
# Redis的數據結構
`redis是用c語言寫的!`
## 一、簡單動態字符串
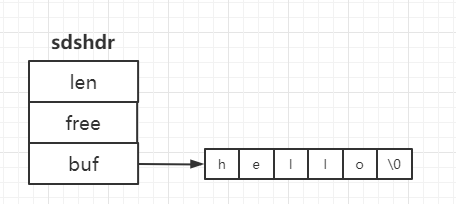
Redis中的字符串并不是使用原生的C語言字符串,而是自己寫了一個結構體來表示字符串,在redis中稱為簡單動態字符串(simple dynamic string)即SDS。其定義如下:
~~~
?struct sdshdr {
? ? ?int len; // 當前的字節長度
? ? ?int free; // 空閑空間的字節長度
? ? ?char buf[]; // 字節數組
?}
~~~
`這是老版本的redis中的定義,新版本的也采用類似的思想。詳細的查看redis開源代碼中的src/sds.h`
SDS中buf的長度為:len + free + 1。
SDS結構示意:
:-: 
### 與C語言字符串的區別
`注意在C語言中并沒有嚴格意義上的字符串類型,而是采用數據的方式來保存字符串。`
1. 獲取長度的時間復雜為O(1)
c語言的字符串是通過遍歷的方式來獲取字符串的長度,統計到‘\\0’字符為止,其時間復雜度為O(N)。但是sds結構中本身就有len屬性記錄了當前的字符串的長度,同時也不是通過'\\0'來表示字符串的結尾,雖然會在字符串的結尾中添加上'\\0'。
2. 杜絕緩沖區的溢出
使用c語言字符串進行拼接的時候strcat(dest, source),如果dest沒有提前分配足夠大小的內存,c語言任然會直接加source的內容拼接到dest后面,這樣就可能會覆蓋掉dest后面的內容。而redis中的sdscat的拼接會提前判斷dest中的free屬性是否足夠大,如果不夠,則會`自動的進行空間的擴展`,然后再進行拼接。
3. 減少修改字符串時帶來的內存重新分配次數
在C語言中,每次修改字符串的內容,都會重新分配內存空間,這是操作系統本身會進行的系統調用。而在redis中由于本身被修改比較頻繁,因此采用了兩種策略來減少內存的重新分配次數。
* 空間的預分配
空間預分配規則用于對字符串空間擴展時使用,程序不僅會擴展上足夠的空間,還會擴展預留的空間。
~~~
?# 規則
?1. 當字符串的長度小于1MB時,會分配和len同樣大小的未使用空間,即讓len=free。
?2. 當字符串長度大于等于1MB時,程序將會分配1MB的未使用空間。
~~~
`通過預分配策略,SDS使得連續增長N字符串所需的內存重分配次數從必定N次減少到最多N次。`
* 惰性空間的釋放
惰性空間的使用規則用于對字符串空間縮減時使用,其并不會真正的減少sds的長度,而是將釋放出來的空間作為未使用空間繼續保存,其`長度保存在free`中。
~~~
?tips: SDS類型存放的字節,并不僅僅是存放ASCII。
~~~
## 二、鏈表(雙端鏈表)
鏈表節點的定義:
~~~
?typedef struct listNode {
? ? ?// 上一個節點
? ? ?struct listNode *prev;
? ? ?// 下一個節點
? ? ?struct listNode *next;
? ? ?// 節點的值
? ? ?void *value;
?} listNode;
~~~
鏈表的定義:
~~~
?typedef struct list {
? ? ?// 頭節點
? ? ?listNode *head;
? ? ?// 尾節點
? ? ?listNode *tail;
? ? ?// 節點復制函數
? ? ?void *(*dup)(void *ptr);
? ? ?// 節點釋放函數
? ? ?void (*free)(void *ptr);
? ? ?// 節點對比函數
? ? ?int (*match)(void *ptr, void *key);
? ? ?// 節點的長度
? ? ?unsigned long len;
?} list;
~~~
* dup函數用于復制鏈表節點所保存的值。
* free函數用于釋放鏈表節點所保存的值。
* match函數用于比較鏈表節點所保存的值和另一個輸入值是否相等。
結構示意:
### redis鏈表的特性
1. 獲取表尾節點的時間復雜度為O(1),因此在鏈表尾部添加節點的時間復雜度也是O(1)。
2. 獲取鏈表的長度的時間復雜度為O(1),可以直接通過len屬性獲取。
