
## 說明
匹配方式(匹配符)這個是規則配置的基礎,需要深入的理解,并融會貫通才可以配置出自己想要的規則
**對應匹配規則中第二個參數**
## 匹配符
這里就通過一些例子來讓大家對匹配符有更清楚的理解,這里關鍵的前提是 **能不用正則就不用!!!**
### 等于
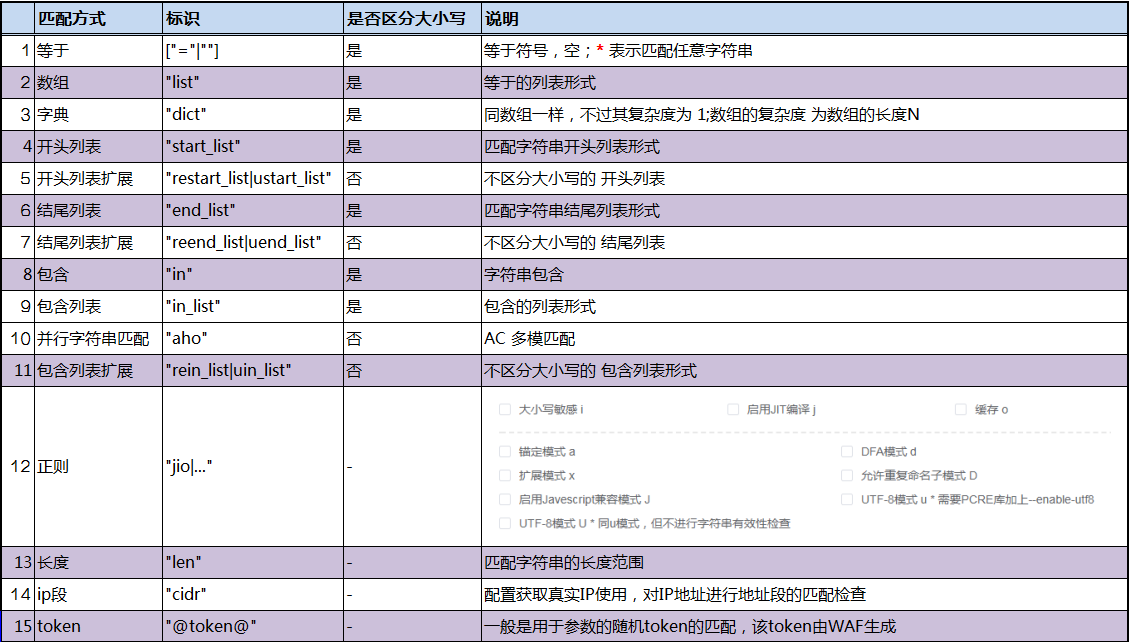
等于匹配是進行字符串的完全匹配,是區分大小寫的。
比如匹配域名時,匹配符選擇等于,如果我要匹配`www.abc.com`那邊就可以在內容處填寫該內容
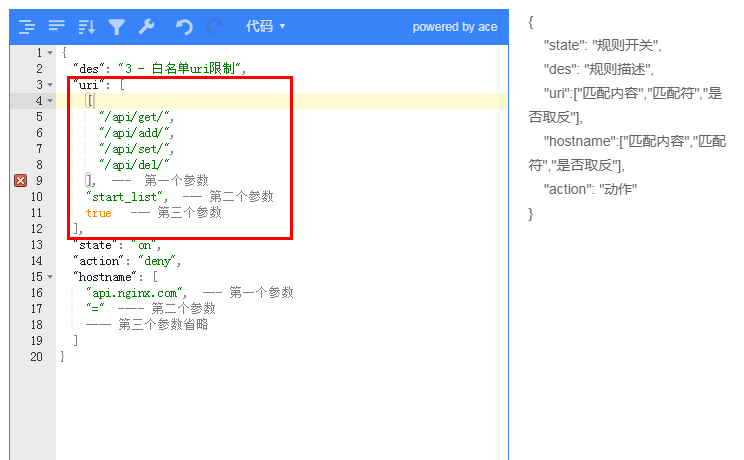
第一個參數就是配置的域名,第二個參數為空/或者 `=`,第三參數表示是否取反(可以省略不寫)
### 數組
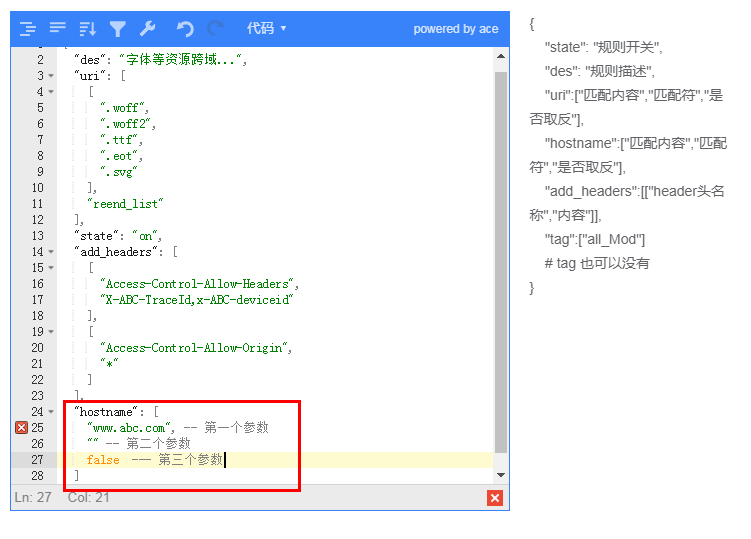
等于匹配時只有一個不夠用,當匹配多個相等的內容時,就可以使用數組(滿足數組中任何一個即為真)
當我們需要進行對接口進行白名單控制,不是我們允許的`uri` 就可以全部拒絕訪問,配合取反功能即可
```
域名 api.nginx.com 對外有4個 接口 uri
/api/get/some-msg
