[TOC]
# TCP/IP協議族的基本知識
>想要學習`HTTP協議`知識么?怎么討論`TCP/IP協議族`了?
別急著學習`HTTP協議`,如果你沒有`計算機網絡`的基本知識功底,還是乖乖的繼續往下學習,否則`舉步維艱`描述的就是將來的你。
>一名游走于**江湖**的蟲師,怎么能對`計算機網絡`毫無所知?匪夷所思!匪夷所思!啊!
## 理解協議分層原因
理解計算機網絡的第一個知識點是 **網絡通信模型分層的產生原因** ,我們要從兩個故事開始:
### 故事一:單層結構通信
`瑪利亞`和`安`兩個人是鄰居并且都有同樣的興趣愛好,兩人語言不通,`瑪利亞`只會說`西班牙語`而`安`只會說`英語`,但是都學習過手語,因此兩人可以通過手語面對面的交流想法和觀點。

### 故事二:多層結構通信
由于工作原因,`安`搬離了另外的城市居住,兩人分開前很傷心,但是`安`送給`瑪利亞`一個翻譯機,可以將`西班牙語`的文字翻譯成`密碼`,也可以將`密碼`翻譯成`西班牙語`文字,
而`安`自己也有一個翻譯機,可以將`英語`文字翻譯成`密碼`,也可以將`密碼`翻譯成`英文`文字,兩人通過`郵局`將文字轉換成的密碼內容傳遞給對方,再通過`翻譯機`來解密獲得自己認識的文字內容,
這樣兩人又可以互相通信了。
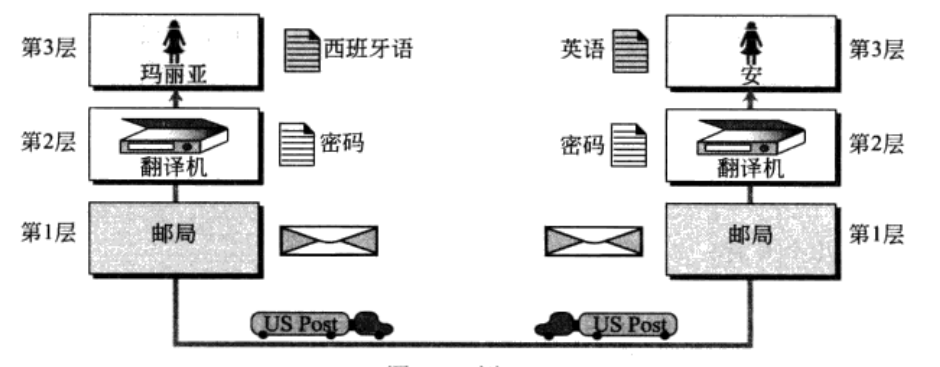
### 網絡協議分層
> 計算機網絡的通信就如同`瑪利亞`與`安`之間的通信一樣,需要跨越很多物理硬件的差異才能與另外一臺主機通信。
一種新技術的誕生,通常需要提前制定好實現的標準規范,這樣才能保證不同的人實現的結果就有一致性,比如通信模型,這種一致性的好處就是雖然實現方式不同,但是結果是二者可以互相正確通信。
試想一下,我們生活中的電源插座、`USB`插座或者手機充電接口都是同樣的道理。
再比如`蘋果`手機的充電接口和`Android`的充電接口的不一致,其實是有意為之,帶來的結果**不兼容!不兼容!不兼容!** , 生活中遇見不兼容的問題是多磨讓人頭疼的事情!看看下面這些USB接口吧。

為了解決**不兼容**等一切網絡通信問題,達到讓所有計算機可以在網絡中相互通信, 一個叫做`OSI`模型的網絡通信模型誕生了,這個模型是由國際標準化組織(ISO)召集了大約全世界四分之三的國家代表參與下共同制定的(1984年發布了著名的ISO/IEC 7498標準)。
當時的網絡通信參考模型并不是只有一種,在`OSI`參考模型之前已經有了`TCP/IP`參考模型(也被稱為互聯網協議套件或TCP/IP協議族)。
根據維基百科資料,1983年1月1日,互聯網前身ARPA網中的通信方式換成了`TCPIP模型`,并且在現在的互聯網中經受住了競爭的考研也就是說`TCPIP模型`在`OSI`參考模型指定前就已經被實現并應用了,而且通信模型相對更加容易實現。
