* 如何解決緩存雪崩?
* 如何解決緩存穿透?
* 如何保證緩存與數據庫雙寫時一致的問題?
# 一、緩存雪崩
## 1.1什么是緩存雪崩?
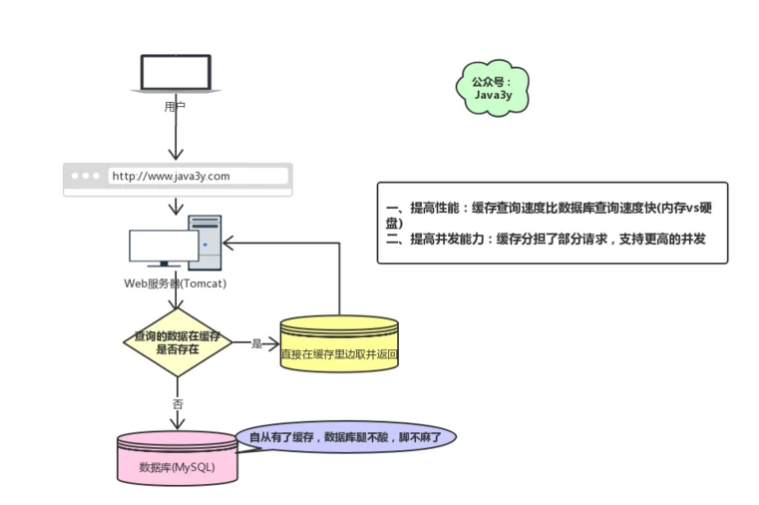
回顧一下我們為什么要用緩存(Redis):
](images/screenshot_1628844092011.png)
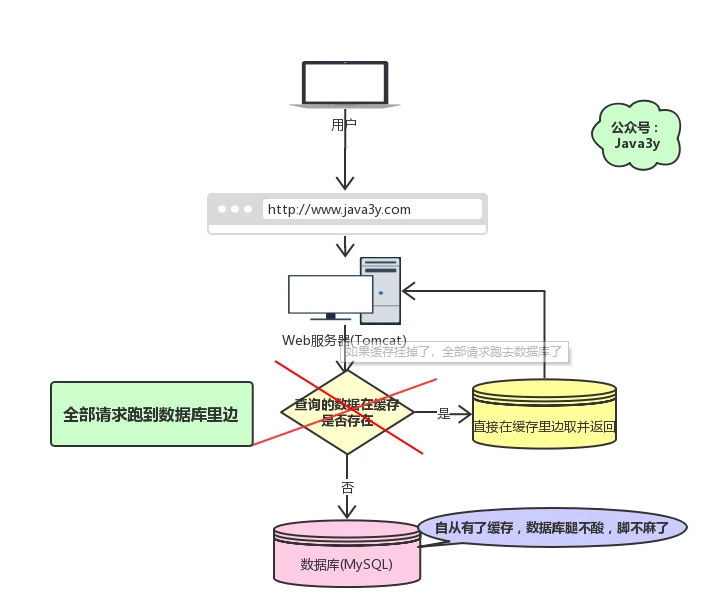
現在有個問題,**如果我們的緩存掛掉了,這意味著我們的全部請求都跑去數據庫了**。
](images/screenshot_1628844112093.png)
在前面學習我們都知道Redis不可能把所有的數據都緩存起來(**內存昂貴且有限**),所以Redis需要對數據設置過期時間,并采用的是惰性刪除+定期刪除兩種策略對過期鍵刪除。[Redis對過期鍵的策略+持久化](https://link.segmentfault.com/?url=https%3A%2F%2Fmp.weixin.qq.com%2Fs%3F__biz%3DMzI4Njg5MDA5NA%3D%3D%26amp%3Bmid%3D2247484386%26amp%3Bidx%3D1%26amp%3Bsn%3D323ddc84dc851a975530090fcd6e2326%26amp%3Bchksm%3Debd742e3dca0cbf52bc65d430447e639d81cc13e0ac34613edf464dae3950b10e2e1df74dcc5%26amp%3Btoken%3D1834317504%26amp%3Blang%3Dzh_CN%23rd)
如果緩存數據**設置的過期時間是相同**的,并且Redis恰好將這部分數據全部刪光了。這就會導致在這段時間內,這些緩存**同時失效**,全部請求到數據庫中。
**這就是緩存雪崩**:
* Redis掛掉了,請求全部走數據庫。
* 對緩存數據設置相同的過期時間,導致某段時間內緩存失效,請求全部走數據庫。
緩存雪崩如果發生了,很可能就把我們的數據庫**搞垮**,導致整個服務癱瘓!