/api/add/some-msg
/api/set/some-msg
/api/del/some-msg
```
例子:在普通規則 --- uri 頁中可以這樣配置
### 字典
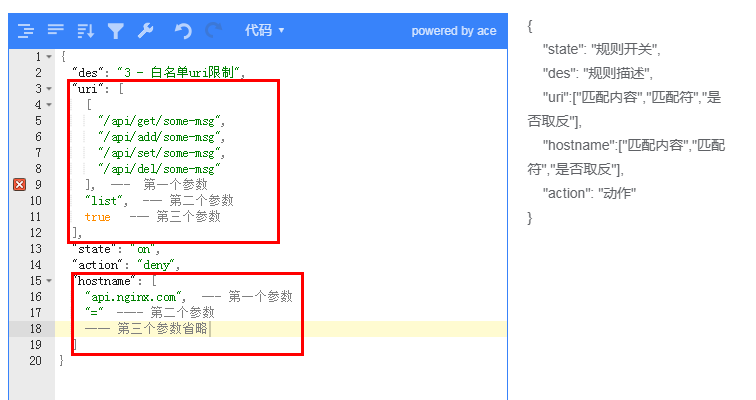
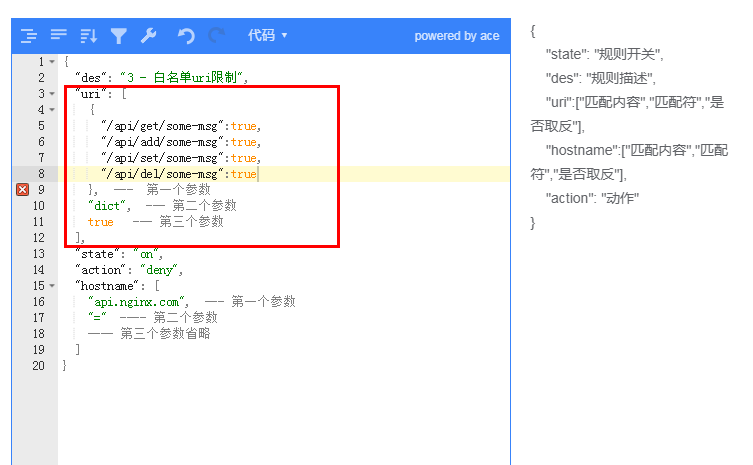
數組匹配時條目太多(超過500個)使用,和數組效果一樣,不過其空間復雜度為 1 ,效率更高,其有2個參數一個是匹配的內容,一個是布爾類型,真:表示匹配,假:表示不匹配
例子:實現和上面一樣的作用,使用字典來配置
### 開頭列表/開頭擴展列表
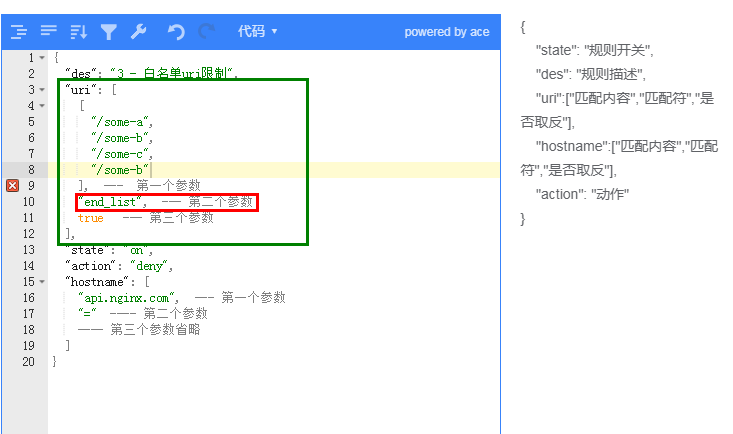
開頭列表:名字標記有些俗氣,但是非常好理解,就是匹配字符串開頭,且是一個數組(數組中任意一個匹配成功,即匹配命中)
開頭擴展列表:僅僅是不區分大小寫的開頭列表
```
當匹配一些 uri 時,我們只知道他們是以什么什么開頭的(區分大小寫),后面的 uri 是一些可變參數
/api/v1/sms/{tel}/status
/api/v2/aisp/{user-id}/msg
等等這樣的 uri 時
```
例子:實現上面類似的功能
### 結尾列表/結尾擴展列表
結尾列表,同樣俗氣的標記,就是匹配字符串的結尾,是個數組(數組中任意一個匹配成功,即匹配命中)
結尾擴展列表:僅僅是不區分大小寫的結尾列表
```
當一些域名 他們是 前綴不一樣,但是后面的字符串是完全一樣的,就可以使用該匹配符進行匹配
www1.nginx.com
img.nginx.com
static.nginx.com
05c12a287334386c94131ab8aa00d08a.cdn.nginx.com
7d6006e64eb59bcf40d8f8f31ff94ea9.ds.nginx.com
在包含時出現的域名,同樣也可以使用結尾列表匹配,且性能會高于 包含
```
舉例子:
### 包含
比如一些情況下,等于不能進行很好的匹配,但是我們需要匹配的`host`都包含一些關鍵字,就可以使用 包含
```
www1.nginx.com
img.nginx.com
static.nginx.com
05c12a287334386c94131ab8aa00d08a.cdn.nginx.com
7d6006e64eb59bcf40d8f8f31ff94ea9.ds.nginx.com
...
