
[TOC]
Java內存模型規范(JSR-133)是圍繞原子性、可見性和有序性展開的。
## 原子性、可見性、有序性

如下圖說明了Java線程、工作內存和主存之前的關系。
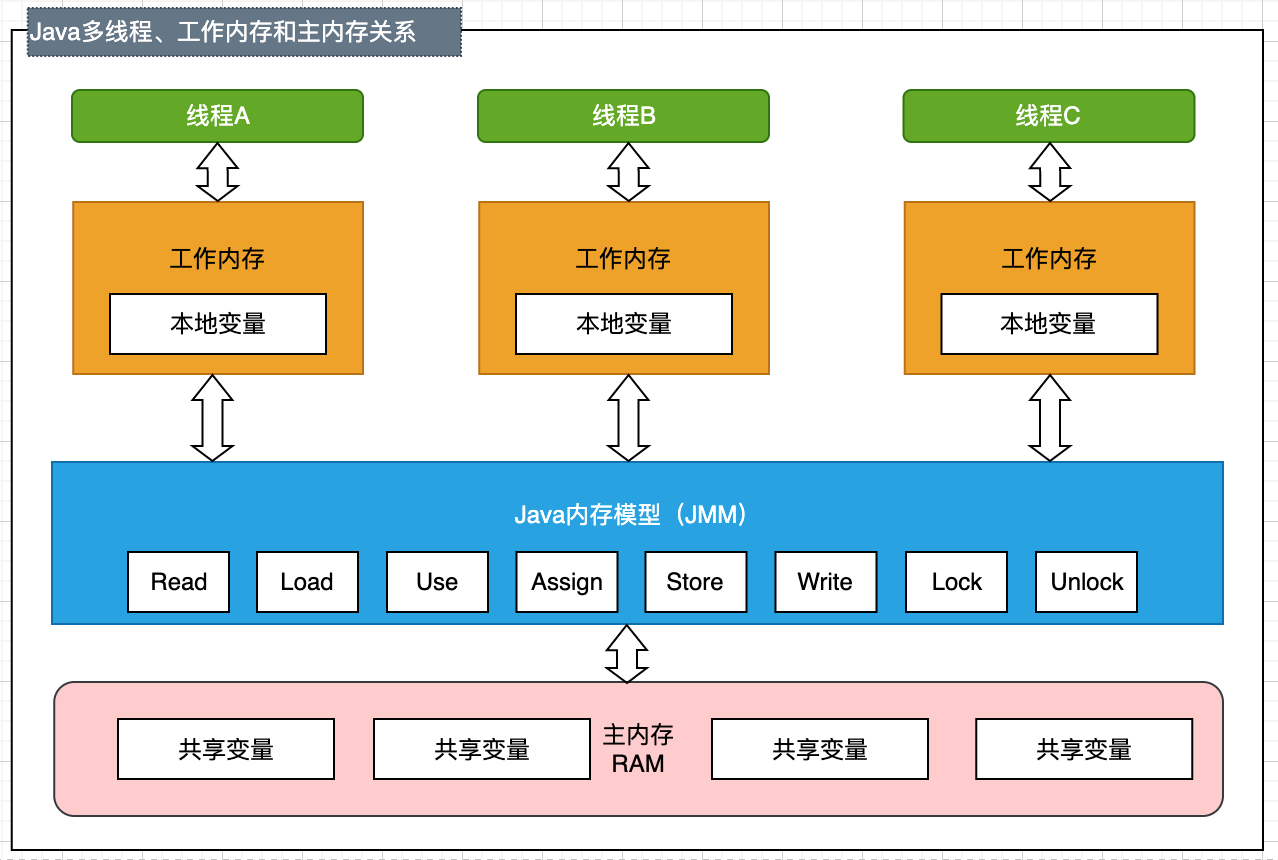
Java內存模型(JMM)定義了一套自己的主存到工作內存之間的交互協議,即一個變量如何從主存拷貝到工作內存,又如何從工作內存寫入主存,該協議包含8種操作,并且要求JVM具體實現必須保證其中每一種操作都是原子的、不可再分的。
8種操作分別是:
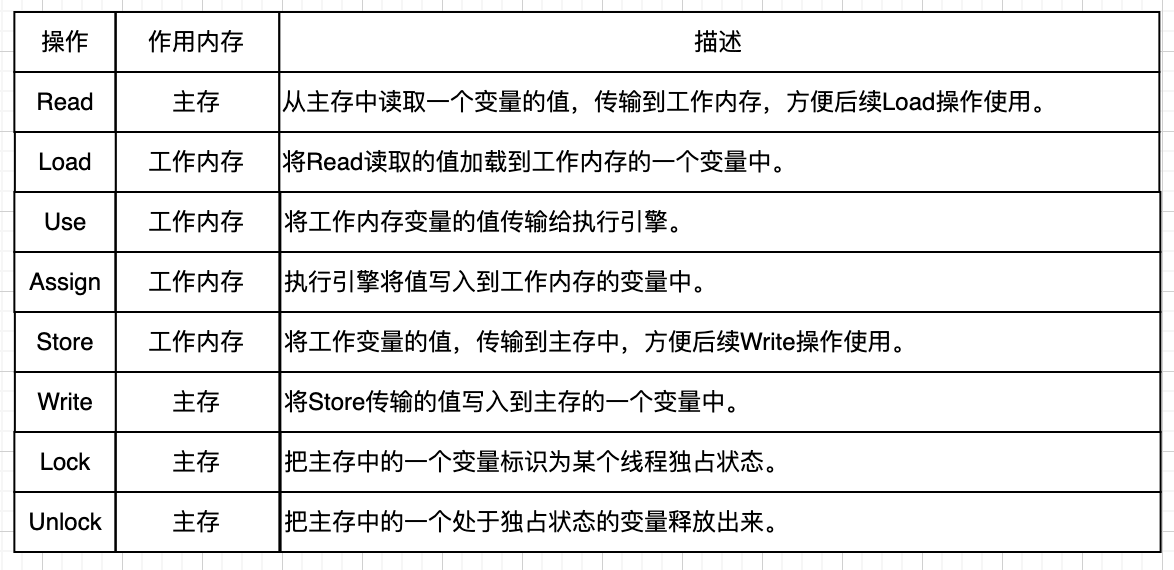
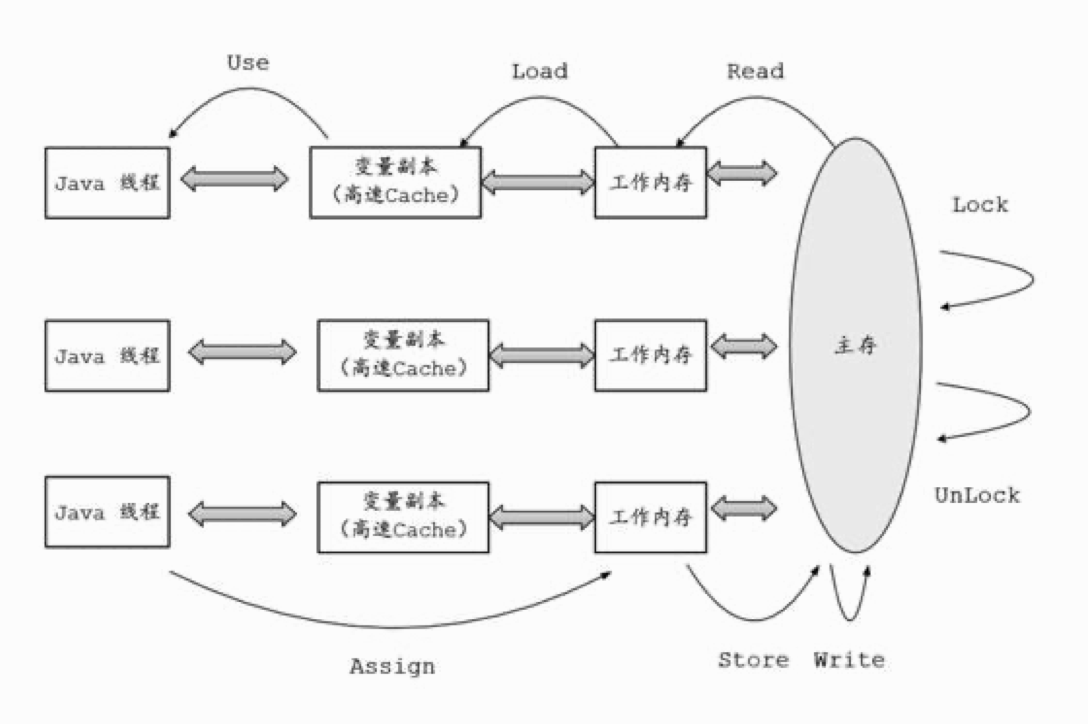
