[TOC]
# HTTP協議基礎知識
了解了`TCP/IP協議族`分層結構后,我們可以學習`HTTP`協議了。
`HTTP`協議屬于`應用層`的協議,協議定義的是`客戶端`與`服務端`之間通信的數據報文格式,接下來一步一步的學習具體的報文格式及其作用。
成就非凡的俠客,不能只看圖練招式,還有`內功心法`。
`HTTP`協議格式就是踏入江湖的第一段`內功心法`。沒有它你就很難立足于`Web江湖`。**謹記:耐心!**
## HTTP協議格式
要學習HTTP協議格式,需要分別從下面兩個部分了解HTTP協議格式:
1. 請求報文-Request : 客戶端/瀏覽器 發送給 服務端 的報文
2. 應答報文-Response: 服務端 返回給 客戶端/瀏覽器 的報文
**我們來通過下面HTTP交互過程來了解報文格式發送過程:**
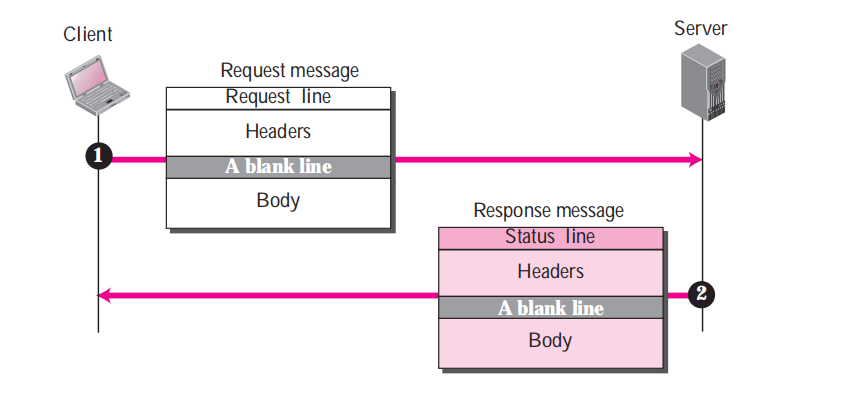
從圖中可以看到兩種報文發送流程很簡單:
- 第一步:客戶端/瀏覽器 發送給 服務端 一條`Request`請求報文,告訴服務器,我要瀏覽頁面"www.example.com/index.html"
- 第二步:服務器 返回給 客戶端/瀏覽器 一條`Response`應答報文,告訴客戶端,好的!接收吧,這是你要的數據。
就這樣,一次愉快的請求和應答完成了。
---
愉快歸愉快,可是瀏覽器向服務器發送了哪些數據呢?
如果連這點都不清楚,那就沒辦法成為一名合格的蟲師啦。
所謂知己知彼,連這個`知己`都還沒搞清楚,何以闖蕩**江湖**...
好啦! `耐心`的將兩種格式(`心法`)記住,達到`倒背如流`的程度吧!