3. `多態`:鏈表節點是通過void\* 指針來保存節點的值,并且可以通過list結構的dup、free、match三個屬性為節點值設置特定類型,可以用于保存各種不同的數據類型。
## 三、字典
redis中的字典使用哈希表作為底層的實現,一個hash table里面的每個hash entry都保留了一個鍵值對。
哈希表的定義:`dict.h/dictht`
~~~
?typedef struct dictht {
? ? ?dictEntry **table;
? ? ?// 哈希表的大小
? ? ?unsigned long size;
? ? ?// 用于計算哈希索引,大小固定位size - 1
? ? ?unsigned long sizemask;
? ? ?// 哈希表中的節點個數
? ? ?unsigned long used;
?} dictht;
~~~
哈希表的每一項由dictEntry構成:
~~~
?typedef struct dictEntry {
? ? ?// 鍵
? ? ?void *key;
? ? ?// 值
? ? ?union {
? ? ? ? ?void *val;
? ? ? ? ?uint64_t u64;
? ? ? ? ?int64_t s64;
? ? ? ? ?double d;
? ? } v;
? ? ?// 下一個節點
? ? ?struct dictEntry *next;
?}dictEntry;
~~~
**next**屬性使用了鏈表的方式解決hash沖突。
字典的定義:
~~~
?typedef struct dict {
? ? ?dictType *type;
? ? ?void *privdata;
? ? ?// 保存了兩個hash表,用于rehash
? ? ?dictht ht[2];
? ? ?// 用于重新hash, 不用重新hash時值為-1
? ? ?long rehashidx;
? ? ?// 大于0時暫停rehash
? ? ?int16_t pauserehash;
?} dict;
~~~
**type**屬性保存了一系列操作特定類型鍵值對的函數,**privdata**屬性保存了這些函數的可選參數。
~~~
?typedef struct dictType {
? ? ?// 哈希函數
? ? ?uint64_t (*hashFunction)(const void *key);
? ? ?// 復制鍵
? ? ?void *(*keyDup)(void *privdata, const void *key);
? ? ?// 復制值
? ? ?void *(*valDup)(void *privdata, const void *obj);
? ? ?// 鍵比較
? ? ?int (*keyCompare)(void *privdata, const void *key1, const void *key2);
? ? ?// 銷毀鍵
? ? ?void (*keyDestructor)(void *privdata, void *key);
? ? ?// 銷毀值
? ? ?void (*valDestructor)(void *privdata, void *obj);
? ? ?int (*expandAllowed)(size_t moreMem, double usedRatio);
?} dictType;
~~~
字典結構:
### 哈希算法
~~~
?1. 計算鍵對應的hash值
?hash = dict->type->hashFunction(key)
?2. 計算哈希表的索引
?index = hash & dict->ht[x].sizemask;
~~~
x為0或者1,算出來的index就放在0或1中,如果出現沖突,則使用鏈地址法的方式解決沖突,并且使用頭插法的方式往鏈表中插入節點。
`redis使用murmurHash2算法計算hash值。`
### rehash
當哈希表的負載因子超過一定范圍時,字典會進行一次重新散列,減少沖突或者減少空間的浪費。
~~~
?load_factor = dictht[0].used / dictht[0].size;
~~~
1. 擴展操作
當滿足下列情況之一時,字典會進行rehash操作:
* 服務器目前沒有執行bgsave或者是bgrewriteaof命令時,且負載因子大于等于1.