## 1.2如何解決緩存雪崩?
對于“對緩存數據設置相同的過期時間,導致某段時間內緩存失效,請求全部走數據庫。”這種情況,非常好解決:
* 解決方法:在緩存的時候給過期時間加上一個**隨機值**,這樣就會大幅度的**減少緩存在同一時間過期**。
對于“Redis掛掉了,請求全部走數據庫”這種情況,我們可以有以下的思路:
* 事發前:實現Redis的**高可用**(主從架構+Sentinel 或者Redis Cluster),盡量避免Redis掛掉這種情況發生。
* 事發中:萬一Redis真的掛了,我們可以設置**本地緩存(ehcache)+限流(hystrix)**,盡量避免我們的數據庫被干掉(起碼能保證我們的服務還是能正常工作的)
* 事發后:redis持久化,重啟后自動從磁盤上加載數據,**快速恢復緩存數據**。
# 二、緩存穿透
## 2.1什么是緩存穿透
比如,我們有一張數據庫表,ID都是(**正數**):
但是可能有黑客想把我的數據庫搞垮,每次請求的ID都是**負數**。這會導致我的緩存就沒用了,請求全部都找數據庫去了,但數據庫也沒有這個值啊,所以每次都返回空出去。
> 緩存穿透是指查詢一個一定**不存在的數據**。由于緩存不命中,并且出于容錯考慮,如果從**數據庫查不到數據則不寫入緩存**,這將導致這個不存在的數據**每次請求都要到數據庫去查詢**,失去了緩存的意義。
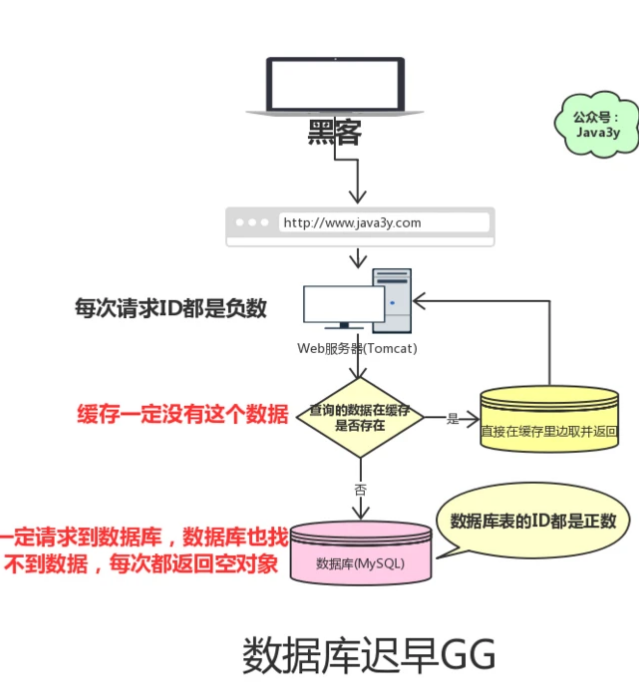
**這就是緩存穿透**:
* 請求的數據在緩存大量不命中,導致請求走數據庫。
緩存穿透如果發生了,也可能把我們的數據庫**搞垮**,導致整個服務癱瘓!
## 2.1如何解決緩存穿透?
解決緩存穿透也有兩種方案:
* 由于請求的參數是不合法的(每次都請求不存在的參數),于是我們可以使用布隆過濾器(BloomFilter)或者壓縮filter**提前攔截**,不合法就不讓這個請求到數據庫層!