### Request請求報文格式
> `Request`請求報文就是我們的瀏覽器發送給服務器的數據格式
**Request請求報文格式如下:**
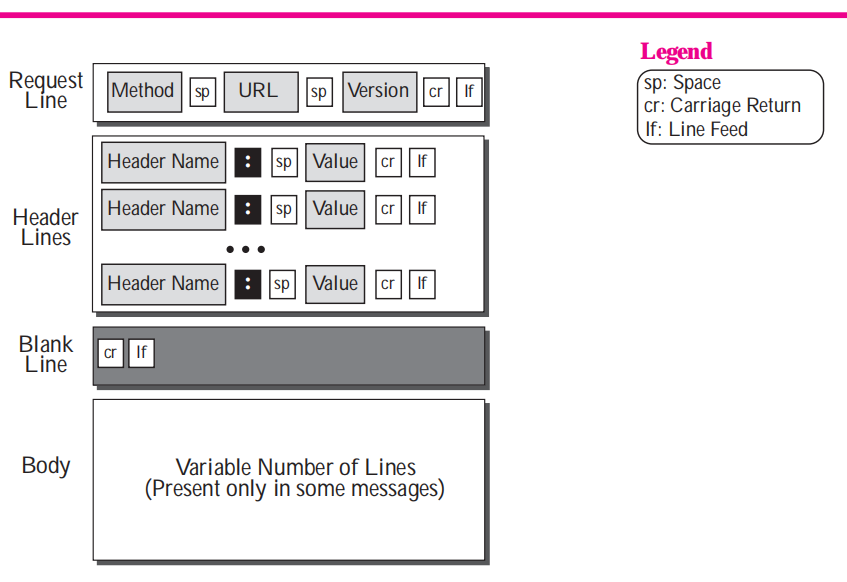
格式其實很簡單,主要分成三部分:
- `請求行(RequestLine) `: 包含請求方法、請求資源位置和協議版本信息。
- `頭部(Headers)`: 可能多行,以讀到一個空行(一行內容為"\r\n")為結束標識。
- `實體正文(Body)`:這里就是實際的請求參數信息或者傳輸數據,如果不傳數據可以沒有實體部分。
#### HTTP協議版本-Version
> 版本號字段雖然對一名蟲師來說不常用,但是對于歷史的變遷與未來的方向都可以在版本中映射出他們在**江湖**中的故事。
- `HTTP/0.9`: 1991年,第一個版本,已過時。
- `HTTP/1.0`: 1996年,第二個版本,替代0.9版本,仍在使用中,僅支持`GET`、`HEAD`和`POST`三種方法。
- `HTTP/1.1`: 1997年,第三個版本,目前使用最為廣泛,新增`OPTIONS`,`PUT`,`DELETE`,`TRACE`和`CONNECT`五種方法,默認支持長連接(`keep-alive`),支持分塊傳輸編碼。
- `HTTP/2.0`: 2015年5月14日發布`RFC7540`文檔,第四個版本,幾乎所有的Web瀏覽器和主要的Web服務器都通過使用應用程序層協議協商(ALPN)擴展的傳輸層安全性(TLS)來支持,其中需要TLS 1.2或更高版本(**強制性加密支持**)。值得一提的是這個協議參考了Google的`SPDY協議`。增加了對頭部基于`霍夫曼編碼`壓縮的支持,支持TCP連接的多路復用,極大的降低網絡延遲和傳輸數據量。 [維基百科 HTTP/2.0](https://en.wikipedia.org/wiki/HTTP/2)
- `HTTP/3.0`: 2018年被提出,第五個版本,2019年9月Google的Chrome瀏覽器(79)穩定版本中可以啟用。在HTTP/3中,將傳輸層的`TCP協議`改為使用基于UDP協議的`QUIC(快速UDP網絡連接)`協議實現。而這種改動設計最初也來自`Google`。[維基百科 HTTP/3.0](https://en.wikipedia.org/wiki/HTTP/3)
