
# mysql 索引
## 一、BTree索引
> 官方定義:索引是一種幫助mysql提高查詢效率的排好序的**數據結構**。
mysql采用BTree的變種B+Tree作為索引的數據結構,下面就從BTree數據結構開始一步步的探究Mysql的索引究竟是什么東西?
### 1. BTree
Mysql采用BTree作為索引的數據結構,BTree也是一種樹結構,與二叉樹相比,其能有多個子節點。
> 那么Mysql為什么采用BTree作為索引的數據結構呢?而不是采用常見的紅黑樹或者平衡二叉樹?
答案就是:在數據庫表中有大量的記錄的情況下,我們無法一次性的將數據庫中一整表中的數據都讀入內存中,只能分開多次讀取磁盤,讀取的次數與數據的存儲結構的設計有關。BTree這種結構所具有的特性能夠很好的適應這種情況,也就是BTree的高度要遠遠低于平衡二叉樹或者紅黑樹,磁盤的讀寫IO次數更少(這在后面進行說明);可以這么說,BTree這種數據結構是針對磁盤讀寫而設計的。
#### 1.1 磁盤的結構
先來看看磁盤的結構

典型的物理磁盤一般有多個盤片組成,每個盤片一般都有上下兩個盤面,盤面表面覆蓋有一層可磁化的物質可以用來記錄數據。磁盤驅動器可以驅動磁臂來進行尋道,同時盤片可以高速旋轉到磁頭所在的位置,進而定位到一個要讀寫數據的位置。這個過程是機械化的過程,與電氣過程相比非常緩慢。一次磁盤的讀取時間一般可以分為:**尋道時間 + 旋轉延遲 + 傳輸時間**。傳輸時間屬于電氣過程,與另外兩個所花費的時間相比可以忽略不計。一般而言磁盤的平均讀寫時間為8-11ms,而主存的存取時間在50ns左右(參考《算法導論》)。因此一次磁盤的讀取周期,主存都能進行十幾萬次的存取了,速度相比是非常大的。
基于磁盤和主存之間的速度的差異性,為了不讓磁盤的讀取時間嚴重影響到整體的性能,一個重要的改進就是減少磁盤的讀取次數。BTree樹就是為此而誕生的。一棵BTree的類似結構如下:
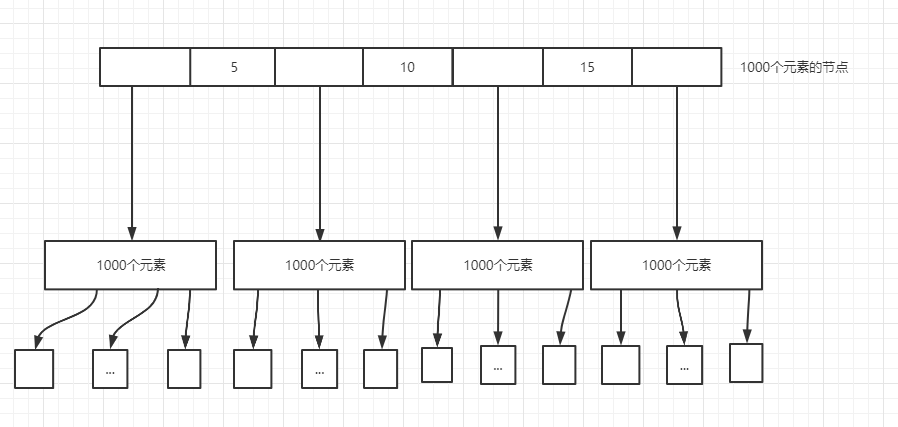
假定每個節點可以存放1000個索引,一個索引占4個字節,假設指向孩子節點的指針占6個字節(InnoDB引擎就是這么6個字節),則一個節點總共占1000 \* 4 + 1001 \* 6 ≈ 9.7kB;InnoDB的默認頁大小為**16KB**,所以一次IO磁盤讀寫將一個節點寫入(或寫出)主存是完全沒有問題的。對于這樣一棵高度為3的BTree,能夠存放的索引數量為 1000 \* 1 + 1000 \* 1001 + 1000 \* 1001 \* 1001 = 1,003,003,000,大約包含10億個索引數量(不考慮衛星數據)。而這只用進行2次磁盤讀寫(根節點一般常駐內存)就能夠找到一個索引的位置。如果是平衡二叉樹或者紅黑樹10億個節點的樹的高度可能就遠遠不止這么大了,要進行磁盤讀寫的次數也會隨之增加。
