
## 什么是Prometheus?
Prometheus是由SoundCloud開發的開源監控報警系統和時序列數據庫(TSDB)。Prometheus使用Go語言開發,是Google BorgMon監控系統的開源版本。
2016年由Google發起Linux基金會旗下的原生云基金會(Cloud Native Computing Foundation), 將Prometheus納入其下第二大開源項目。
Prometheus目前在開源社區相當活躍。
Prometheus和Heapster(Heapster是K8S的一個子項目,用于獲取集群的性能數據。)相比功能更完善、更全面。Prometheus性能也足夠支撐上萬臺規模的集群。
## Prometheus的特點
* 多維度數據模型。
* 靈活的查詢語言。
* 不依賴分布式存儲,單個服務器節點是自主的。
* 通過基于HTTP的pull方式采集時序數據。
* 可以通過中間網關進行時序列數據推送。
* 通過服務發現或者靜態配置來發現目標服務對象。
* 支持多種多樣的圖表和界面展示,比如Grafana等。
官網地址:https://prometheus.io/
## 架構圖
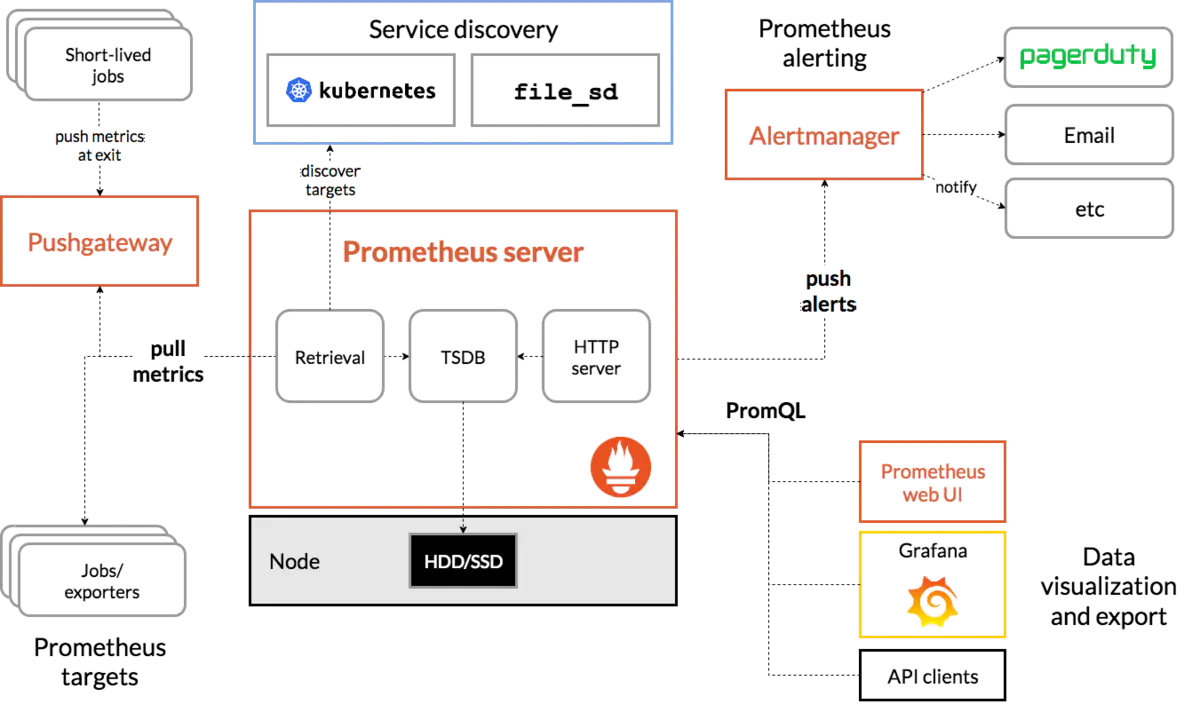
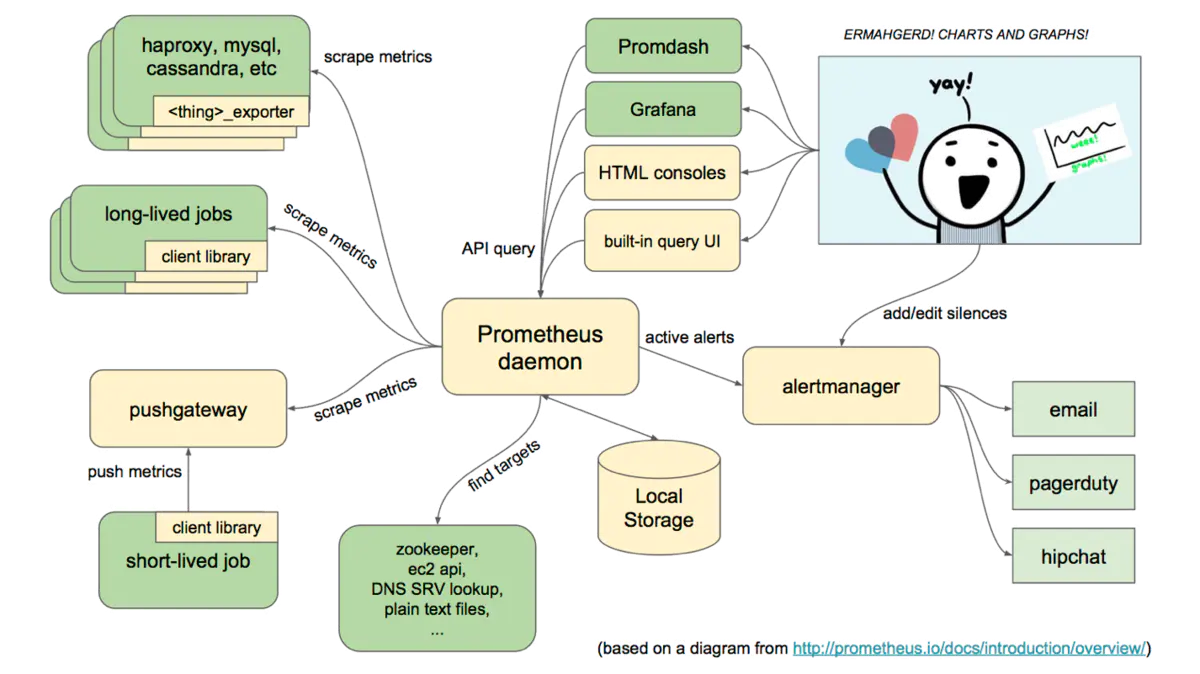
## 基本原理
Prometheus的基本原理是通過HTTP協議周期性抓取被監控組件的狀態,任意組件只要提供對應的HTTP接口就可以接入監控。不需要任何SDK或者其他的集成過程。這樣做非常適合做虛擬化環境監控系統,比如VM、Docker、Kubernetes等。輸出被監控組件信息的HTTP接口被叫做exporter 。目前互聯網公司常用的組件大部分都有exporter可以直接使用,比如Varnish、Haproxy、Nginx、MySQL、Linux系統信息(包括磁盤、內存、CPU、網絡等等)。
## 服務過程
* Prometheus Daemon負責定時去目標上抓取metrics(指標)數據,每個抓取目標需要暴露一個http服務的接口給它定時抓取。Prometheus支持通過配置文件、文本文件、Zookeeper、Consul、DNS SRV Lookup等方式指定抓取目標。Prometheus采用PULL的方式進行監控,即服務器可以直接通過目標PULL數據或者間接地通過中間網關來Push數據。
* Prometheus在本地存儲抓取的所有數據,并通過一定規則進行清理和整理數據,并把得到的結果存儲到新的時間序列中。
* Prometheus通過PromQL和其他API可視化地展示收集的數據。Prometheus支持很多方式的圖表可視化,例如Grafana、自帶的Promdash以及自身提供的模版引擎等等。Prometheus還提供HTTP API的查詢方式,自定義所需要的輸出。
* PushGateway支持Client主動推送metrics到PushGateway,而Prometheus只是定時去Gateway上抓取數據。
