
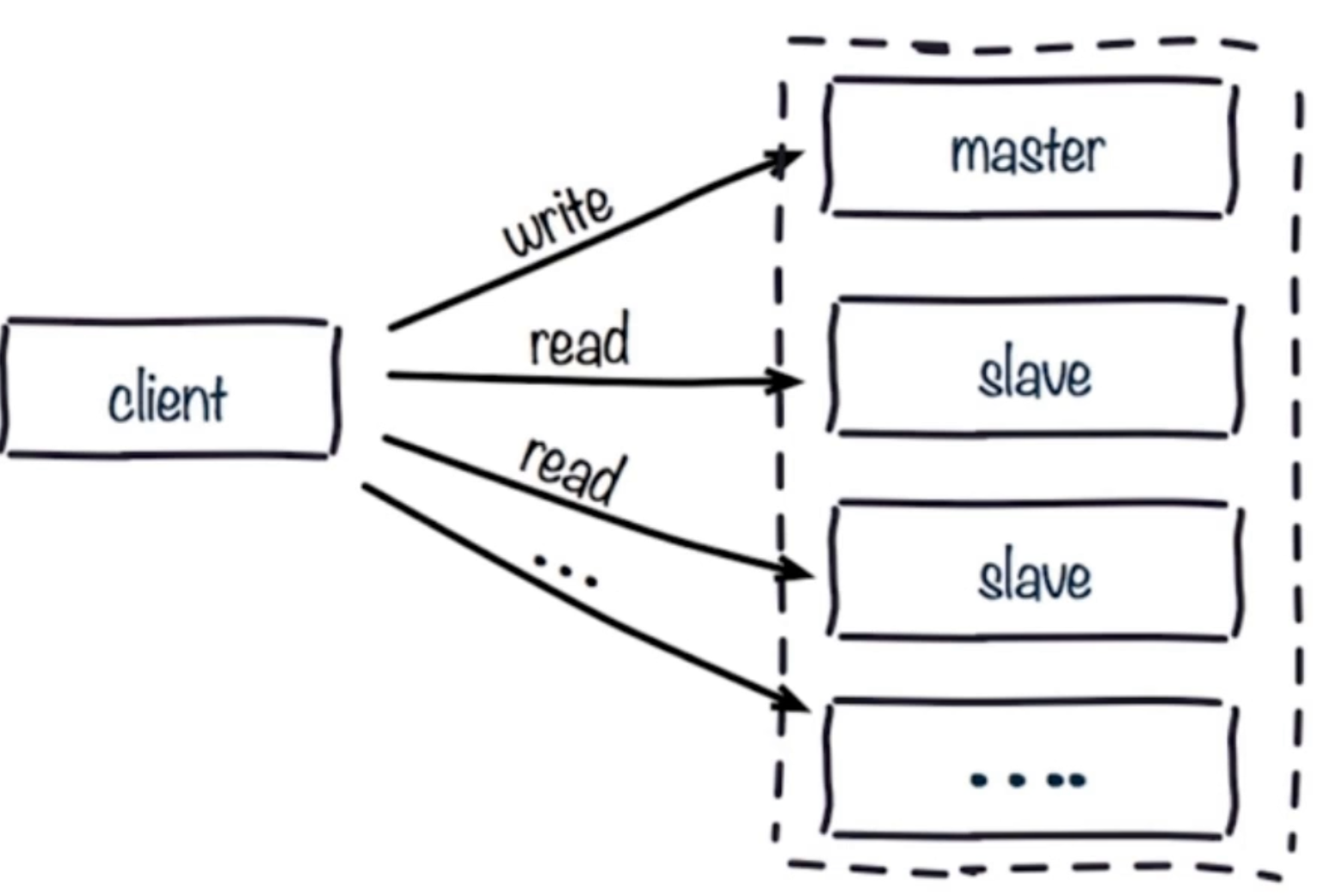
### 讀寫分離
讀流量分攤到從節點;
#### 可能遇到的問題
**1.數據復制的延遲**
讀寫分離時,master會異步的將數據復制到slave,如果這是slave發生阻塞,則會延遲master數據的寫命令,造成數據不一致的情況
解決方法:可以對slave的偏移量值進行監控,如果發現某臺slave的偏移量有問題,則將數據讀取操作切換到master,但本身這個監控開銷比較高,所以關于這個問題,大部分的情況是可以直接使用而不去考慮的。
**2.讀到過期的數據**
### 為什么從庫不刪除數據?
redis刪除過期數據有以下幾個策略:
1.惰性刪除:當讀/寫一個已經過期的key時,會觸發惰性刪除策略,直接刪除掉這個過期key,很明顯,這是被動的!