如下圖描述了以上8個操作所在位置:
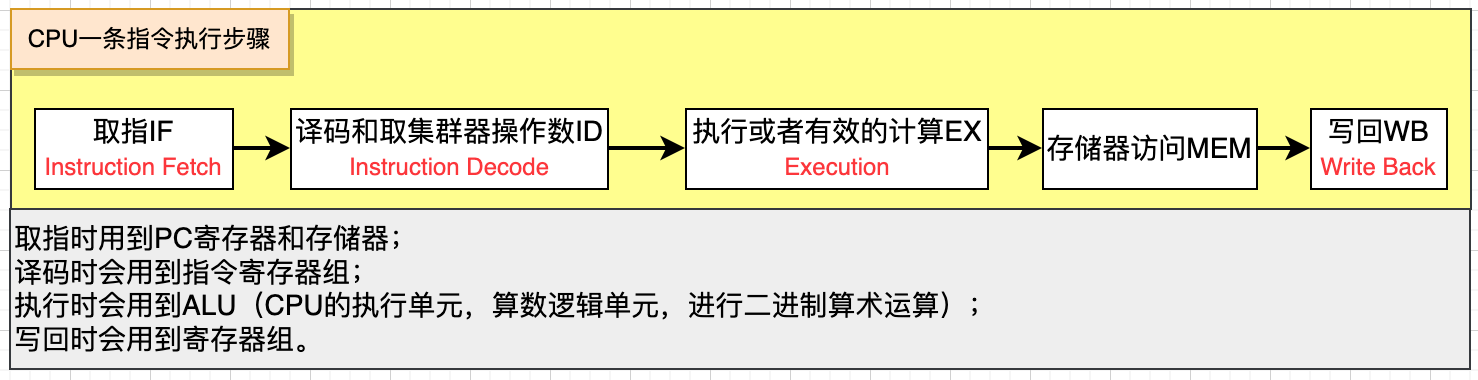
## 什么是指令重排,為什么需要?
要搞懂指令重排,首先要知道一條指令在CPU內是如何執行的,如下圖約5個步驟。
為了加快指令并行速度,CPU硬件支持了流水線技術。
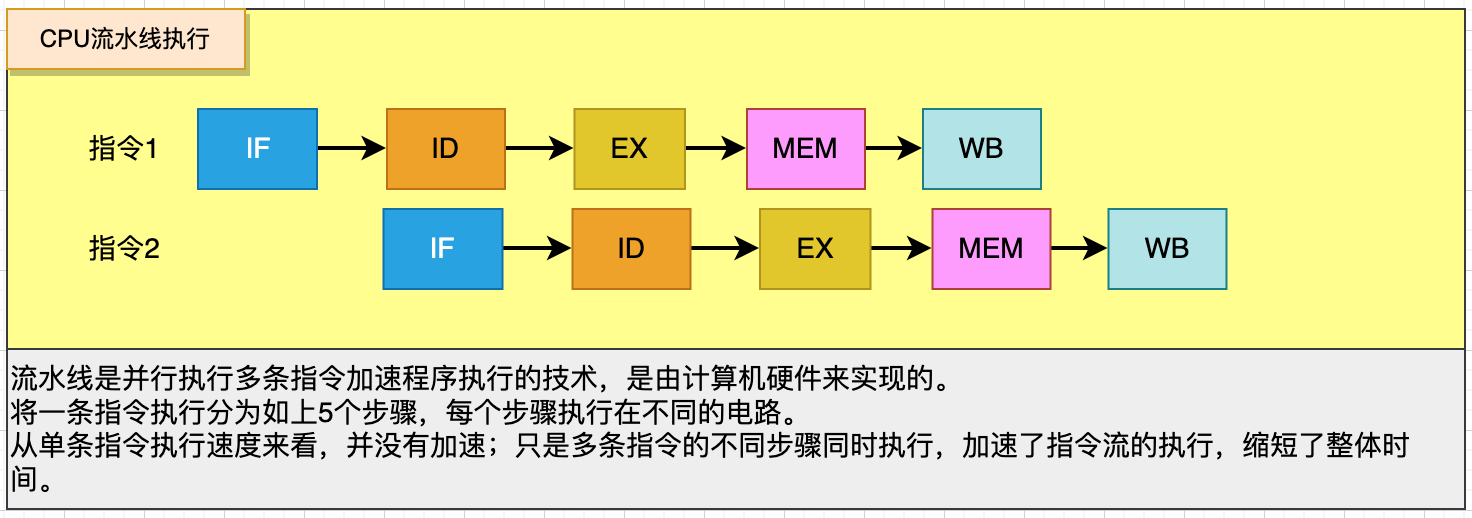
不同的指令步驟執行在不同的硬件局部,從而可以支持同時并發執行。
知道了CPU流水線之后,我們來看一個A=B+C的流水線執行過程例子:
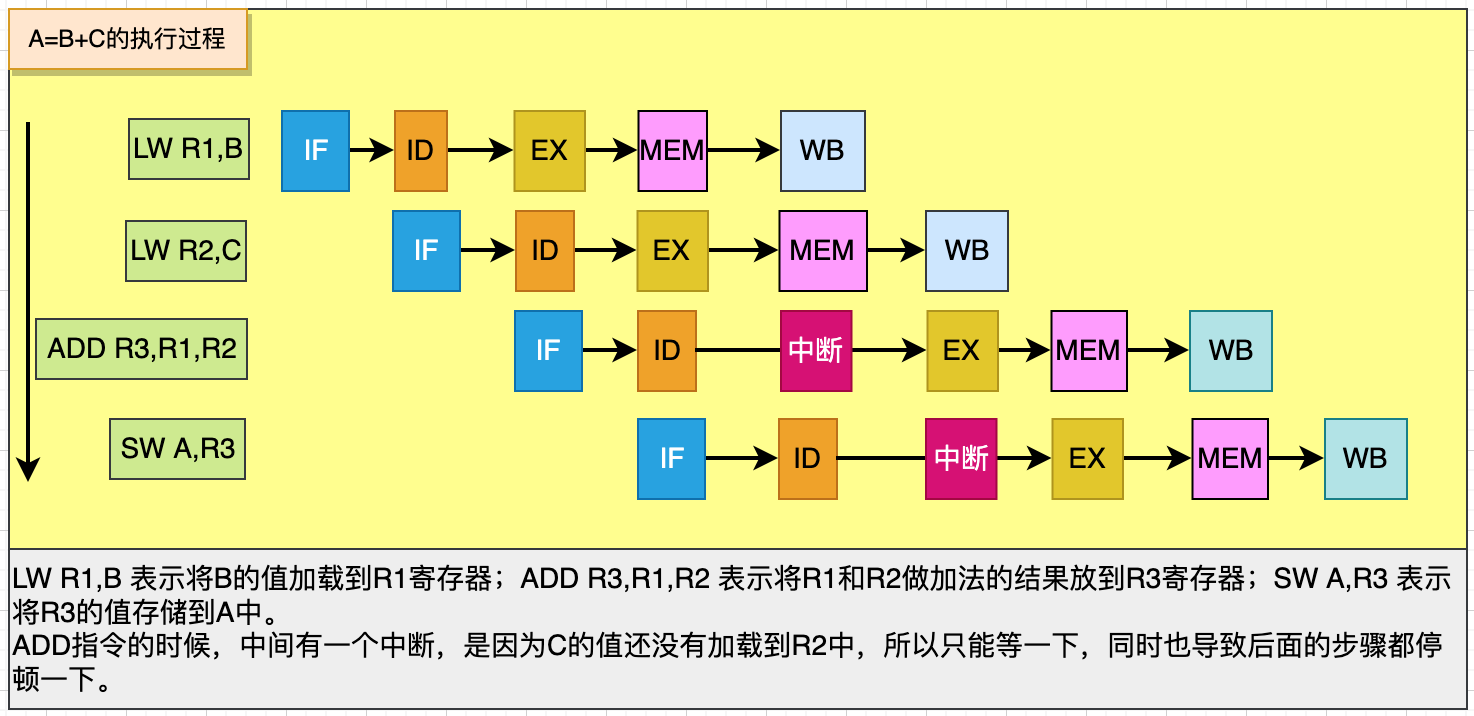