* Alertmanager是獨立于Prometheus的一個組件,可以支持Prometheus的查詢語句,提供十分靈活的報警方式。
## 三大套件
* Server 主要負責數據采集和存儲,提供PromQL查詢語言的支持。
* Alertmanager 警告管理器,用來進行報警。
* Push Gateway 支持臨時性Job主動推送指標的中間網關。
## 本飛豬教程內容簡介
* 1.演示安裝Prometheus Server
* 2.演示通過golang和node-exporter提供metrics接口
* 3.演示pushgateway的使用
* 4.演示grafana的使用
* 5.演示alertmanager的使用
## 安裝準備
這里我的服務器IP是10.211.55.25,登入,建立相應文件夾
```
mkdir -p /home/chenqionghe/promethues
mkdir -p /home/chenqionghe/promethues/server
mkdir -p /home/chenqionghe/promethues/client
touch /home/chenqionghe/promethues/server/rules.yml
chmod 777 /home/chenqionghe/promethues/server/rules.yml
```
下面開始三大套件的學習
# 一.安裝Prometheus Server
通過docker方式
首先創建一個配置文件/home/chenqionghe/test/prometheus/prometheus.yml
掛載之前需要改變文件權限為777,要不會引起修改宿主機上的文件內容不同步的問題
```
global:
scrape_interval: 15s # 默認抓取間隔, 15秒向目標抓取一次數據。
external_labels:
monitor: 'codelab-monitor'
# 這里表示抓取對象的配置
scrape_configs:
#這個配置是表示在這個配置內的時間序例,每一條都會自動添加上這個{job_name:"prometheus"}的標簽 - job_name: 'prometheus'
scrape_interval: 5s # 重寫了全局抓取間隔時間,由15秒重寫成5秒
static_configs:
- targets: ['localhost:9090']
```
運行
```
docker rm -f prometheus
docker run --name=prometheus -d \
-p 9090:9090 \
-v /home/chenqionghe/promethues/server/prometheus.yml:/etc/prometheus/prometheus.yml \
-v /home/chenqionghe/promethues/server/rules.yml:/etc/prometheus/rules.yml \
prom/prometheus:v2.7.2 \
--config.file=/etc/prometheus/prometheus.yml \
