
# Zookeeper
概述:
1. ZooKeeper 是 Apache 軟件基金會的一個軟件項目,它為大型分布式計算提供開源的`分布式配置服務`、同步服務和命名注冊。其架構通過冗余服務實現高可用性。
2. Zookeeper 的設計目標是將那些復雜且容易出錯的分布式一致性服務封裝起來,構成一個高效可靠的原語集,并以一系列簡單易用的接口提供給用戶使用。
3. Zookeeper的數據保存在內存中,性能高,可以實現高吞吐量和低延遲量。
4. ZooKeeper可以用于解決分布式數據一致性的問題,常用在數據發布/訂閱、負載均衡、命名服務、集群管理、Master選舉、`分布式鎖`、`分布式配置服務`和分布式隊列等功能中。
**總之:Zookeeper提供分布式協調服務。**
## 理論補充
**CAP理論**
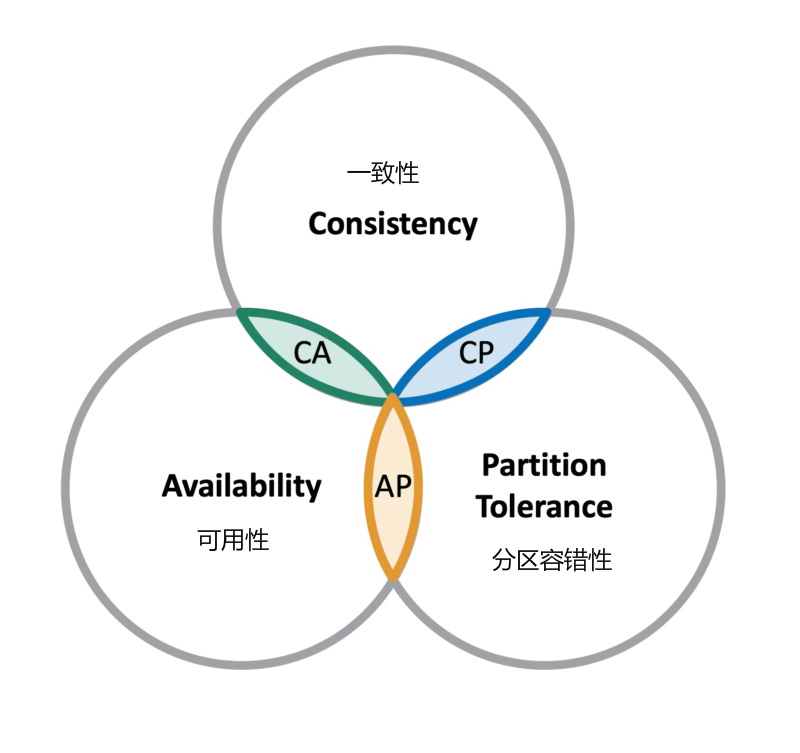
CAP 理論指出對于一個分布式計算系統來說,不可能同時滿足以下三點:
* **一致性**:Consistency 在分布式環境中,一致性是指數據在多個副本之間能夠保持一致的特性,等同于所有節點訪問`同一份最新的`數據副本。在一致性的需求下,當一個系統在數據一致的狀態下執行更新操作后,應該保證系統的數據仍然處于一致的狀態。
* **可用性**:Availability 每次請求都能獲取到正確的響應,但是不保證獲取的數據為最新數據。
* **分區容錯性**:Partition Tolerance 分布式系統在遇到任何網絡分區故障的時候,仍然需要能夠保證對外提供滿足一致性和可用性的服務,除非是整個網絡環境都發生了故障。
一個分布式系統最多只能同時滿足一致性(Consistency)、可用性(Availability)和分區容錯性(Partition tolerance)這三項中的兩項。
在這三個基本需求中,最多只能同時滿足其中的兩項,P 是必須的,因此只能在 CP 和 AP 中選擇,`zookeeper 保證的是 CP`,更準確講ZooKeeper會實現最終的一致性,但是并不能保證強一致性;對比 spring cloud 系統中的注冊中心 `eruka 實現的是 AP`。
**BASE理論**
BASE 是 Basically Available(基本可用)、Soft-state(軟狀態) 和 Eventually Consistent(最終一致性) 三個短語的縮寫。
* **基本可用**:在分布式系統出現故障,允許損失部分可用性(服務降級、頁面降級)。
* **軟狀態**:允許分布式系統出現中間狀態。而且中間狀態不影響系統的可用性。這里的中間狀態是指不同的 data replication(數據備份節點)之間的數據更新可以出現延時的最終一致性。
* **最終一致性**:data replications 經過一段時間達到一致性。
BASE 理論是對 CAP 中的一致性和可用性進行一個權衡的結果,理論的核心思想就是:`我們無法做到強一致,但每個應用都可以根據自身的業務特點,采用適當的方式來使系統達到最終一致性。`ZooKeeper可以實現系統的最終一致性。
## 安裝
## 安裝
1. Linux的話去[官網](https://zookeeper.apache.org/releases.html)找到最新的穩定版本的下載路徑
:-: 
注意下載下來的要帶有bin命名的才是打包好的。
2. Linux中創建文件夾下載安裝包
~~~
?wget https://dlcdn.apache.org/zookeeper/zookeeper-3.6.3/apache-zookeeper-3.6.3-bin.tar.gz
~~~
在下載目錄中解壓
~~~
?tar -zxvf apache-zookeeper-3.6.3-bin.tar.gz
~~~
3. 復制配置文件,在安裝目錄的conf目錄下
~~~
?cp zoo_camp.cfg zoo.cfg
~~~
zoo.cfg是zookeeper的默認啟動配置文件
3. 配置bin環境
~~~
?vim /etc/profile
??
?# 添加上如下內容