雖然版本在提升,但是協議的格式并沒有發生改變,改變的僅僅是壓縮算法和傳輸協議。這對于我們來學習分析格式是沒有任何影響的。
#### `HTTP協議`請求方法-Method

#### `HTTP協議`請求Web地址-URL
> 我們常說的網頁地址,通常就是指`URL`地址,而`URL`地址格式其實是統一資源標識符`URI`的一種特定形式,例如 "http://www.example.com/index.html" 表示 訪問主機"www.example.com"上的`index.html`文件。
看似簡單的`URL`其實包含了一種標準格式`URI`的規范:
```
URI = scheme:[//authority]path[?query][#fragment]
authority = [userinfo@]host[:port]
```

- `schema`: 標識協議類型,例如 http/https/ftp/mailto/jdbc
- `authority` : 認證訪問信息,以"//"開頭,包括主機地址`host`,可選端口,可選的用戶信息`userinfo`(用戶密碼認證信息)
- `path` : 訪問資源路徑,以"/"開始表示絕對路徑,每層目錄都使用"/"分割。
- `query`: 查詢條件參數設置,前面以"?"開頭,每個條件參數格式為"key=value",相鄰參數以"&"符號分割開,例如"/get_proxy?check_count=100&type=http"
- `fragment`: 分片ID, 以"#"開頭,通常在`web`頁面中用來同一頁面的目錄導航快速定位章節位置。
下面的示例都是`URL`地址:
```
http://www.example.com:8080/admin/login.html
http://www.example.com/query/?q=spider
ftp://ftpuser:ftppass@www.example.com:21
```
