
# :-: Large-scale cluster management at Google with Borg
此文主要介紹kubernetes的前生borg,主要涉及borg的主要架構與特性,重要的設計并在多年的google經營中學到的經驗,borg的優缺點,以及哪些方面被kubernetes繼承。
原文鏈接 [https://research.google/pubs/pub43438/](https://research.google/pubs/pub43438/)
這篇文章目前有不少地方仍然不能理解,后續會持續更新。
*****
本文摘錄與記錄對于這篇文章的學習。
###
## **1 Introduction**
Borg提供的主要特性有以下三點:
1.隱藏資源管理和錯誤處理的細節讓用戶能夠專注于應用的開發。
2.具有很高的可靠性與可用性。同時支持應用程序的復用。
3.能夠在大規模機器上同時負載。
:-: 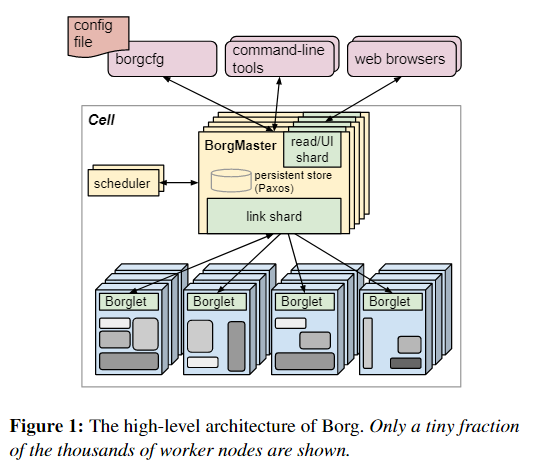
## :-: **borg架構圖**
在Borg中,將高優先級Borg job作為“production”(**prod**),剩下的就作為non-production”(**non-prod**).大多數長時間運行的服務都作為prod。在一個典型的cell中,prod job被分配了大約70%的CPU資源和大約60%的CPU使用量;它們大約占據了總內存的55%,占據了總內存使用的85%。分配和使用之間的差異將被證明是重要的。一個中等的cell大于有10K的機器,jobs可以強制指定到特定的os,處理器架構。
\*\*Allocs:\*\*指那些可以被用于運行的資源集合。Alloc可用于為將來的任務留出資源,在停止任務和重新啟動任務之間保留資源,并將來自不同作業的任務收集到同一臺機器上創建分配集后,可以提交一個或多個作業在其中運行。簡潔起見,我們通常會使用“job”來指代分配或頂級任務,使用“tesk”來指代alloc集。
## **2.1 Priority, quota, and admission control**
每個作業都有優先級,一個小的正整數。高優先級的任務可以以較低優先級的任務為代價獲得資源,即使這涉及搶占(殺死)后者。配額的標簽包括:moni-toring,production,batch, andbest effort(also known astestingorfree)。prod jobs屬于monitoring 與productionbands。優先級表示在單元格中正在運行或等待運行的作業的相對重要性。配額用于決定允許哪些作業進行調度。配額表示為一段時間(通常為數月)內具有給定優先級的資源數量(CPU,RAM,磁盤等)的向量。數量指定了用戶的作業請求一次可以請求的最大資源量(例如,“從現在到7月下旬,cell中的內存為20 TiB”)。配額檢查是準入控制的一部分,而非調度:配額不足的作業會在提交后立即被拒絕
## **2.2 Naming and monitoring**
為了能夠在重新分配新的機器后找到新的prod,borg為每一個任務創建一個“Borg name service” (BNS),其中包括cell name, job name, and task number,Borg將任務的主機名和端口寫到Chubby中名稱一致的,高度可用的文件中被使用到RPC系統去找到endpoint。BNS名稱也構成了DNS名稱的基礎。Borg還會在任務發生變化時將任務大小和任務運行狀況信息寫入到chubby中,這樣負載平衡器就可以知道將請求路由到哪里。Borg監視運行狀況并檢查URL,并重新啟動無法及時響應或返回HTTP錯誤代碼的任務。
一項名為Sigma的服務提供了一個基于Web的用戶界面(UI),用戶可以通過該界面檢查所有作業,特定單元的狀態,或者向下鉆取到各個作業和任務以檢查其資源行為,詳細的日志,執行歷史記錄,以及最終的結果。Borg在Infrastore中記錄所有作業提交和任務事件,以及每個任務的詳細資源使用信息,Infrastore是可擴展的只讀數據存儲,具有通過Dremel的類似SQL的界面進行交互。
### **2.2.1 Borg architecture**
Borg的所有組件都是用C++編寫的。每個單元的Borgmaster包含兩個進程:主 Borgmaster進程和單獨的調度程序。Borgmaster主進程處理客戶端RPC,這些RPC會更改狀態(例如,創建作業)或提供對數據的只讀訪問權限(例如,查找作業)。Borgmaster主進程處理客戶端RPC,這些RPC會更改狀態(例如,創建作業)或提供對數據的只讀訪問權限(例如,查找作業)。它還為系統中的所有對象(機器,任務,分配等)管理狀態機,與Borglets通信,并提供Web UI作為Sigma的備份。從邏輯上講,Borgmaster是一個單一的過程,但實際上被復制了五次。每個副本都維護該單元大多數狀態的內存副本,并且此狀態副本也記錄在基于Paxos的分布式,高可用性,本地磁盤存儲中。單個cell serves的elected master同時作為Paxos leader與state mutator。處理更改cell狀態的所有操作,例如提交作業或終止機器上的任務。