> 備注:
>
> 1. Mysql中的節點的指針就是為6個字節大小,猜測這應該和現在64位操作系統的48位的虛存尋址一樣,沒有找到對應的說明。
>
> 2. 現在操作系統的虛存頁的大小一般在2K~16K大小(Linux系統的為4KB),mysql的InnoDB存儲引擎給每個節點分配的索引頁分配的大小為:16KB,可以通過語句
>
> show global status like 'Innodb\_page\_size';查看具體的大小。
>
說了這么多下面先來看一下BTree的定義及相關操作的時間復雜度(不會涉及到具體的實現)
#### 1.2 BTree定義
假設:
1. 節點的衛星數據與節點存放在一起,這里的衛星數據可以是真正的數據,或者是存放數據對應的地址(通過這種方式區分出了聚簇索引和非聚簇索引)。
2. BTree的節點的最大度為M。
則一棵BTree需要滿足如下的性質:
* 根節點如果不是葉子節點,則至少有兩個子節點。
* 每個節點最多只有M個子節點。
* 每個除根外的非葉子結點至少有? M / 2?個子節點。
* 具有K個子節點的非葉子節點有K - 1個關鍵字,同時關鍵字按照**非遞減次序排序。**
* 節點的每個關鍵字都分割子節點的關鍵字的范圍,關鍵字左邊的子樹的所有關鍵字小于等于該關鍵字,右邊子樹的所有關鍵字大于該關鍵字。
* **所有的葉子都在同一層,是平衡的。**
**注意:對于一棵BTree進行先序遍歷將會得到非遞減的次序。**
#### 1.3 查找操作
跟二叉樹的查找類似,BTree的查找是多路的,其時間復雜度和BTree的高度有關,對于一棵有n個節點的BTree,其高度不超過
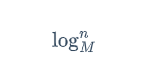
對于一棵“滿”的BTree的高度為logM(n)。因此其查找的時間復雜度為O(logM(n)),當節點的最大度M比較大的時候,樹的高度是非常小的(例如上面說的h=3的樹可以存放10億個關鍵字)。
#### 1.4 插入操作
BTree的插入操作只會在葉子結點中進行,如果插入之后節點的關鍵字數量不滿足BTree的要求,則會對節點進行分裂,即將該節點的關鍵字分為左右兩部分,將中間大小的關鍵字提升到父節點中,分類成兩個子節點;對于父節點也是做同樣的操作,不滿足的節點就進行回溯,直到分裂根節點。
這個過程也是和樹的高度相關,其時間復雜度為O(lgn)。
#### 1.5 刪除操作
如果要刪除的節點是葉子節點,則直接進行刪除,同時判斷父節點是否滿足BTree的要求,如果不滿足,則做跟插入操作做類似的分裂回溯操作使其滿足BTree的要求。