如果按串行排列,則耗時4 * 5 = 20個時鐘周期;使用CPU流水線并行技術后,可以只消耗9個時鐘周期,節省了11個時鐘周期的時間。所以流水線技術的引入,大大提高了CPU并行執行速度。
再看如下圖的例子:
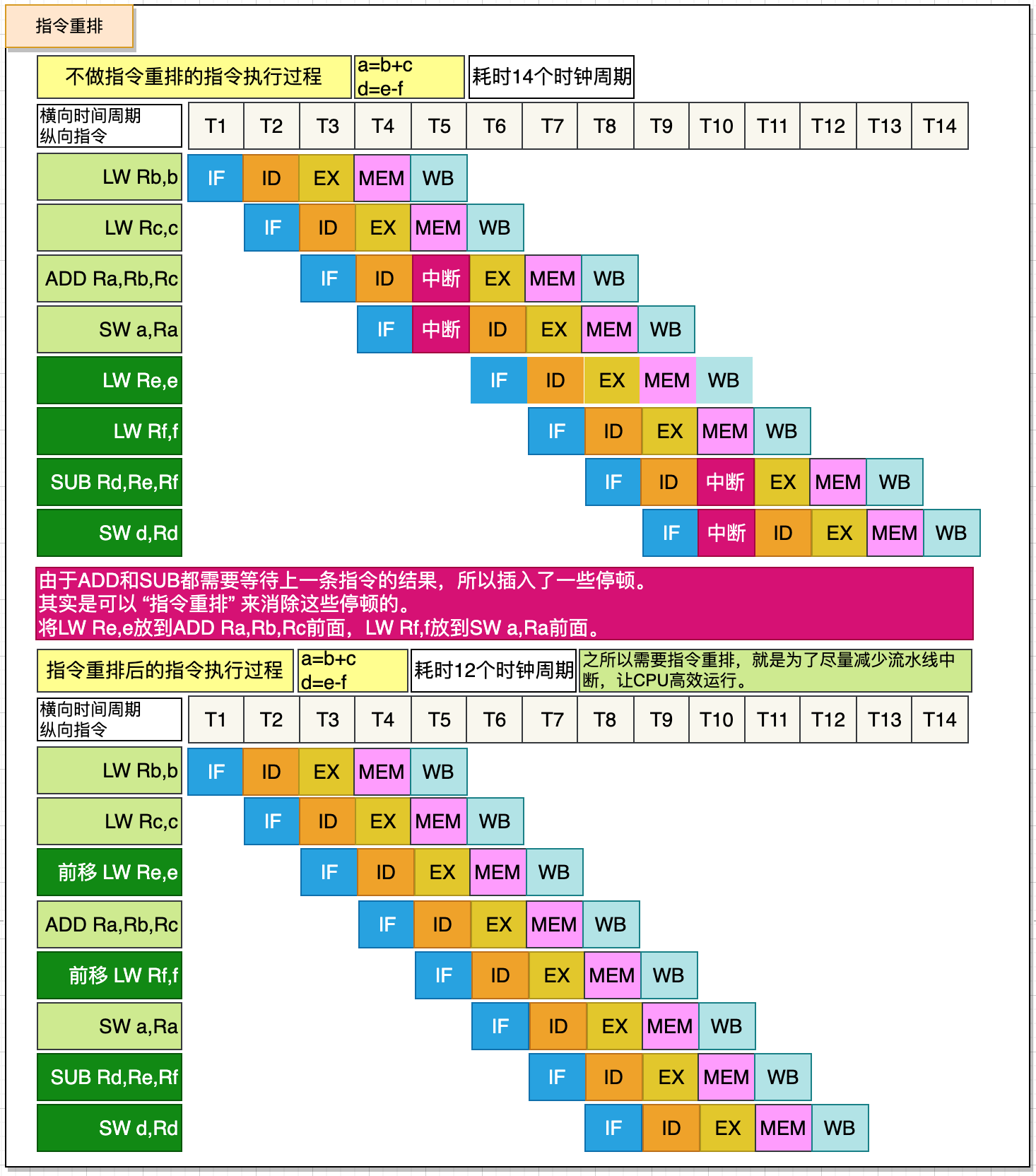
多條語句執行時,通過指令重排(CPU指令級重排序)可以消除一些CPU中斷,從而縮短執行時間,加快執行速度。
## 重排序
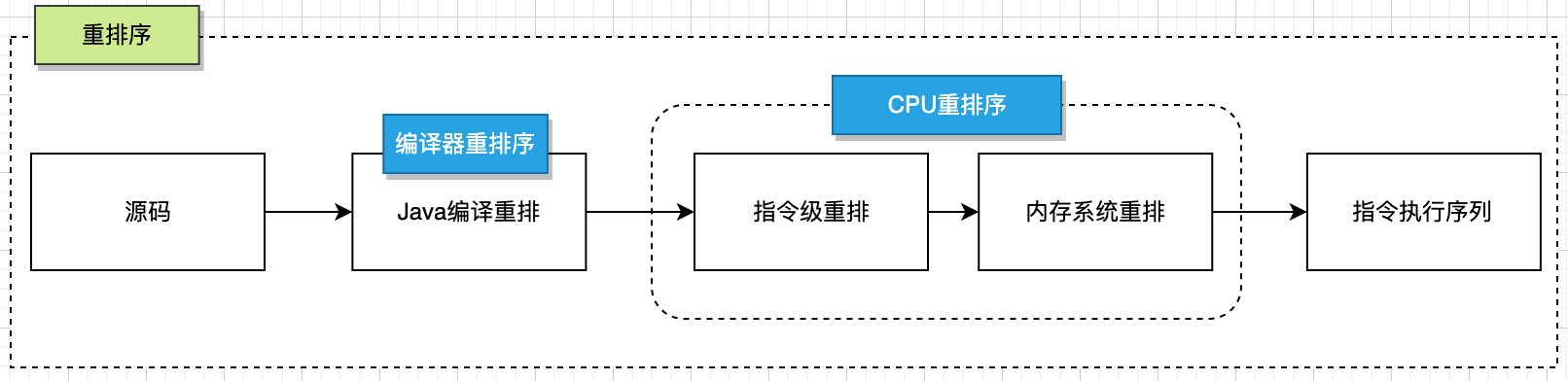
對于Java語言來說,為了提高新能,從源碼到得到指令執行序列可能會經過編譯器重排序和CPU重排序;CPU重排序又分為指令級重排和內存系統重排。
### 編譯器重排序
編譯器重排序指的是在代碼編譯階段進行指令重排,不改變程序執行結果的情況下,為了提升效率,編譯器對指令進行亂序(Out-of-Order)的編譯。
