# 使用Orange3對圖片進行數據挖掘
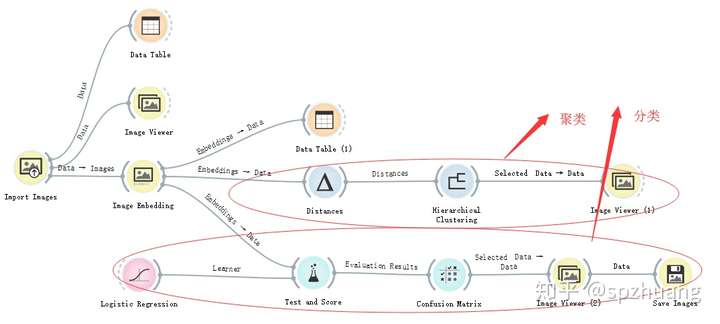
摘要:本文是Orange3進行數據挖掘的第二部分教程,本文的內容主要是使用Orange3對圖片進行一些通用的處理,這些操作包括對圖片數據的載入,分類,聚類。本教程應用的布局如下圖:
1. 數據準備
首先,我們需要一組圖片數據才可以對圖片進行處理。我從必應搜索中,輸入關鍵詞“花”,選擇了5個花的類別“杜鵑花”,“蘭花”,“菊花”,“玫瑰”,“水仙”,每個類別5張圖片,一共有25張圖片,保存在本機電腦的文件“花”中(自個兒建一個)。
2\. 載入圖片數據并預覽
為了能夠載入圖片數據,需要我們先安裝圖片處理的包,點擊“菜單”-> "Options" -> "Image Analytics"安裝圖片處理包,安裝后需要重啟Orange3, 然后我們能夠在左側的工具中找到圖片處理的窗口了。
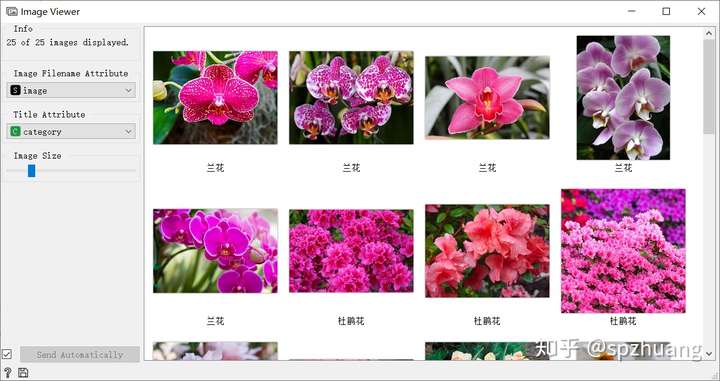
然后,我們將Import Images和Image Viewer拖到右側的畫板中,雙擊“Import Images",選擇圖片文件”花“,然后連接"Import Images"和"Image Viewer",進入“Image Viewer”就可以看到這些圖片了。
3\. 使用圖片embedding
為了對這些圖片進行分類和聚類,我們還需要對圖片進行embedding操作,這個操作的含義類似于自然語言處理中對原始文本進行embedding化,將它們轉化為各個結構化的tensor。
將“Image Embedding”應用從左側的工具窗口拖到右側的畫板中,連接“Import Images"和"Image Embedding",進入“Image Embedding”,這里可以選擇不同的圖片嵌入方式,不知道什么原因,其它的幾個選擇(“Vgg16,Inception v3”)都不會有實際的作用,盡管它們都是比較著名的圖片處理網絡,這里只有選擇“SqueezeNet(local)”才可以真正的發揮效用。
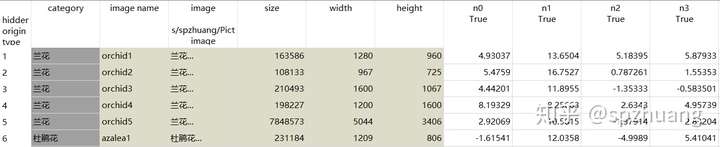
這個時候,將“Data Table”應用拖入到右側的畫板中,連接"Image Embedding"和"Data Table",就可以看到這些圖片被嵌入后的數據了(沒有做embedding之前,沒有n0,n1這些字段)。
4\. 對圖片進行聚類
將左側“Unsupervised”窗口中的“Distances”,"Hierarc Clustering"以及"Image Analytics"的"Image Viwer"拖入到右側的畫板中,連接“Image Embedding”和“Distances”,連接“Distances”和“Hierarc Clustering”,連接“Hierarc Clustering”和“Image Viwer”。
配置了聚類組件之后,我們稍微詳細的說一下具體設置。
在“Distances”中可以選擇不同的距離,比如余弦距離(cosine),歐式距離(Euclidean),曼哈頓距離(Manhattan)等。對圖片的處理,針對不同的數據,改變不同的距離度量對處理結果會產生影響。
