
## 說明
* Redis集群自身實現了高可用。高可用首先需要解決集群部分失敗的場景:當集群內少量節點出現故障時通過自動故障轉移保證集群可以正常對外提供服務。本文介紹故障轉移的細節,分析故障發現和替換故障節點的過程
## 故障發現
1. 通過ping/pong奧西實現故障發現,不需要sentinel;
2. 主觀下線和客觀下線;
* **當集群內某個節點出現問題時,需要通過一種健壯的方式保證識別出節點是否發生了故障**。Redis集群內節點通過ping/pong消息實現節點通信,消 息不但可以傳播節點槽信息,還可以傳播其他狀態如:主從狀態、節點故障等
* **因此故障發現也是通過消息傳播機制實現的,主要環節包括:**
* **主觀下線 (pfail):**指某個節點認為另一個節點不可用,即下線狀態,這個狀態并不是最終的故障判定,只能代表一個節點的意見,可能存在誤判情況
* **客觀下線(fail):**指標記一個節點真正的下線,集群內多個節點都認為該節點不可用,從而達成共識的結果。如果是持有槽的主節點故障,需要為該節點進行故障轉移
## 主觀下線
* 集群中每個節點都會定期向其他節點發送ping消息,接收節點回復pong消息作為響應。**如果在cluster-node-timeout時間內通信一直失敗,則發送節點會認為接收節點存在故障**,把接收節點標記為**主觀下線(pfail)狀態** 主觀下線是帶有"偏見"的,是單獨一個節點認為某個節點下線了;不代表所有節點的認知;
* **流程如下圖所示:**
* 1)節點a發送ping消息給節點b,如果通信正常將接收到pong消息,節點a更新最近一次與節點b的通信時間
* 2)如果節點a與節點b通信出現問題則斷開連接,下次會進行重連。如果一直通信失敗,則節點a記錄的與節點b最后通信時間將無法更新
* 3)節點a內的定時任務檢測到與節點b最后通信時間超高cluster-nodetimeout時,更新本地對節點b的狀態為主觀下線(pfail)
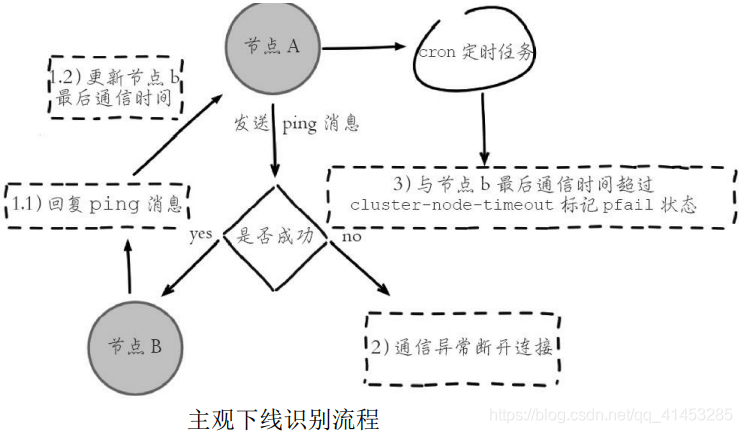
* 主觀下線簡單來講就是,**當cluster-note-timeout時間內某節點無法與另一個節點順利完成ping消息通信時,則將該節點標記為主觀下線狀態**。每個節點內的cluster State結構都需要保存其他節點信息,用于從自身視角判斷其他節點的狀態。
* **Redis集群對于節點最終是否故障判斷非常嚴謹,只有一個節點認為主觀下線并不能準確判斷是否故障**。例如下圖所示的場景,節點6379與6385通信中斷,導致6379判斷6385為主觀下線狀態,但是 6380與6385節點之間通信正常,這種情況不能判定節點6385發生故
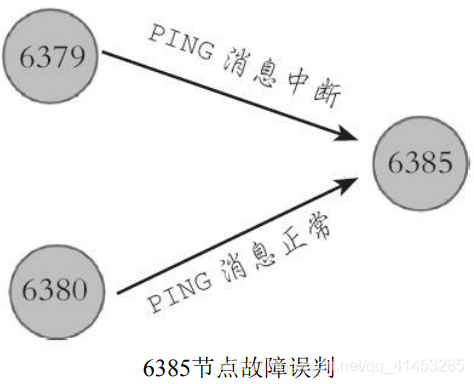
* **因此對于一個健壯的故障發現機制,需要集群內大多數節點都判斷6385故障時, 才能認為6385確實發生故障,**然后為6385節點進行故障轉移。而這種**多個節點協作完成故障發現的過程叫做客觀下線**
## 客觀下線
1. 當半數以上持有槽的主節點都標記某節點主觀下線就認為是客觀下線;