### CPU重排序
流水線(Pipeline)和亂序執行(Out-of-Order Execution)是現代CPU基本都具有的特性。
所謂“亂序”,僅僅是被稱為“亂序”,實際上也遵循著一定規則:只要兩個指令之間不存在“數據依賴”,就可以對這兩個指令亂序。
CPU重排序包括兩類:指令級重排序和內存系統重排序。
* 指令級重排序
在不影響程序執行結果的情況下,CPU內核采用ILP(Instruction-Level Parallelism,指令級并行運算)技術來將多條指令重疊執行,主要是為了提升效率。如果指令之間不存在數據依賴性,CPU就可以改變語句的對應機器指令的執行順序,叫作指令級重排序。
* 內存系統重排序
對于現代的CPU來說,在CPU內核和主存之間都具備一個高速緩存,高速緩存的作用主要是減少CPU內核和主存的交互(CPU內核的處理速度要快得多),在CPU內核進行讀操作時,如果緩存沒有的話就從主存取,而對于寫操作都是先寫在緩存中,最后再一次性寫入主存。
由于處理器使用緩存和讀/寫緩沖區,這使得加載和存儲操作看上去可能是在亂序執行。
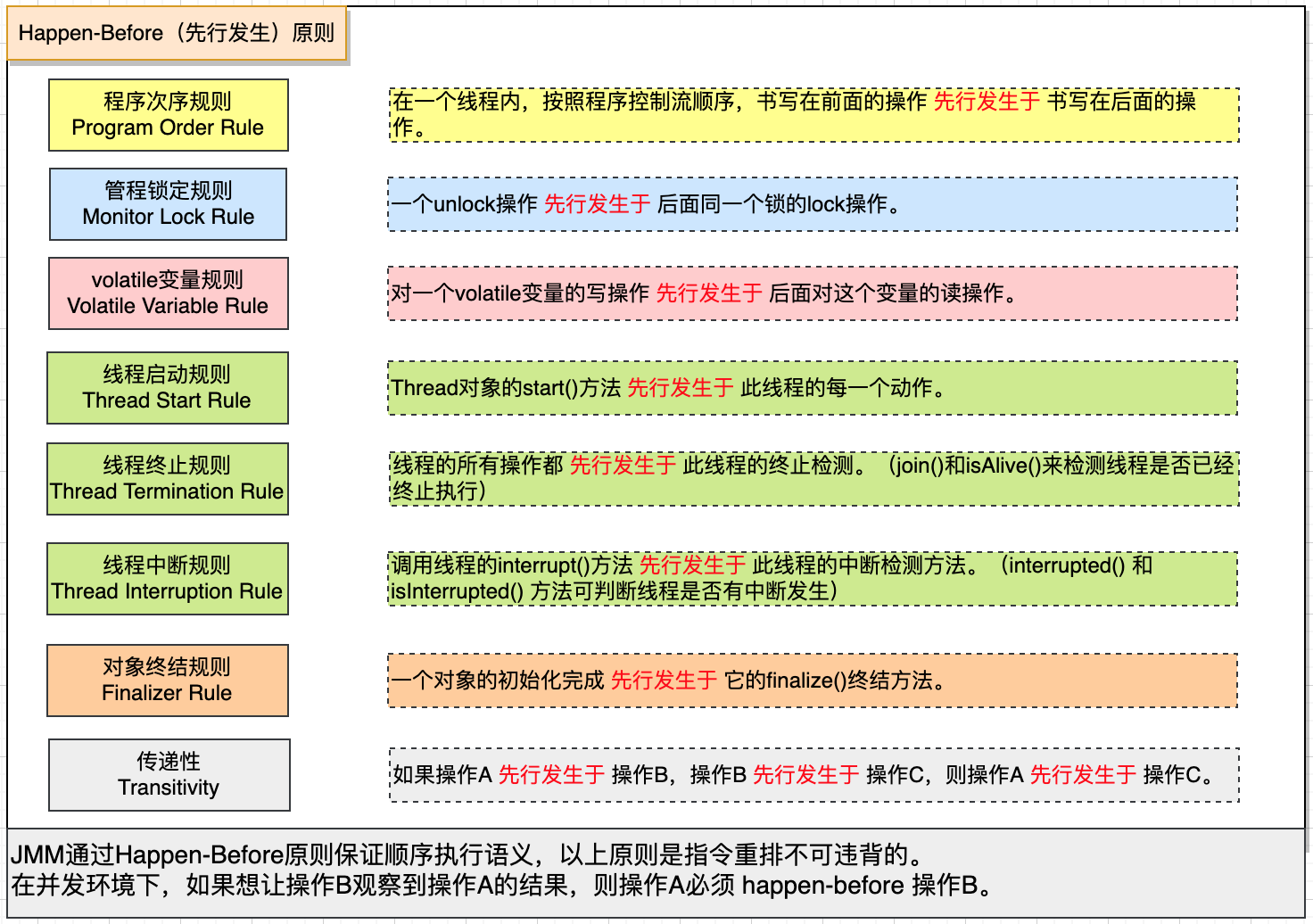
## 哪些指令不能重排:Happen-Before原則(先行發生)
## 參考文檔
* 書籍:葛一鳴 *《Java高并發程序設計第二版》
* 書籍:周志明 *《深入理解Java虛擬機》
- 面試突擊
- Java虛擬機
- 認識字節碼