這個過程的時間復雜度也是為O(lgn)。
> 備注:關于BTree的插入和刪除操作是怎么維護BTree的性質的可以查看《算法導論》第18章。
>
> 參考博文:[https://www.cnblogs.com/lianzhilei/p/11250589.html](https://www.cnblogs.com/lianzhilei/p/11250589.html)
### 2\. B+Tree
在Mysql中并不是直接使用上面BTree的結構,而是使用其變種B+Tree。B+Tree與BTree的主要差別在于非葉子結點不存儲衛星數據,使得非葉子節點能夠存儲的索引數量盡可能的大,以此來壓縮樹的高度;**與此同時需要在葉子節點中備份存放非葉子節點的關鍵字及其衛星數據**,同時葉子節點之間使用雙向鏈表進行連接,這樣能夠**方便進行范圍查詢**。兩種結構的區別可如下圖:
BTree結構:
:-: 
B+Tree結構:

(上面圖片使用網站:[https://www.cs.usfca.edu/~galles/visualization/Algorithms.html](https://www.cs.usfca.edu/~galles/visualization/Algorithms.html)繪制)。
注意:與上圖B+Tree結構不同的是,Mysql中的葉子節點是使用**雙向鏈表**進行連接。
mysql中不同的存儲引擎的索引的具體結構還有些區別,具體區別在于衛星數據是否和索引放在一起,由此可以引出如下兩個概念:
* 聚簇索引:索引和對應的行數據存儲在一起。(InnoDB存儲引擎使用)
* 非聚餐索引:索引和對應的行數據分開存儲。(MyIsam存儲引擎使用)
> 備注:下面的實驗在mysql8中進行。
### 3\. 聚簇索引
也稱聚集索引。Mysql8之后默認使用的就是InnoDB存儲引擎,一般情況下使用的是聚簇索引,索引和行數據一起存儲,也稱為主鍵索引,InnoDB會為每張表創建一個主鍵索引(顯示或者是隱藏的)。例如在創建Student表時使用Innodb存儲引擎:
~~~
?create table student(
? ? sid int primary key auto_increment,
? ? name varchar(64),
? ? age int,
? ? grade varchar(32),
? ? sex char(2)
?);
~~~
創建成功之后可以看到在本地文件夾中生成了.idb的文件

這個文件中存放了表的索引及其行記錄的數據,同時也保存了表元數據,沒有在另外生成一個.sdi文件。
其索引結構的直觀感受如下:

【圖像來源網上】