2. 客觀下線邏輯流程:
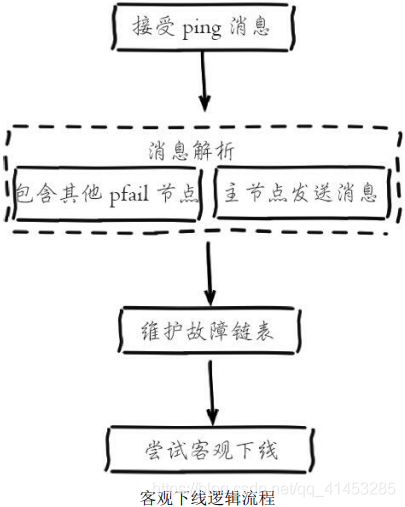
* **當某個節點判斷另一個節點主觀下線后,相應的節點狀態會跟隨消息在集群內傳播**。ping/pong消息的消息體會攜帶集群1/10的其他節點狀態數據, 當接受節點發現消息體中含有主觀下線的節點狀態時,會在本地找到故障節點的ClusterNode結構,保存到下線報告鏈表中。
* * 通過Gossip消息傳播,集群內節點不斷收集到故障節點的下線報告。**當半數以上持有槽的主節點都標記某個節點是主觀下線時。觸發客觀下線流程**。這里有兩個疑問:
* **1)為什么必須是負責槽的主節點參與故障發現決策?**因為集群模式下只有處理槽的主節點才負責讀寫請求和集群槽等關鍵信息維護,而從節點只 進行主節點數據和狀態信息的復制
* **2)為什么半數以上處理槽的主節點?**必須半數以上是為了應對網絡分 區等原因造成的集群分割情況,被分割的小集群因為無法完成從主觀下線到 客觀下線這一關鍵過程,從而防止小集群完成故障轉移之后繼續對外提供服務
* 假設節點a標記節點b為主觀下線,**一段時間后節點a通過消息把節點b的狀態發送到其他節點,當節點c接受到消息并解析出消息體含有節點b的pfail狀態時,會觸發客觀下線流程**,如下圖所示:
* 1)當消息體內含有其他節點的pfail狀態會判斷發送節點的狀態,**如果發送節點是主節點則對報告的pfail狀態處理,從節點則忽略**
* 2)找到pfail對應的節點結構,更新clusterNode內部下線報告鏈表
* 3)根據更新后的下線報告鏈表告嘗試進行客觀下線
## 維護下線報告鏈表
* 每個節點ClusterNode結構中都會存在一個**下線鏈表結構,保存了其他主節點針對當前節點的下線報告**
* 下線報告中保存了報告故障的節點結構和最近收到下線報告的時間,當接收到fail狀態時,會維護對應節點的下線上報鏈表
* 每個下線報告都存在有效期:****每次在嘗試觸發客觀下線時,都會檢測下線報告是否過期,對于過期的下線報告將被刪除。如果在cluster-node-time\*2的時間內該下線報告沒有得到更新則過期并刪除,
* 下線報告的有效期限是server.cluster\_node\_timeout\*2,**主要是針對故障誤報的情況**。例如節點A在上一小時報告節點B主觀下線,但是之后又恢復正常。現在又有其他節點上報節點B主觀下線,根據實際情況之前的屬于誤報不能被使用
* 運維提示:如果在cluster-node-time\*2時間內無法收集到一半以上槽節點的下線報告,那么之前的下線報告將會過期,也就是說主觀下線上報的速度追趕不上下線報告過期的速度,那么故障節點將永遠無法被標記為客觀下線從而導致故障轉移失敗。**因此不建議將cluster-node-time設置得過小**
## 嘗試客觀下線
**集群中的節點每次接收到其他節點的pfail狀態,都會嘗試觸發客觀下線,流程如下圖所示:**
* 1)首先統計有效的下線報告數量,如果**小于集群內持有槽的主節點總數的一半則退出**
* 2)**當下線報告大于槽主節點數量一半時,**標記對應故障節點為客觀下線狀態