> 注: 以后了解了數據訪問知識后,你會發現`URI`格式不僅僅用于訪問`Web頁面`(http),訪問`數據庫`(odbc,jdbc)、`FTP`(ftp)以及`郵箱`(mailto)都是可以使用的。
#### `HTTP協議` 的請求首部-Headers

#### HTTP協議請求報文示例
> Wireshark是抓包、分析消息的利器,作為蟲師必備,下圖即一條訪問`http://localhost:5030/get/?check_count=100`請求示例。
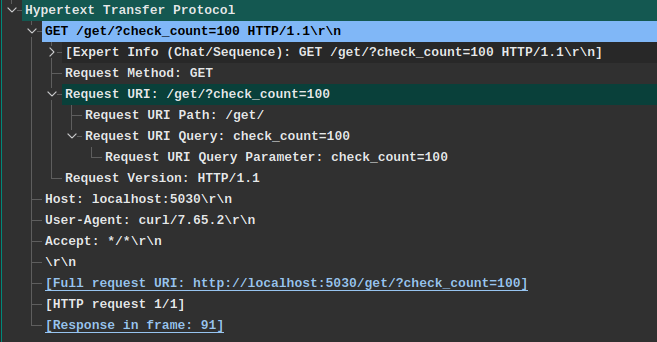
在這條HTTP請求報文中,客戶端向服務器發送了這些信息:
- `Method`方法: `GET`
- `URL`請求路徑: `/get/?check_count=100` ,實際請求需要結合`Host`字段為完整的URI地址。
- `HTTP版本信息`: `HTTP/1.1`
- `Host`請求服務器主機(如果有端口會附帶端口): `localhost:5030`
- `User-Agent`客戶端程序標識: `curl/7.65.2`,因為這是我使用`curl`命令發出的請求。
- `Accept`接收媒體格式: `*/*`支持服務端返回任意格式數據.
當這條請求發給`服務器`后,服務器就會知道 一個來自`curl/7.65.2`客戶端請求`/get/`位置數據,請求參數為`check_count=100`,并且客戶端支持接收任意格式的數據內容。
---
### Response應答報文格式
> 學習應答報文協議格式后我們可以了解服務器給我們回答的報文數據格式以及包含了哪些字段信息,以及這些字段都表達了服務器的什么含義,這樣我們對返回結果可以理解的更加透徹。方便我們在遇到問題時來分析原因。
**Response 應答報文格式**
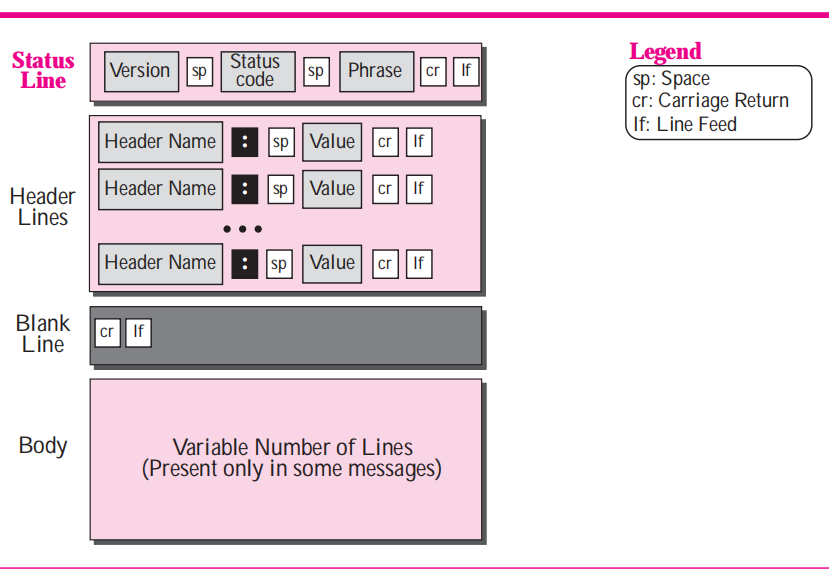
#### 應答返回狀態碼-`Status Code`
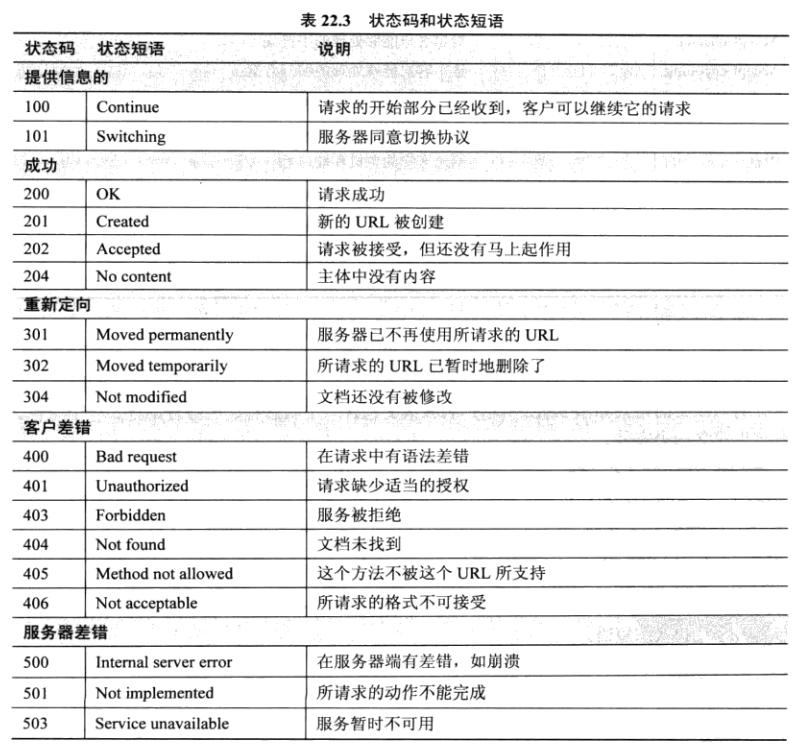
**常見的狀態碼有:**
- `200`-請求成功。
- `302`-服務請求臨時重定向到新URL地址。
- `404`-請求地址無法找到或請求錯誤都會返回404.
