[TOC]
# 學習目標
1. 如何創建數據挖掘工作流?
2. 如何使用文件組件加載數據集?
3. 什么是特征?
4. 使用散點圖組件使用“信息投影”實現數據數據分類?
# 問題描述
你是一名植物學愛好者,對鳶尾花(Iris)的品種很感興趣,你收集了一些鳶尾花的以下測量數據:
- 花瓣的長度
- 花瓣的寬度
- 花萼的長度
- 花萼的寬度
> 所有測量結果的單位都是厘米
| 萼長 | 萼寬 | 瓣長 | 瓣寬 | 類別 |
| ---- | ---- | ---- | ---- | ---- |
| 5.1 | 3.5 | 1.4 | 0.2 | ? |
| 4.9 | 3 | 1.4 | 0.2 | ? |

你還有一些鳶尾花分類的測量數據,這些花已經被植物學專家鑒定為屬于Iris setosa(山鳶尾)、Iris versicolor(變色鳶尾)或 Iris virginica(維吉尼亞鳶尾花)三個品種之一。對于這些測量數據,你可以確定每朵鳶尾花所屬的品種。
現在的問題,你想知道采集的鳶尾花是不是這些已知的品種,如果是,是哪一種。
## 模型(model)
我們的目標是構建一個機器學習模型,可以從這些已知品種的鳶尾花測量數據中進行學習,從而能夠預測新鳶尾花的品種。因為我們有已知的鳶尾花的測量數據,所以這是一個監督學習問題。
## 類別(class)
在這個問題中,我們要在多個選項中預測其中一個(鳶尾花的品種),這是一個分(classification)問題的示例。可能的輸出(鳶尾花的品種)叫做類別(class)。數據集中的每朵鳶尾花都屬于三個類別之一,所以這是一個三分類問題。
## 標簽(label)
單個數據點(一朵鳶尾花)的預期輸出是這朵花的品種。對于一個數據點來說,它的品種叫做標簽(label)。
## 特征(feature)
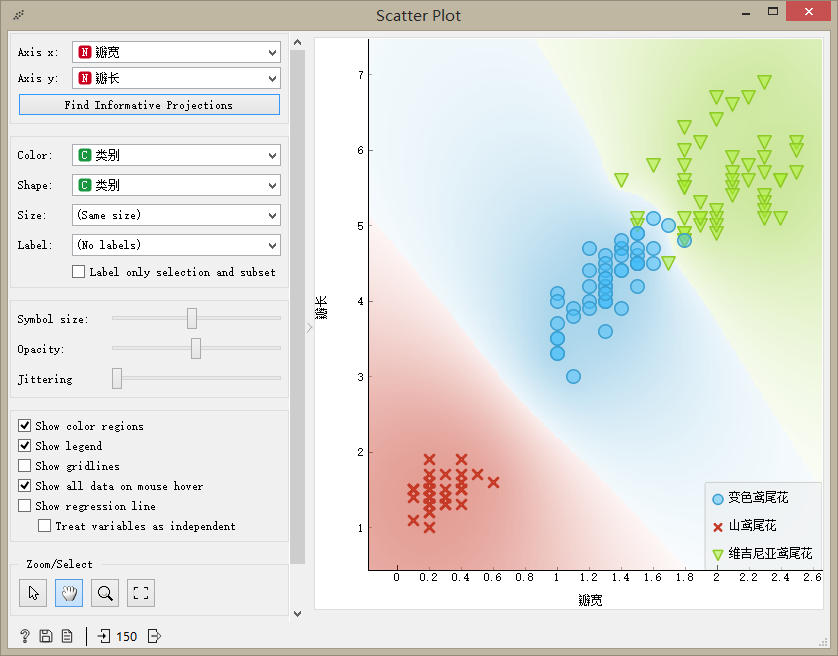
采集到的鳶尾花數據包含:萼長、萼寬、瓣長、瓣寬4個特征,我們選擇 瓣長、瓣寬兩個屬性,并以瓣寬為X軸,瓣長為Y軸在二維平面上將這些樣本繪制出來,從圖中可以看出變色鳶尾花和維吉利亞鳶尾花兩個類別的有一部分樣本混合在一起,而山鳶尾花和其它兩個類別的花能夠能夠很好的區分開來。
使用散點圖可以可以可視化查看測試數據,由于采集到的樣本有四個屬性,是一個4維的向量,不能在平面上展示出來,因此我們人工選擇瓣長、瓣寬兩個屬性分別作為x和y軸的屬性,從而在散點圖上展示樣本的分布情況。
> 通過查找信息投影(Find Information Projections)按鈕自動選擇最具有分辨能力的兩個特征:瓣長、瓣寬。
