
## 概念介紹
* **Broker**:簡單來說就是消息隊列服務器實體。
* **Exchange**:消息交換機,它指定消息按什么規則,路由到哪個隊列。
* **Queue**:消息隊列載體,每個消息都會被投入到一個或多個隊列。
* **Binding**:綁定,它的作用就是把exchange和queue按照路由規則綁定起來。
* **Routing Key**:路由關鍵字,exchange根據這個關鍵字進行消息投遞。
* **vhost**:虛擬主機,一個broker里可以開設多個vhost,用作不同用戶的權限分離。
* **producer**:消息生產者,就是投遞消息的程序。
* **consumer**:消息消費者,就是接受消息的程序。
* **channel**:消息通道,在客戶端的每個連接里,可建立多個channel,每個channel代表一個會話任務。
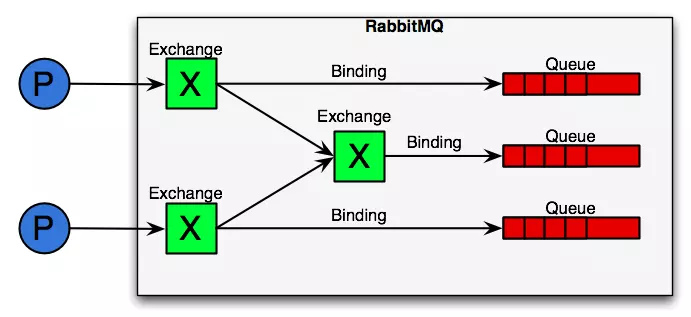
## RabbitMQ使用流程
AMQP模型中,消息在producer中產生,發送到MQ的exchange上,exchange根據配置的路由方式發到相應的Queue上,Queue又將消息發送給consumer,消息從queue到consumer有push和pull兩種方式。 消息隊列的使用過程大概如下:
1. 客戶端連接到消息隊列服務器,打開一個channel。
2. 客戶端聲明一個exchange,并設置相關屬性。
3. 客戶端聲明一個queue,并設置相關屬性。
4. 客戶端使用routing key,在exchange和queue之間建立好綁定關系。
5. 客戶端投遞消息到exchange。
exchange接收到消息后,就根據消息的key和已經設置的binding,進行消息路由,將消息投遞到一個或多個隊列里。 exchange也有幾個類型,完全根據key進行投遞的叫做Direct交換機,例如,綁定時設置了routing key為”abc”,那么客戶端提交的消息,只有設置了key為”abc”的才會投遞到隊列。
## rabbitMQ常用的命令
啟動監控管理器:rabbitmq-plugins enable rabbitmq\_management關閉監控管理器:rabbitmq-plugins disable rabbitmq\_management啟動rabbitmq:rabbitmq-service start關閉rabbitmq:rabbitmq-service stop查看所有的隊列:rabbitmqctl list\_queues清除所有的隊列:rabbitmqctl reset關閉應用:rabbitmqctl stop\_app啟動應用:rabbitmqctl start\_app
**用戶和權限設置**
添加用戶:rabbitmqctl add\_user username password
分配角色:rabbitmqctl set\_user\_tags username administrator
新增虛擬主機:rabbitmqctl add\_vhost vhost\_name
將新虛擬主機授權給新用戶:`rabbitmqctl set_permissions -p vhost_name username “.*” “.*” “.*”`(后面三個”\*”代表用戶擁有配置、寫、讀全部權限)
**角色說明**
* 超級管理員(administrator)可登陸管理控制臺,可查看所有的信息,并且可以對用戶,策略(policy)進行操作。
* 監控者(monitoring)可登陸管理控制臺,同時可以查看rabbitmq節點的相關信息(進程數,內存使用情況,磁盤使用情況等)
* 策略制定者(policymaker)可登陸管理控制臺, 同時可以對policy進行管理。但無法查看節點的相關信息(上圖紅框標識的部分)。
* 普通管理者(management)僅可登陸管理控制臺,無法看到節點信息,也無法對策略進行管理。
* 其他無法登陸管理控制臺,通常就是普通的生產者和消費者。
- 文章翻譯
- Large-scale cluster management at Google with Borg
- Borg Omega and kubernetes
- scaling kubernetes to 7500 nodes
- bpf 的過去,未來與現在
- Demystifying Istio Circuit Breaking