2.定期刪除:由于惰性刪除策略無法保證冷數據被及時刪掉,所以?redis?會定期主動淘汰一批已過期的key。(在第二節中會具體說明)
3.主動刪除:當前已用內存超過maxMemory限定時,觸發主動清理策略。主動設置的前提是設置了maxMemory的值
### 產生原因:
redis的從庫是無法主動的刪除已經過期的key的,所以如果做了讀寫分離,就很有可能在從庫讀到臟數據
讀寫分離時,master會異步的將數據復制到slave,如果這是slave發生阻塞,則會延遲master數據的寫命令,造成數據不一致的情況
解決方法:可以對slave的偏移量值進行監控,如果發現某臺slave的偏移量有問題,則將數據讀取操作切換到master,但本身這個監控開銷比較高,所以關于這個問題,大部分的情況是可以直接使用而不去考慮的。
### 主從配置不一致
1. maxmomory不一致:丟失數據;原因:例如master配置4G,slave配置2G,這個時候主從復制可以成功,但,如果在進行某一次全量復制的時候,slave拿到master的RDB加載數據時發現自身的2G內存不夠用,這時就會觸發slave的maxmemory策略,將數據進行淘汰。更可怕的是,在高可用的集群環境下,如果我們將這臺slave升級成master的時候,就會發現數據已經丟失了。
2. **數據結構優化參數不一致(例如hash-max-ziplist-entries):這個就會導致內存不一致** ;原因:例如在master上對這個參數進行了優化,而在slave沒有配置,就會造成主從節點內存不一致的詭異問題。
### 規避全量復制
首先,我們知道,redis復制有全量復制和部分復制兩種(這個我前面博客有寫到)而全量復制的開銷是很大的。那么我們來看看,如何盡量去規避全量復制。
**1.第一次全量復制**
當我們某一臺slave第一次去掛到master上時,是不可避免要進行一次全量復制的,那么,我們如何去想辦法降低開銷呢?
方案1:小主節點,例如我們把redis分成2G一個節點,這樣一來,會加速RDB的生成和同步,同時還可以降低我們fork子進程的開銷(master會fork一個子進程來生成同步需要的RDB文件,而fork是要拷貝內存快的,如果主節點內存太大,fork的開銷就大)。