- `503`-服務暫時不可用,可能服務器應答超時或者出了其他內部問題。
#### 應答返回的頭部信息-Headers

#### HTTP協議應答報文示例
> 這段消息是上面請求報文的應答報文,都是來自Wireshark抓包結果。
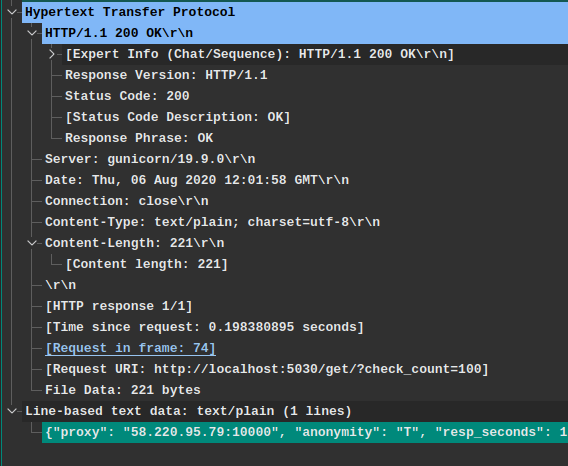
從這條HTTP報文可以了解到:
- HTTP協議版本(`Response Version`): HTTP/1.1
- 狀態碼(`Status Code`): 200
- 服務器軟件(`Server`): gunicorn/19.9.0
- 響應時間(`Date`): "Thu, 06 Aug 2020 12:01:58 GMT"
- TCP鏈接狀態(`Connection`): 關閉狀態(不是長連接)
- 返回的內容類型(`Content-Type`): "text/plain; charset=utf-8" 文本類型,并且使用`utf-8`編碼規則
- 返回的內容長度(`Content-Length`): 221字節
- 文本內容(空行"\r\n"后面的內容): "{proxy:....}"
>注意: 這里看到的一些信息是`Wireshark`軟件的輔助解釋信息,比如 `Request in frame:74` 這并不是此報文包含的信息,而是`Wireshark`根據TCP請求序號關聯的一次消息交互結果,這個關聯結果意思是此應答報文對應抓包文件中的第`74`幀的請求,雙擊后我們就可以跳到請求幀查看客戶端發出的請求內容。如下圖所示:

## 總結
看到這里,表明你已經了解了`HTTP`協議的兩種報文格式。
可以自我練習一下,使用Wireshark工具監聽本機的瀏覽器訪問某個網站過程中的交互過程。
你會發現,`HTTP`協議網站交互內容一覽無余,而使用`HTTPS`協議的網站交互內容是無法查看,這就是加密的作用。
## HTTPS協議-安全的HTTP協議
> HTTP基礎上加了TLS傳輸安全層,這個層通過瀏覽器和服務器的協商掌握一個只有兩人知道的對稱加密秘鑰key,使用key對明文的`HTTP`內容加密傳輸。
對于秘鑰協商的過程簡單來說就是:
1. 服務端先發送公鑰給瀏覽器
2. 瀏覽器使用公鑰加密自己的`key`,并傳回服務端
3. 服務端使用私鑰解密,獲得瀏覽器的`key`。
4. 二者開心的使用`key`加密數據實現安全交互。
這里服務端的`公鑰`和`私鑰`是一對`非對稱加密類型`秘鑰,誰都可以知道`公鑰`并使用它加密數據,但是`私鑰`只有服務端自己保存。
使用`公鑰`解密的數據只能被對應的`私鑰`解密,而不能被`公鑰`解密。這樣就保證了網絡數據的安全。
但是`非對稱加密`方式加密長文本數據相對與`對稱加密`算法較慢,這又是它的劣勢,因此`HTTPS`同時使用了這兩種算法。
1. 使用`非對稱加密`算法傳遞`對稱加密`算法的秘鑰。
2. 使用共享后的`對稱加密`算法`秘鑰`進行數據加密、解密。
下面圖片是`Wireshark`分析的一段`HTTPS`握手協商交換秘鑰的過程:
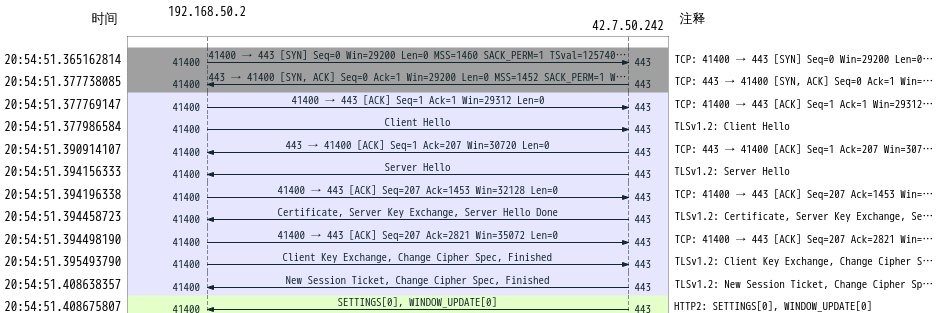
具體過程就不細說了,接下來我們說一下如何使用`Wireshark`查看解密后的`HTTPS`協議的報文內容。
### Wireshark抓包解析HTTPS消息方法
> 下面方法是記錄對稱加密算法中的兩個隨機數,生成對稱加密算法的關鍵參數,知道了這兩個參數就可以生成對稱秘鑰并解密`HTTPS`協議報文。