* 當我們從數據庫找不到的時候,我們也將這個**空對象設置到緩存里邊去**。下次再請求的時候,就可以從緩存里邊獲取了。
* 這種情況我們一般會將空對象設置一個**較短的過期時間**。
參考資料:
* 緩存系列文章--緩存穿透問題
* [https://carlosfu.iteye.com/blog/2248185](https://link.segmentfault.com/?url=https%3A%2F%2Fcarlosfu.iteye.com%2Fblog%2F2248185)
# 三、緩存與數據庫雙寫一致
## 3.1對于讀操作,流程是這樣的
上面講緩存穿透的時候也提到了:如果從數據庫查不到數據則不寫入緩存。
一般我們對**讀操作**的時候有這么一個**固定的套路**:
* 如果我們的數據在緩存里邊有,那么就直接取緩存的。
* 如果緩存里沒有我們想要的數據,我們會先去查詢數據庫,然后**將數據庫查出來的數據寫到緩存中**。
* 最后將數據返回給請求
## 3.2什么是緩存與數據庫雙寫一致問題?
如果僅僅查詢的話,緩存的數據和數據庫的數據是沒問題的。但是,當我們要**更新**時候呢?各種情況很可能就**造成數據庫和緩存的數據不一致**了。
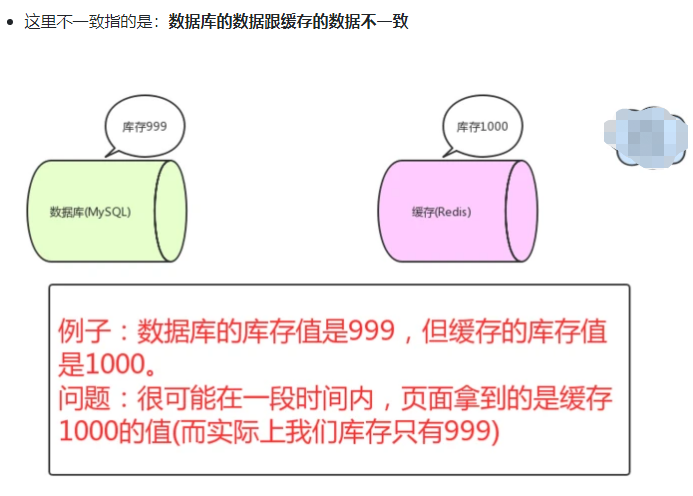
從理論上說,只要我們設置了**鍵的過期時間**,我們就能保證緩存和數據庫的數據**最終是一致**的。因為只要緩存數據過期了,就會被刪除。隨后讀的時候,因為緩存里沒有,就可以查數據庫的數據,然后將數據庫查出來的數據寫入到緩存中。
除了設置過期時間,我們還需要做更多的措施來**盡量避免**數據庫與緩存處于不一致的情況發生。
## 3.3對于更新操作
一般來說,執行更新操作時,我們會有兩種選擇:
* 先操作數據庫,再操作緩存
* 先操作緩存,再操作數據庫
首先,要明確的是,無論我們選擇哪個,我們都希望這**兩個操作要么同時成功,要么同時失敗**。所以,這會演變成一個**分布式事務**的問題。
所以,**如果原子性被破壞了**,可能會有以下的情況:
* **操作數據庫成功了,操作緩存失敗了**。
* **操作緩存成功了,操作數據庫失敗了**。
> 如果第一步已經失敗了,我們直接返回Exception出去就好了,第二步根本不會執行。
下面我們具體來分析一下吧。
### 3.3.1操作緩存
操作緩存也有兩種方案:
* 更新緩存
* 刪除緩存
一般我們都是采取**刪除緩存**緩存策略的,原因如下:
1. 高并發環境下,無論是先操作數據庫還是后操作數據庫而言,如果加上更新緩存,那就**更加容易**導致數據庫與緩存數據不一致問題。(刪除緩存**直接和簡單**很多)
2. 如果每次更新了數據庫,都要更新緩存【這里指的是頻繁更新的場景,這會耗費一定的性能】,倒不如直接刪除掉。等再次讀取時,緩存里沒有,那我到數據庫找,在數據庫找到再寫到緩存里邊(體現**懶加載**)
基于這兩點,對于緩存在更新時而言,都是建議執行**刪除**操作!