- 知識圖譜
- skill level up graph
- 一、運維常用技能
- 1.0 Vim (編輯器)
- 1.1 Nginx & Tengine(Web服務)
- 基礎
- 1.2 zabbix
- 定義
- 登錄和配置用戶
- 1.3 RabbitMQ(消息隊列)
- 原理
- RabbitMQ(安裝)
- 1.4虛擬化技術
- KVM
- 1.5 Tomcat(Web中間件)
- 1.6Jenkins
- pipline
- 1.7 Docker
- network
- 1.8 Keepalived(負載均衡高可用)
- 1.9 Memcache(分布式緩存)
- 1.10 Zookeeper(分布式協調系統)
- 1.11 GitLab(版本控制)
- 1.12 Jenkins(運維自動化)
- 1.13 WAF(Web防火墻)
- 1.14 HAproxy負載均衡
- 1.15 NFS(文件傳輸)
- 1.16 Vim(編輯器)
- 1.17 Cobbler(自動化部署)
- 二、常用數據庫
- 2.1 MySQL(關系型數據庫)
- mysql主從復制
- 2.2 Mongodb(數據分析)
- 2.3 Redis(非關系數據庫)
- 三、自動化運維工具
- 3.1 Cobbler(系統自動化部署)
- 3.2 Ansible(自動化部署)
- 3.3 Puppet(自動化部署)
- 3.4 SaltStack(自動化運維)
- 四、存儲
- 4.1 GFS(文件型存儲)
- 4.2 Ceph(后端存儲)
- 五、運維監控工具
- 5.1 云鏡
- 5.2 ELK
- 六、運維云平臺
- 6.1 Kubernetes
- 6.2 OpenStack
- 介紹
- 安裝
- 七、Devops運維
- 7.1 理念
- 7.2 Devops運維實戰
- 八、編程語言
- 8.1 Shell
- 書籍《Wicked Cool Shell Scripts》
- 8.2 Python
- 8.3 C
- 8.4 Java
- leecode算法與數據結構
- 九、雜記
- 高優先級技能
- 知識點
- JD搜集
- 明顯的短板
- 1.0 Python
- 1.1 Kubernetes
- 1.18.2 《kubernetes in action》
- 遺漏知識點
- 1.18.3 GCP、azure、aliyun
- Azure文檔
- 1.18.5 《program with kubernetes》
- Istio
- HELM
- 《Kubernetes best practice》
- Kubernetes源碼學習
- Scheduler源碼
- 調度器入口
- 調度器框架
- Node篩選算法
- Node優先級算法
- pod搶占調度
- 入口
- 主要代碼結構
- new
- 文章翻譯
- Flannel
- 從二進制集群搭建
- 信息收集
- docker優化
- 1.2 shell
- 面試題
- grep awk sed 常見用法
- shell實踐
- 1.3 Data structure(數據結構)
- Calico
- Aliyun文檔以及重點模塊
- git
- 大數據組件
- 前端,后端,web框架
- cgroup,namespace
- 內核
- Linux搜集
- crontab
- centos7常用優化配置
- centos Mariadb
- eBPF
- ebpf的前世今生
- Linux性能問題排查與分析
- 性能分析搜集
- 性能分析常用10條
- 網絡性能優化
- 文本處理命令
- sql
- Iptables
- python面試題
- iptables
- iptables詳細
- zabbix面試題,proj
- prometheus
- web中間件
- nginx
- Haproxy
- grep sed awk
- Linux常用命令
- 云平臺
- 書籍Linux應用技巧
- kafka
- kafka面試題
- ETCD
- Jenkins
- 3天補充的點
- K8s源碼
- K8s
- k8s實操
- etcd
- test
- BPF
- PSFTP使用
- StackOverflow問答精選
- 問題
- 我對于學習思考
- 修改ssh超時時間
- 課程目錄
- 運維與運維開發
- The Person
- 個人雜談
- mysql主從復制
- 對于工作的認識與思考