方案2:既然第一次不可以避免,那我們可以選在集群低峰的時間(凌晨)進行slave的掛載。
**2.節點RunID不匹配**
例如我們主節點重啟(RunID發生變化),對于slave來說,它會保存之前master節點的RunID,如果它發現了此時master的RunID發生變化,那它會認為這是master過來的數據可能是不安全的,就會采取一次全量復制
**解決辦法**:對于這類問題,我們只有是做一些故障轉移的手段,例如master發生故障宕掉,我們選舉一臺slave晉升為master(哨兵或集群)
**3.復制積壓緩沖區不足**
我在全量復制與部分復制那篇文章提到過,master生成RDB同步到slave,slave加載RDB這段時間里,master的所有寫命令都會保存到一個復制緩沖隊列里(如果主從直接網絡抖動,進行部分復制也是走這個邏輯),待slave加載完RDB后,拿offset的值到這個隊列里判斷,如果在這個隊列中,則把這個隊列從offset到末尾全部同步過來,這個隊列的默認值為1M。而如果發現offset不在這個隊列,就會產生全量復制。
**解決辦法**:增大復制緩沖區的配置 rel\_backlog\_size 默認1M,我們可以設置大一些(10M),從而來加大我們offset的命中率。這個值,我們可以假設,一般我們網絡故障時間一般是分鐘級別,那我們可以根據我們當前的QPS來算一下每分鐘可以寫入多少字節,再乘以我們可能發生故障的分鐘就可以得到我們這個理想的值。
### 規避復制風暴
什么是復制風暴?舉例:我們master重啟,其master下的所有slave檢測到RunID發生變化,導致所有從節點向主節點做全量復制。盡管redis對這個問題做了優化,即只生成一份RDB文件,但需要多次傳輸,仍然開銷很大。
**1.單主節點復制風暴:主節點重啟,多從節點全量復制**
**解決:**更換復制拓撲如下圖:
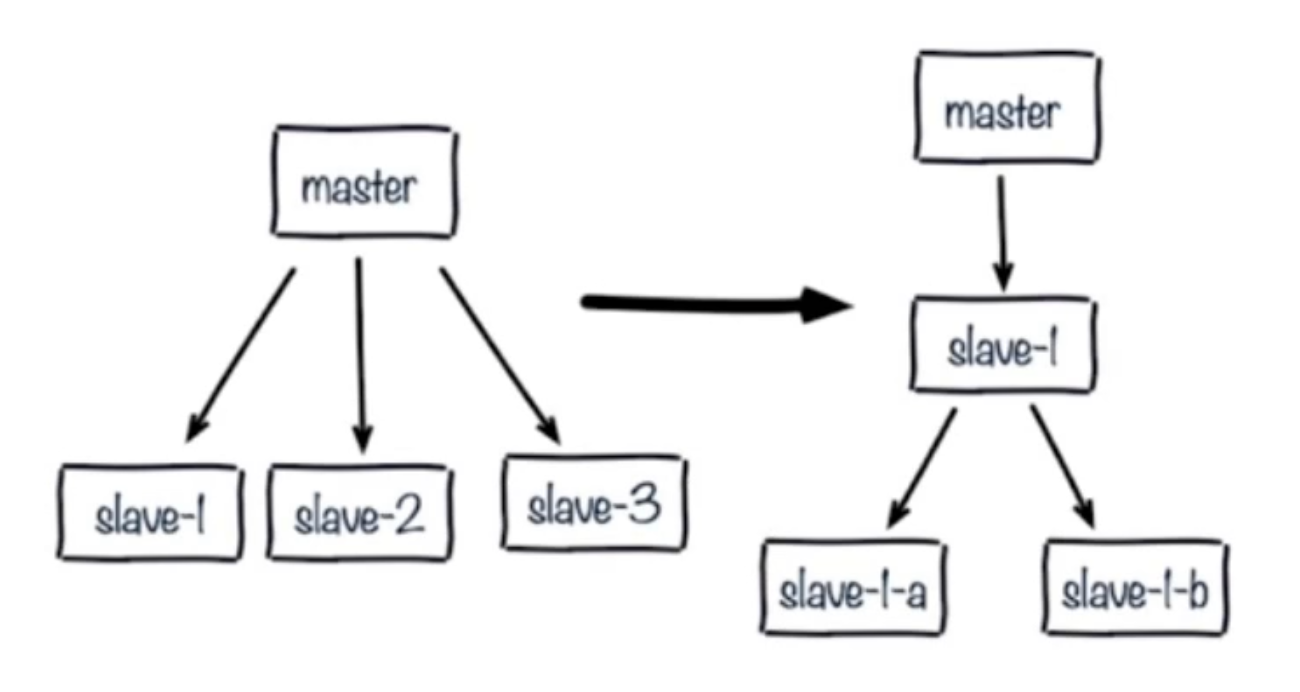
1.我們將原來master與slave中間加一個或多個slave,再在slave上加若干個slave,這樣可以分擔所有slave對master復制的壓力。(這種架構還是有問題:讀寫分離的時候,slave1也發生了故障,怎么去處理?)