對于其他的創建的索引,即輔助索引(非聚簇索引),會在葉子節點的衛星數據中存放該行記錄對應的主鍵值。如果SQL語句走的是輔助索引,則會先在輔助索引中找到對應行的主鍵,接著才去聚簇索引中尋找對應的數據(這個過程就稱為回表)。例如輔助索引的高度為3,聚簇索引的高度也為3,找到一行記錄需要6次的IO讀寫操作。因此一般而言查詢優化器會偏向于使用聚簇索引進行查找(我們書寫SQL語句時應該也一樣)。
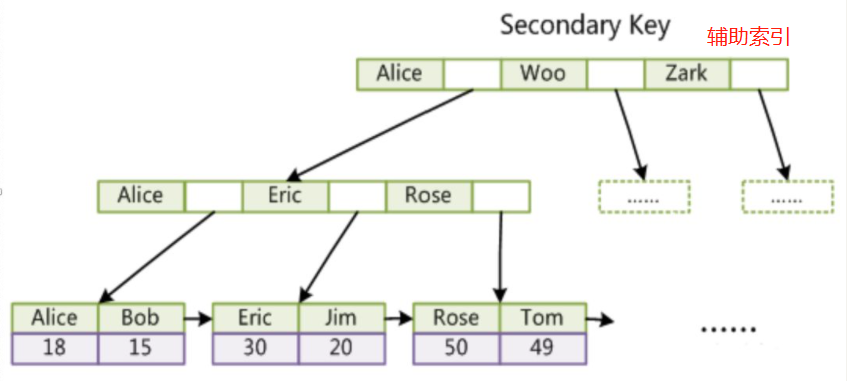
【圖像來源網上】
?? 可以認為在InnoDB中,除了聚簇索引(也就是主鍵索引),其他的索引全是輔助索引,這對理解InnoDB中索引樹的結構十分重要。即主鍵索引會和數據一起存放在葉子節點中,輔助索引的葉子節點存放輔助索引和其對應的主鍵。
### 4\. 非聚簇索引
也稱輔助索引,非聚集索引,是MyIsam存儲引擎使用的索引結構(當然InnoDB引擎非主鍵索引也是稱為非聚簇索引),區分聚簇索引與非聚簇的關鍵是,非聚簇索引和對應的行數據分開存儲,例如創建user表時指定MyIsam引擎:
~~~
?create table user(
? ? uid int primary key auto_increment,
? ? name varchar(64),
? ? age int,
? ? sex char(2)
?)engine=MYISAM;
~~~
創建成功之后可以到mysql的安裝目錄的**data**文件夾中找到user表所在的數據庫名稱對應的文件夾,可以發現生成了兩個如下文件:

生成了一個以.MYD結尾和一個以.MYI結尾的文件夾,從文件名也可以看出.myd文件就是存儲使用MyIsam引擎表的數據(MyIsam Data),而.myi就是存儲使用MyIsam引擎表的索引(MyIsam Index)。同時可以發現在我們剛創建的時候索引文件就是有數據的了(初始化B+Tree的結構),而數據文件因為還沒有插入任何數據,因此里面還沒有數據,為0KB。
~~~
?備注:mysql8之后再也沒有生產frm文件,對于由非innodb引擎建立的表會生成一個.sdi文件來存儲表結構的元數據。
~~~
MyIsam索引結構的直觀感受:
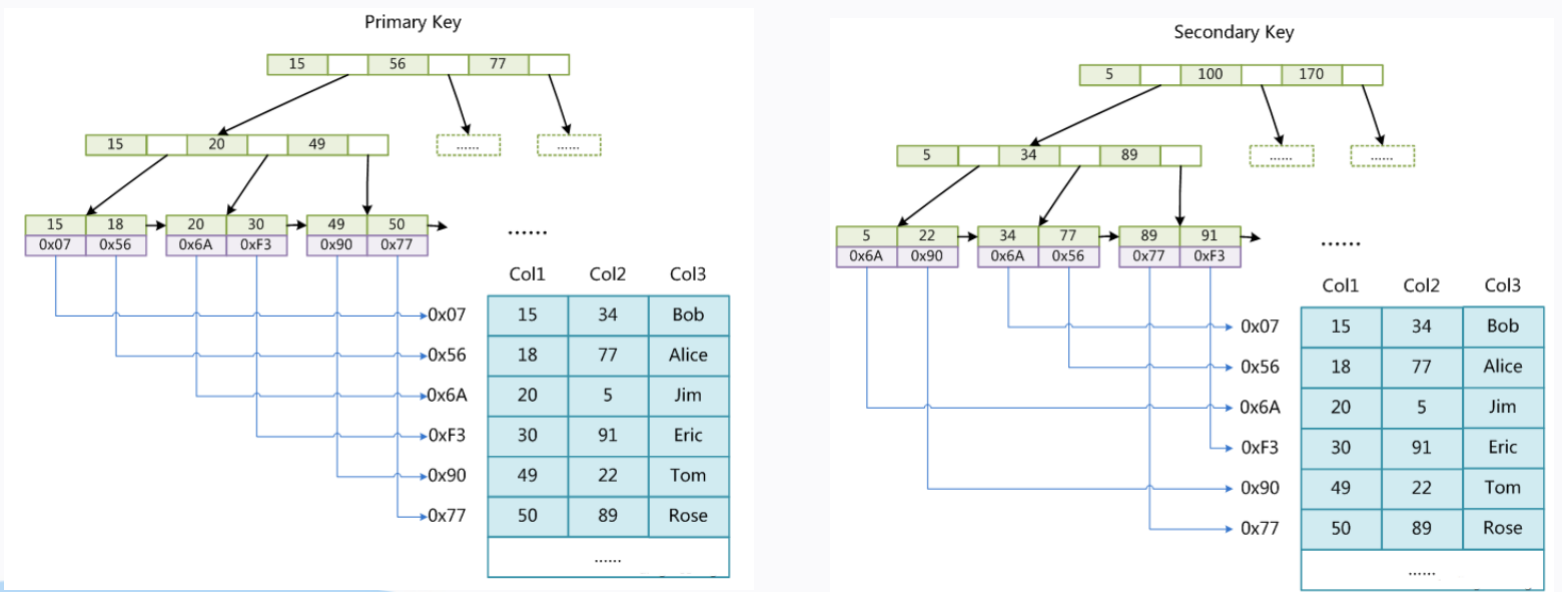
【圖像來源網上】
#### 4.1聯合索引
多個列作為索引,例如(name,age,position)作為聯合索引,在比較的時候按照定義索引時的屬性順序一個一個進行比較。聯合索引遵循`最左匹配原則`。一個查詢有沒有走索引可以用explain工具來查看。

只有第一條會走索引,下面兩條都不走索引。對于沒有用name的查詢條件(最左的查詢條件),會進行全表的掃描,因為最左邊的不同,不一定是有序的。