比如我們需要匹配這些域名,這些都包含了`nginx.com`,那么就可以使用包含來匹配這些域名
```
舉例子:
第二參數改成 in,第一個參數需要是字符串
### 多模匹配 (aho)
效果同包含列表,但是其性能是遠遠高于的,具體是使用了 aho 的算法,當匹配的字符串不是很多,很大時,可以不用該匹配方式
### 包含列表 / 包含擴展列表
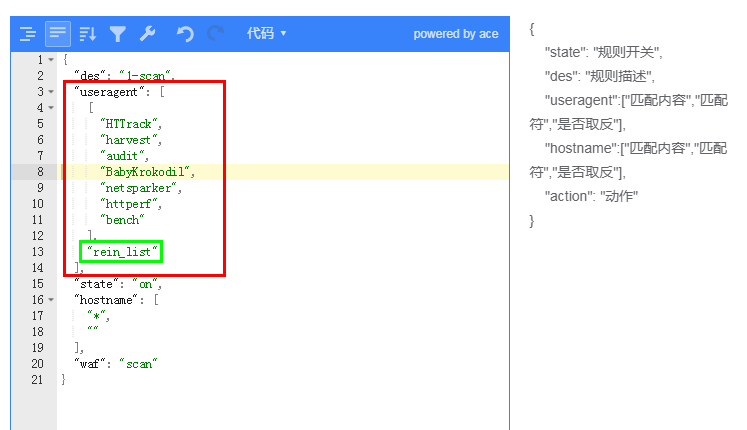
包含列表:包含的復數形式,當有多個字符串需要進行包含匹配時,是個數組(數組中任意一個匹配成功,即匹配命中)
包含擴展列表:僅僅是不區分大小寫的包含列表
一些掃描器,攻擊軟件在`useragent`處有一些特征,就可以使用包含/包含擴展列表進行匹配
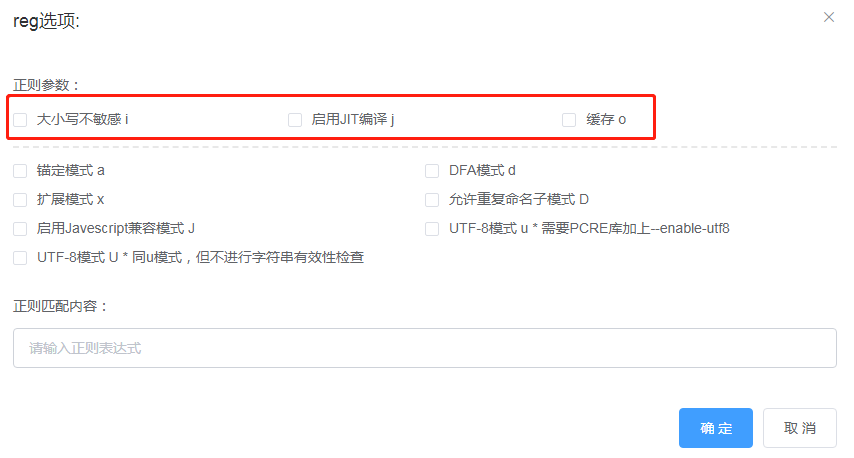
### 正則
正則是匹配中使用比較多的地方, 但是正則寫的不好,會對性能有非常大的影響,所以在前面就特別說明了,**能不用正則的就不用**。
正則匹配這里用到了 `luajit` 緩存 等一些優化特性,即便是這樣,正則的使用一定要仔細,看幾個例子吧
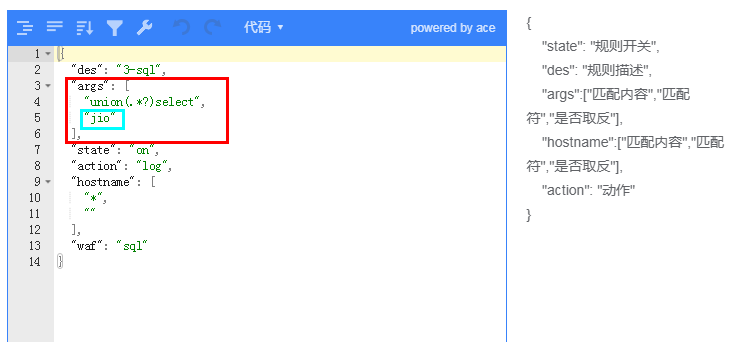
使用正則一定要進行匹配測試!!!