--web.enable-lifecycle
```
啟動時加上--web.enable-lifecycle啟用遠程熱加載配置文件
調用指令是curl -X POST http://localhost:9090/-/reload
訪問http://10.211.55.25:9090
我們會看到如下l界面
訪問http://10.211.55.25:9090/metrics
我們配置了9090端口,默認prometheus會抓取自己的/metrics接口
在Graph選項已經可以看到監控的數據

# 二.安裝客戶端提供metrics接口
## 1.通過golang客戶端提供metrics
```
mkdir -p /home/chenqionghe/promethues/client/golang/src
cd !$
export GOPATH=/home/chenqionghe/promethues/client/golang/
#克隆項目
git clone https://github.com/prometheus/client_golang.git
#安裝需要FQ的第三方包
mkdir -p $GOPATH/src/golang.org/x/
cd !$
git clone https://github.com/golang/net.git
git clone https://github.com/golang/sys.git
git clone https://github.com/golang/tools.git
#安裝必要軟件包
go get -u -v github.com/prometheus/client_golang/prometheus
#編譯
cd $GOPATH/src/client_golang/examples/random
go build -o random main.go
```
運行3個示例metrics接口
```
./random -listen-address=:8080 &
./random -listen-address=:8081 &
./random -listen-address=:8082 &
```
## 2.通過node exporter提供metrics
```
docker run -d \
--name=node-exporter \
-p 9100:9100 \
prom/node-exporter
```
然后把這兩些接口再次配置到prometheus.yml, 重新載入配置curl -X POST http://localhost:9090/-/reload
```
global:
scrape_interval: 15s # 默認抓取間隔, 15秒向目標抓取一次數據。
external_labels:
monitor: 'codelab-monitor'
rule_files:
#- 'prometheus.rules'
# 這里表示抓取對象的配置
scrape_configs:
