
## 分代收集理論
### 3個假說
* 弱分代假說:絕大多數對象都是朝生夕滅的。(設計了年輕代)
* 強分代假說:熬過越多次垃圾收集過程的對象就越難以消亡。(設計了老年代)
* 跨代引用假說:跨代引用相對于同代引用僅占極少數。(實際Java應用中,可能會存在年輕代的對象跨代引用了老年代的對象)(設計了`記憶集`,在新生代上建立全局的記憶集,把老年代劃分為若干個小塊,標識出老年代的哪一塊內存會存在跨代引用,此后在Minor GC時,只有包含了跨代引用的小塊內存里的對象才會被加入到GC Roots進行掃描)
### 分代實現
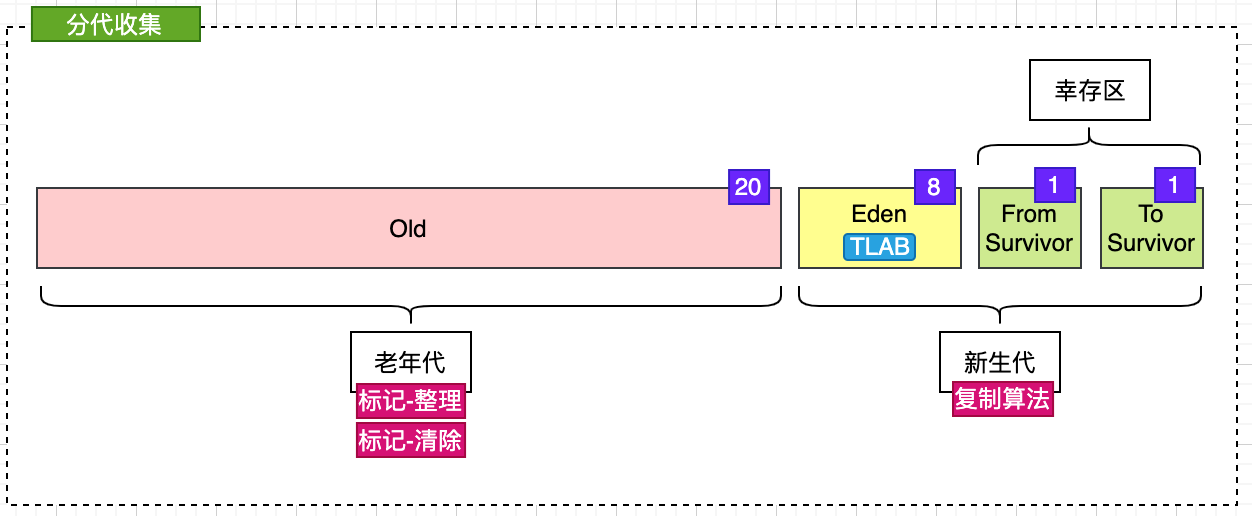
HotSpot虛擬機中,根據對象存活周期的不同,將內存劃分為幾塊。一般是將Java堆分為新生代和老年代,比例為`2:1`;新生代又細分為`Eden`區、`From Survivor`區和`To Survivor`區,比例為`8:1:1`。不同的代采用不同的回收算法:
* 新生代:復制算法
* 老年代:標記-清除算法,或者標記-整理算法
### 定義一些關于GC的名詞
1. 部分收集(Partial GC): 不是完整收集Java堆的收集。
* 新生代收集(Minor GC/Young GC):只是新生代的收集。
* 老年代收集(Major GC/Old GC):只是老年代的收集。目前只有CMS收集器會有單獨收集老年代的行為。