### 3.3.2先更新數據庫,再刪除緩存
正常的情況是這樣的:
* 先操作數據庫,成功;
* 再刪除緩存,也成功;
如果原子性被破壞了:
* 第一步成功(操作數據庫),第二步失敗(刪除緩存),會導致**數據庫里是新數據,而緩存里是舊數據**。
* 如果第一步(操作數據庫)就失敗了,我們可以直接返回錯誤(Exception),不會出現數據不一致。
如果在高并發的場景下,出現數據庫與緩存數據不一致的**概率特別低**,也不是沒有:
* 緩存**剛好**失效
* 線程A查詢數據庫,得一個舊值
* 線程B將新值寫入數據庫
* 線程B刪除緩存
* 線程A將查到的舊值寫入緩存
要達成上述情況,還是說一句**概率特別低**:
> 因為這個條件需要發生在讀緩存時緩存失效,而且并發著有一個寫操作。而實際上數據庫的寫操作會比讀操作慢得多,而且還要鎖表,**而讀操作必需在寫操作前進入數據庫操作,而又要晚于寫操作更新緩存**,所有的這些條件都具備的概率基本并不大。
對于這種策略,其實是一種設計模式:`Cache Aside Pattern`
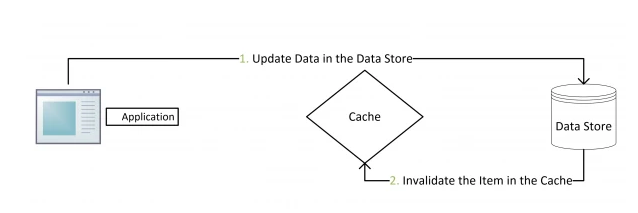
**刪除緩存失敗的解決思路**:
* 將需要刪除的key發送到消息隊列中
* 自己消費消息,獲得需要刪除的key
* **不斷重試刪除操作,直到成功**
### 3.3.3先刪除緩存,再更新數據庫
正常情況是這樣的:
* 先刪除緩存,成功;
* 再更新數據庫,也成功;
如果原子性被破壞了:
* 第一步成功(刪除緩存),第二步失敗(更新數據庫),數據庫和緩存的數據還是一致的。
* 如果第一步(刪除緩存)就失敗了,我們可以直接返回錯誤(Exception),數據庫和緩存的數據還是一致的。
看起來是很美好,但是我們在并發場景下分析一下,就知道還是有問題的了:
* 線程A刪除了緩存
* 線程B查詢,發現緩存已不存在
* 線程B去數據庫查詢得到舊值
* 線程B將舊值寫入緩存
* 線程A將新值寫入數據庫
所以也會導致數據庫和緩存不一致的問題。
**并發下解決數據庫與緩存不一致的思路**:
* 將刪除緩存、修改數據庫、讀取緩存等的操作積壓到**隊列**里邊,實現**串行化**。

## 3.4對比兩種策略
我們可以發現,兩種策略各自有優缺點:
* 先刪除緩存,再更新數據庫
* 在高并發下表現不如意,在原子性被破壞時表現優異
* 先更新數據庫,再刪除緩存(`Cache Aside Pattern`設計模式)
* 在高并發下表現優異,在原子性被破壞時表現不如意
## 3.5其他保障數據一致的方案與資料
可以用**databus**或者阿里的**canal監聽binlog**進行更新。
參考資料:
* 緩存更新的套路
* [https://coolshell.cn/articles/17416.html](https://link.segmentfault.com/?url=https%3A%2F%2Fcoolshell.cn%2Farticles%2F17416.html)
* 如何保證緩存與數據庫雙寫時的數據一致性?