Borg在某個時間點的狀態稱為檢查點,其形式為定期快照以及保存在Paxos存儲的變更日志。檢查點有許多用途,包括將Borgmaster的狀態恢復到過去的任意點(例如,在接受觸發Borg中的軟件缺陷的請求之前,以便可以對其進行調試);通過手工操作端對它進行修復;建立事件的持久日志以供將來查詢;和離線模擬。
Borg可以使用稱為Fauxmaster的高保真Borgmaster模擬器讀取檢查點文件,并創建完整的生產環境Borgmaster代碼副本,并帶有連接到Borglets的接口。它接受RPC進行狀態機更改并執行諸如“計劃所有待處理的任務”之類的操作,并且我們通過與RPC進行交互,就好像它是一個實時的Borgmaster一樣,使用它來調試故障,通過Borglets的模擬可以從中重放真實的交互用戶,單步執行并觀察過去實際發生的系統狀態更改。 Fauxmaster還可以用于容量規劃(“可以容納多少個此類型的job?”),以及在對單元的配置進行更改之前進行完整性檢查(“此更改會淘汰重要的工作嗎?”)。
## **3.1 Scheduling**
提交作業后,Borgmaster將其持久地記錄在Paxos存儲中,并將該作業的任務添加到掛起隊列中。調度程序將對其進行異步掃描,如果有足夠的可用資源滿足任務的約束,調度程序會將任務分配給計算機。(調度程序主要用于執行任務,而不是工作。)掃描從高優先級到低優先級,并由優先級內的循環機制進行調制,以確保各個用戶之間的公平性,并避免在處理大量工作后出現行頭阻塞。調度算法包括兩部分:可行性檢查,查找可以在其上運行任務的機器,以及評分,以選擇可行的機器。在可行性檢查中,調度程序會找到一組滿足任務約束且具有足夠“可用”資源的機器,其中包括分配給可以撤出的低優先級任務的資源。
## **3.2 Borglet**
Borglet是本地Borg agent,它存在于cell的每臺計算機上。它啟動和停止任務;如果它們失敗,則重新啟動它們;通過操縱OS內核設置來管理本地資源;滾動調試日志;并向Borgmaster和其他監控系統報告機器的狀態。Borgmaster每隔幾秒鐘會輪詢每個Borglet,以檢索計算機的當前狀態并向其發送任何異常請求。這Borgmaster可以控制通信速率,避免了需要明確的流量控制機制,并防止了恢復風暴。The elected master負責準備消息發送到borglet和更新cell的狀態與他們的響應。為了實現性能可伸縮性,每個borgter副本運行一個stateless link分片來處理與一些Borglets的通信;只要發生Borgmaster election,分區就會重新計算分區。為了提高彈性,Borglet總是報告它的完整狀態,但是鏈接碎片通過只向狀態機報告差異來聚合和壓縮這些信息,以減少在所選主服務器上的更新負載。
如果Borglet不響應多個輪詢消息,則其計算機將標記為已關閉,并且正在運行的所有任務都將在其他計算機上重新安排。如果恢復了通信,則Borgmaster會通知Borglet取消已重新安排的任務,以避免重復。即使失去與Borgmaster的聯系,Borglet也會繼續正常運行,因此,即使所有Borgmaster副本均失敗,當前正在運行的任務和服務也將保持正常運行。
## **3.3 Scalability**
我們不確定Borg集中式架構的最終可擴展性限制將來自何處;到目前為止,每次達到極限時,我們都設法消除了極限。單個Borgmaster可以在一個單元中管理成千上萬的機器,并且幾個單元的任務每分鐘超過10000個。繁忙的Borgmaster使用10–14CPU和多達50 GiB RAM。我們使用多種技術來達到這一規模。
幾個事情使Borg調度程序更具可擴展性:
### **分數緩存**:????評估可行性并為機器評分是耗費昂貴的,因此Borg會緩存分數,直到機器的屬性或任務發生變化–例如,機器上的任務終止,屬性被更改或任務的需求變化。忽略資源數量的微小變化可減少緩存失效。
### **等價類**:Borg作業中的任務通常具有相同的要求和約束,因此,不是確定每臺機器上每個待處理任務的可行性,并為所有可行機器評分,在具有相同要求的一組任務中。Borg對每一個等價類中的一個任務進行評分。
### **寬松的隨機化**:計算大型單元中計算所有計算機的可行性和分數是浪費的,因此調度程序會以隨機順序檢查計算機,直到找到“足夠”的可行計算機進行評分,然后在該集合中選擇最佳計算機。這減少了任務進入和離開系統時所需的評分和緩存失效數量,并加快了任務向計算機的分配。
## **4\. Availability**
:-: 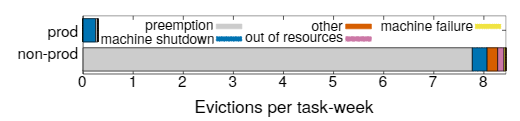,
失敗是大型系統中的常態。圖3提供了15個樣本單元中任務逐出原因的分解。Borg提供了處理失敗事件的操作,使用例如republication,持久化存儲在分布式系統中,如果合適的話,偶爾設置Checkpoint,即使如此,我們仍然嘗試減輕這些事件的影響,例如,如有必要,