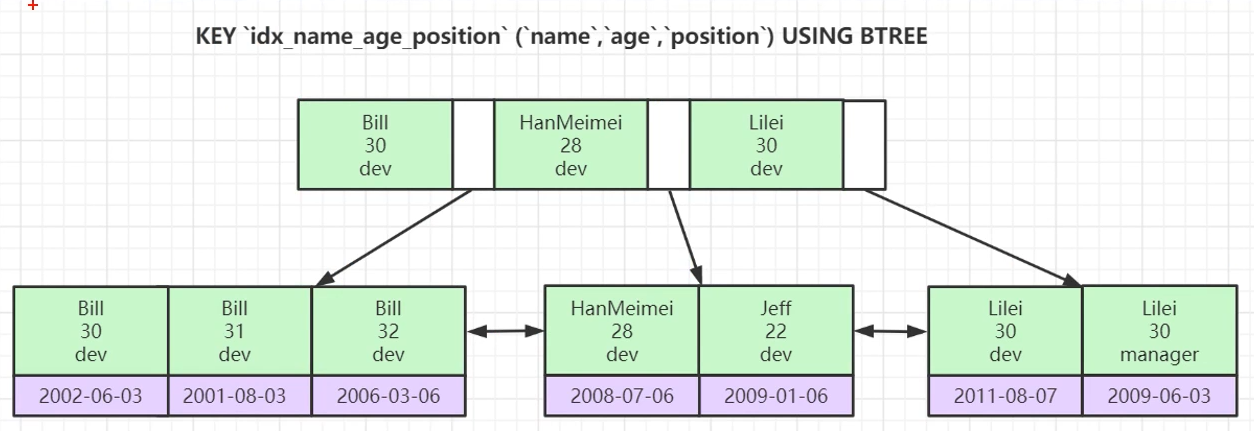
可以看到如果只是查詢age=30的話并不能按照索引的方式來順序查找,還是的全表掃描。
使用聯合索引的好處在于可以對多個索引列按照邏輯順序排好序,例如對于有一張表buy\_log,用來記錄用戶的購買日期,如下:
~~~
?create table buy_log(
? user_id int unsigned not null,
? ? buy_date DATE
?)ENGINE=InnoDB;
?insert into buy_log values(1, '2022-01-01');
?insert into buy_log values(2, '2022-01-01');
?insert into buy_log values(3, '2022-01-01');
?insert into buy_log values(1, '2022-02-01');
?insert into buy_log values(2, '2022-02-01');
?insert into buy_log values(3, '2022-02-01');
?insert into buy_log values(1, '2022-03-01');
?insert into buy_log values(1, '2022-04-01');
?# 創建兩個索引
?alter table buy_log add key(user_id);
?alter table buy_log add key(user_id, buy_date);
~~~
分別執行如下兩條語句可以得到下面的執行的執行計劃:
~~~
?mysql> explain select * from buy_log where user_id = 2\G;
?*************************** 1. row ***************************
? ? ? ? ? ? id: 1
? ?select_type: SIMPLE
? ? ? ? ?table: buy_log
? ? partitions: NULL
? ? ? ? ? type: ref
?possible_keys: user_id,user_id_2
? ? ? ? ? ?key: user_id_2
? ? ? ?key_len: 4
? ? ? ? ? ?ref: const
? ? ? ? ? rows: 2
? ? ? filtered: 100.00
? ? ? ? ?Extra: Using index
?1 row in set, 1 warning (0.00 sec)
??
??
