
## 無底洞問題
* 2010年,Facebook的Memcache節點已經達到了3000個,承載著TB級別的緩存數據。但開發和運維人員發現了一個問題,為了滿足業務要求**添加了大量新Memcache節點,但是發現性能不但沒有好轉反而下降了**,當時將這 種現象稱為緩存的“無底洞”現象。
* 那么為什么會產生這種現象呢,通常來說添加節點使得Memcache集群性能應該更強了,但事實并非如此。鍵值數據庫由于通常采用哈希函數將 key映射到各個節點上,造成key的分布與業務無關,但是**由于數據量和訪問量的持續增長,造成需要添加大量節點做水平擴容,導致鍵值分布到更多的節點上**,所以無論是Memcache還是Redis的分布式,批量操作通常**需要從不同節點上獲取,相比于單機批量操作只涉及一次網絡操作,分布式批量操作會涉及多次網絡時間**
* 下圖展示了在分布式條件下,一次mget操作需要訪問多個Redis節點, 需要多次網絡時間
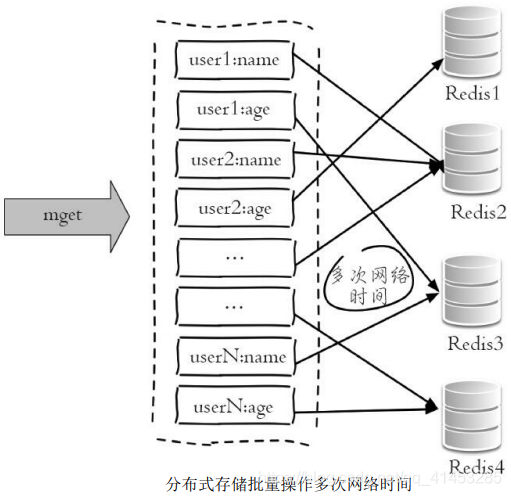
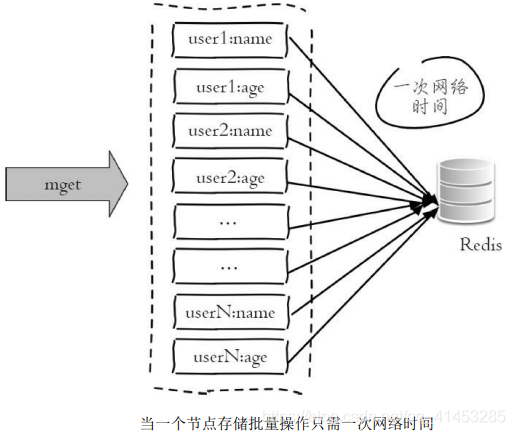
* 而下圖由于所有鍵值都集中在一個節點上,所以一次批量操作只需要 一次網絡時間
## 無底洞問題分析
* 客戶端一次批量操作會涉及多次網絡操作,也就意味著批量操作會隨 著節點的增多,耗時會不斷增大
* 網絡連接數變多,對節點的性能也有一定影響
* 用一句通俗的話總結就是,更多的節點不代表更高的性能,所謂“無底 洞”就是說投入越多不一定產出越多。但是分布式又是不可以避免的,因為 訪問量和數據量越來越大,一個節點根本抗不住,所以如何高效地在分布式緩存中批量操作是一個難點;
## 優化IO的幾種方法
1. 命令本身優化"例如慢查詢keys,hgetall ,bigkey;
2. 減少網絡通信次數;
3. 降低接入成本:例如客戶端長連接/連接池,NIO等;
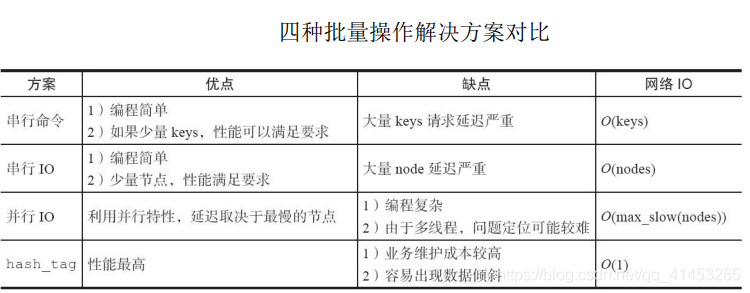
## 四種批量優化方法
https://blog.csdn.net/qq_41453285/article/details/106547980
1. 串行mget;
2. 串行io;
3. 并行io;
4. hash_tag;
- Redis簡介
- 簡介
- 典型應用場景
- Redis安裝
- 安裝
- redis可執行文件說明
- 三種啟動方法
- Redis常用配置
- API的使用和理解
- 通用命令
- 數據結構和內部編碼
- 單線程
- 數據類型
- 字符串
- 哈希
- 列表
- 集合
- 有序集合
- Redis常用功能
- 慢查詢
- Pipline
- 發布訂閱
- Bitmap
- Hyperloglog
- GEO
- 持久化機制
- 概述
- snapshotting快照方式持久化
- append only file追加方式持久化AOF
- RDB和AOF的抉擇
- 開發運維常見問題
- fork操作
- 子進程外開銷
- AOF追加阻塞
- 單機多實例部署
- Redis復制原理和優化
- 什么是主從復制
- 主從復制配置
- 全量復制和部分復制
- 故障處理
- 開發運維常見問題
- Sentinel
- 主從復制高可用
- 架構說明
- 安裝配置
- 客戶端連接
- 實現原理
- 常見開發運維問題
- 高可用讀寫分離
- 故障轉移client怎么知道新的master地址
- 總結
- Sluster
- 呼喚集群
- 數據分布
- 搭建集群
- 集群通信
- 集群擴容
- 集群縮容
- 客戶端路由
- 故障轉移
- 故障發現
- 故障恢復
- 開發運維常見問題
- 緩存設計與優化
- 緩存收益和成本
- 緩存更新策略
- 緩存粒度控制
- 緩存穿透優化
- 緩存雪崩優化
- 無底洞問題優化
- 熱點key重建優化
- 總結
- 布隆過濾器
- 引出布隆過濾器
- 布隆過濾器基本原理
- 布隆過濾器誤差率
- 本地布隆過濾器
- Redis布隆過濾器
- 分布式布隆過濾器
- 開發規范
- 內存管理
- 開發運維常見坑
- 實戰
- 對文章進行投票
- 數據庫的概念
- 啟動多實例