注:lujit 中特殊的優化特性(啟用JIT、緩存),看一下使用正則時的參數的說明
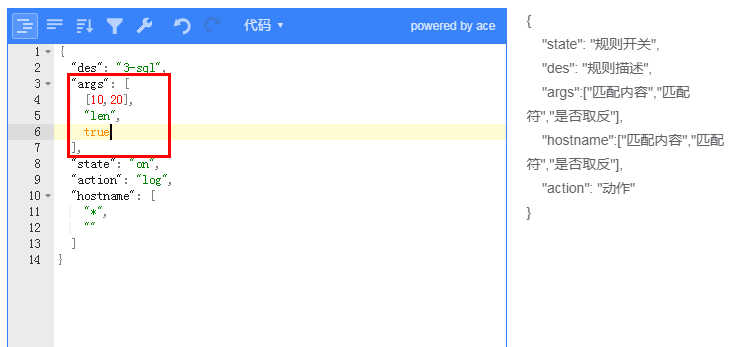
### 長度
長度比較好理解就是對字符串的長度進行匹配
```
一些 GET 請求參數 我們可以進行長度的控制,比如 userid ,其長度是 我們開發人員約定生成的(18位數字)
那么就可以使用一定規則進行匹配,不符合就可以攔截
```
例子:限制了所有query_string參數的值長度只能是10-20,不在這個范圍就都被攔截
### ip段
這里是ip段的匹配,用于匹配整個網段的ip
```
192.168.0.1/24 就可以匹配 ip 192.168.0.1 - 255
```
第二個參數為:cidr,第三個參數就是 tabel了
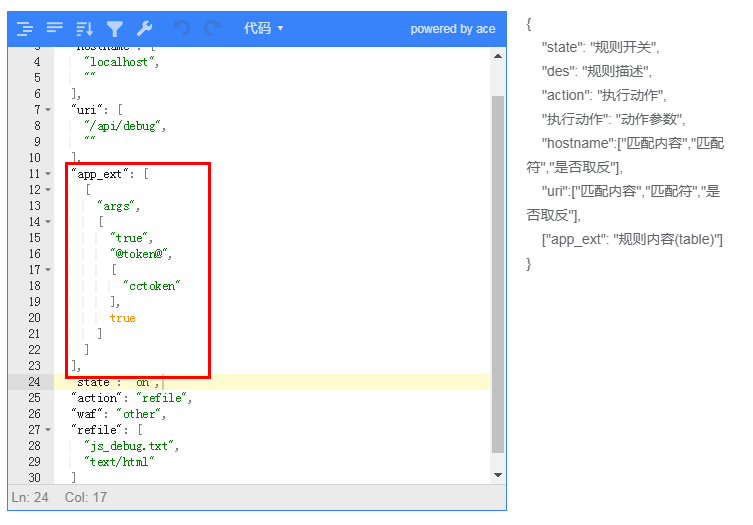
### token
token是特殊的匹配,token的匹配是WAF在內存中生成的一個隨機字符串,匹配則是判斷該字符串是否由WAF生成的,這樣應用場景一般是一些防護CC攻擊時使用
```
該條規則就是 訪問 uri = /api/debug 時,我們進行 GET 參數(cctoken) 進行匹配,匹配失敗則返回一個固定的文件內容
<html>
<head>
<script>
var Num="@token@";
var url = window.location.href;
var re = new RegExp("\\?","i");
var url = window.location.href;
if(re.test(url)){
window.location.href=url+"&cctoken="+Num;
}
else
{
window.location.href=url+"?&cctoken="+Num;
}
</script>
</head>
</html>
這是一個JS跳轉,跳轉的時候添加了一個 cctoken 的參數,其值為 @token@
注:WAF在返回 文件/字符串 時,會將 @token@ 替換為一個WAF 生成的隨機字符串
這樣配合 對參數 cctoken 進行 token 的檢查,這樣就可以實現一種 cc 防護了
```
- kcon 兵器譜
- 演示 1
- 演示 2
- 演示 3
- 演示 4
- 演示 5
- 前言
- 安裝
- 更新
- 登錄后臺
- 授權認證
- 集群配置
- 7層防護 -- 最佳實踐
- 匹配位置說明
- 匹配方式說明
- 規則匹配詳解
- 全局 - CDN規則
- 添加header頭配置
- 限速limit配置
- 緩存proxy_cache配置
- 清除緩存
- 全局 - 獲取真實IP配置
- 全局 - IP黑白名單
- 全局 - 域名方法配置(白名單)
- 全局 - 跳轉規則配置
- 全局 - 高級規則配置
- 全局 - 普通規則配置
- 全局 - 頻率規則配置
- 全局 - 內容替換規則
- 內容替換規則(插件使用)
- 全局 - 攔截信息配置
- 全局 - LOG規則配置
- 平臺配置
- 基本配置
- 高級配置
- 配置文件管理
- 4 層代理
- 轉發配置
- 插件管理
- 防護配置
- 網站管理
- 證書管理
- 域名管理
- 網站規則
- 插件管理
- 插件操作 --- 基本使用
- 插件操作 --- 手機號脫敏插件
- 歸檔
- 更新日志
- 視頻教程目錄