# 課程大綱
本課程分如下幾個階段介紹網絡爬蟲知識:
- [入門篇](入門篇.md): 基本功,掌握基礎Web知識
- [進階篇](進階篇.md): 武功招式,游走在PC瀏覽器和移動APP上的數據操作
- [高級篇](高級篇.md): 高級招式, “天下武功,唯快不破。”

---
Pyhon蟲師的進階之路
--
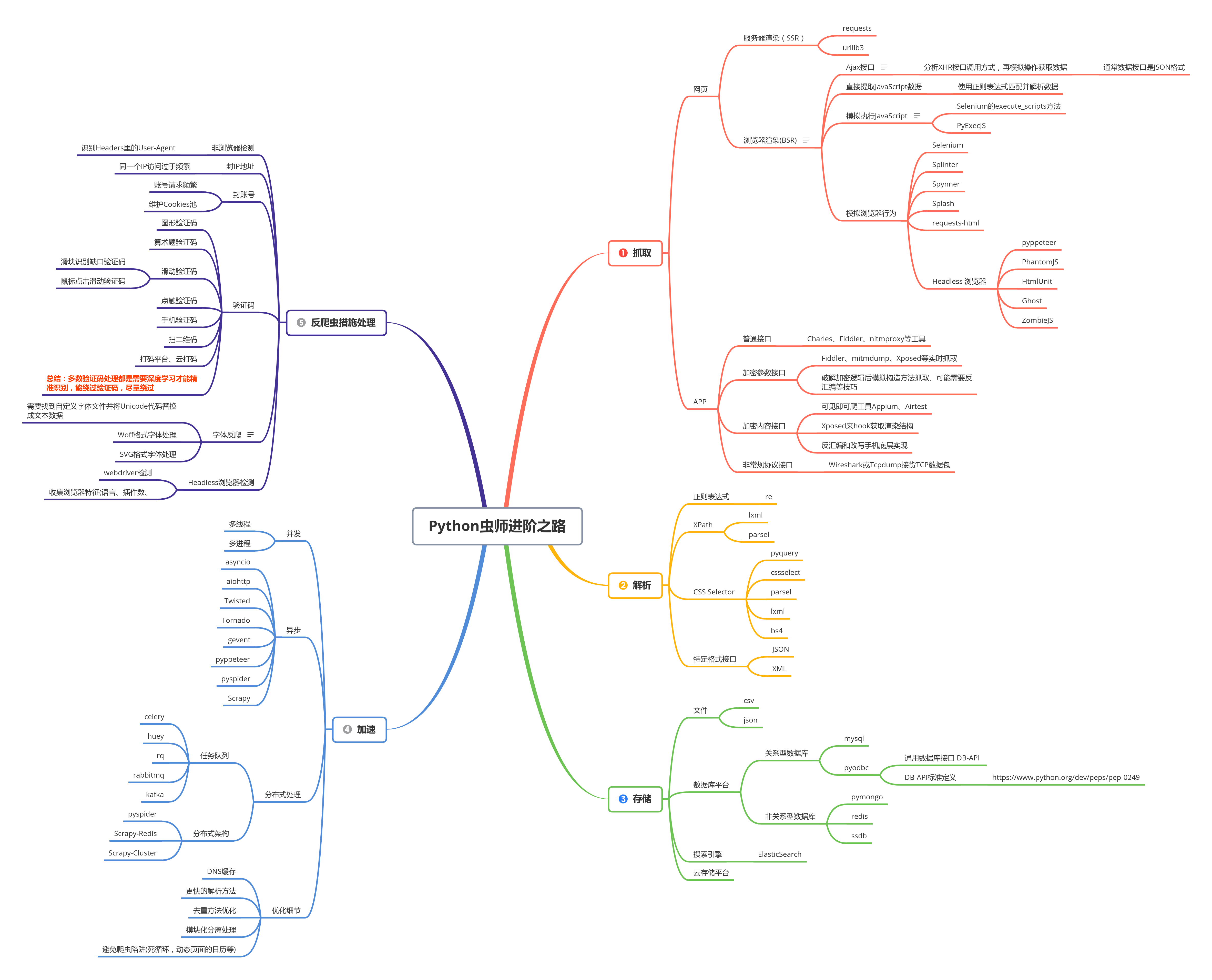
- 課程大綱
- 入門篇
- 爬蟲是什么
- 為什么要學習爬蟲
- 爬蟲的基本原理
- TCP/IP協議族的基本知識
- HTTP協議基礎知識
- HTML基礎知識
- HTML_DOM基礎知識
- urllib3庫的基本使用
- requests庫的基本使用
- Web頁面數據解析處理方法
- re庫正則表達式的基礎使用
- CSS選擇器參考手冊
- XPath快速了解
- 實戰練習:百度貼吧熱議榜
- 進階篇
- 服務端渲染(CSR)頁面抓取方法
- 客戶端渲染(CSR)頁面抓取方法
- Selenium庫的基本使用
- Selenium庫的高級使用
- Selenium調用JavaScript方法
- Selenium庫的遠程WebDriver
- APP移動端數據抓取基礎知識
- HTTP協議代理抓包分析方法
- Appium測試Android應用基礎環境準備
- Appium爬蟲編寫實戰學習
- Appium的元素相關的方法
- Appium的Device相關操作方法
- Appium的交互操作方法
- 代理池的使用與搭建
- Cookies池的搭建與用法
- 數據持久化-數據庫的基礎操作方法(mysql/redis/mongodb)
- 執行JS之execjs庫使用
- 高級篇
- Scrapy的基本知識
- Scrapy的Spider詳細介紹
- Scrapy的Selector選擇器使用方法
- Scrapy的Item使用方法
- Scrapy的ItemPipeline使用方法
- Scrapy的Shell調試方法
- Scrapy的Proxy設置方法
- Scrapy的Referer填充策略
- Scrapy的服務端部署方法
- Scrapy的分布式爬蟲部署方法
- Headless瀏覽器-pyppeteer基礎知識
- Headless瀏覽器-pyppeteer常用的設置方法
- Headless瀏覽器-反爬應對辦法
- 爬蟲設置技巧-UserAgent設置
- 反爬策略之驗證碼處理方法
- 反爬識別碼之點擊文字圖片的自動識別方法
- 反爬字體處理方法總結
- 防止反爬蟲的設置技巧總結
- 實戰篇
- AJAX接口-CSDN技術博客文章標題爬取
- AJAX接口-拉購網職位搜索爬蟲
- 執行JS示例方法一之動漫圖片地址獲取方法
- JS執行方法示例二完整mangabz漫畫爬蟲示例
- 應用實踐-SOCKS代理池爬蟲
- 落霞小說爬蟲自動制作epub電子書
- 一種簡單的適用于分布式模式知乎用戶信息爬蟲實現示例
- 法律安全說明