* 服務器目前正在執行bgsave或者是bgrewriteaof命令,且負載因子大于等于5.
~~~
?當服務器在執行bgsave或者bgrewriteaof命令時,會fork一個子進程,并且服務器采用寫時復制來優化子程序的性能,此時會擴展負載因子,從而盡量避免了在上述命令操作時進行rehash。
~~~
rehash的擴展操作是通過字典中的另外一個hash table(ht\[1\])來實現的,對于擴展操作,其會分配的空間大小為:
~~~
?第一個大于等于ht[0].used * 2的2的n次冪的大小。
?例如:ht[0].used = 3,
?則會給ht[1]分配:3 * 2 = 6,比之大的第一個2的n次冪為8,即會分配8個單位的空間大小
~~~
之后會采用漸進式的方式在`每次增刪改操作時修改rehashIndex的值`,將該rehashIndex索引下的所有鍵值對rehash到ht\[1\]中去。每次操作都會遞增rehashIndex的值,同時對于字典的添加操作,新添加的會放到ht\[1\]中,確保ht\[0\]會被釋放完畢。當ht\[0\]為空時設置rehashIndex為-1,結束rehash。
接著將ht\[0\]執行ht\[1\],重新創建一個新的ht\[1\]。
2. 收縮操作
當負載因子小于0.1時會自動進行收縮操作,此時對ht\[1\]分配的大小為:
~~~
?第一個大于等于ht[0].used的2的n次冪。
~~~
`漸進式rehash操作時,添加在ht[1]中,查找、更新、刪除在ht[0]和ht[1]中進行。`
- 第一章 Java基礎
- ThreadLocal
- Java異常體系
- Java集合框架
- List接口及其實現類
- Queue接口及其實現類
- Set接口及其實現類
- Map接口及其實現類
- JDK1.8新特性
- Lambda表達式
- 常用函數式接口
- stream流
- 面試
- 第二章 Java虛擬機
- 第一節、運行時數據區
- 第二節、垃圾回收
- 第三節、類加載機制
- 第四節、類文件與字節碼指令
- 第五節、語法糖
- 第六節、運行期優化
- 面試常見問題
- 第三章 并發編程
- 第一節、Java中的線程
- 第二節、Java中的鎖
- 第三節、線程池
- 第四節、并發工具類
- AQS
- 第四章 網絡編程
- WebSocket協議
- Netty
- Netty入門
- Netty-自定義協議
- 面試題
- IO
- 網絡IO模型
- 第五章 操作系統
- IO
- 文件系統的相關概念
- Java幾種文件讀寫方式性能對比
- Socket
- 內存管理
- 進程、線程、協程
- IO模型的演化過程
- 第六章 計算機網絡
- 第七章 消息隊列
- RabbitMQ
- 第八章 開發框架
- Spring
- Spring事務
- Spring MVC
- Spring Boot
- Mybatis
- Mybatis-Plus
- Shiro
- 第九章 數據庫
- Mysql
- Mysql中的索引
- Mysql中的鎖
- 面試常見問題
- Mysql中的日志
- InnoDB存儲引擎
- 事務
- Redis
- redis的數據類型
- redis數據結構
- Redis主從復制
- 哨兵模式
- 面試題
- Spring Boot整合Lettuce+Redisson實現布隆過濾器
- 集群
- Redis網絡IO模型
- 第十章 設計模式
- 設計模式-七大原則
- 設計模式-單例模式
- 設計模式-備忘錄模式
- 設計模式-原型模式
- 設計模式-責任鏈模式
- 設計模式-過濾模式
- 設計模式-觀察者模式
- 設計模式-工廠方法模式
- 設計模式-抽象工廠模式
- 設計模式-代理模式
- 第十一章 后端開發常用工具、庫
- Docker
- Docker安裝Mysql
- 第十二章 中間件
- ZooKeeper