- 000Java發展歷史
- 000Macos10.15.7上編譯OpenJDK8u
- 001熟悉Java內存區域
- 002熟悉HotSpot中的對象
- 003Java如何計算對象大小
- 004垃圾判定算法與4大引用
- 005回收堆和方法區中對象
- 006垃圾收集算法
- 007HotSpot虛擬機垃圾算法實現篇1
- 007HotSpot虛擬機垃圾算法實現篇2
- 007HotSpot虛擬機垃圾算法實現篇3
- 008垃圾收集器
- 009內存分配與回收策略
- 010Java虛擬機相關工具
- 011調優案例分析
- 012一次IDEA的啟動速度調優
- 013類文件Class的結構
- 014熟悉字節碼指令
- 015類加載機制(過程)
- 016類加載器
- IDEA的JVM參數
- Java基礎
- Java自動裝箱與拆箱
- Java基礎數據類型
- Java方法的參數傳遞
- Java并發
- 001走入并行的世界
- 002并行程序基礎
- 003熟悉Java內存模型JMM
- 004Java并發之volatile關鍵字
- 005線程池入門到精通
- 006Java多線程間的同步控制方法
- 007Java維基準測試框架JMH
- 008Java并發容器
- 009Java的線程實現
- 010Java關鍵字synchronized
- 011一些并行模式的熟悉
- 單例模式和不變模式
- 生產者消費者模式
- Future模式
- 012一些并行算法的熟悉
- 面試總結
- 長亮一面