最終歷史并沒有給`OSI`模型表現的機會,`OSI`參考模型只是作為學習研究的參考模型。
## TCP/IP協議族
翻一翻《計算機網絡》書中的這張圖,大家可以參考了解下。
`OSI`模型: 七層協議棧
`TCPIP`模型: 四層協議棧
`教科書`模型: 五層協議棧,這是結合了二者模型的學習參考模型。《TCPIP協議棧》教材也是按照五層講解每層協議的。
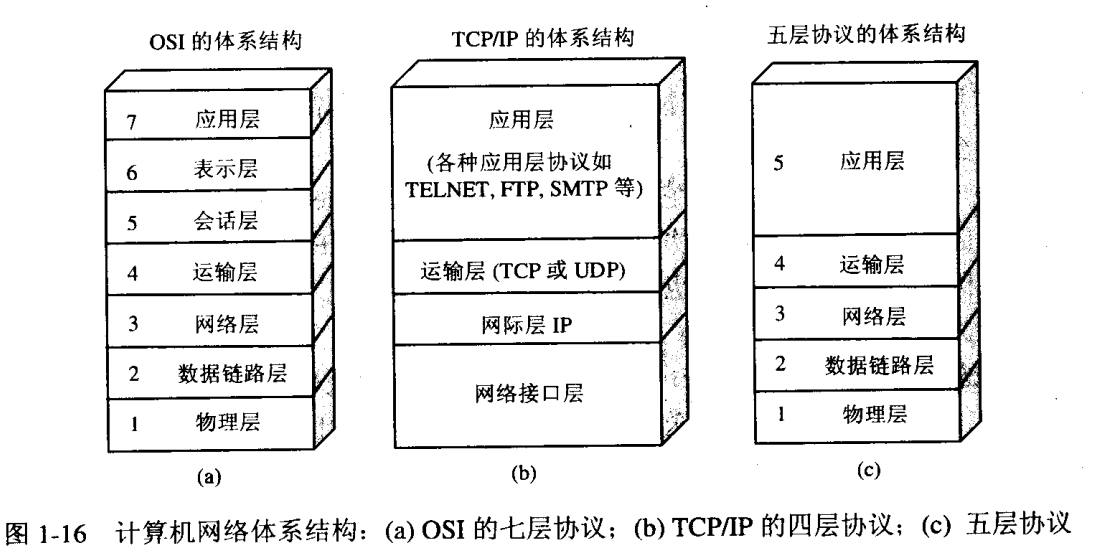
### `TCP/IP協議棧`的體系結構(以五層為例)
> 七層OSI結構為理論學習使用,四層結構為現在計算機實際應用結構,而五層體系結構為教科使用
- `物理層`:直接對接網絡物理硬件(例如:網線、光纖等),保證數字信號與電信號在物理硬件上的正確傳輸,例如低成本的集線器就是工作在物理層,發送數據時都是沒有針對性的,而是采用廣播方式發送給連接在集線器上的所有主機。
- `數據鏈路層`:負責`相鄰節點`之間的點對點幀(frame)數據傳輸,通信的地址為物理網卡的MAC地址,例如家用的交換機就是在這一層工作,它可以根據目標MAC地址有針對的發送到特定端口,而不必廣播給所有接入主機。
- `網絡層`:負責為分組交換網絡上的不同主機提供通信服務,使用的IP協議將`IP數據報`傳輸到目標主機上,IP地址的目的是識別主機的網絡位置。例如路由器也是工作在這一層的。
- `傳輸層`: 知道主機位置了,那是什么應用服務之間在通信呢,傳輸層就是為兩個主機之間進程通信提供服務的。服務的標識為端口號,協議主要包含`TCP`、`UDP`協議。例如網絡硬件負載均衡設備是工作在這一層完成服務的負載均衡的。
- `應用層`: 知道兩個主機是哪個進程在通信了還不夠,還要知道他們是使用什么協議在通信的,這個協議的實現就是應用層提供的服務,比如 `HTTP、FTP、SSH、SMTP` 等等協議。
**主機之間的網絡通信依賴于每一層的協議,這一系列的協議就是按照`TCP/IP協議族`中協議規范實現的。**
下圖為實際兩臺主機之間的網絡交互過程描述:
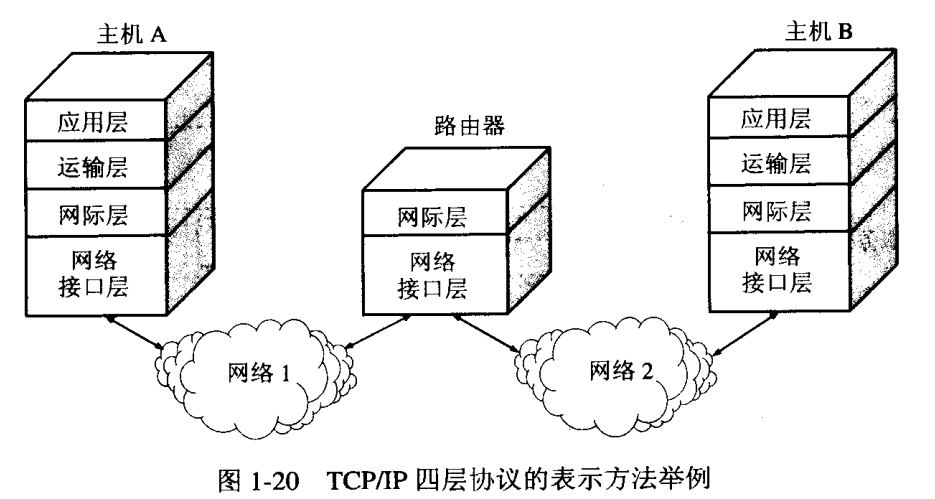
下圖為Wireshark工具下分析消息包的層次結構(每層都對應著一種協議格式):

數據通過這種協議棧的層層包裹與解析,可以清晰無誤的傳達需要傳達的數據,不會因為協議在中途解析識別錯誤而丟失的情況,如果數據因為某種原因無法傳達到目的地,也會有對應的協議保證可以及時發現匯報。
### RFC文檔
>每一種協議的實現都是有個標準規范,比如我們都要實現一個FTP協議,那么大家都按同一個標準規范來做才能保證不同人的實現功能保證一致,彼此才能正確通信。
每種協議都對應著一個或多個RFC規范文檔,例如: `FTP`協議規范文檔有`RFC959`、`RFC1579`、`RFC2228`等。
`HTTP`協議規范文檔有`RFC2616`、`RFC7540`。