* 混合收集(Mixed GC):收集整個新生代以及部分老年代的垃圾收集。目前只有G1收集器會有這種行為。
2. 整堆收集(Full GC):收集整個Java堆和方法區的垃圾收集。
## 垃圾收集算法
知道了如何判定**無用的對象**、**廢棄常量**和**無用的類**后,接下來就是將這些無用的對象給回收掉。
如下是常用的3種垃圾收集算法。
### 標記-清除
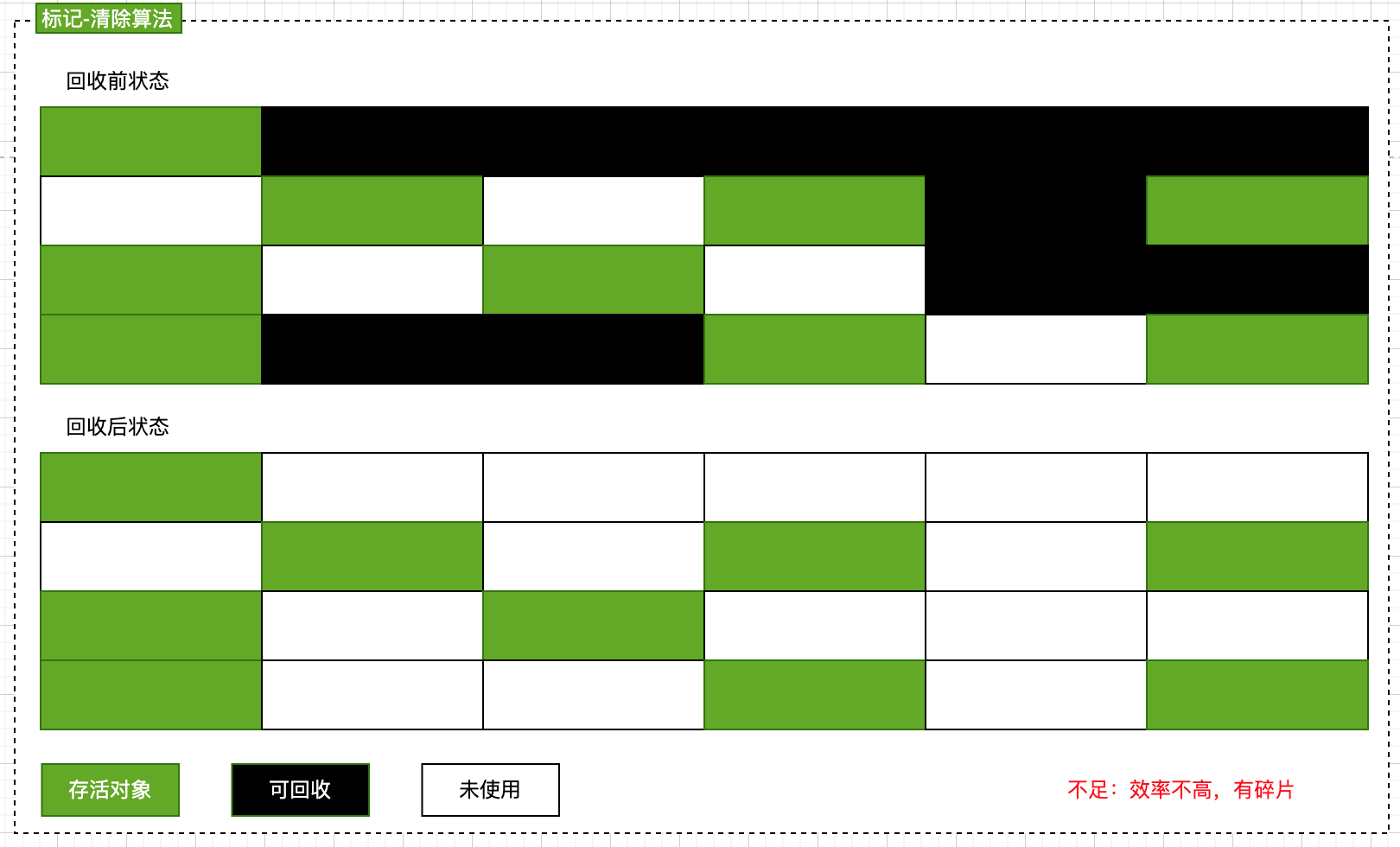
該算法分為標記和清除兩個階段。
* 標記:遍歷所有的 GC Roots,然后將所有 GC Roots 可達的對象標記為存活的對象。
* 清除:遍歷堆中所有的對象,將沒有標記的對象清除掉。同時清除對象上的標記,以便下一次垃圾回收。
這種方法有2個不足:
1. 效率問題:標記和清除2個過程效率都不高
2. 空間問題:回收后內存會有大量碎片;碎片太多可能導致以后需要分配大對象時,無法找到足夠連續的內存不得不提前觸發另一次垃圾回收動作。
### 復制(新生代)

為了解決效率問題,復制算法出現了。它將可用內存按容量劃分為大小相同的兩塊,每次只使用其中的一塊。當這一塊內存用完,需要進行垃圾收集時,就將存活的對象復制到另一塊上,然后清除掉這一塊內存。
這種算法有優有劣:
* 優勢:不會產生碎片。
* 劣勢:內存縮小為原來的一般,浪費空間。