?自動在新的機器上重新安排已退出的任務
?通過在整個故障域(如機器,機架和電源域)中分散作業從而減少相關的故障避免重復導致任務或機器崩潰的
?在諸如OS或機器升級之類的維護活動中限制允許的任務中斷率和作業中的任務數量
?使用聲明的期望狀態表示和等效冪等變操作,以便失敗的客戶端可以無害地重新提交任何忘記的請求
?避免重復導致任務或機器崩潰的task :: machine配對;
?通過重復地重新運行一個日志保護程序任務來恢復寫入到本地磁盤的中間數據(§2.4),即使它附加的alloc被終止或移動到另一臺機器。用戶可以設置系統持續嘗試的時間,通常是幾天。
????Borg的一個關鍵設計特點是,即使Borgmaster或某個任務的Borglet宕機,已經運行的任務仍能繼續運行。但是保持主服務器正常運行仍然很重要,因為當它宕機時,不能提交新的作業或更新現有的作業,來自失敗機器的任務不能重新調度。Borgmaster使用了使it在實踐中實現99.99%可用性的技術組合:機器故障復制;準入控制以避免任務過載;使用簡單的底層工具部署實例來最小化額外的依賴。每個單元獨立于其他單元,以盡量減少相關操作符錯誤和故障傳播的機會。這些目標,而不是可限制伸縮性,是大型cell的關鍵。
## **5\. Utilization**
Borg的主要目標之一是有效利用谷歌的機器,這是一項重大的金融投資:提高幾個百分點的機器利用率可以節省數百萬美元。本節討論和評估了Borg在這方面所采用的一些政策和技術。
## 5.1 Evaluation methodology
我們job有部署條件,同時需要處理罕見的工作量高峰,我們的機器是異構的,并且我們從service jobs回收的資源中繼續run batch job。因此,要評估我們的方案選擇,我們需要一個比“平均利用率”更復雜的指標,在經過了大量的實驗后,我們選擇了cell compaction:給定一個工作負載,given a workload,we found out how small a cell it could be fitted into by removing machines until the workload no longer fitted, re-peatedly re-packing the workload from scratch to ensure thatwe didn’t get hung up on an unlucky configuration. This provided clean termination conditions and facilitated auto-mated comparisons without the pitfalls of synthetic work-load generation and modeling . A quantitative compari-son of evaluation techniques can be found in \[78\]: the detailsare surprisingly subtle.
不可能在實際的生產環境中做這些測試,但是我們使用Fauxmaster來高保真的模擬結果,采用從實際生產環境的cell與工作負載,同時包括他們的限制性條件,實際限制,reservations,以及使用數據,該數據來自PDT 2014年10月11日星期三獲取的Borg Checkpoint。我們首先淘汰了專用,測試和小型(<5000臺計算機)單元,從而選擇了15個Borg單元進行報告,然后對剩余的總體進行抽樣,以實現在大小范圍內的平均分布。為了保持compacted cell的機器異質性,我們隨機選擇要移除的機器。為了維持工作負載的heterogeneity。我們保留了全部,除了與特定計算機綁定的服務器和存儲任務外。那些超過cell數量一半大的job,我們將硬約束改為條件改為了軟約束條件。如果job非常“挑剔”且只能放置在少數機器上,則允許最多0.2%的任務處于pending狀態,廣泛的是試驗之后表明這樣會產生低變動性的重復結果;if we needed a larger cell than the original we cloned the orig-inal cell a few times before compaction; if we needed morecells, we just cloned the original。