?mysql> explain select * from buy_log where user_id = 1 ORDER BY buy_date\G;
?*************************** 1. row ***************************
? ? ? ? ? ? id: 1
? ?select_type: SIMPLE
? ? ? ? ?table: buy_log
? ? partitions: NULL
? ? ? ? ? type: ref
?possible_keys: user_id,user_id_2
? ? ? ? ? ?key: user_id_2
? ? ? ?key_len: 4
? ? ? ? ? ?ref: const
? ? ? ? ? rows: 4
? ? ? filtered: 100.00
? ? ? ? ?Extra: Using index
?1 row in set, 1 warning (0.00 sec)
~~~
PS:與《MYSQL技術內幕 InnoDB存儲引擎》不同的是,這兩條走的都是聯合索引。
#### 4.2 覆蓋索引
Covering index,或稱索引覆蓋。如果一個索引包含(覆蓋)所需要查詢的字段的值,我們就稱之為“覆蓋索引”。即從輔助索引中就可以得到要查詢的值,而不需要去聚簇索引中在查詢一遍。
對于一些執行統計的操作,執行優化器會偏向于執行覆蓋索引的操作。
例如:
~~~
?mysql> explain select count(*) from buy_log\G;
?*************************** 1. row ***************************
? ? ? ? ? ? id: 1
? ?select_type: SIMPLE
? ? ? ? ?table: buy_log
? ? partitions: NULL
? ? ? ? ? type: index
?possible_keys: NULL
? ? ? ? ? ?key: user_id
? ? ? ?key_len: 4
? ? ? ? ? ?ref: NULL
? ? ? ? ? rows: 8
? ? ? filtered: 100.00
? ? ? ? ?Extra: Using index
?1 row in set, 1 warning (0.00 sec)
??
?mysql> explain select count(*) from buy_log where buy_date >= '2022-01-01' and buy_date <= '2022-03-03'\G;
?*************************** 1. row ***************************
? ? ? ? ? ? id: 1
? ?select_type: SIMPLE
? ? ? ? ?table: buy_log
? ? partitions: NULL
? ? ? ? ? type: index
?possible_keys: user_id_2
? ? ? ? ? ?key: user_id_2
? ? ? ?key_len: 8
? ? ? ? ? ?ref: NULL
? ? ? ? ? rows: 8
? ? ? filtered: 12.50
? ? ? ? ?Extra: Using where; Using index
?1 row in set, 1 warning (0.00 sec)
~~~
對于單單buy\_date的查詢,一般都不會去走索引,但是在統計操作中,執行優化器會去走索引。
> 備注:使用explain執行器查看到的Extra字段的值為Using index就是走覆蓋索引。
#### 4.3 前綴索引
對于一些內容很長的列可以使用前綴索引,即選取該列的前面幾個字節作為索引,這種方式需要去判斷所選擇的字段的選擇性怎么樣。
## 二、哈希索引
### 1\. 哈希算法
InnoDB使用的哈希函數為除法散列的方式,同時使用鏈地址法來解決沖突。哈希表槽位m的選擇一般都會選擇一個比緩沖池頁中的數量大的2的倍數的一個質數。例如當緩沖池為128M時,共有8192個頁。對于哈希表來說就會分配接近8192 x 2=16384的一個質數。
### 2\. 哈希索引
哈希索引是基于哈希表實現的,只能用于等值查詢中,不能用于范圍查詢中。存儲引擎會通過哈希函數為表中的每行數據計算出一個哈希碼,在哈希表中保存這個哈希碼,同時保存指向該行數據的一個指針。
InnoDB存儲引擎不支持顯示的創建哈希索引,只有Memory引擎(基于內存的一個存儲引擎)顯示的支持哈希索引。InnoDB存儲引擎在注意到某些索引值使用非常頻繁的時候,就會在基于BTree索引之上創建一個哈希索引,以實現快速哈希查找。可以通過如下命令原則是否打開自適應哈希索引:
~~~
?set global innodb_adaptive_hash_index = off/on;
~~~
查看自適應哈希索引是否打開:
~~~
?show variables like '%ap%hash_index';
~~~