?export ZOOKEEPER_HOME=/下載目錄/apache-zookeeper-3.6.3-bin
?export PATH=$ZOOKEEPER_HOME/bin:$PATH
?
?# 使其生效
?source /etc/profile
~~~
最好是保證JDK在profile中配置了!
4. 打開Zookeeper服務
:-: 
如果不能正確啟動成功,有很大的可能是JDK的問題,注意查看JDK是否已經配置了環境變量了。
### 集群搭建
ZooKeeper一般都會搭建集群來使用,當然使用單機也行,但是這樣就不能很好的發揮其高可用的特性了。ZooKeeper需要至少3臺服務器形成一個集群。
1. 準備至少三臺服務器(由于ZooKeeper的Leader選舉至少要過半才能通過,因此ZooKeeper的集群至少要三臺服務器才行)。
2. 在各個服務器中安裝相同的ZooKeeper版本。并修改`/etc/profile`,將ZooKeeper的相關命令添加到環境變量中。同時要確保服務器中至少安裝了JDK1.8+。
:-: 
3. 修改每臺服務器的ZooKeeper的配置文件,在配置文件的末尾添加上類似如下內容:
:-: 
及其書寫格式為:
~~~
?server.myid=ip:2888:3888
~~~
2888集群內各臺機器之間通信使用,3888用于投票選舉時使用。
4. 每臺服務器創建myid文件,需要創建在zoo.cfg配置文件`dataDir`目錄下的;假如這里dataDir=/var/zookeeper,則可以通過如下命令創建myid文件,設置每臺服務器的myid
~~~
?echo 1 > /tmp/zookeeper/myid
~~~
'1'表示的就是該服務器的myid,需要和配置文件中server.myid配置的相對應。
5. 啟動各臺服務器的zkServer.sh。
~~~
# 前臺啟動
zkServer.sh start-foreground
# 后臺啟動
zkServer.sh start
~~~
可以使用命令`zkServer.sh status`查看哪臺服務器是Leader節點。
## 相關元素
1. 架構

* Client
客戶端,分布式應用集群中的一個節點,從ZooKeeper服務器訪問信息。客戶端和ZooKeeper服務器之間會維持心跳連接。
* Server
服務器,ZooKeeper集群中的一個節點,為客戶端提供所有的服務。在客戶端連接的時候,客戶端發送確認碼以告知服務器是活躍的。
* Ensemble
ZooKeeper服務器組。形成ensemble所需的最小節點數為3。
* Leader
Zookeeper是主從集群,和Reids類似。Leader表示中心節點,在集群啟動的時候被選舉。如果集群中Leader服務宕機了,則執行自動選舉過程。注意增刪改只能發送在Leader中,查詢可以發生在其他節點中。
當Leader 節點宕機的時候,官方的壓測給出了大約在200ms左右可以選舉一個新的節點作為leader節點。即從不可用狀態恢復到可用狀態大約需要200ms。
* Follower
ZooKeeper集群的節點之一,屬于Leader節點的從節點,可以給客戶端提供查詢功能;每個Follower節點在Leader宕機的時候都有機會被選擇成新的Leader的。
2. 層次命名空間
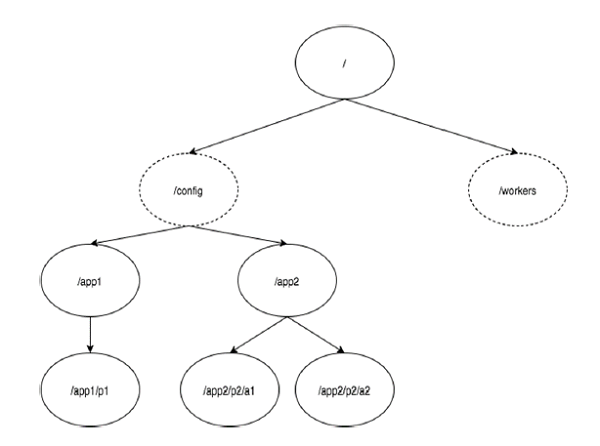
下圖描述了用于內存表示的ZooKeeper文件系統的`樹結構`。ZooKeeper節點稱為 **znode** 。每個znode由一個名稱標識,并用路徑(/)序列分隔。
* 在圖中,首先有一個由“/”分隔的znode。在根目錄下,兩個邏輯命名空間 **config** 和 **workers** 。
* **config** 命名空間用于集中式配置管理,**workers** 命名空間用于命名。
* 在 **config** 命名空間下,每個znode最多可存儲1MB的數據。這種結構的主要目的是存儲同步數據并描述znode的元數據。此結構稱為 **ZooKeeper數據模型**。