#這個配置是表示在這個配置內的時間序例,每一條都會自動添加上這個{job_name:"prometheus"}的標簽 - job_name: 'prometheus'
- job_name: 'prometheus'
scrape_interval: 5s # 重寫了全局抓取間隔時間,由15秒重寫成5秒
static_configs:
- targets: ['localhost:9090']
- targets: ['http://10.211.55.25:8080', 'http://10.211.55.25:8081','http://10.211.55.25:8082']
labels:
group: 'client-golang'
- targets: ['http://10.211.55.25:9100']
labels:
group: 'client-node-exporter'
```
可以看到接口都生效了
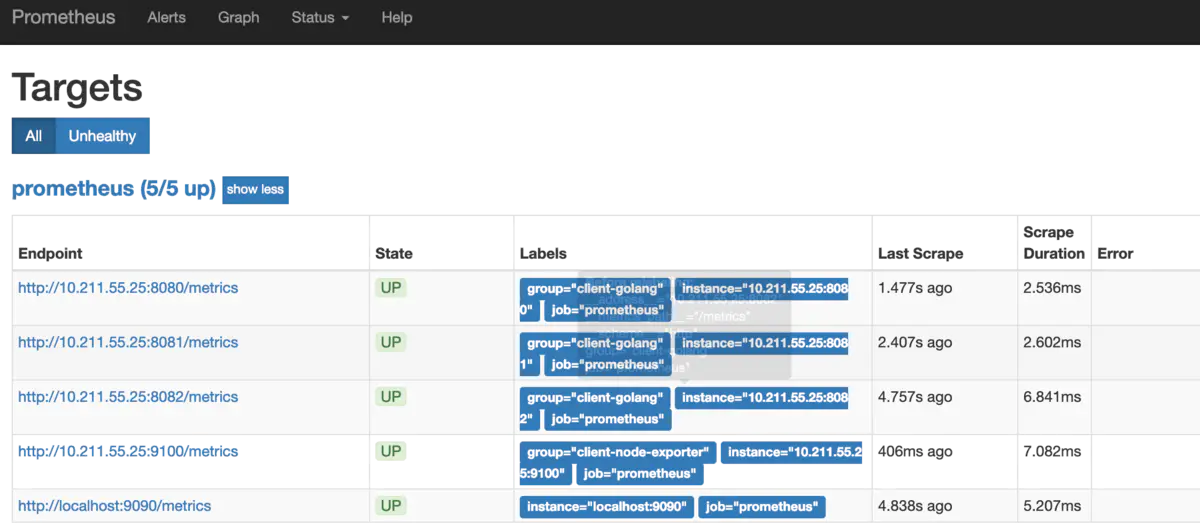
prometheus還提供了各種exporter工具,感興趣小伙伴可以去研究一下
# 三.安裝pushgateway
pushgateway是為了允許臨時作業和批處理作業向普羅米修斯公開他們的指標。
由于這類作業的存在時間可能不夠長, 無法抓取到, 因此它們可以將指標推送到推網關中。
Prometheus采集數據是用的pull也就是拉模型,這從我們剛才設置的5秒參數就能看出來。但是有些數據并不適合采用這樣的方式,對這樣的數據可以使用Push Gateway服務。
它就相當于一個緩存,當數據采集完成之后,就上傳到這里,由Prometheus稍后再pull過來。
我們來試一下,首先啟動Push Gateway
```
mkdir -p /home/chenqionghe/promethues/pushgateway
cd !$
docker run -d -p 9091:9091 --name pushgateway prom/pushgateway
```
訪問http://10.211.55.25:9091 可以看到pushgateway已經運行起來了
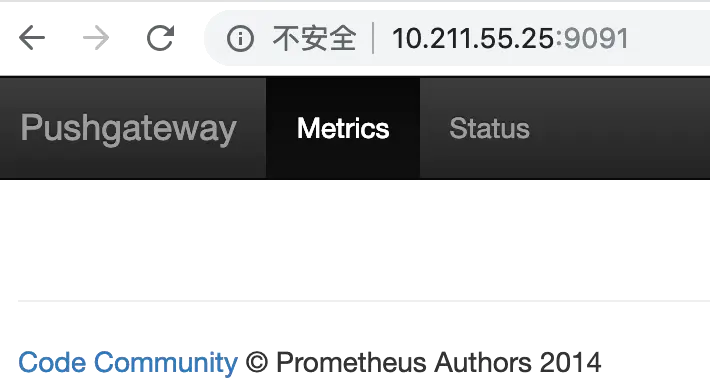
接下來我們就可以往pushgateway推送數據了,prometheus提供了多種語言的sdk,最簡單的方式就是通過shell
* 推送一個指標
```
echo "cqh_metric 100" | curl --data-binary @- http://ubuntu-linux:9091/metrics/job/cqh
```
* 推送多個指標
```
cat <<EOF | curl --data-binary @- http://10.211.55.25:9091/metrics/job/cqh/instance/test
# 鍛煉場所價格
muscle_metric{label="gym"} 8800
# 三大項數據 kg
bench_press 100
dead_lift 160
deep_squal 160
EOF
```
