
## 為什么要做數據分布
* **分布式數據庫首先要解決把整個數據集按照分區規則映射到多個節點的問題,即把數據集劃分到多個節點上,每個節點負責整體數據的一個子集**。 如下圖所示:
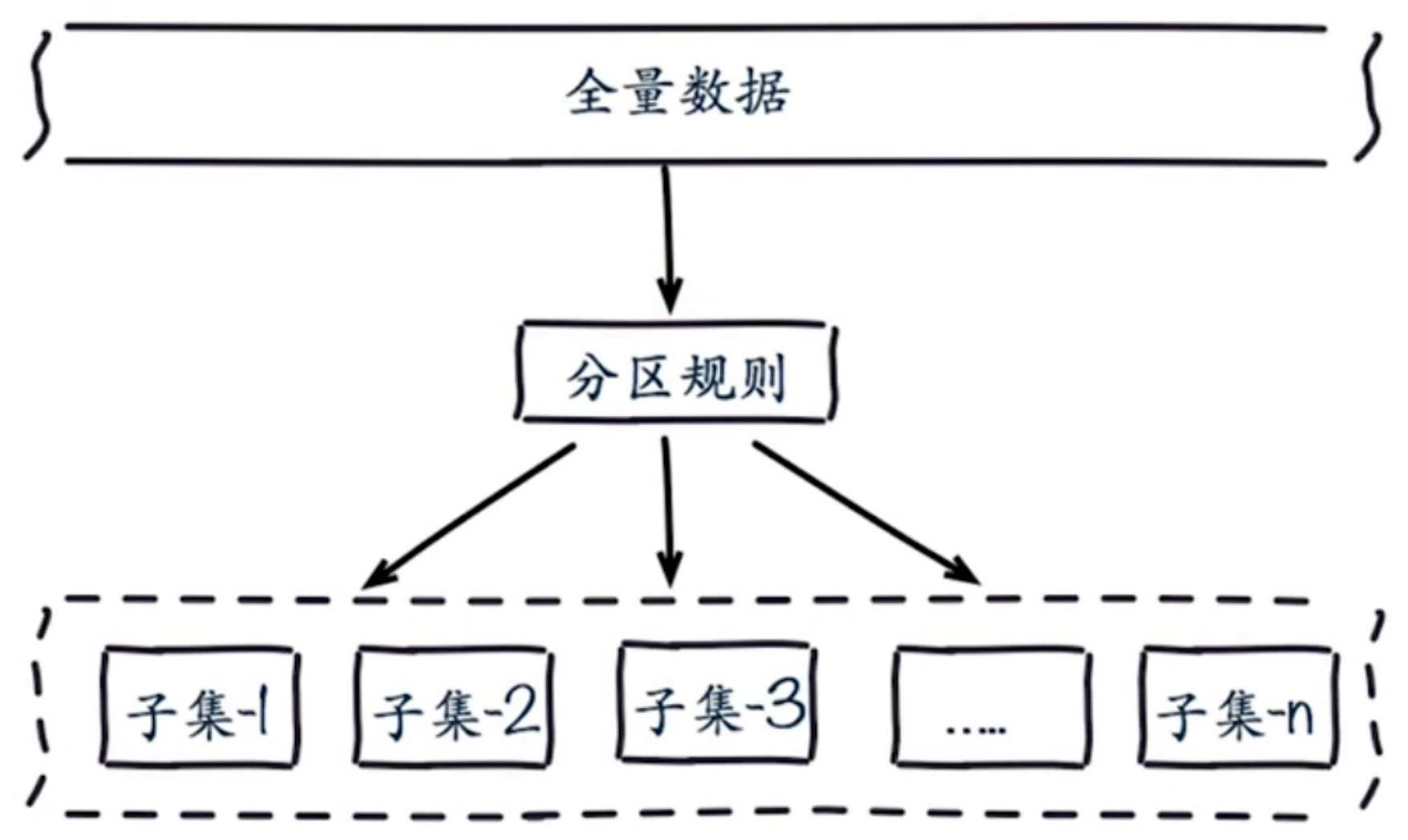
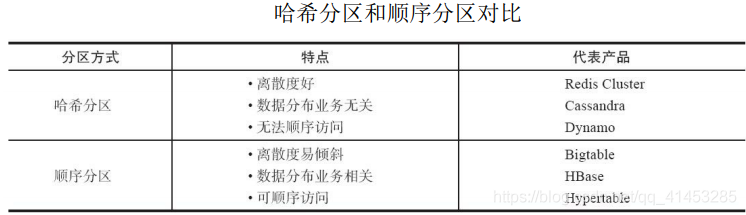
* **需要重點關注的是數據分區規則。**常見的分區規則有哈希分區和順序分區兩種,下圖對這兩種分區規則進行了對比:
## 哈希分布
1. 節點取余;
2. 一致性哈希分區;
3. 虛擬槽分區;
## 節點取余分區
* 使用特定的數據,如Redis的鍵或用戶ID,再根據節點數量N使用公式: hash(key)%N計算出哈希值,用來決定數據映射到哪一個節點上;
* 這種方案存在一個問題:當節點數量變化時,如擴容或收縮節點,數據節點映射關 系需要重新計算,會導致數據的重新遷移;
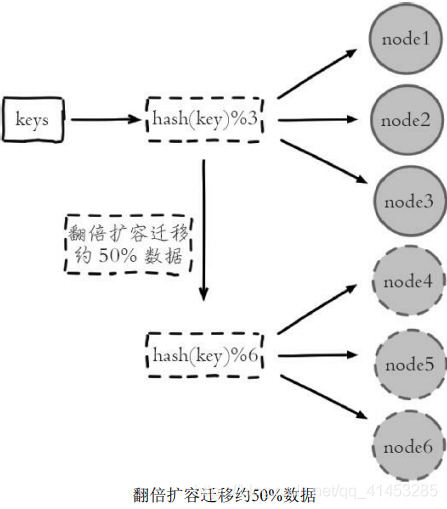
* 這種方式的突出優點是:簡單性,常用于數據庫的分庫分表規則,一般采用預分區的方式,提前根據數據量規劃好分區數,比如劃分為512或1024張表,保證可支撐未來一段時間的數據量,再根據負載情況將表遷移到其他數 據庫中。擴容時通常采用翻倍擴容,避免數據映射全部被打亂導致全量遷移的情況,如下圖所示;