### 5.2 Cell sharing
:-: 幾乎我們所有的機器都同時運行prod和non-prod任務,98%的機器是共享Brog cell的,Borg管理了整個集合的83%的機器,剩下一些為專用單元特殊用途,因為許多其他的組織在分離的集群中運行user-facing 和batch jobs,我們研究了同時做這些事情會發生時什么。圖五展示了在mdeian cell中分離prod與non-prod的工作將會需要20%-30%的額外機器去負載,這是因為prod jobs通常保留資源為了處理少見的負載峰值。但大多數時間這些資源又是沒有使用的,Borg回收了未使用的資源(第5.5節)來運行大部分非產品,因此我們總體上需要的機器更少。大多數的Brog cell由成千上萬的用戶共享,圖6展示了為什么,對于這個測試,如果用戶消耗了至少10 TiB的內存(或100 TiB),我們會將用戶的工作負載劃分到一個新的單元中。我們現有的政策看起來不錯:即使閾值較大,我們也需要2-16倍的cell,和20–150%的額外機器。再一次表明,合并資源可大大降低成本。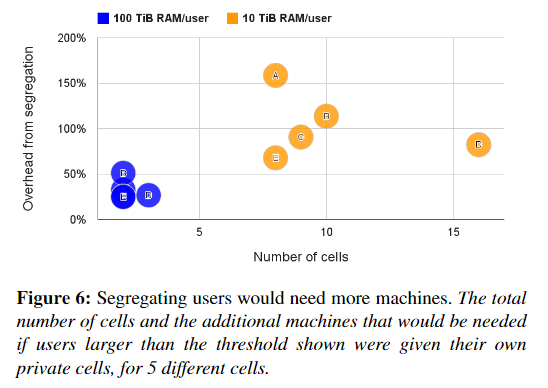
但是也許將不相關的用戶和作業類型打包到同一臺計算機上會導致CPU干擾,因此我們將需要更多的機器來補償,為了對此進行評估,我們研究了在相同環境下以相同時鐘速度運行的不同環境中的任務的CPI(每條指令的周期數)如何變化。在這些條件下,CPI的值擁有可比性,and can be used as a proxy for performance interference(可以被作為性能被干擾的指標?),因為將CPI加倍會使CPU綁定程序的運行時間加倍。這些數據為在一周內從大約12000個隨機的pod任務中收集。使用以下所述的硬件配置基礎結構,在5分鐘的間隔內對周期和指令進行計數,并加權樣本,以便對CPU時間的每一秒進行平均計數。結果并不明確。
(此處粗省略一大段不會的論證資料;<)
這些實驗證實,在倉庫規模上進行性能比較是棘手的,這增強了\[51\]中的觀點,并且還表明共享并不會顯著增加運行程序的成本。
但是即使假設我們的結果是最不利的,共享仍然是一種制勝法寶:he CPU slowdown is outweighed by thedecrease in machines required over several different parti-tioning schemes,(在幾種不同的分區方案下,所需的機器數量減少,而CPU的速度降低卻無法彌補,),并且共享優勢應用到了所有資源,包括內存和磁盤,而不僅僅是CPU。
5.3 Large cells
Google建立了大型cell,并且允許運行大型計算,并減少資源分散,We testedthe effects of the latter by partitioning the workload for a cellacross multiple smaller cells – by first randomly permutingthe jobs and then assigning them in a round-robin manneramong the partitions.(機翻:我們通過跨多個較小的單元劃分一個單元的工作負載來測試后者的效果-首先隨機排列作業,然后以循環方式在分區之間分配它們。)圖7證實使用較小的cell將需要更多的計算機。
:-: 
### 5.4 Fine-grained resource requests
Borg用戶要求以毫核心為單位的CPU,和內存以及磁盤空間(以字節為單位),一個核心是處理器超線程,針對各種機器類型的性能進行了標準化。圖8顯示了他們利用了這種粒度:請求的內存或CPU核心數量有少數明顯的“最佳點”,這些資源之間幾乎沒有明顯的相關性。這些分布與\[68\]中的分布非常相似,除了我們看到90%以上的內存請求稍微大一些.
提供一組固定大小的容器或虛擬機,盡管在IaaS(基礎設施即服務)提供商中很常見(待完成)
### 5.5 Resource reclamation
一個job可以指定一個資源限制,每個人物可以被授予的資源上限,這個限制被Borg用來確定用戶是否有足夠的配額來接受這份工作,同時決定,如果一個特殊的機器有足夠的空閑資源去安排任務,就像有些用戶購買的配額超出了他們的需求一樣,這些用戶請求的比他們任務使用的要少,因為Borg通常會終止試圖使用比其請求更多的RAM或磁盤空間的任務,or throttle CPU to what itasked for.此外,某些任務有時需要使用所有資源(在一天中的高峰時段或在應對拒絕服務攻擊時),但大多數時候都不是這樣。
與其浪費當前沒有被消耗的分配資源,我們估算一個任務會使用多少資源同時回收剩余的資源
用來運行低質量的任務,例如批處理作業,這整個過程稱為資源回收。這種估算稱為任務的保留(task‘s reservation),由Borg-master幾秒鐘計算一次。使用Borglet捕獲的細粒度(資源消耗)信息。初始reservation被設置為等于資源請求(the limit);在300秒之后。考慮到啟動瞬態
to allow for startup transients, it decays slowly towards the actual usage plus a safety margin. The reserva-tion is rapidly increased if the usage exceeds it.
