系列函數,如何切割多字節字符串
- PHP設置腳本最大執行時間的三種方法
- 升級Php 7.4帶來的兩個大坑
- 不同域名的iframe下,fckeditor在chrome下的SecurityError,解決辦法~~
- Linux find+rm -rf 執行組合刪除
- 從零搭建Prometheus監控報警系統
- Bug之group_concat默認長度限制
- PHP生成的XML顯示無效的Char值27消息(PHP generated XML shows invalid Char value 27 message)
- XML 解析中,如何排除控制字符
- PHP各種時間獲取
- nginx配置移動自適應跳轉
- 已安裝nginx動態添加模塊
- auto_prepend_file與auto_append_file使用方法
- 利用nginx實現web頁面插入統計代碼
- Nginx中的rewrite指令(break,last,redirect,permanent)
- nginx 中 index try_files location 這三個配置項的作用
- linux安裝git服務器
- PHP 中運用 elasticsearch
- PHP解析Mysql Binlog
- 好用的PHP學習網(持續更新中)
- 一篇寫給準備升級PHP7的小伙伴的文章
- linux 安裝php7 -系統centos7
- Linux 下多php 版本共存安裝
- PHP編譯安裝時常見錯誤解決辦法,php編譯常見錯誤
- nginx upstream模塊--負載均衡
- 如何解決Tomcat服務器打開不了HOST Manager的問題
- PHP的內存泄露問題與垃圾回收
- Redis數據結構 - string字符串
- PHP開發api接口安全驗證
- 服務接口API限流 Rate Limit
- php內核分析---內存管理(一)
- PHP內存泄漏問題解析
- 【代碼片-1】 MongoDB與PHP -- 高級查詢
- 【代碼片-1】 php7 mongoDB 簡單封裝
- php與mysql系統中出現大量數據庫sleep的空連接問題分析
- 解決crond引發大量sendmail、postdrop進程問題
- PHP操作MongoDB GridFS 存儲文件,如圖片文件
- 淺談php安全
- linux上keepalived+nginx實現高可用web負載均衡
- 整理php防注入和XSS攻擊通用過濾