Znode兼具文件和目錄兩種特點。既像文件一樣維護著*數據長度、元信息、ACL、時間戳*等數據結構,又像目錄一樣可以作為路徑標識的一部分。每個Znode由三個部分組成:
* **stat**:此為狀態信息,描述該Znode版本、權限等信息。
* **data**:與該Znode關聯的數據。
* c**hildren**:該Znode下的節點。
其他信息:
* **版本號** - 每個znode都有版本號,這意味著每當與znode相關聯的數據發生變化時,其對應的版本號也會增加。當多個zookeeper客戶端嘗試在同一znode上執行操作時,版本號的使用就很重要。
* **操作控制列表(ACL)** - ACL基本上是訪問znode的認證機制。管理所有znode讀取和寫入操作。
* **時間戳** - 時間戳表示創建和修改znode所經過的時間。通常以毫秒為單位。ZooKeeper從“事務ID"(zxid)標識znode的每個更改。**Zxid** 是唯一的,并且為每個事務保留時間,可以輕松地確定從一個請求到另一個請求所經過的時間。
* **數據長度** - 存儲在znode中的數據總量是數據長度。最多可以存儲1MB的數據。
3. Znode的類型
Znode分為持久(persistent)節點,順序(sequential)節點和臨時(ephemeral)節點。
* **持久節點**
即使在創建該特定znode的客戶端斷開連接后,持久節點仍然存在。默認情況下,除非另有說明,否則所有znode都是持久的。大小為1MB。
* **臨時節點**
客戶端活躍時,臨時節點就是有效的。當客戶端與ZooKeeper集群的連接斷開時,臨時節點會自動刪除。因此,只有臨時節點不允許有子節點。如果臨時節點被刪除,則下一個合適的節點將填充其位置。臨時節點在leader選舉中起著重要作用。也可以用于Redis中的分布式鎖。
* **順序節點**
順序節點可以是持久的或臨時的。當一個新的znode被創建為一個順序節點時,ZooKeeper通過將10位的序列號附加到原始名稱來設置znode的路徑。
例如,如果將具有路徑 **/myapp** 的znode創建為順序節點,則ZooKeeper會將路徑更改為 **/myapp0000000001** ,并將下一個序列號設置為0000000002。如果兩個順序節點是同時創建的,那么ZooKeeper不會對每個znode使用相同的數字。順序節點在鎖定和同步中起重要作用。

4. Sessions(會話)
會話對于ZooKeeper的操作非常重要。會話中的請求按FIFO順序執行。一旦客戶端連接到服務器,將建立會話并向客戶端分配**會話ID** 。
客戶端以特定的時間間隔發送**心跳**以保持會話有效。如果ZooKeeper集合在超過服務器開啟時指定的期間(會話超時)都沒有從客戶端接收到心跳,則它會判定客戶端死機。
會話超時通常以毫秒為單位。當會話由于任何原因結束時,在該會話期間創建的臨時節點也會被刪除。
5. Watches(監視)
監視是一種簡單的機制,使客戶端收到關于ZooKeeper中znode的更改的通知。客戶端可以在讀取特定znode時設置Watches。Watches會向注冊的客戶端發送任何znode(客戶端注冊表)更改的通知。
Znode更改是與znode相關的數據的修改或znode的子項中的更改。只觸發一次watches。如果客戶端想要再次通知,則必須通過另一個讀取操作來完成。當連接會話過期時,客戶端將與服務器斷開連接,相關的watches也將被刪除。
## 客戶端使用
### 常用命令
1. 查看目錄下的zNode
~~~
?ls [-s] [-w] [-R] path
~~~
2. 創建節點
~~~
?create [-s] [-e] path data
??
?# 例如:創建aabb節點
?create /aabb "hello world"
~~~
選項說明:
* \-s:創建序列化節點,節點名稱相同時數據不會覆蓋,會自動添加個版本號。可以使每個客戶端都有自己的一個同名節點。序列化數字由leader維護,會一直遞增。可以用于并發的場景中。
例如:
~~~
?[zk: localhost:2181(CONNECTED) 9] create /aabb -s "01"
?Created /aabb0000000001
?[zk: localhost:2181(CONNECTED) 10] create /aabb -s "02"
?Created /aabb0000000002
?[zk: localhost:2181(CONNECTED) 11] ls /
?[aabb0000000001, aabb0000000002, test, zookeeper]
~~~
* \-e:創建臨時節點。
3. 獲取節點的數據
~~~
?get [-s] [-w] path
~~~
選項說明:
* \-s:獲取節點的詳細數據,包括元數據
~~~
?[zk: localhost:2181(CONNECTED) 15] get -s /test
?hello world ?# data內容
?cZxid = 0x2
?ctime = Mon Jan 17 11:05:13 HKT 2022
?mZxid = 0x2
?mtime = Mon Jan 17 11:05:13 HKT 2022
?pZxid = 0x2
?cversion = 0
?dataVersion = 0
?aclVersion = 0
?ephemeralOwner = 0x0
?dataLength = 11
?numChildren = 0
~~~
cZxid:創建事務id,64位,由Leader節點維護。
mZxid:修改的事務id。
pZxid:最后一個節點創建的事務id。
ephemeralOwner:session id,用于臨時節點。創建節點的時候可以使用-e選項。
* \-w:只獲取data的內容。
### API使用
1. 導入依賴
~~~
?<dependency>
? ? ?<groupId>org.apache.zookeeper</groupId>
? ? ?<artifactId>zookeeper</artifactId>
? ? ?<version>3.6.3</version>
?</dependency>
~~~
注意要和集群的版本一致。
2. 創建ZooKeeper對象
~~~
?final CountDownLatch countDownLatch = new CountDownLatch(1);
?ZooKeeper zk = new ZooKeeper("103.118.42.131:2181", 3000, watchedEvent -> {
? ? ?System.out.println("new zk watch:" + watchedEvent);
? ? ?Watcher.Event.KeeperState state = watchedEvent.getState();
? ? ?Watcher.Event.EventType type = watchedEvent.getType();
? ? ?String path = watchedEvent.getPath();
? ? ?System.out.println("path:" + path);
? ? ?// 連接狀態的監控
? ? ?switch (state) {
? ? ? ? ?case Unknown:
? ? ? ? ?case NoSyncConnected:
? ? ? ? ? ? ?break;
? ? ? ? ?case Disconnected:
? ? ? ? ? ? ?System.out.println("disconnected...");
? ? ? ? ? ? ?break;
? ? ? ? ?case SyncConnected:
? ? ? ? ? ? ?System.out.println("SyncConnected...");
? ? ? ? ? ? ?countDownLatch.countDown();
? ? ? ? ? ? ?break;
? ? ? ? ?case AuthFailed:
? ? ? ? ? ? ?break;
? ? ? ? ?case ConnectedReadOnly:
? ? ? ? ? ? ?break;
? ? ? ? ?case SaslAuthenticated:
? ? ? ? ? ? ?break;
? ? ? ? ?case Expired:
? ? ? ? ? ? ?break;
? ? ? ? ?case Closed:
? ? ? ? ? ? ?System.out.println("closed...");
? ? ? ? ? ? ?break;
? ? ? ? ?default:
? ? ? ? ? ? ?break;
? ? }
??
? ? ?// 節點的相關狀態
? ? ?switch (type) {
? ? ? ? ?case None:
? ? ? ? ? ? ?break;
? ? ? ? ?case NodeCreated:
? ? ? ? ? ? ?System.out.println("NodeCreated...");
? ? ? ? ? ? ?break;
? ? ? ? ?case NodeDeleted:
? ? ? ? ? ? ?System.out.println("NodeDeleted...");
? ? ? ? ? ? ?break;
? ? ? ? ?case NodeDataChanged:
? ? ? ? ? ? ?System.out.println("NodeDataChanged...");
? ? ? ? ? ? ?break;
? ? ? ? ?case NodeChildrenChanged:
? ? ? ? ? ? ?System.out.println("NodeChildrenChanged...");
? ? ? ? ? ? ?break;
? ? ? ? ?case DataWatchRemoved:
? ? ? ? ? ? ?System.out.println("DataWatchRemoved...");
? ? ? ? ? ? ?break;
? ? ? ? ?case ChildWatchRemoved:
? ? ? ? ? ? ?System.out.println("ChildWatchRemoved...");
? ? ? ? ? ? ?break;
? ? ? ? ?case PersistentWatchRemoved:
? ? ? ? ? ? ?System.out.println("PersistentWatchRemoved...");
? ? ? ? ? ? ?break;
? ? ? ? ?default:
? ? ? ? ? ? ?break;
? ? }
?});
?countDownLatch.await();
~~~
由于是異步連接的,所以要用CountDownLatch進行等待。
2. 創建節點
~~~
?String path = zk.create("/test1", "hello world".getBytes(StandardCharsets.UTF_8), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL);
~~~
3. 設置數據
~~~
?Stat stat = zk.setData(path, "hello test".getBytes(StandardCharsets.UTF_8), -1);
~~~
\-1表示自動匹配數據的版本,否則要和集群中的znode節點一致,不然的話會報錯。
4. 獲取數據,同時設置watch
~~~
?byte[] data = zk.getData("/test", new Watcher() {
? ? ?@Override
? ? ?public void process(WatchedEvent watchedEvent) {
? ? ? ? ?System.out.println("getData watch:" + watchedEvent);
? ? ? ? ?try {
? ? ? ? ? ? ?//可以重新注冊回調