Borg調度器使用Limit去計算prod 任務的可行性,因此他們從不依賴回收資源,也不會面臨資源超額訂購的情況,對于non-prod任務,他使用已有任務的reservation因此新任務可以調度到回收資源上。
如果對于reservation的預測錯誤的話,一臺機器在運行時可能會用盡資源,即使所有任務的使用小于限制,如果這種情況發生,我們選擇kill或者限制non-prod任務,但從來不是pods。
圖10顯示,如果沒有資源回收,將需要更多的機器。在median cell中,大約有20%的工作負載run在回收資源中。
我們可以在圖11中看到更多的細節,它顯示了預訂和使用限制的關系。如果需要資源,超過內存限制的任務將首先被搶占,而不管它的優先級如何,因此任務很少超過它們的內存限制。另一方面,CPU可以很容易地被調節,所以短期的峰值可以將使用推高到保留水平,這是無害的。
圖11表明資源回收可能過于保守:在reservation跟usage line之間有明顯的區域。為了測試這個,為了測試這個,我們選擇了一個生產環境的cell并且調整了資源估計算法的參數到一個更為激進的設置,通過減少安全邊際來維持了一周,而后另一周調整到一個中等設置介于baseline與激進設置之間。最后又條件回到baseline。圖13展示了發生可什么,在第二個week里面reservations非常接近于usage。而在第三周則有所減少,最大的差距顯示在baseline周里面,1st與4st,正如預期的那樣,內存不足(OOM)事件的發生率在第2周和第3周略有增加。在審查了這些結果之后,我們認為凈收益超過了不利因素。并部署了medium資源回收參數到其他cell。
:-: 
##
6.Isolation
我們有50%的計算機運行9個或更多任務;一臺90%的機器大約有25個任務,將運行約4500個線程\[83\]。盡管在應用程序之間共享計算機可以提高利用率,但是它也需要良好的機制來防止任務之間的相互干擾。這影響到安全性和性能。
6.1 Security isolation
我們使用Linux chroot jail作為同一臺計算機上多個任務之間的主要安全隔離機制。為了允許進行遠程調試,我們曾經自動分發(和撤消)sshkey,以使用戶只能在機器正在為用戶運行任務時訪問它。對于大多數用戶而言,它已被borgssh命令所取代,該命令與Borglet協作以構建與該任務在同一chroot和cgroup中運行的shell的ssh連接,從而更緊密地鎖定訪問。
通過google的Google’s AppEngin與Google Compute Engine (GCE).采用VM與安全沙箱技術來運行外部軟件。在一個KVM進程當中我們運行每一個宿主VM,這被作為Borg task來運行。
6.2 Performance isolation
Borglet的早期版本具有相對原始的資源隔離實施:對內存,磁盤空間和CPU周期進行事后使用檢查,再加上終止使用過多內存或磁盤的任務,以及積極使用Linux的CPU優先級來遏制過分使用很多CPU。但是,流氓任務仍然很容易影響計算機上其他任務的性能,因此某些用戶夸大了他們的資源請求,以減少Borg可以與他們共同調度的任務數量,從而降低了利用率。資源回收可以收回部分盈余,但由于涉及安全邊際,因此不能全部收回。在最極端的情況下,用戶請愿使用專用機器或單元.
現如今,所有的Borg任務都運行在一個Linux cgropu-based 資源容器上,Borglet操作容器設置,由于操作系統內核在循環中,所以提供了更好的控制,即使如此,偶爾還是會發生低級資源干擾(例如,內存帶寬或L3緩存污染),如\[60,83\]。
為了解決超負荷以及過度使用的問題,Brog任務有一個應用class or appclass,appclasses與其他的最重要的區別是延遲敏感性,在這偏文章中我們把它叫做batch,LS任務用于需要快速響應請求的面向用戶的應用程序和共享基礎結構服務。高優先級LS任務會受到最高的待遇。并有能力餓死bach任務幾秒鐘。第二個分離是在資源的可壓縮上,(例如,CPU周期,磁盤I / O帶寬)這些都是基于速率的可以通過降低服務質量回收而不會kill掉。不可壓縮資源(例如內存,磁盤空間),這些資源除通常不能回收除非kill掉任務。如果一臺機器耗盡了不可壓縮資源,Borglet將會迅速的終止任務,從最低優先級到最高優先級,直到剩下的reservation可以滿足為止,如果機器耗盡了可壓縮資源,Borg將會限制用量(多數在LS任務上)以便于處理負載峰值而不用kill掉任何任務。如果事情沒有好轉,Borgmaster 將會從機器中移除一個或更多的任務。
Borglet中的用戶空間控制循環根據預測的未來使用(for prod task)或內存壓力(for non-prod ones)將內存分配給容器,處理來自內核的內存不足實踐,同時當他們嘗試分配超過他們自身的內存限制時,kill掉。或者當一臺機器over-committed(過度承諾)但實際上卻已經耗盡了內存,由于需要精確的內存計算,Linux迫切需要的文件緩存極大地復雜了這個實現。
為了提高性能隔離,延遲敏感類任務可以保留整個物理CPU核心,這將會停止其他延遲敏感性任務使用。Batcg 類任務允許在任何一個核心上運行。但是,相對于延遲敏感型任務,他們被賦予了更小的調度程序份額。Borglet動態的調整延遲敏感型資源去確保他們在數分鐘內不會使batch 任務挨餓。在需要時選擇性的應用CFS帶寬控制。共享是不足夠的,因為我們有多個優先級級別。