然后我們再將pushgateway配置到prometheus.yml里邊,重載配置
看到已經可以搜索出剛剛推送的指標了
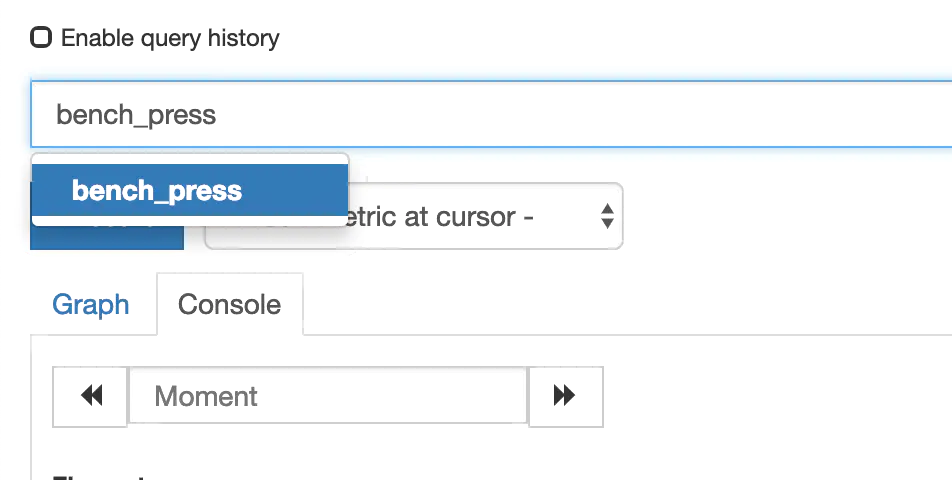
# 四.安裝Grafana展示
Grafana是用于可視化大型測量數據的開源程序,它提供了強大和優雅的方式去創建、共享、瀏覽數據。
Dashboard中顯示了你不同metric數據源中的數據。
Grafana最常用于因特網基礎設施和應用分析,但在其他領域也有用到,比如:工業傳感器、家庭自動化、過程控制等等。
Grafana支持熱插拔控制面板和可擴展的數據源,目前已經支持Graphite、InfluxDB、OpenTSDB、Elasticsearch、Prometheus等。
我們使用docker安裝
```
docker run -d -p 3000:3000 --name grafana grafana/grafana
```
默認登錄賬戶和密碼都是admin,進入后界面如下
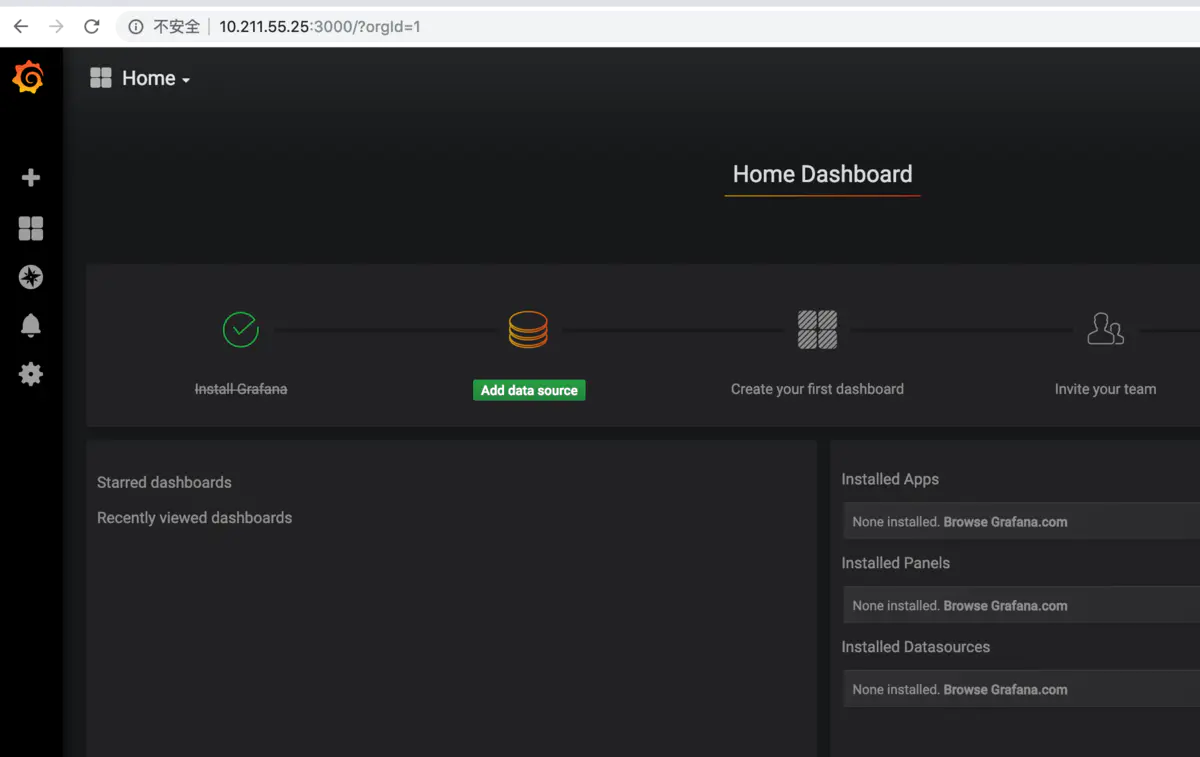
我們添加一個數據源
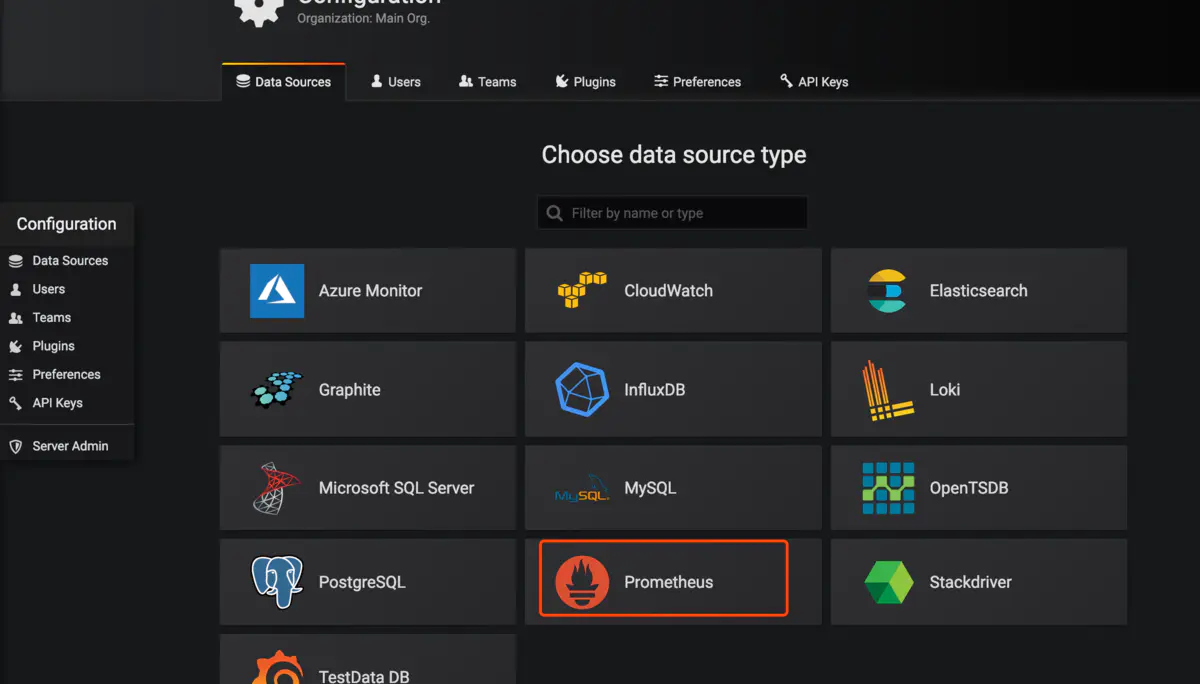
把Prometheus的地址填上
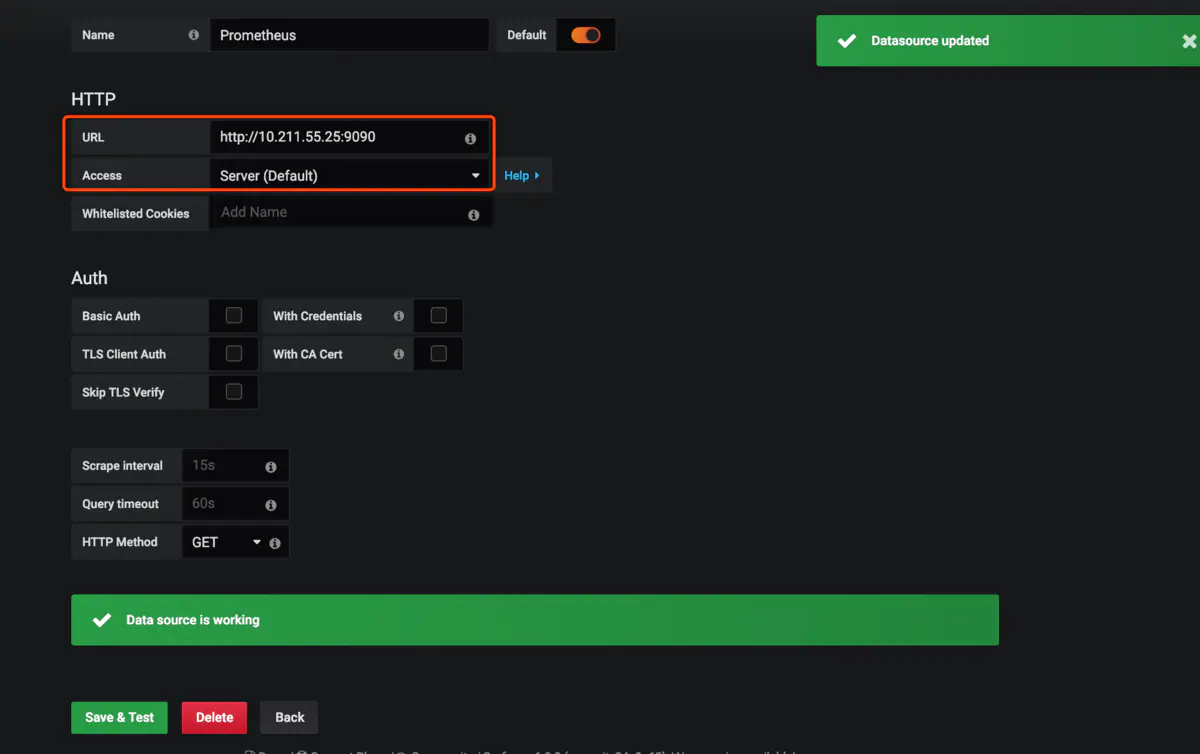
導入prometheus的模板
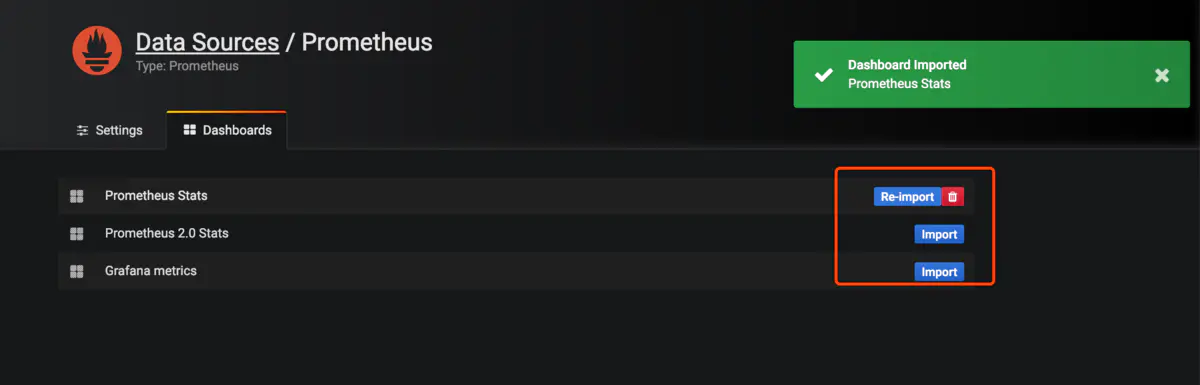
打開左上角選擇已經導入的模板會看到已經有各種圖
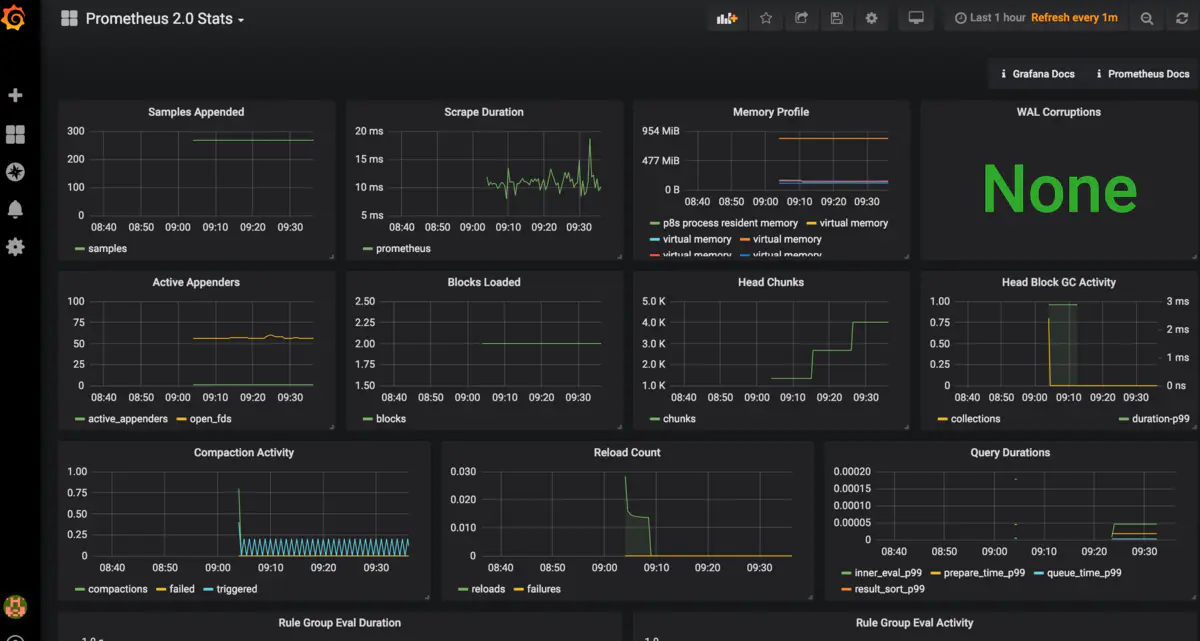
我們來添加一個自己的圖表
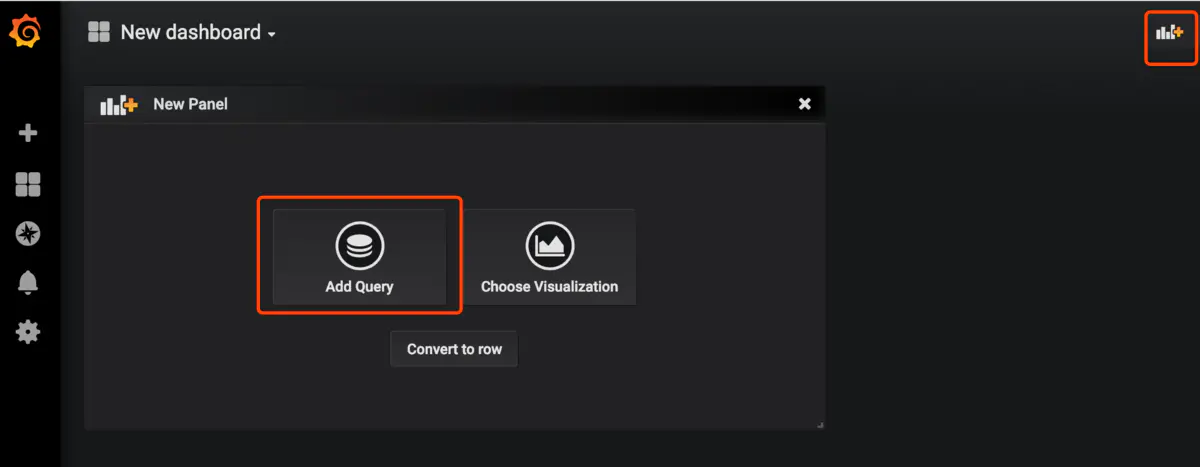
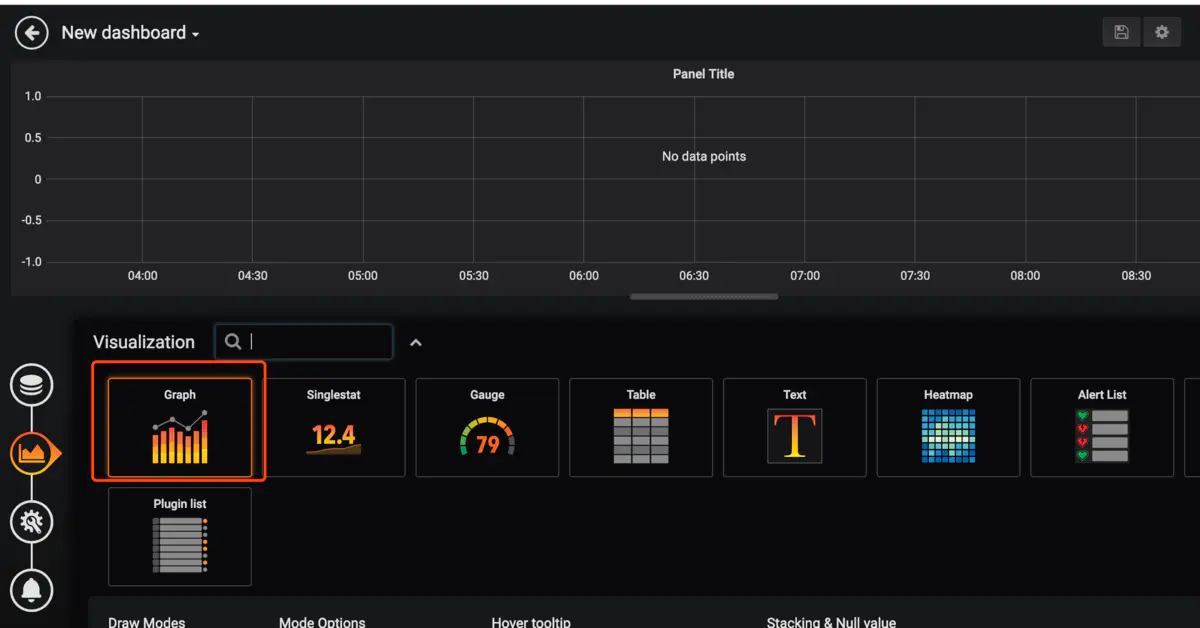
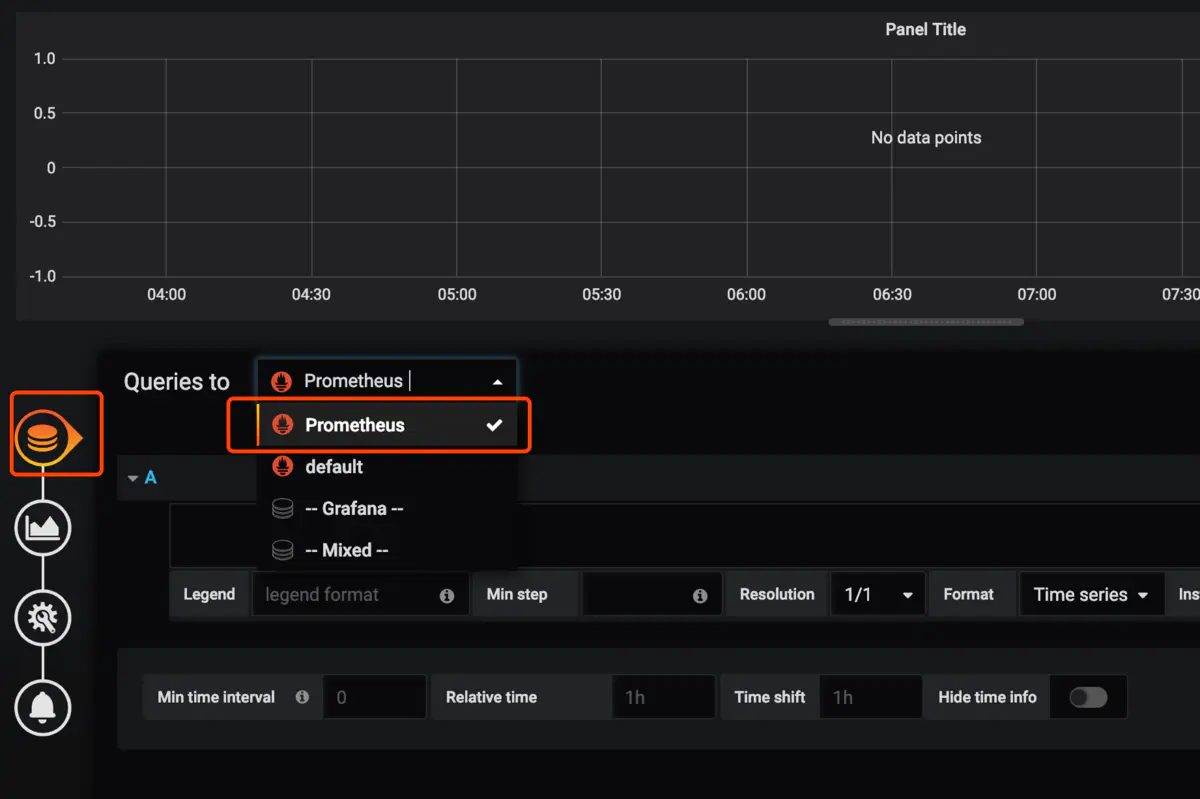
指定自己想看的指標和關鍵字,右上角保存
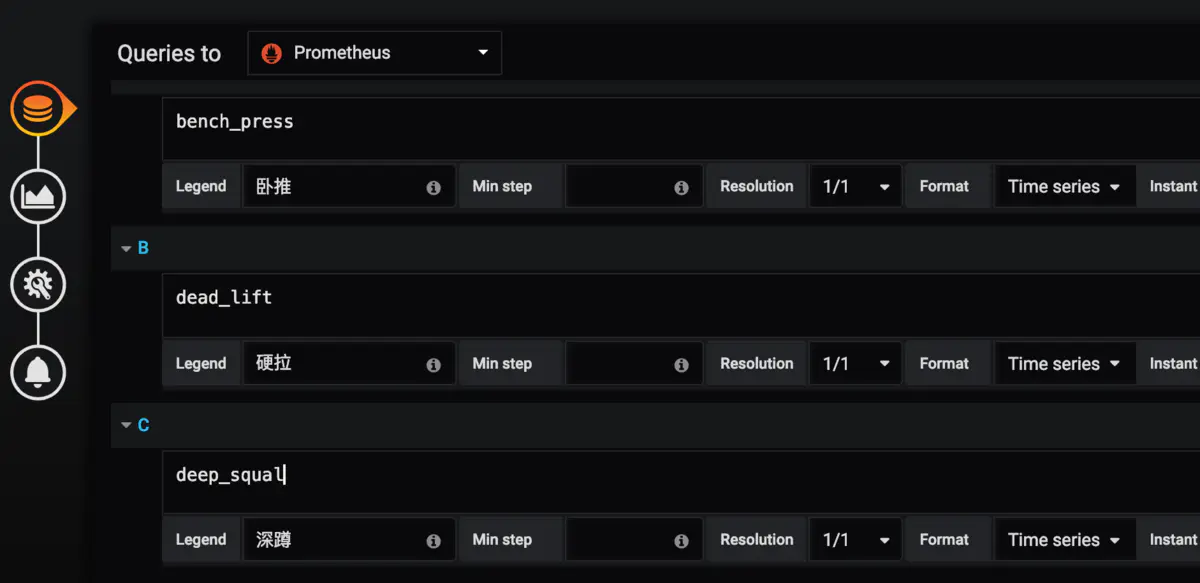
看到如下數據
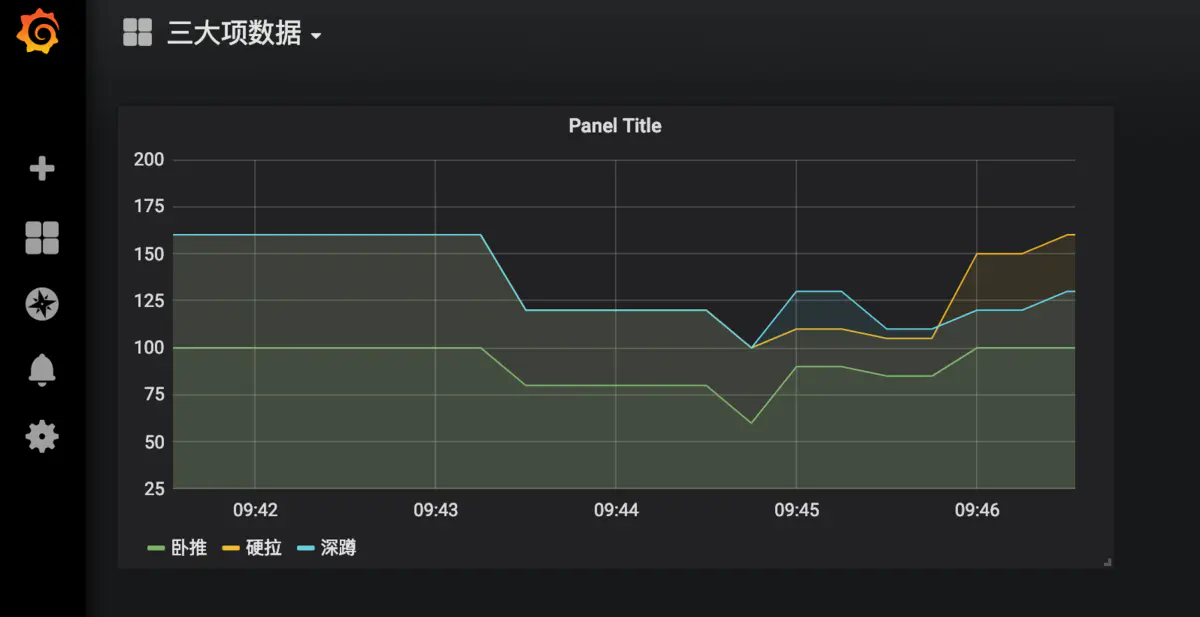
到這里我們就已經實現了數據的自動收集和展示,下面來說下prometheus如何自動報警
# 五.安裝AlterManager
Pormetheus的警告由獨立的兩部分組成。
Prometheus服務中的警告規則發送警告到Alertmanager。
然后這個Alertmanager管理這些警告。包括silencing, inhibition, aggregation,以及通過一些方法發送通知,例如:email,PagerDuty和HipChat。
建立警告和通知的主要步驟:
* 創建和配置Alertmanager
* 啟動Prometheus服務時,通過-alertmanager.url標志配置Alermanager地址,以便Prometheus服務能和Alertmanager建立連接。
創建和配置Alertmanager
```
mkdir -p /home/chenqionghe/promethues/alertmanager