接下來我們通過k近鄰算法用機器來統計有多少花能夠正確的分類,識別的正確率有多少。
# kNN 算法
## 算法
k 近鄰(kNN)算法把每個樣例看做是空間上的一個點,給定一個測試樣例,使用適當的鄰近性度量算法,計算出該點與訓練集中其他點的鄰近度。選擇 K 個最相近的點。在選擇出的 K 個樣例中,比例最好的類就是測試樣例的類。
> 從以上描述中可以看出,如果 k 選擇的太小,該算法容易受到噪聲的影響,而產生過度擬合的影響,然而如果選擇的過大,可能造成誤分類。
## 算法描述
```
k是最近鄰數目,D是訓練樣例的集合,z是測試樣例
for 樣例 in 訓練樣例集合:
計算 z和每個樣例的相似度
找到k個最相近的樣例集合
k個樣例中類標號最多的類,就是測試樣例的類標號
```
# 實驗與評估
## 實驗平臺
* Orange([http://orange.biolab.si/](http://orange.biolab.si/))由斯洛文尼亞大學計算與信息學系的生物信息實驗室BioLab開發,是一個基于組件的數據挖掘和機器學習軟件套裝,支持 Python 進行腳本開發。
* [Orange](https://orange.biolab.si/)是一個開源的數據挖掘和機器學習軟件。Orange 基于 Python 和 C/C++ 開發,提供了一系列的數據探索、可視化、預處理以及建模組件。Orange 擁有漂亮直觀的交互式用戶界面,非常適合新手進行探索性數據分析和可視化展示;同時高級用戶也可以將其作為 Python 的一個編程模塊進行數據操作和組件開發。
* 從 3.0 版本開始使用 Python 代碼庫進行科學計算,例如 numpy、scipy 以及 scikit-learn,前端的圖形用戶界面使用跨平臺的 Qt 框架。
* Orange 支持 Windows、macOS 以及 Linux 平臺。
> 建議使用[Anaconda](https://www.anaconda.com/)集成環境,通過Anaconda Navigator 安裝Orange軟件。
## Iris 數據集
本教程使用標準的Iris數據集,Iris 數據集是常用的分類實驗數據集,由 Fisher, 1936 收集整理。Iris 也稱鳶尾花卉數據集,是一類多重變量分析的數據集。Iris 數據集包含三個花的品種,每個品種各 50 個樣本,共計150個樣本,每個樣本四個特征參數:萼片長度和寬度、花瓣長度和寬度
- Iris setosa(山鳶尾)
- Iris virginica(維吉尼亞鳶尾花)