同時打開“Hierarc Clustering”和“Image Viewer”,當我們選擇了“Hierarc Clustering”中的一些聚類的結果時,在“Image Viewer”中會顯示出被選擇聚類結果對應的“花”。如下圖:
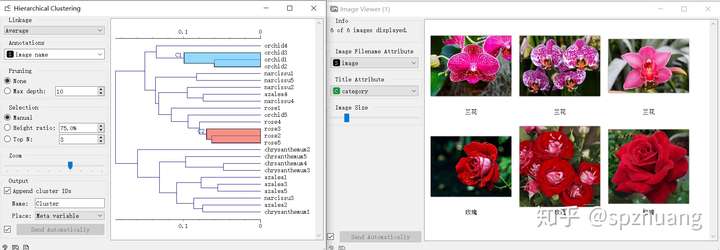
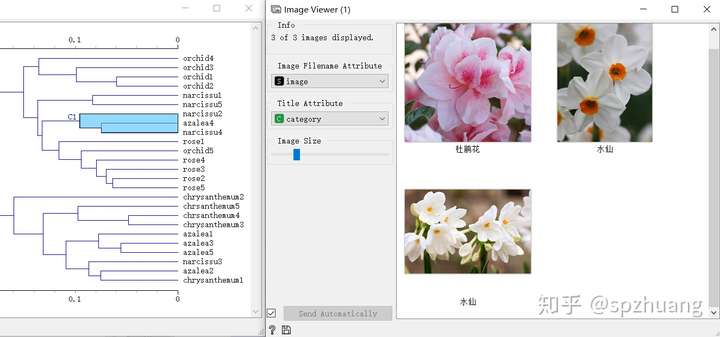
通過這種方式,能夠非常高效的分析聚類結果。從圖片中可以看出,蘭花和玫瑰確實區別比較大,因此它們被劃分到不同的簇中;另一方面,這種聚類將某個杜鵑花和二張水仙花的圖片分到了一個簇中,從右側的Image Viewer中,可看出它們確實非常相似。這同協同反應,我覺得時Oragne3非常吸引人的地方。
5 對圖片進行分類
將左側窗口中“Evaluate”下的幾個應用“Test and Score”,"Confusion Matrix", 將“Image Analysis”中的“Image Viewer”,“Save Images”,將“Model”中的“Logistic Regression”共7個應用拖入到右側畫板中。連接“Image Embedding"-"Test and Score”,"Logistic Regression"-"Test and Score","Test and Score"-"Confusion Matrix","Confusion Matrix"-"Image Viewer","Image Viewer"-"Save Images",這樣分類的應用部署就完成了。
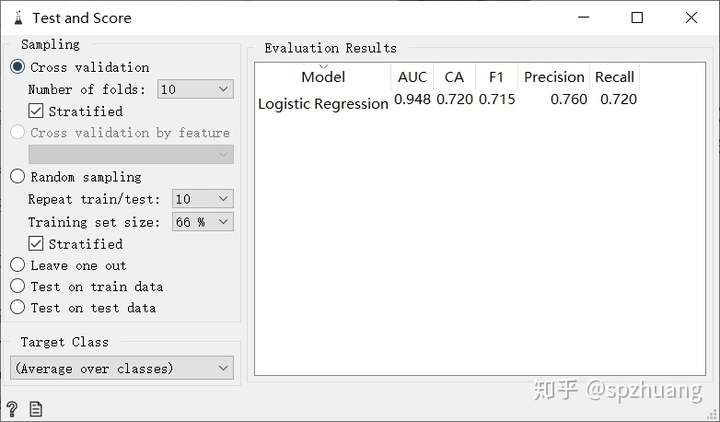
在“Logistic Regression”中,可以調節它的正則化系數,為L1范數還是L2范數,以及懲罰稀疏的大小。在“Test and score”中,可以看模型Logistic回歸對圖片的分類結果,包括AUC,F1,Precision,Recall等常用指標,并且還可以調節交叉驗證的參數,只要調節"Cross Validation"下"Number of Folds"下的參數即可。
為了查看具體分錯的樣本,我們可以同時打開“Confusion Matrix”和“Image Viewer”。混肴矩陣的含義這里不再討論,感興趣的讀者可自行百度。在混肴矩陣中,對角線上的數字代表正確分類的,而非對角線上的數字,代表的時錯誤的分類。
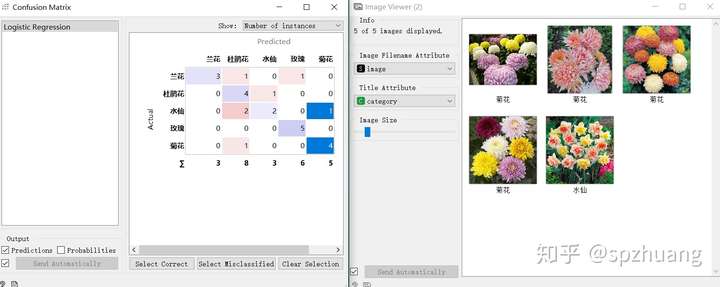
深藍色的時我選擇的數據,它們會在右側的Image Viewer中出現。從混肴矩陣中有,第3行第5列的1代表的時Logistics將水仙花預測成了菊花,從右側的Image Viewer,直觀上看,圖片上的水仙花,確實和菊花很相似,因此這個樣本并不容易劃分。
最后的"save image"可以將圖片Image Viwer中的圖片保存到本機中。
6\. 總結
本本講述了如何使用Orange對圖片進行讀取,查看,embedding,聚類和分類,以及分類或者聚類后查看出錯的數據。揭示了Orange可以高效的分析異常圖片的特性。這些是吸引我們使用Orange3處理數據一個點。