cd !$
```
創建配置文件alertmanager.yml
```
global:
resolve_timeout: 5m
route:
group_by: ['cqh']
group_wait: 10s #組報警等待時間
group_interval: 10s #組報警間隔時間
repeat_interval: 1m #重復報警間隔時間
receiver: 'web.hook'
receivers:
- name: 'web.hook'
webhook_configs:
- url: 'http://10.211.55.2:8888/open/test'
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
```
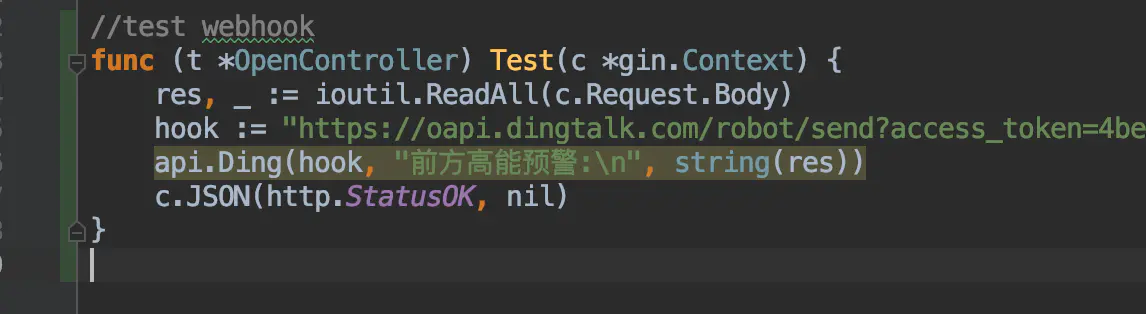
這里配置成了web.hook的方式,當server通知alertmanager會自動調用webhook http://10.211.55.2:8888/open/test
下面運行altermanager
```
docker rm -f alertmanager
docker run -d -p 9093:9093 \
--name alertmanager \
-v /home/chenqionghe/promethues/alertmanager/alertmanager.yml:/etc/alertmanager/alertmanager.yml \
prom/alertmanager
```
訪問http://10.211.55.25:9093
接下來修改Server端配置報警規則和altermanager地址
修改規則/home/chenqionghe/promethues/server/rules.yml
```
groups:
- name: cqh
rules:
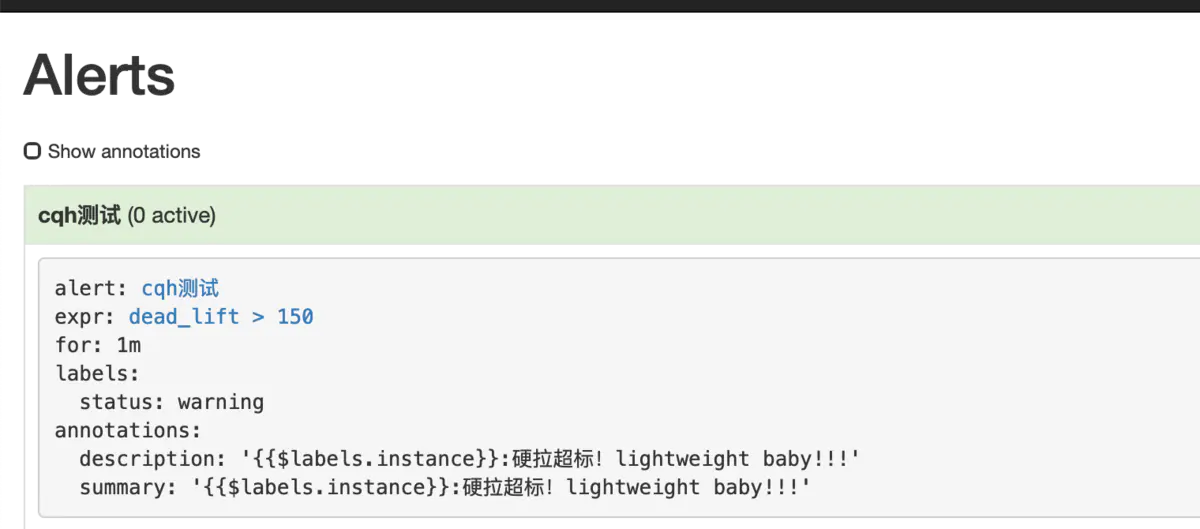
- alert: cqh測試
expr: dead_lift > 150
for: 1m
labels:
status: warning
annotations:
summary: "{{$labels.instance}}:硬拉超標!lightweight baby!!!"
description: "{{$labels.instance}}:硬拉超標!lightweight baby!!!"
```
這條規則的意思是,硬拉超過150公斤,持續一分鐘,就報警通知
然后再修改prometheus添加altermanager配置
```
global:
scrape_interval: 15s # 默認抓取間隔, 15秒向目標抓取一次數據。
external_labels:
monitor: 'codelab-monitor'
rule_files:
- /etc/prometheus/rules.yml
# 這里表示抓取對象的配置
scrape_configs:
#這個配置是表示在這個配置內的時間序例,每一條都會自動添加上這個{job_name:"prometheus"}的標簽 - job_name: 'prometheus'
- job_name: 'prometheus'
scrape_interval: 5s # 重寫了全局抓取間隔時間,由15秒重寫成5秒
static_configs:
- targets: ['localhost:9090']
- targets: ['10.211.55.25:8080', '10.211.55.25:8081','10.211.55.25:8082']
labels:
group: 'client-golang'
- targets: ['10.211.55.25:9100']
labels:
group: 'client-node-exporter'
- targets: ['10.211.55.25:9091']
labels:
group: 'pushgateway'
alerting:
alertmanagers:
- static_configs:
- targets: ["10.211.55.25:9093"]
```
重載prometheus配置,規則就已經生效
接下來我們觀察grafana中數據的變化
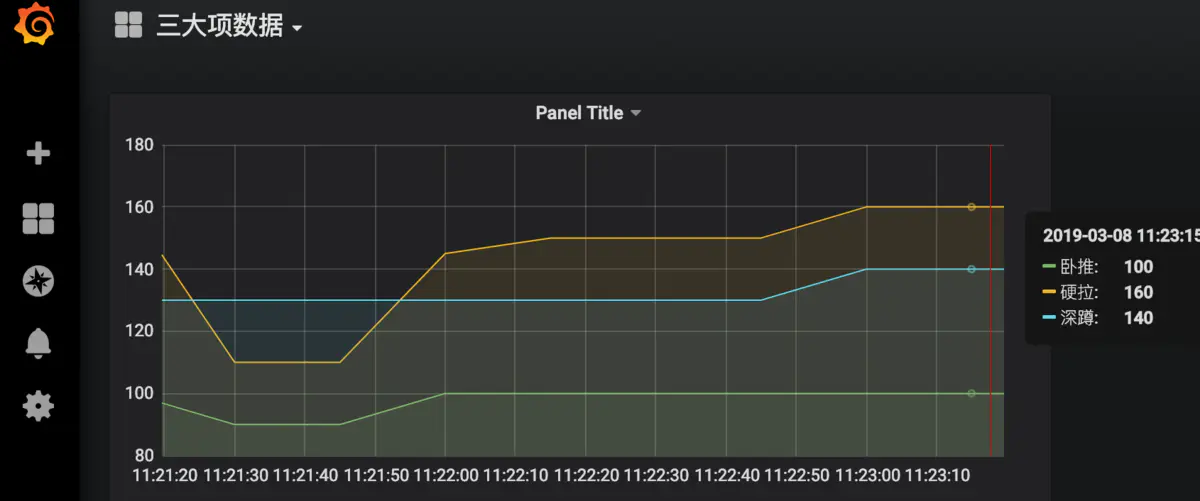
然后我們點擊prometheus的Alert模塊,會看到已經由綠->黃-紅,觸發了報警
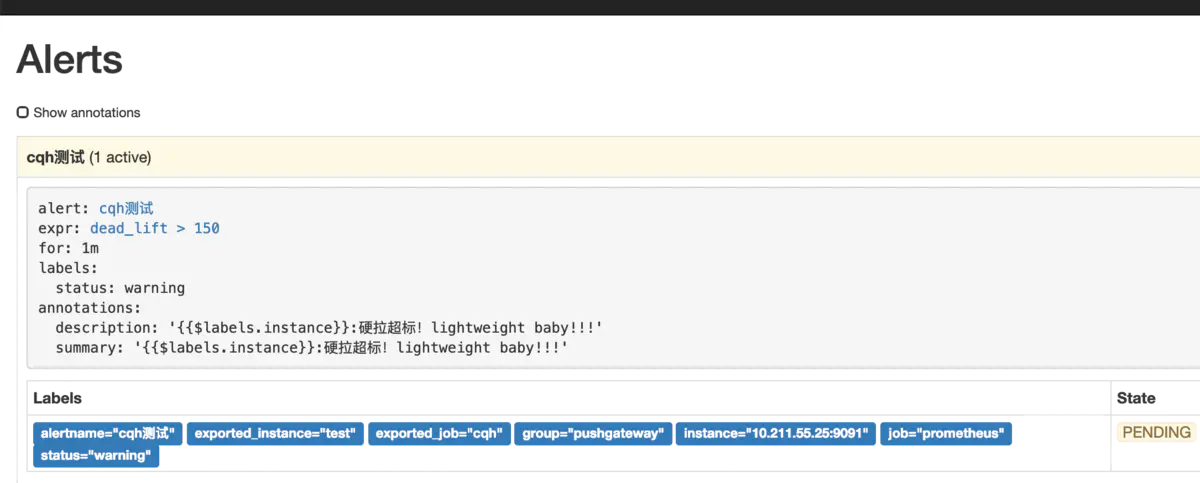
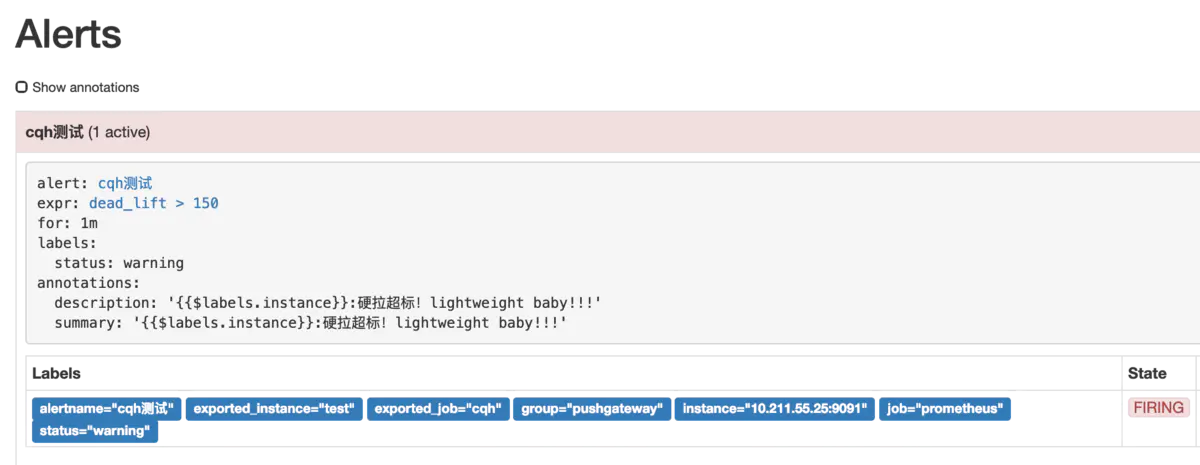
然后我們再來看看提供的webhook接口,這里的接口我是用的golang寫的,接到數據后將body內容報警到釘釘
釘釘收到報警內容如下

到這里,從零開始搭建Prometheus實現自動監控報警就說介紹完了,一條龍服務,自動抓取接口+自動報警+優雅的圖表展示,你還在等什么,趕緊high起來!
- 技能知識點
- 對死鎖問題的理解
- 文件系統原理:如何用1分鐘遍歷一個100TB的文件?
- 數據庫原理:為什么PrepareStatement性能更好更安全?
- Java Web程序的運行時環境到底是怎樣的?
- 你真的知道自己要解決的問題是什么嗎?
- 如何解決問題
- 經驗分享
- GIT的HTTP方式免密pull、push
- 使用xhprof對php7程序進行性能分析
- 微信掃碼登錄和使用公眾號方式進行掃碼登錄
- 關于curl跳轉抓取
- Linux 下配置 Git 操作免登錄 ssh 公鑰
- Linux Memcached 安裝
- php7安裝3.4版本的phalcon擴展
- centos7下php7.0.x安裝phalcon框架
- 將字符串按照指定長度分割
- 搜索html源碼中標簽包的純文本
- 更換composer鏡像源為阿里云
- mac 隱藏文件顯示/隱藏
- 谷歌(google)世界各國網址大全
- 實戰文檔
- PHP7安裝intl擴展和linux安裝icu
- linux編譯安裝時常見錯誤解決辦法