* [https://github.com/doocs/advanced-java/blob/master/docs/high-concurrency/redis-consistence.md](https://link.segmentfault.com/?url=https%3A%2F%2Fgithub.com%2Fdoocs%2Fadvanced-java%2Fblob%2Fmaster%2Fdocs%2Fhigh-concurrency%2Fredis-consistence.md)
* 分布式之數據庫和緩存雙寫一致性方案解析
* [https://zhuanlan.zhihu.com/p/48334686](https://link.segmentfault.com/?url=https%3A%2F%2Fzhuanlan.zhihu.com%2Fp%2F48334686)
* Cache Aside Pattern
* [https://blog.csdn.net/z50l2o08e2u4aftor9a/article/details/81008933](https://link.segmentfault.com/?url=https%3A%2F%2Fblog.csdn.net%2Fz50l2o08e2u4aftor9a%2Farticle%2Fdetails%2F81008933)
- 文檔說明
- 開始
- linux
- 常用命令
- ps -ef
- lsof
- netstat
- 解壓縮
- 復制
- 權限
- 其他
- lnmp集成安裝
- supervisor
- 安裝
- supervisor進程管理
- nginx
- 域名映射
- 負載均衡配置
- lnmp集成環境安裝
- nginx源碼安裝
- location匹配
- 限流配置
- 日志配置
- 重定向配置
- 壓縮策略
- nginx 正/反向代理
- HTTPS配置
- mysql
- navicat創建索引
- 設置外網鏈接mysql
- navicat破解
- sql語句學習
- 新建mysql用戶并賦予權限
- php
- opcache
- 設計模式
- 在CentOS下安裝crontab服務
- composer
- 基礎
- 常用的包
- guzzle
- 二維碼
- 公共方法
- 敏感詞過濾
- IP訪問頻次限制
- CURL
- 支付
- 常用遞歸
- 數據排序
- 圖片相關操作
- 權重分配
- 毫秒時間戳
- base64<=>圖片
- 身份證號分析
- 手機號相關操作
- 項目搭建 公共處理函數
- JWT
- 系統函數
- json_encode / json_decode 相關
- 數字計算
- 數組排序
- php8
- jit特性
- php8源碼編譯安裝
- laravel框架
- 常用artisan命令
- 常用查詢
- 模型關聯
- 創建公共方法
- 圖片上傳
- 中間件
- 路由配置
- jwt
- 隊列
- 定時任務
- 日志模塊
- laravel+swoole基本使用
- 拓展庫
- 請求接口log
- laravel_octane
- 微信開發
- token配置驗證
- easywechart 獲取用戶信息
- 三方包
- webman
- win下熱更新代碼
- 使用laravel db listen 監聽sql語句
- guzzle
- 使用workman的httpCLient
- 修改隊列后代碼不生效
- workman
- 安裝與使用
- websocket
- eleticsearch
- php-es 安裝配置
- hyperf
- 熱更新
- 安裝報錯
- swoole
- 安裝
- win安裝swoole-cli
- google登錄
- golang
- 文檔地址
- 標準庫
- time
- 數據類型
- 基本數據類型
- 復合數據類型
- 協程&管道
- 協程基本使用
- 讀寫鎖 RWMutex
- 互斥鎖Mutex
- 管道的基本使用
- 管道select多路復用
- 協程加管道
- beego
- gin
- 安裝
- 熱更新
- 路由
- 中間件
- 控制器
- 模型
- 配置文件/conf
- gorm
- 初始化
- 控制器 模型查詢封裝
- 添加
- 修改
- 刪除
- 聯表查詢
- 環境搭建
- Windows
- linux
- 全局異常捕捉
- javascript
- 常用函數
- vue
- vue-cli
- 生產環境 開發環境配置
- 組件通信
- 組件之間通信
- 父傳子
- 子傳父
- provide->inject (非父子)
- 引用元素和組件
- vue-原始寫法
- template基本用法
- vue3+ts項目搭建
- vue3引入element-plus
- axios 封裝網絡請求
- computed 計算屬性
- watch 監聽
- 使用@符 代替文件引入路徑
- vue開發中常用的插件
- vue 富文本編輯
- nuxt
- 學習筆記
- 新建項目踩坑整理
- css
- flex布局
- flex PC端基本布局
- flex 移動端基本布局
- 常用css屬性
- 盒子模型與定位
- 小說分屏顯示
- git
- 基本命令
- fetch
- 常用命令
- 每次都需要驗證
- git pull 有沖突時
- .gitignore 修改后不生效
- 原理解析
- tcp與udp詳解
- TCP三次握手四次揮手
- 緩存雪崩 穿透 更新詳解
- 內存泄漏-內存溢出
- php_fpm fast_cgi cig
- redis
- 相關三方文章
- API對外接口文檔示范
- elaticsearch
- 全文檢索
- 簡介
- 安裝
- kibana
- 核心概念 索引 映射 文檔
- 高級查詢 Query DSL
- 索引原理
- 分詞器
- 過濾查詢
- 聚合查詢
- 整合應用
- 集群
- docker
- docker 簡介
- docker 安裝
- docker 常用命令
- image 鏡像命令
- Contrainer 容器命令
- docker-compose
- redis 相關
- 客戶端安裝
- Linux 環境下安裝
- uni
- http請求封裝
- ios打包
- 視頻縱向播放
- 日記
- 工作日記
- 情感日志
- 壓測
- ab
- ui
- thorui
- 開發規范
- 前端
- 后端
- 狀態碼
- 開發小組未來規劃