1. 環境變量設置: `export SSLKEYLOGFILE="~/.sslkeylogfile.txt"`
2. 命令行執行`chrome`或者其他瀏覽器都可以。隨便訪問一個`HTTPS`協議網站就會保存sslkey到文件中
3. 使用`SSLKEYLOGFILE`變量指定文件到`Wireshark`中設置一下,設置方法為: `菜單欄Edit` ==> `Preferences` ==> `Protocols` ==> `TLS`,找到`(Pre)-Master-Secretlog filename`中選擇剛才設置的`~/.sslkeylogfile.txt`文件,點擊確定。
此時再看看監聽獲取的`HTTPS`消息是不是已經被解密了呢?
---
~END~
- 課程大綱
- 入門篇
- 爬蟲是什么
- 為什么要學習爬蟲
- 爬蟲的基本原理
- TCP/IP協議族的基本知識
- HTTP協議基礎知識
- HTML基礎知識
- HTML_DOM基礎知識
- urllib3庫的基本使用
- requests庫的基本使用
- Web頁面數據解析處理方法
- re庫正則表達式的基礎使用
- CSS選擇器參考手冊
- XPath快速了解
- 實戰練習:百度貼吧熱議榜
- 進階篇
- 服務端渲染(CSR)頁面抓取方法
- 客戶端渲染(CSR)頁面抓取方法
- Selenium庫的基本使用
- Selenium庫的高級使用
- Selenium調用JavaScript方法
- Selenium庫的遠程WebDriver
- APP移動端數據抓取基礎知識
- HTTP協議代理抓包分析方法
- Appium測試Android應用基礎環境準備
- Appium爬蟲編寫實戰學習
- Appium的元素相關的方法
- Appium的Device相關操作方法
- Appium的交互操作方法
- 代理池的使用與搭建
- Cookies池的搭建與用法
- 數據持久化-數據庫的基礎操作方法(mysql/redis/mongodb)
- 執行JS之execjs庫使用
- 高級篇
- Scrapy的基本知識
- Scrapy的Spider詳細介紹
- Scrapy的Selector選擇器使用方法
- Scrapy的Item使用方法
- Scrapy的ItemPipeline使用方法
- Scrapy的Shell調試方法
- Scrapy的Proxy設置方法
- Scrapy的Referer填充策略
- Scrapy的服務端部署方法
- Scrapy的分布式爬蟲部署方法
- Headless瀏覽器-pyppeteer基礎知識
- Headless瀏覽器-pyppeteer常用的設置方法
- Headless瀏覽器-反爬應對辦法
- 爬蟲設置技巧-UserAgent設置
- 反爬策略之驗證碼處理方法
- 反爬識別碼之點擊文字圖片的自動識別方法
- 反爬字體處理方法總結
- 防止反爬蟲的設置技巧總結
- 實戰篇
- AJAX接口-CSDN技術博客文章標題爬取
- AJAX接口-拉購網職位搜索爬蟲
- 執行JS示例方法一之動漫圖片地址獲取方法
- JS執行方法示例二完整mangabz漫畫爬蟲示例
- 應用實踐-SOCKS代理池爬蟲
- 落霞小說爬蟲自動制作epub電子書
- 一種簡單的適用于分布式模式知乎用戶信息爬蟲實現示例
- 法律安全說明