? ? ? ? ? ? ?zk.getData("/test", this, new Stat());
? ? ? ? } catch (KeeperException e) {
? ? ? ? ? ? ?e.printStackTrace();
? ? ? ? } catch (InterruptedException e) {
? ? ? ? ? ? ?e.printStackTrace();
? ? ? ? }
? ? }
?}, new Stat());
~~~
在getData中設置的Watch會在給znode設置數據或者刪除節點的時候觸發,注意一個watch只能觸發一次,所以一般都會重復設置。
異步回調方式:
~~~
?zk.getData(path, false, new AsyncCallback.DataCallback() {
? ? ?@Override
? ? ?public void processResult(int rc, String path, Object ctx, byte[] data, Stat stat) {
? ? ? ? ?System.out.println("rc:" + rc);
? ? ? ? ?System.out.println("-------async call back----------");
? ? ? ? ?System.out.println(ctx.toString());
? ? ? ? ?System.out.println(new String(data));
? ? ? ? ?countDownLatch1.countDown();
? ? }
?}, "abc");
~~~
這種方式會在讀取到數據的時候觸發。
- 第一章 Java基礎
- ThreadLocal
- Java異常體系
- Java集合框架
- List接口及其實現類
- Queue接口及其實現類
- Set接口及其實現類
- Map接口及其實現類
- JDK1.8新特性
- Lambda表達式
- 常用函數式接口
- stream流
- 面試
- 第二章 Java虛擬機
- 第一節、運行時數據區
- 第二節、垃圾回收
- 第三節、類加載機制
- 第四節、類文件與字節碼指令
- 第五節、語法糖
- 第六節、運行期優化
- 面試常見問題
- 第三章 并發編程
- 第一節、Java中的線程
- 第二節、Java中的鎖
- 第三節、線程池
- 第四節、并發工具類
- AQS
- 第四章 網絡編程
- WebSocket協議
- Netty
- Netty入門
- Netty-自定義協議
- 面試題
- IO
- 網絡IO模型
- 第五章 操作系統
- IO
- 文件系統的相關概念
- Java幾種文件讀寫方式性能對比
- Socket
- 內存管理
- 進程、線程、協程
- IO模型的演化過程
- 第六章 計算機網絡
- 第七章 消息隊列
- RabbitMQ
- 第八章 開發框架
- Spring
- Spring事務
- Spring MVC
- Spring Boot
- Mybatis
- Mybatis-Plus
- Shiro
- 第九章 數據庫
- Mysql
- Mysql中的索引
- Mysql中的鎖
- 面試常見問題
- Mysql中的日志
- InnoDB存儲引擎
- 事務
- Redis
- redis的數據類型
- redis數據結構
- Redis主從復制
- 哨兵模式
- 面試題
- Spring Boot整合Lettuce+Redisson實現布隆過濾器
- 集群
- Redis網絡IO模型
- 第十章 設計模式
- 設計模式-七大原則
- 設計模式-單例模式
- 設計模式-備忘錄模式
- 設計模式-原型模式
- 設計模式-責任鏈模式
- 設計模式-過濾模式
- 設計模式-觀察者模式
- 設計模式-工廠方法模式
- 設計模式-抽象工廠模式
- 設計模式-代理模式
- 第十一章 后端開發常用工具、庫
- Docker
- Docker安裝Mysql
- 第十二章 中間件
- ZooKeeper