## 一致性哈希
* 一致性哈希分區(Distributed Hash Table)實現思路是:為系統中每個節點分配一個token,范圍一般在0~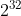,這些token構成一個哈希環。數據讀寫執行節點查找操作時,先根據key計算hash值,然后順時針找到第一個大于等于該哈希值的token節點,如下圖所示
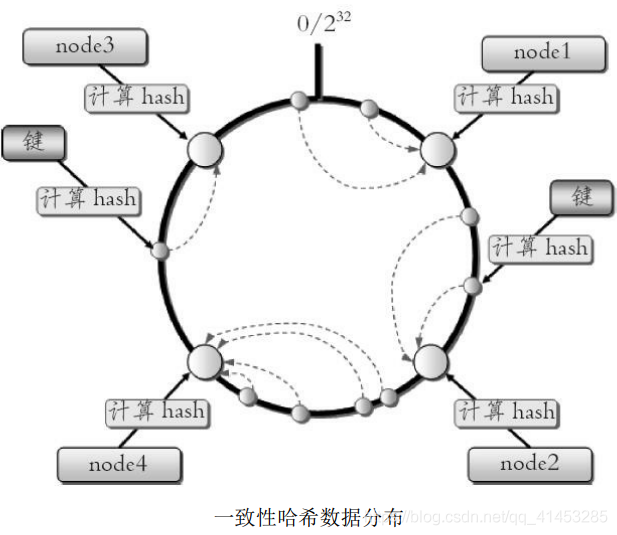
* **這種方式相比節點取余最大的好處在于**加入和刪除節點只影響哈希環中相鄰的節點,對其他節點無影響;
* **但一致性哈希分區存在幾個問題:**
* 加減節點會造成哈希環中部分數據無法命中(例如一個key增減節點前映射到第3個節點,因此它的數據是保存在第3個節點上的;當我們增加一個節點后被映射到第2個節點上了,此時我們去第2個節點上去找這個key對應的值是找不到的,見下圖),需要手動處理或者忽略這部分數據,因此一致性哈希常用于緩存場景
* 當使用少量節點時,節點變化將大范圍影響哈希環中數據映射,因此這種方式不適合少量數據節點的分布式方案
* 普通的一致性哈希分區在增減節點時需要**增加一倍或減去一半節點**才能保證數據和負載的均衡;
* 正因為一致性哈希分區的這些缺點,一些分布式系統采用虛擬槽對一致性哈希進行改造,比如Dynamo系統
## 虛擬槽分區
1. 預設虛擬槽:每個槽映射一個數據子集,一般比節點數大;
2. 良好的哈希函數:例如CRC16;
3. 服務端管理節點,槽,數據:例如Redis cluster;