- linux刪除文件后不釋放磁盤空間解決方法
- PHP開啟異步多線程執行腳本
- file_exists(): open_basedir restriction in effect. File完美解決方案
- PHP 7.1 安裝 ssh2 擴展,用于PHP進行ssh連接
- php命令行加載的php.ini
- linux文件實時同步
- linux下php的psr.so擴展源碼安裝
- php將字符串中的\n變成真正的換行符?
- PHP7 下安裝 memcache 和 memcached 擴展
- PHP 高級面試題 - 如果沒有 mb 系列函數,如何切割多字節字符串
- PHP設置腳本最大執行時間的三種方法
- 升級Php 7.4帶來的兩個大坑
- 不同域名的iframe下,fckeditor在chrome下的SecurityError,解決辦法~~
- Linux find+rm -rf 執行組合刪除
- 從零搭建Prometheus監控報警系統
- Bug之group_concat默認長度限制
- PHP生成的XML顯示無效的Char值27消息(PHP generated XML shows invalid Char value 27 message)
- XML 解析中,如何排除控制字符
- PHP各種時間獲取
- nginx配置移動自適應跳轉
- 已安裝nginx動態添加模塊
- auto_prepend_file與auto_append_file使用方法
- 利用nginx實現web頁面插入統計代碼
- Nginx中的rewrite指令(break,last,redirect,permanent)
- nginx 中 index try_files location 這三個配置項的作用
- linux安裝git服務器
- PHP 中運用 elasticsearch
- PHP解析Mysql Binlog
- 好用的PHP學習網(持續更新中)
- 一篇寫給準備升級PHP7的小伙伴的文章
- linux 安裝php7 -系統centos7
- Linux 下多php 版本共存安裝
- PHP編譯安裝時常見錯誤解決辦法,php編譯常見錯誤
- nginx upstream模塊--負載均衡
- 如何解決Tomcat服務器打開不了HOST Manager的問題
- PHP的內存泄露問題與垃圾回收
- Redis數據結構 - string字符串
- PHP開發api接口安全驗證
- 服務接口API限流 Rate Limit
- php內核分析---內存管理(一)
- PHP內存泄漏問題解析
- 【代碼片-1】 MongoDB與PHP -- 高級查詢
- 【代碼片-1】 php7 mongoDB 簡單封裝
- php與mysql系統中出現大量數據庫sleep的空連接問題分析
- 解決crond引發大量sendmail、postdrop進程問題
- PHP操作MongoDB GridFS 存儲文件,如圖片文件
- 淺談php安全
- linux上keepalived+nginx實現高可用web負載均衡
- 整理php防注入和XSS攻擊通用過濾