參考博文:[https://www.cnblogs.com/geaozhang/p/7252389.html](https://www.cnblogs.com/geaozhang/p/7252389.html)
### 3\. 自定義哈希索引
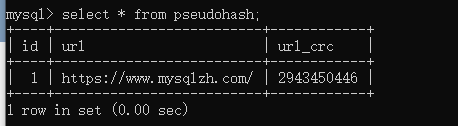
可以自定義一個偽哈希索引來達到哈希索引的目的,當原始要索引的列的值很長的時候就可以對該值使用CRC32()函數生成一個32位的整數值索引。這樣索引占用的空間就大大減少了,每頁可以放下更多的節點。
下面的例子使用觸發器來自動維護哈希索引的創建:
~~~
?# 創建表,id、url、url_crc,其中url_crc表示經過CRC32()函數加工后的索引值。
?create table pseudohash(
? id int unsigned not null auto_increment,
? ? url varchar(255) not null,
? ? url_crc int unsigned not null default 0,
? ? ?primary key(id),key(url_crc)
?);
~~~
創建插入和更新觸發器;
~~~
?delimiter //
?create trigger pseudohash_crc_insert before insert on pseudohash for each row
? ? begin
? ? set new.url_crc=crc32(new.url);
? ? end;
? ? //
?create trigger pseudohash_crc_update before update on pseudohash for each row
? ? begin
? ? set new.url_crc=crc32(new.url);
? ? end;
? ? //
?delimiter ;
~~~
插入新的url
~~~
?insert into pseudohash (url) values('http://www.mysql.com');
~~~
:-: 
更新url
~~~
?update pseudohash set url = 'https://www.mysqlzh.com/' where id=1;
~~~
:-: 
當然查詢的時候需要添加對url添加上crc32函數進行查詢:
~~~
?select * from pseudohash where url_crc = crc32('https://www.mysqlzh.com/');
~~~
:-: 
為了避免哈希沖突,一般都會加上對應的被哈希的列的值
~~~
?select * from pseudohash where url_crc = crc32('https://www.mysqlzh.com/')
? AND url='https://www.mysqlzh.com/';
~~~
## 三、全文索引
可以用于在數據庫中查找文本中的關鍵詞,常用于文章的檢索、商品詳情的檢索等。
## 四、mysql索引的管理
1. 創建主鍵索引,隨表建立的時候一起建立。
~~~
?create table employee(
? employee_ID int primary key
?);
~~~
2. 創建普通索引
在創建表的時候一起創建
~~~
?create table employee(
? employee_ID int primary key,
? ? empoyee_name varchar(32),
? ? ?key (employee_name)
?);
??
~~~
這種方式建立的列名和索引名字一致;
創建表之后指定索引
~~~
?create index index_name on table_name(column);
~~~
3. 創建唯一索引
在建表的時候一起創建
~~~
?create table employee(
? employee_ID int primary key,
? ? name varchar(32),
? ? company_name varchar(32),
? ? ?key(name),
? ? ?unique(company_name)
?);
~~~
創建表之后建立
~~~
?create unique index index_name on table_name(column);
~~~
4. 創建聯合索引
在建表的時候一起創建
~~~
?create table employee(
? employee_ID int primary key,
? ? name varchar(32),
? ? company_name varchar(32),
? ? ?key(name, company_name)
?);
~~~
5. 對列的一部分數據進行索引,例如一個表test中有某個列的定義如下:name varchar(1000);則對這個列的前100個字段添加索引可如下:
~~~
?alter table test add key idx_name (name(100))
~~~
5. 刪除索引
~~~
?drop index index_name on table_name;
~~~
6. 查看表的索引
~~~
?show index from table;