像Leverich一樣,我們發現標準化的Linux CPU 調度(CFS)需要大量調整以同時支持低延遲與高利用率。為了減少調度延遲,我們的CFS版本使用采用per-cgropu加載記錄,允許延遲敏感性任務搶占batch任務。當多個LS任務在CPU上運行時,減少調度量。幸運的是,我們的許多應用程序采用thread-per-request模型。減輕了持續負載不平衡的影響。我們很少使用CPUset將CPU內核分配給延遲要求特別嚴格的應用程序。圖13顯示了這些結果的效果。在這方面的工作還在繼續,添加線程放置和CPU管理,即NUMA,超線程和功耗感知,并提高Borglet的控制精度。
任務被設置為允許消耗達到最大限值。他們中的大多數都被允許超越諸如CPU之類的可壓縮資源。為了利用未使用的閑置資源。大概只有5%的LS任務禁用了此功能,大概是為了獲得更好的可預測性。不到批處理任務的1%。默認情況下是禁用閑置資源的。因為它增加了任務被kill掉的概率。但即使如此,10%的LS任務重寫了這個,以及79%的batch任務這樣做了,因為這是一個mapreduce框架的默認設置。這補充了回收資源的結果(§5.5)。batch 任務愿意使用未被使用的以及回收的資源機會。在大多數情況下,這是可行的,盡管當LS任務急需資源時,偶爾的批處理任務會被犧牲掉。
1. Related work
資源調度已經研究了數十年,涉及范圍廣泛,例如廣域HPC超級計算網格,工作站網絡和大型服務器集群。在此,我們僅關注大型服務器集群中最相關的工作。
最近的幾項研究追蹤了來自yahoo,Google,facebook的集群。并說明了這些現代數據中心和工作負載固有的規模和異構性挑戰。包含集群管理器架構的分類。
Facebook的Tupperware \[64\]是一種類似于Borg的系統,用于在群集上調度cgroup容器;盡管似乎提供了資源回收的一種形式,但僅公開了一些細節。 Twitter開源了aurora \[5\],這是一種類似于Borg的調度程序,用于在Mesos之上運行的長期運行的服務,其配置語言和狀態機類似于Borg。
Apache Mesos 使用基于報價的機制在中央資源管理器(類似于Borgmaster減去其調度程序)和諸如Hadoop \[41\]和Spark \[73\]的多個“框架”之間劃分資源管理和放置功能。(不得不感嘆,google的翻譯太強了。。)Borg主要使用一種可伸縮的基于請求的機制來集中這些功能。DRF最初是為了Mesos開發的。Borg使用優先級與權限配額。Mesos開發者已經宣布擴展Mesos的雄心,去包括推測性資源分配與回收。以及修理一些已知的問題。
YARN是一個hadoop-centric集群管理器,每一個應用有一個manager,負責與中心資源管理器協商所需的資源。這跟google的map reduce jobs從Borg獲取資源很類似。YARN的資源管理最近變得。。。。。YARN最近被擴展去支持多種資源類型,搶占,和高級任務控制,The Tetris research prototype \[40\] supports makespan-awarejob packin。
facebook的Tupperware,是一個類Borg系統,用于在cluster上調度cgroup容器,僅僅只有少數的細節披露了,盡管他似乎提供了資源回收的一種形式,twtter開源了Aurora,一個運行在Mesos上的用來長時間運行services的類Borg調度器。跟Borg的聲明式語言與機器狀態類似。
微軟的Autopilot系統提供自動配置軟件與部署。系統監測,并且采用修復措施去處理軟硬件錯誤。Borg同時提供了相似的功能,但這里不進行討論,Isaard指明了我們所遵循的最佳路線。
阿里巴巴的Fuxi \[84\]支持數據分析工作負載;自2009年以來一直在運行。像Borgmaster一樣,中央FuxiMaster(為容錯而復制)從節點收集資源可用性信息,接受來自應用程序的請求并進行匹配一個到另一個。 Fuxi增量計劃策略與Borg的等價類相反:Fuxi不會將每個任務匹配到一組合適的機器上,而是將新可用資源與待處理工作的積壓進行匹配。與Mesos一樣,Fuxi允許定義“虛擬資源”類型。只有合成工作負載結果可公開獲得
Google的開源Kubernetes系統\[53\]將Docker容器\[28\]中的應用程序放置在多個主機節點上。它既可以在裸機(如Borg)上運行,也可以在各種云托管服務提供商(如Google Compute Engine)上運行,許多構建Borg的工程師都在積極開發中。 Google提供了一個托管版本,稱為Google Container Engine \[39\]。下一節我們將討論如何將來自Borg的課程應用于Kubernetes
最后,正如我們已經指出的那樣,管理大型集群的另一個重要部分是自動化和“操作員橫向擴展”。 \[43\]描述了如何計劃故障,多租戶,運行狀況檢查,準入控制和重啟能力,以實現大量的機器操作員。博格(Borg)的設計理念是相似的,它使我們能夠為每個操作員(SRE)提供數萬臺機器。
## 8\. Lessons and future work
在本節中,我們將回顧從運營Borg到生產中十多年中獲得的一些定性教訓,并描述如何在設計Kubernetes時利用這些觀察結果。
8.1 Lessons learned: the bad
我們從Borg的一些經驗開始,病態kubernetes中提供了替代的設置。