* 3)**向集群廣播一條fail消息,**通知所有的節點將故障節點標記為客觀下線,fail消息的消息體只包含故障節點的ID
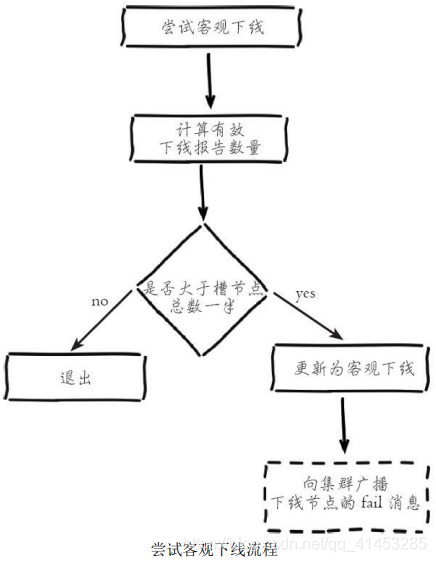
* **廣播fail消息是客觀下線的最后一步,它承擔著非常重要的職責:**
* 通知集群內所有的節點標記故障節點為客觀下線狀態并立刻生效
* 通知故障節點的從節點觸發故障轉移流程
* **需要理解的是,盡管存在廣播fail消息機制,但是集群所有節點知道故障節點進入客觀下線狀態是不確定的**。比如當出現網絡分區時有可能集群被分割為一大一小兩個獨立集群中。大的集群持有半數槽節點可以完成客觀下線并廣播fail消息,但是小集群無法接收到fail消息,如下圖所示:
* 但是當網絡恢復后,只要故障節點變為客觀下線,最終**總會通過Gossip消息傳播至集群的所有節點**
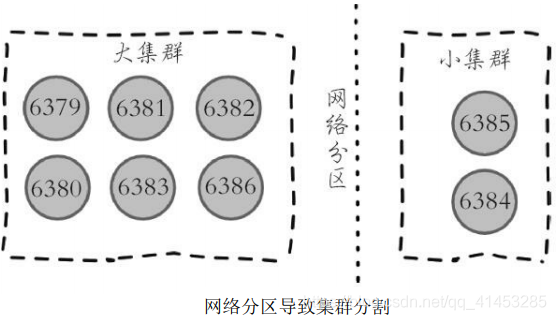
* 運維提示:網絡分區會導致分割后的小集群無法收到大集群的fail消息,因此如果故障節點所有的從節點都在小集群內將導致無法完成后續故障轉移,**因此部署主從結構時需要根據自身機房/機架拓撲結構,降低主從被分區的可能性**
- Redis簡介
- 簡介
- 典型應用場景
- Redis安裝
- 安裝
- redis可執行文件說明
- 三種啟動方法
- Redis常用配置
- API的使用和理解
- 通用命令
- 數據結構和內部編碼
- 單線程
- 數據類型
- 字符串
- 哈希
- 列表
- 集合
- 有序集合
- Redis常用功能
- 慢查詢
- Pipline
- 發布訂閱
- Bitmap
- Hyperloglog
- GEO
- 持久化機制
- 概述
- snapshotting快照方式持久化
- append only file追加方式持久化AOF
- RDB和AOF的抉擇
- 開發運維常見問題
- fork操作
- 子進程外開銷
- AOF追加阻塞
- 單機多實例部署
- Redis復制原理和優化
- 什么是主從復制
- 主從復制配置
- 全量復制和部分復制
- 故障處理
- 開發運維常見問題
- Sentinel
- 主從復制高可用
- 架構說明
- 安裝配置
- 客戶端連接
- 實現原理
- 常見開發運維問題
- 高可用讀寫分離
- 故障轉移client怎么知道新的master地址
- 總結
- Sluster
- 呼喚集群
- 數據分布
- 搭建集群
- 集群通信
- 集群擴容
- 集群縮容
- 客戶端路由
- 故障轉移
- 故障發現
- 故障恢復
- 開發運維常見問題
- 緩存設計與優化
- 緩存收益和成本
- 緩存更新策略
- 緩存粒度控制
- 緩存穿透優化
- 緩存雪崩優化
- 無底洞問題優化
- 熱點key重建優化
- 總結
- 布隆過濾器
- 引出布隆過濾器
- 布隆過濾器基本原理
- 布隆過濾器誤差率
- 本地布隆過濾器
- Redis布隆過濾器
- 分布式布隆過濾器
- 開發規范
- 內存管理
- 開發運維常見坑
- 實戰
- 對文章進行投票
- 數據庫的概念
- 啟動多實例