~~~
:-: 
## 五、Explain使用
Explain工具可以幫助查看查詢執行計劃的信息,一般而言Mysql最終就會根據執行計劃的信息執行查詢語句。可以通過Explain執行計劃來判斷一條查詢的SQL語句究竟有沒有走索引,以此來寫出更好SQL語句來。
使用方式為在select之前加上explain關鍵字,例如
~~~sql
explain select * from user where id = 1;
~~~
explain的輸出為每一個select語句輸出一行。
### Explain列
1. id:select的編號,如果沒有子查詢或者其他連結操作,id=1。
2. select_type:對應行是簡單的select還是復雜的select。可能的值為:primary,如果有復雜的子查詢,則最外層標識為primary。union,標識聯合的查詢。
3. table:訪問的表名或者表的別名。
4. type:select訪問表的類型,指示mysql如何查找表中的行。最差到最優的可能的值為:
**ALL**,全表掃描。
**index**,與ALL類似,但是掃描的是索引數據,通常Extra列中會顯示“Using index”。**range**,范圍上的索引掃描,通常出現在帶有between或者大于號的查詢語句中。**ref**,使用非唯一索引時發生,主要用在等值的條件判斷中,同時返回值可能有多行數據。
**equ_ref**,最多返回一條符合條件的記錄。
**const**,對查詢的某部分進行優化并將其轉化成一個常量時會使用。
**NULL**,Mysql提前優化,執行階段甚至不用再訪問表或者索引。
5. possible_keys:可能使用哪些索引,不一定會用。
6. Key:執行時真正使用的索引。
7. key_len:索引的字節長度。
8. ref:使用的索引的列。
9. rows:估計要找到行所需要讀取的行數,并不一定精確。
10. Extra:額外信息。可能的值有:
**Using index**,使用覆蓋索引。
**Using where**,檢索出行后再進行行過濾。
**Using filesort**,不管是內存中完成排序還是再磁盤中完成排序都會顯示這個值。
## 六、索引優化
1. Cardinality值
在使用語句`show index from table\G;`中可以查看到有一列Cardinality的值

Cardinality值可以用來表示索引中不重復記錄數量的估計值。該值可以用于判斷一個列是否具有高選擇性,即其是否應該創建索引。該列的值除于表中的行數應該盡可能的接近1。如果該值過低要考慮是否去掉該列上的索引。
使用`analyze table\G;`可以更新表中所以的Cardinality的值,但是這個過程對于大表需要時間比較就,需要在系統停止服務的時候使用。
【參考】
1. 《Mysql高性能》
2. 《Mysql技術內幕 InnoDB存儲引擎》
- 第一章 Java基礎
- ThreadLocal
- Java異常體系
- Java集合框架
- List接口及其實現類
- Queue接口及其實現類
- Set接口及其實現類
- Map接口及其實現類
- JDK1.8新特性
- Lambda表達式
- 常用函數式接口
- stream流
- 面試
- 第二章 Java虛擬機
- 第一節、運行時數據區
- 第二節、垃圾回收
- 第三節、類加載機制
- 第四節、類文件與字節碼指令
- 第五節、語法糖
- 第六節、運行期優化
- 面試常見問題
- 第三章 并發編程
- 第一節、Java中的線程
- 第二節、Java中的鎖
- 第三節、線程池
- 第四節、并發工具類
- AQS
- 第四章 網絡編程
- WebSocket協議
- Netty
- Netty入門
- Netty-自定義協議
- 面試題
- IO
- 網絡IO模型
- 第五章 操作系統
- IO
- 文件系統的相關概念
- Java幾種文件讀寫方式性能對比
- Socket
- 內存管理
- 進程、線程、協程
- IO模型的演化過程
- 第六章 計算機網絡
- 第七章 消息隊列
- RabbitMQ
- 第八章 開發框架
- Spring
- Spring事務
- Spring MVC
- Spring Boot
- Mybatis
- Mybatis-Plus
- Shiro
- 第九章 數據庫
- Mysql
- Mysql中的索引
- Mysql中的鎖
- 面試常見問題
- Mysql中的日志
- InnoDB存儲引擎
- 事務
- Redis
- redis的數據類型
- redis數據結構
- Redis主從復制
- 哨兵模式
- 面試題
- Spring Boot整合Lettuce+Redisson實現布隆過濾器
- 集群
- Redis網絡IO模型
- 第十章 設計模式
- 設計模式-七大原則
- 設計模式-單例模式
- 設計模式-備忘錄模式
- 設計模式-原型模式
- 設計模式-責任鏈模式
- 設計模式-過濾模式
- 設計模式-觀察者模式
- 設計模式-工廠方法模式
- 設計模式-抽象工廠模式
- 設計模式-代理模式
- 第十一章 后端開發常用工具、庫
- Docker
- Docker安裝Mysql
- 第十二章 中間件
- ZooKeeper