作業作為任務的唯一分組機制是有限制性的。Borg沒有一流的方法來將一個完整的多job service作為一個單獨的實體來管理,或者將一個服務的相關實例(例如canary和生產軌跡)加以引用。作為hack,用戶將其服務拓撲編碼在作業名稱中,并構建更高級別的管理工具來解析這些名稱。在另一端,另一方面,不可能指代工作的任意子集,這會導致諸如滾動更新和調整工作大小的語義不靈活等問題。
為了避免此類困難,Kubernetes拒絕任務指示,而是使用標簽(用戶可以將其附加到系統中的任何對象)來組織其調度單位(pod)。可以通過將job:jobname,label附加到一組pod上來完成相當于Borg作業的任務,但是也可以表示任何其他有用的分組,例如服務,層或發布類型(例如,生產,標記,測試) 。 Kubernetes中的操作通過標簽查詢的方式來確定其目標,該標簽查詢選擇操作應應用于的對象。這種方法比作業的單個固定分組具有更大的靈活性。
每臺機器一個IP地址會使事情變得復雜。在InBorg中,計算機上的所有任務都使用其主機的單個IP地址,從而共享主機的端口空間。這帶來了許多困難:Borg必須安排端口作為資源;任務必須預先聲明它們需要多少個端口,并愿意在啟動時被告知要使用哪些端口; Borglet必須強制執行端口隔離;并且命名和RPC系統必須處理端口以及IP地址。
由于Linux名稱空間,VM,IPv6和軟件定義的網絡的出現,Kubernetes可以采用更加用戶友好的方法來消除這些復雜性:每個pod和服務都有其自己的IP地址,從而使開發人員可以選擇端口而不是要求它們的軟件可以適應基礎架構選擇的軟件,并消除了管理端口的基礎架構復雜性。
以犧牲普通用戶為代價優化高級用戶。Borg提供了一套針對“超級用戶”的功能,這樣他們就可以微調他們程序的運行方式(BCL規范列出了大約230個參數):最主要的關注點是支持谷歌最大的資源消費者,對他們來說效率提高是最重要的。這個API的豐富性使“隨意”用戶的工作變得更加困難,并且限制了它的發展。我們的解決方案是構建自動化工具和服務,運行在Borg之上,并從實驗中確定適當的設置。這些得益于容錯應用程序所提供的實驗自由:如果自動化造成錯誤,那將是令人討厭的,而不是災難。
## 8.2 Lessons learned: the good
另一方面,Borg的許多設計功能非常有益,并且經受了時間的考驗。
\*\*Allocs很有用。\*\*Borg alloc抽象產生了廣泛使用的logaver模式(第2.4節),而另一個流行的模式是簡單的數據加載器任務定期更新Web服務器使用的數據。 Alloc和軟件包允許由單獨的團隊開發許多幫助服務。Kubernete的pod相當于alloc(分配器),它是一個或多個容器的封裝源,這些容器總是安排在同一臺機器上并且可以共享資源。Kubernetes在同一容器中使用輔助容器而不是在alloc 中的任務,但是想法是相同的。
\*\*集群管理不僅僅是任務管理。\*\*盡管博格的主要職責是管理任務和機器的生命周期,但運行在博格上的應用程序可以從許多其他集群服務中受益,包括命名和負載平衡。 Kubernetes使用service抽象支持命名和負載平衡:service具有名稱和由標簽選擇器定義的動態Pod集。群集中的任何容器都可以使用服務名稱連接到服務。在幕后,Kubernetes會在與標簽選擇器匹配的Pod之間自動對服務的連接進行負載平衡,并跟蹤Pod在哪里運行,并為它們隨著時間故障而重新安排。
\*\*自我檢查至關重要,\*\*盡管Borg幾乎總是“工作正常”,但是當出現問題時,找到根本原因可能是具有挑戰性的。在Borg中,一項重要的設計決策是向所有用戶公開調試信息,而不是將其隱藏。
Borg有成千上萬的用戶,因此“自助”已成為調試的第一步。盡管這使我們更難以棄用功能并更改用戶所依賴的內部政策,但這仍然是一個勝利,并且我們沒有找到現實的選擇。為了處理大量數據,我們提供了多個級別的UI和調試工具,因此用戶可以快速識別與其工作相關的異常事件,然后從其應用程序和基礎結構本身中深入查看詳細的事件和錯誤日志。
Kubernetes旨在復制許多Borg的自檢技術。例如,它附帶了諸如cAdvisor \[15\]之類的工具,用于資源監視以及基于Elasticsearch / Kibana \[30\]和Fluentd \[32\]的日志聚合。可以查詢master以獲取其對象狀態的快照。Kubernetes具有統一的機制,所有組件都可以使用該機制來記錄可供客戶端使用的事件(例如,已調度的Pod,容器失敗)。
**master是分布式系統的內核。**
Borgmaster最初是作為一個整體系統設計的,但隨著時間的流逝,它逐漸成為位于服務生態系統中以管理用戶工作的核心。我們將調度程序和主UI(Sigma)分離為單獨的過程,并添加了用于接納控制,垂直和水平自動縮放,重新打包任務,定期作業提交(cron),工作流管理以及離線歸檔系統操作的服務查詢。總之,這些使我們能夠在不犧牲性能或可維護性的情況下擴大工作量和功能集。
kubernetes的架構走得更遠,它的核心是一個API server,它僅負責處理請求和處理基礎狀態對象。集群管理邏輯是構建為小型的、復合的微服務,它們是這個API服務器的客戶端,比如在出現故障時維護所需的pod副本數量的復制控制器,以及管理機器生命周期的node controller。
8.3 Conclusion
在過去十年,幾乎所有的google集群負載都已經切換到了Borg,并且我們仍在持續的更新它,并且他我們所學到的應用到kubernetes上。
結語:現在看來,kubernetes真是一個吸取了諸多經驗與一流設計的集群操作系統啊!