**為了解決空間利用率問題**,可以將內存分為3塊:Eden、From Survivor、To Survivor,比例是8:1:1,每次使用Eden和其中一塊Survivor。回收時,將Eden和Survivor中存活的對象一次性復制到另一塊Survivor空間上,最后清理掉Eden和剛才使用的Survivor空間。這樣只有10%的內存被浪費。
但是無法保證每次回收都只有不多于10%的對象存活,當Survivor空間不足時,需要依賴其他內存(老年代)進行**分配擔保**。
**分配擔保**是指如果另一塊Survivor空間沒有足夠空間存放上一次新生代收集下來的存活對象時(超過10%),這些對象將直接通過分配擔保機制進入老年代。
### 標記-整理(老年代)
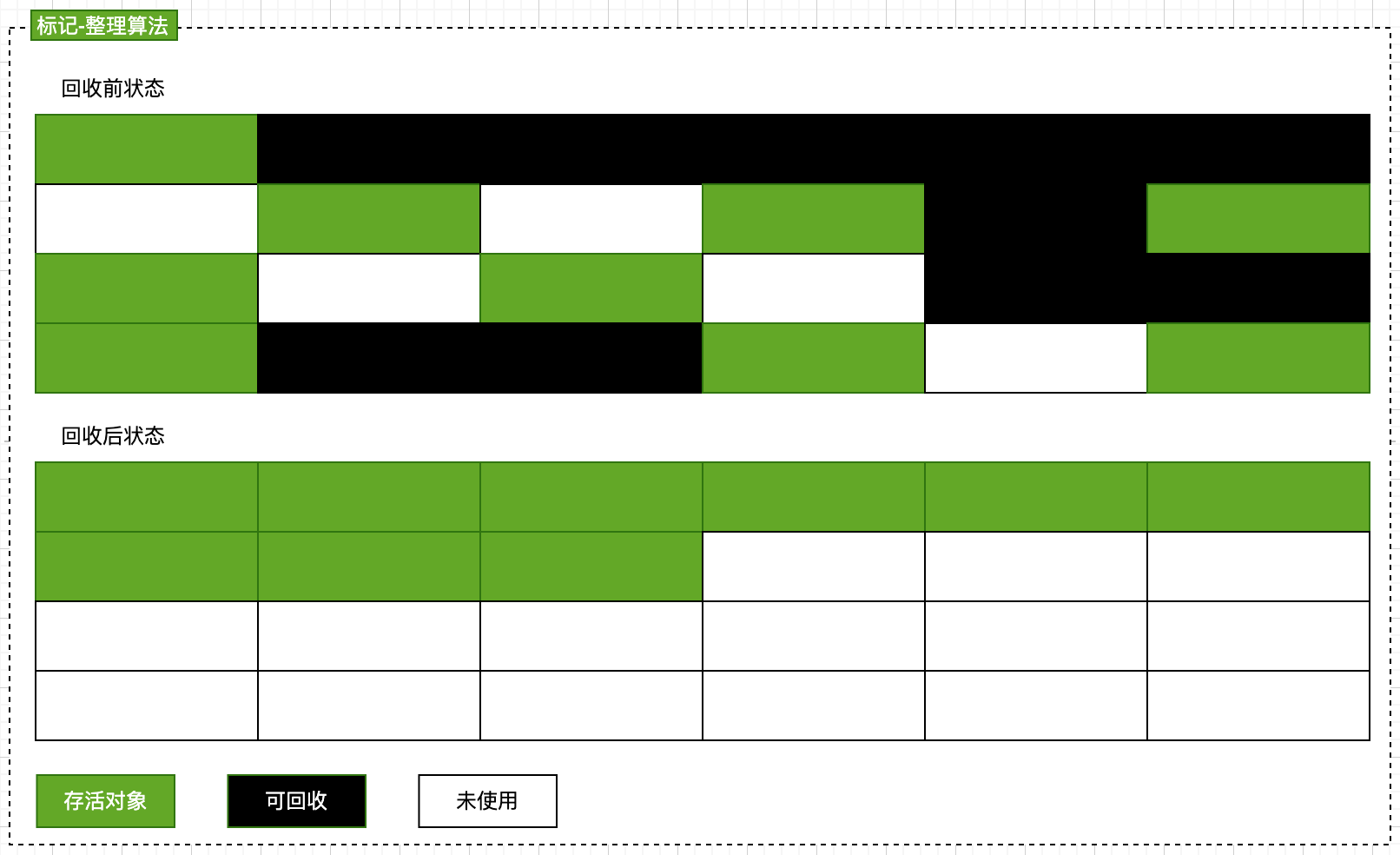
該算法分為標記和整理兩個階段。
* 標記:遍歷所有的 GC Roots,然后將所有 GC Roots 可達的對象標記為存活的對象。(和標記-清除的標記階段一樣)
* 整理:移動所有存活的對象,按著內存地址次序依次排列,然后將末端地址以后的全部內存回收。
這是一種老年代的收集算法,老年代的對象存活時間比較長。
## 參考資料
* 周志明 * 《深入理解Java虛擬機》
* Java虛擬機底層原理知識總結 * https://doocs.github.io/jvm/
- 面試突擊
- Java虛擬機
- 認識字節碼
- 000Java發展歷史
- 000Macos10.15.7上編譯OpenJDK8u