2.如果只是實現高可用,而不做讀寫分離,那當master宕機,直接晉升一臺slave即可。
**2.單機器復制風暴:機器宕機后的大量全量復制,如下圖:**
當machine-A這個機器宕機重啟,會導致該機器所有master下的所有slave同時產生復制。(災難)
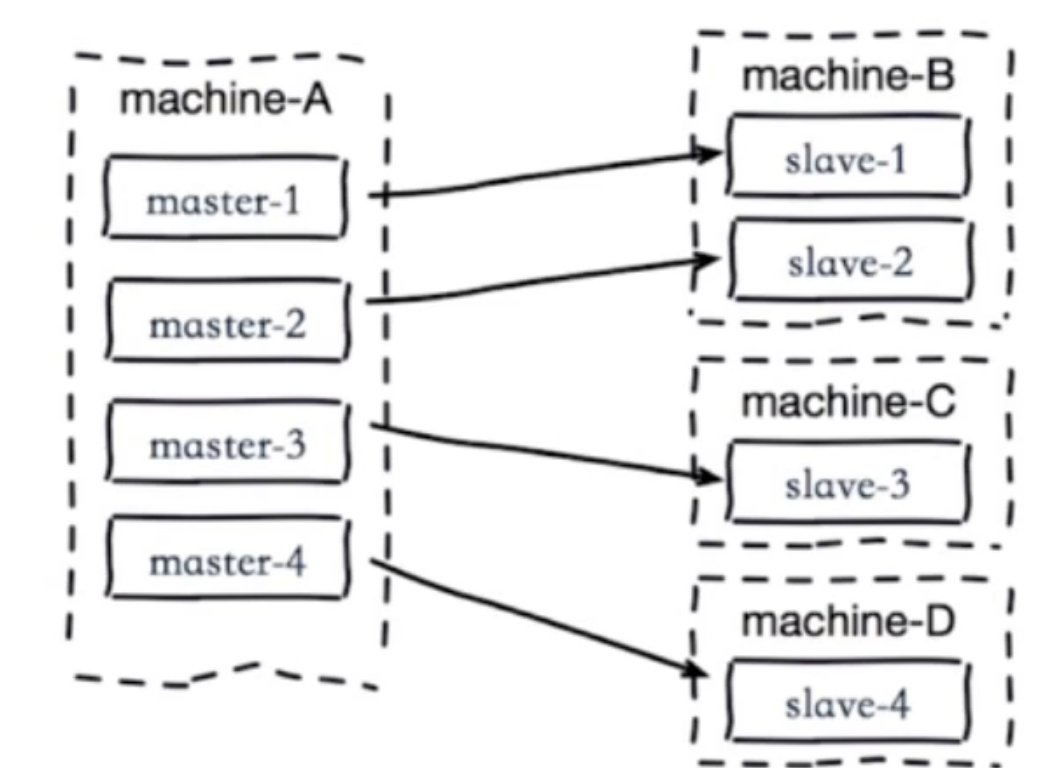
解決:
1.主節點分散多機器(將master分散到不同機器上部署)
2.還有我們可以采用高可用手段(slave晉升master)就不會有類似問題了。
- Redis簡介
- 簡介
- 典型應用場景
- Redis安裝
- 安裝
- redis可執行文件說明
- 三種啟動方法
- Redis常用配置
- API的使用和理解
- 通用命令
- 數據結構和內部編碼
- 單線程
- 數據類型
- 字符串
- 哈希
- 列表
- 集合
- 有序集合
- Redis常用功能
- 慢查詢
- Pipline
- 發布訂閱
- Bitmap
- Hyperloglog
- GEO
- 持久化機制
- 概述
- snapshotting快照方式持久化
- append only file追加方式持久化AOF
- RDB和AOF的抉擇
- 開發運維常見問題
- fork操作
- 子進程外開銷
- AOF追加阻塞
- 單機多實例部署
- Redis復制原理和優化
- 什么是主從復制
- 主從復制配置
- 全量復制和部分復制
- 故障處理
- 開發運維常見問題
- Sentinel
- 主從復制高可用
- 架構說明
- 安裝配置
- 客戶端連接
- 實現原理
- 常見開發運維問題
- 高可用讀寫分離
- 故障轉移client怎么知道新的master地址
- 總結
- Sluster
- 呼喚集群
- 數據分布
- 搭建集群
- 集群通信
- 集群擴容
- 集群縮容
- 客戶端路由
- 故障轉移
- 故障發現
- 故障恢復
- 開發運維常見問題
- 緩存設計與優化
- 緩存收益和成本
- 緩存更新策略
- 緩存粒度控制
- 緩存穿透優化
- 緩存雪崩優化
- 無底洞問題優化
- 熱點key重建優化
- 總結
- 布隆過濾器
- 引出布隆過濾器
- 布隆過濾器基本原理
- 布隆過濾器誤差率
- 本地布隆過濾器
- Redis布隆過濾器
- 分布式布隆過濾器
- 開發規范
- 內存管理
- 開發運維常見坑
- 實戰
- 對文章進行投票
- 數據庫的概念
- 啟動多實例