*實現思路為:
* 虛擬槽分區巧妙地使用了哈希空間,使用分散度良好的哈希函數把所有數據映射到一個固定范圍的整數集合中,整數定義為槽(slot)。這個范圍 一般遠遠大于節點數,比如Redis Cluster槽范圍是0~16383
* 槽是集群內數據管理和遷移的基本單位。采用大范圍槽的主要目的是為了方便數據拆分和集群擴展。每個節點會負責一定數量的槽
* 如下圖所示:當前集群有5個節點,每個節點平均大約負責3276個槽
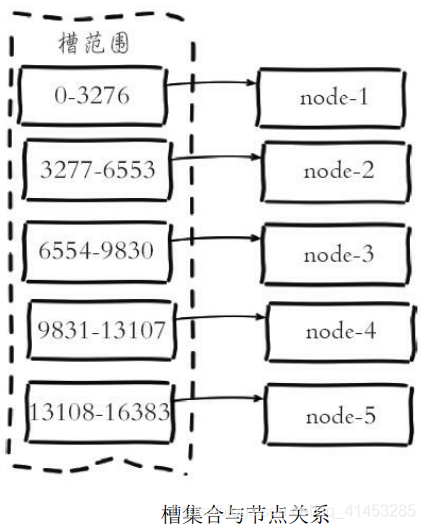
* 由于采用高質 量的哈希算法,每個槽所映射的數據通常比較均勻,將數據平均劃分到5個節點進行數據分區
* Redis Cluster就是采用虛擬槽分區,下面就介紹Redis數據分區方法
## Redis數據分區(槽分區)
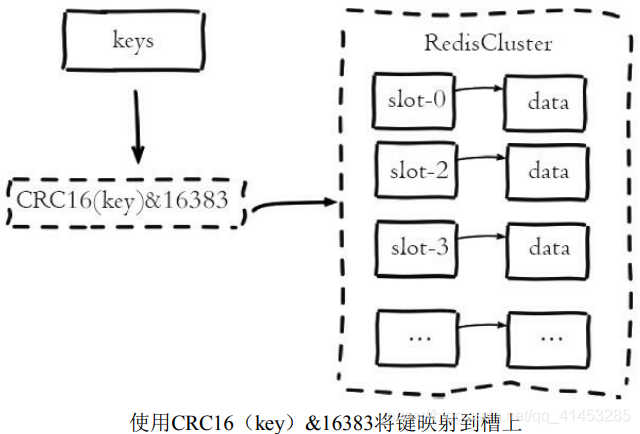
* **Redis Cluser采用虛擬槽分區,所有的鍵根據哈希函數映射到0~16383整數槽內,**計算公式:slot=CRC16(key)&16383。每一個節點負責維護一部分槽以及槽所映射的鍵值數據,如下圖所示
## 為什么是16384個槽位
`CRC16`算法產生的hash值有16bit,該算法可以產生2^16-=65536個值。換句話說,值是分布在0~65535之間。那作者在做`mod`運算的時候,為什么不`mod`65536,而選擇`mod`16384?