- Iris versicolor(變色鳶尾)
## 實驗設計
### 實驗模型圖
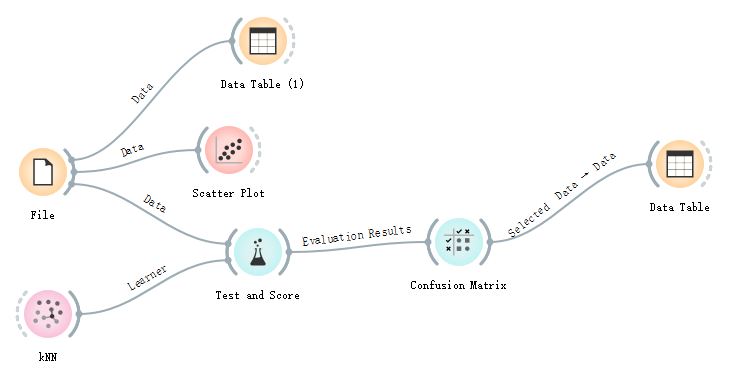
### 添加文件組件
> 添加 File 組件,并設置數據源為 Orange 內置的測試數據集 Iris (英文)或者我們提供的 Iris.csv (中文)文件。
- 在 Orange 面板上找到 File 組件,并拖放到操作面板上
- 雙擊 File 圖標,選擇數據文件
- 將類別這一列的 Role(角色)設置為 target(目標)
> 通過給文件(File)組件連接一個數據表( Data Table) 組件可以觀察數據,通過給文件組件連接一個散點圖(Scatter Plot),可以觀察數據的分布情況。
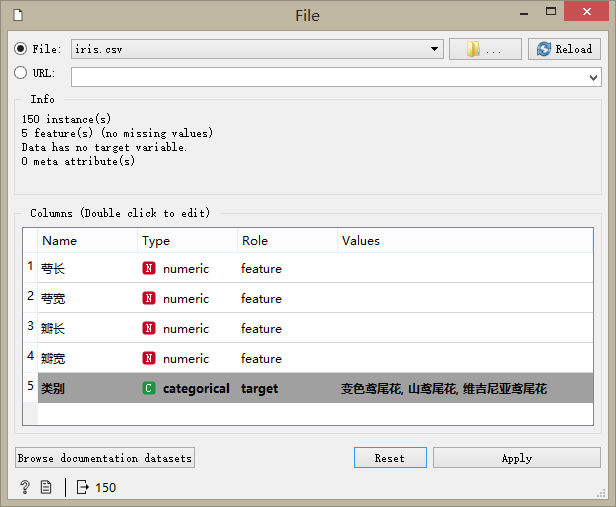
雙擊File組件,設置文件的地址為我們提供的iris.csv文件,如圖所示,鳶尾花數據集(Iris)包含四個特征(feature)列和一個目標列(target)。
> 這里需要手動雙擊“類別”的角色(Role)更改為 target,告訴系統類別是我們識別的目標分類屬性,它是目錄化(categorical)的特征,一共有3種取值(數據只有3類),分別是變色鳶尾花、山鳶尾花、維吉尼亞鳶尾花。
### 算法評估
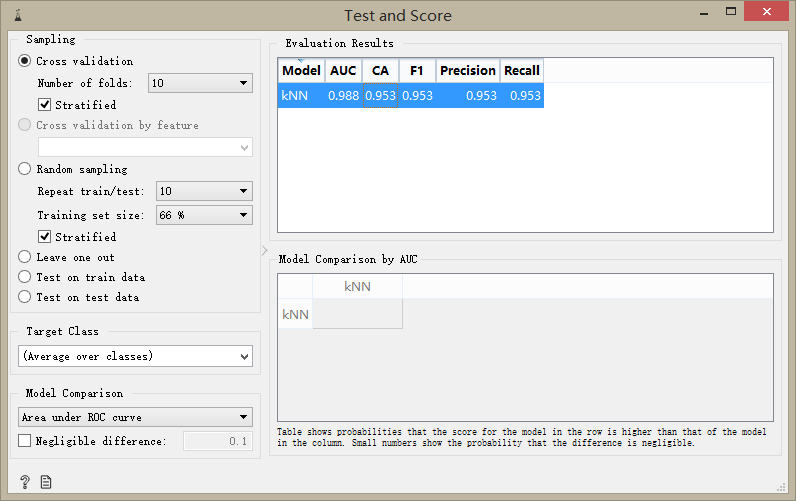
從評估(Evaluate)面板組中拖動測試與評分(Test and Score)組件到工作臺,并從模型(Model)面板組中拖動k近鄰分類器(kNN)組件到工作臺,并參考實驗模型圖建立組件之間的關聯,雙擊測試與評分(Test and Score)組件,可以看到kNN算法的執行結果,精確度(Precision)為0.953,即95.3%的樣本能夠被正確的識別,這個模型也算是不錯了,這個過程我們沒有寫任何代碼。
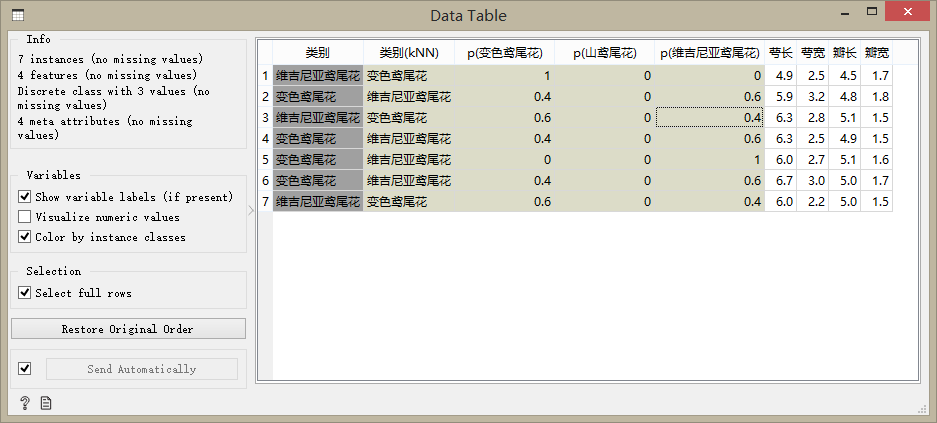
最后我們從評估(Evaluate)面板組中拖動混淆矩陣(Confusion Matrix)組件到工作臺,并建立連接,雙擊混淆矩陣組件,我們發現一共有7個樣本被識別錯誤。其中有3個實際上是維吉利亞鳶尾花被識別為變色鳶尾花,有4朵實際上是變色鳶尾花被識別為維吉利亞鳶尾花,而所有的山鳶尾花都被正確的識別。

選擇誤分類(Select Misclassified)的按鈕,打開數據表(Data Table)組件,可以查看那些樣本被錯誤分類,并分析其原因。