想要閱讀RFC文檔內容可以從這里下載獲取:[RFC文檔下載地址](https://tools.ietf.org/html/)
我們也可以通過查看 [RFC索引文檔](https://tools.ietf.org/rfc/index) 了解搜索關鍵詞找到與之相關的所有的RFC文檔簡要信息。
- 課程大綱
- 入門篇
- 爬蟲是什么
- 為什么要學習爬蟲
- 爬蟲的基本原理
- TCP/IP協議族的基本知識
- HTTP協議基礎知識
- HTML基礎知識
- HTML_DOM基礎知識
- urllib3庫的基本使用
- requests庫的基本使用
- Web頁面數據解析處理方法
- re庫正則表達式的基礎使用
- CSS選擇器參考手冊
- XPath快速了解
- 實戰練習:百度貼吧熱議榜
- 進階篇
- 服務端渲染(CSR)頁面抓取方法
- 客戶端渲染(CSR)頁面抓取方法
- Selenium庫的基本使用
- Selenium庫的高級使用
- Selenium調用JavaScript方法
- Selenium庫的遠程WebDriver
- APP移動端數據抓取基礎知識
- HTTP協議代理抓包分析方法
- Appium測試Android應用基礎環境準備
- Appium爬蟲編寫實戰學習
- Appium的元素相關的方法
- Appium的Device相關操作方法
- Appium的交互操作方法
- 代理池的使用與搭建
- Cookies池的搭建與用法
- 數據持久化-數據庫的基礎操作方法(mysql/redis/mongodb)
- 執行JS之execjs庫使用
- 高級篇
- Scrapy的基本知識
- Scrapy的Spider詳細介紹
- Scrapy的Selector選擇器使用方法
- Scrapy的Item使用方法
- Scrapy的ItemPipeline使用方法
- Scrapy的Shell調試方法
- Scrapy的Proxy設置方法
- Scrapy的Referer填充策略
- Scrapy的服務端部署方法
- Scrapy的分布式爬蟲部署方法
- Headless瀏覽器-pyppeteer基礎知識
- Headless瀏覽器-pyppeteer常用的設置方法
- Headless瀏覽器-反爬應對辦法
- 爬蟲設置技巧-UserAgent設置
- 反爬策略之驗證碼處理方法
- 反爬識別碼之點擊文字圖片的自動識別方法
- 反爬字體處理方法總結
- 防止反爬蟲的設置技巧總結
- 實戰篇
- AJAX接口-CSDN技術博客文章標題爬取
- AJAX接口-拉購網職位搜索爬蟲
- 執行JS示例方法一之動漫圖片地址獲取方法
- JS執行方法示例二完整mangabz漫畫爬蟲示例
- 應用實踐-SOCKS代理池爬蟲
- 落霞小說爬蟲自動制作epub電子書
- 一種簡單的適用于分布式模式知乎用戶信息爬蟲實現示例
- 法律安全說明