- 001熟悉Java內存區域
- 002熟悉HotSpot中的對象
- 003Java如何計算對象大小
- 004垃圾判定算法與4大引用
- 005回收堆和方法區中對象
- 006垃圾收集算法
- 007HotSpot虛擬機垃圾算法實現篇1
- 007HotSpot虛擬機垃圾算法實現篇2
- 007HotSpot虛擬機垃圾算法實現篇3
- 008垃圾收集器
- 009內存分配與回收策略
- 010Java虛擬機相關工具
- 011調優案例分析
- 012一次IDEA的啟動速度調優
- 013類文件Class的結構
- 014熟悉字節碼指令
- 015類加載機制(過程)
- 016類加載器
- IDEA的JVM參數
- Java基礎
- Java自動裝箱與拆箱
- Java基礎數據類型
- Java方法的參數傳遞
- Java并發
- 001走入并行的世界
- 002并行程序基礎
- 003熟悉Java內存模型JMM
- 004Java并發之volatile關鍵字
- 005線程池入門到精通
- 006Java多線程間的同步控制方法
- 007Java維基準測試框架JMH
- 008Java并發容器
- 009Java的線程實現
- 010Java關鍵字synchronized
- 011一些并行模式的熟悉
- 單例模式和不變模式
- 生產者消費者模式
- Future模式
- 012一些并行算法的熟悉
- 面試總結
- 長亮一面