- 文章翻譯
- Large-scale cluster management at Google with Borg
- Borg Omega and kubernetes
- scaling kubernetes to 7500 nodes
- bpf 的過去,未來與現在
- Demystifying Istio Circuit Breaking
- 知識圖譜
- skill level up graph
- 一、運維常用技能
- 1.0 Vim (編輯器)
- 1.1 Nginx & Tengine(Web服務)
- 基礎
- 1.2 zabbix
- 定義
- 登錄和配置用戶
- 1.3 RabbitMQ(消息隊列)
- 原理
- RabbitMQ(安裝)
- 1.4虛擬化技術
- KVM
- 1.5 Tomcat(Web中間件)
- 1.6Jenkins
- pipline
- 1.7 Docker
- network
- 1.8 Keepalived(負載均衡高可用)
- 1.9 Memcache(分布式緩存)
- 1.10 Zookeeper(分布式協調系統)
- 1.11 GitLab(版本控制)
- 1.12 Jenkins(運維自動化)
- 1.13 WAF(Web防火墻)
- 1.14 HAproxy負載均衡
- 1.15 NFS(文件傳輸)
- 1.16 Vim(編輯器)
- 1.17 Cobbler(自動化部署)
- 二、常用數據庫
- 2.1 MySQL(關系型數據庫)
- mysql主從復制
- 2.2 Mongodb(數據分析)
- 2.3 Redis(非關系數據庫)
- 三、自動化運維工具
- 3.1 Cobbler(系統自動化部署)
- 3.2 Ansible(自動化部署)
- 3.3 Puppet(自動化部署)
- 3.4 SaltStack(自動化運維)
- 四、存儲
- 4.1 GFS(文件型存儲)
- 4.2 Ceph(后端存儲)
- 五、運維監控工具
- 5.1 云鏡
- 5.2 ELK
- 六、運維云平臺
- 6.1 Kubernetes
- 6.2 OpenStack
- 介紹
- 安裝
- 七、Devops運維
- 7.1 理念
- 7.2 Devops運維實戰
- 八、編程語言
- 8.1 Shell
- 書籍《Wicked Cool Shell Scripts》
- 8.2 Python
- 8.3 C
- 8.4 Java
- leecode算法與數據結構
- 九、雜記
- 高優先級技能
- 知識點
- JD搜集
- 明顯的短板
- 1.0 Python
- 1.1 Kubernetes
- 1.18.2 《kubernetes in action》
- 遺漏知識點
- 1.18.3 GCP、azure、aliyun
- Azure文檔
- 1.18.5 《program with kubernetes》
- Istio
- HELM
- 《Kubernetes best practice》
- Kubernetes源碼學習
- Scheduler源碼
- 調度器入口
- 調度器框架
- Node篩選算法
- Node優先級算法
- pod搶占調度
- 入口
- 主要代碼結構
- new
- 文章翻譯
- Flannel
- 從二進制集群搭建
- 信息收集
- docker優化
- 1.2 shell
- 面試題
- grep awk sed 常見用法
- shell實踐
- 1.3 Data structure(數據結構)
- Calico
- Aliyun文檔以及重點模塊
- git
- 大數據組件
- 前端,后端,web框架
- cgroup,namespace
- 內核
- Linux搜集
- crontab
- centos7常用優化配置
- centos Mariadb
- eBPF
- ebpf的前世今生
- Linux性能問題排查與分析
- 性能分析搜集
- 性能分析常用10條
- 網絡性能優化
- 文本處理命令
- sql
- Iptables
- python面試題
- iptables
- iptables詳細
- zabbix面試題,proj
- prometheus
- web中間件
- nginx
- Haproxy
- grep sed awk
- Linux常用命令
- 云平臺
- 書籍Linux應用技巧
- kafka
- kafka面試題
- ETCD
- Jenkins
- 3天補充的點
- K8s源碼
- K8s
- k8s實操
- etcd
- test
- BPF
- PSFTP使用
- StackOverflow問答精選
- 問題
- 我對于學習思考
- 修改ssh超時時間
- 課程目錄
- 運維與運維開發
- The Person
- 個人雜談
- mysql主從復制
- 對于工作的認識與思考