如果槽位為65536,發送心跳信息的消息頭達8k,發送的心跳包過于龐大。
如上所述,在消息頭中,最占空間的是`myslots[CLUSTER_SLOTS/8]`。
當槽位為65536時,這塊的大小是:
`65536÷8÷1024=8kb`
因為每秒鐘,redis節點需要發送一定數量的ping消息作為心跳包,如果槽位為65536,這個ping消息的消息頭太大了,浪費帶寬。
(2)redis的集群主節點數量基本不可能超過1000個。
如上所述,集群節點越多,心跳包的消息體內攜帶的數據越多。如果節點過1000個,也會導致網絡擁堵。因此redis作者,不建議redis cluster節點數量超過1000個。
那么,對于節點數在1000以內的redis cluster集群,16384個槽位夠用了。沒有必要拓展到65536個。
(3)槽位越小,節點少的情況下,壓縮比高
Redis主節點的配置信息中,它所負責的哈希槽是通過一張bitmap的形式來保存的,在傳輸過程中,會對bitmap進行壓縮,但是如果bitmap的填充率slots / N很高的話(N表示節點數),bitmap的壓縮率就很低。
如果節點數很少,而哈希槽數量很多的話,bitmap的壓縮率就很低。
* **Redis虛擬槽分區的特點:**
* 解耦數據和節點之間的關系,簡化了節點擴容和收縮難度
* 節點自身維護槽的映射關系,不需要客戶端或者代理服務維護槽分區 元數據
* 支持節點、槽、鍵之間的映射查詢,用于數據路由、在線伸縮等場景
* 數據分區是分布式存儲的核心,理解和靈活運用數據分區規則對于掌握 Redis Cluster非常有幫助
## Redis集群功能限制
**Redis集群相對單機在功能上存在一些限制,需要開發人員提前了解, 在使用時做好規避。限制如下:**
1)key批量操作支持有限。**如mset、mget,目前只支持具有相同slot值的 key執行批量操作。對于映射為不同slot值的key由于執行mget、mget等操作可 能存在于多個節點上因此不被支持
2)key事務操作支持有限。**同理只支持多key在同一節點上的事務操 作,當多個key分布在不同的節點上時無法使用事務功能
3)key作為數據分區的最小粒度,因此**不能將一個大的鍵值對象如 hash、list等映射到不同的節點**
4)不支持多數據庫空間。單機下的Redis可以支持16個數據庫,集群模 式下只能使用一個數據庫空間,即db0
5)復制結構只支持一層,從節點只能復制主節點,不支持嵌套樹狀復制結構
- Redis簡介
- 簡介
- 典型應用場景
- Redis安裝
- 安裝
- redis可執行文件說明
- 三種啟動方法
- Redis常用配置
- API的使用和理解
- 通用命令
- 數據結構和內部編碼
- 單線程
- 數據類型
- 字符串
- 哈希
- 列表
- 集合
- 有序集合
- Redis常用功能
- 慢查詢
- Pipline
- 發布訂閱
- Bitmap
- Hyperloglog
- GEO
- 持久化機制
- 概述
- snapshotting快照方式持久化
- append only file追加方式持久化AOF
- RDB和AOF的抉擇
- 開發運維常見問題
- fork操作
- 子進程外開銷
- AOF追加阻塞
- 單機多實例部署
- Redis復制原理和優化
- 什么是主從復制
- 主從復制配置
- 全量復制和部分復制
- 故障處理
- 開發運維常見問題
- Sentinel
- 主從復制高可用
- 架構說明
- 安裝配置
- 客戶端連接
- 實現原理
- 常見開發運維問題
- 高可用讀寫分離
- 故障轉移client怎么知道新的master地址
- 總結
- Sluster
- 呼喚集群
- 數據分布
- 搭建集群
- 集群通信
- 集群擴容
- 集群縮容
- 客戶端路由
- 故障轉移
- 故障發現
- 故障恢復
- 開發運維常見問題
- 緩存設計與優化
- 緩存收益和成本
- 緩存更新策略
- 緩存粒度控制
- 緩存穿透優化
- 緩存雪崩優化
- 無底洞問題優化
- 熱點key重建優化
- 總結
- 布隆過濾器
- 引出布隆過濾器
- 布隆過濾器基本原理
- 布隆過濾器誤差率
- 本地布隆過濾器
- Redis布隆過濾器
- 分布式布隆過濾器
- 開發規范
- 內存管理
- 開發運維常見坑
- 實戰
- 對文章進行投票
- 數據庫的概念
- 啟動多實例