[TOC]
# XPath快速了解
>`XPath`是用于瀏覽XML文檔元素和屬性的語言,通過XPath路徑表達式遍歷節點元素就如同在磁盤上訪問文件夾路徑一樣的方便精準表達元素和屬性。
XPath內置了200多個函數幫助我們處理文本、數字、布爾值、日期和時間等類型數據,它的語法規則已經廣泛用于很多語言中。
## XPath術語
- 節點(Node) : 元素、屬性、文本、命名空間、處理指令、注釋和文檔(根)節點。XML文檔被當做節點樹對待,樹的根被稱作文檔節點或者根節點。
- 基本值(原子值, Atomic value): 無父或無子的節點。
- 項目(Items):基本值或者節點都可以稱為一個`item`項目。
- 節點關系: 父(Parent)、子(Children)、同胞(Sibling)、先輩(Ancestor)、后代(Descendant)
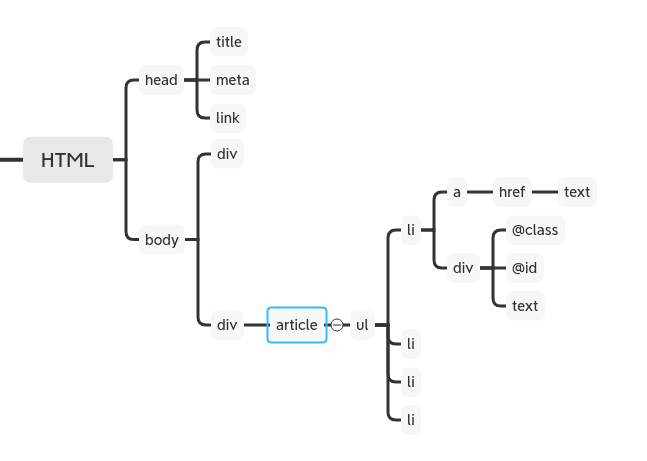
以`articlie`節點為例,父節點為`div`,子節點為`ul` ,孫子節點為 `li` 。
再以`li/div`節點為例, 節點包含節點有 `@class`屬性節點, `@id`屬性節點和`text`文本無子節點就稱為原子值。
## XPath路徑表達式語法
我們以下面例子了解語法及含義:
```XML
<?xml version="1.0" encoding="ISO-8859-1"?>
<bookstore>
<book>
<title lang="eng">Harry Potter</title>
<price>29.99</price>
</book>
<book>
<title lang="eng">Learning XML</title>
<price>39.95</price>
</book>
</bookstore>
```
### 選取節點
下面列出了最常用的路徑表達式:
| 術語 | 含義 |示例|
| :------------- | :------------- | :------------- |
|node_name|選取`node_name`節點的所有子節點。|bookstore|
|/|從根節點選取。|/html/body/table|
|//|從匹配選擇的當前節點選擇文檔中的節點,而不考慮它們的位置。|//div[@class="article"]|
|\.|選取當前節點。|\./a/@href|
|\.\.|選取當前節點的父節點。|\.\./div[@class="article"]|
|@|選取屬性。|//div[@class="article"]|
來看下下面的路徑表達式例子以及表達式的含義解釋:
| 路徑表達式 | 含義 |
| :------------- | :------------- |
|bookstore|選取 bookstore 元素的所有子節點。|
|/bookstore|選取根元素 bookstore。注釋:假如路徑起始于正斜杠( / ),則此路徑始終代表到某元素的絕對路徑!|
|bookstore/book|選取屬于 bookstore 的子元素的所有 book 元素。|
|//book|選取所有 book 子元素,而不管它們在文檔中的位置。|
|bookstore//book|選擇屬于 bookstore 元素的后代的所有 book 元素,而不管它們位于 bookstore 之下的什么位置。|
|//@lang|選取名為 lang 的所有屬性。|
### 謂語(Predicates)
謂語用來查找某個特定的節點或者包含某個指定的值的節點。
謂語被嵌在方括號中。
|路徑表達式 |結果 |
| :----| :----|
|/bookstore/book[1] |選取屬于 bookstore 子元素的第一個 book 元素。 |
|/bookstore/book[last()] |選取屬于 bookstore 子元素的最后一個 book 元素。 |
|/bookstore/book[last()-1] |選取屬于 bookstore 子元素的倒數第二個 book 元素。 |
|/bookstore/book[position()< 3] |選取最前面的兩個屬于 bookstore 元素的子元素的 book 元素。 |
|//title[@lang] |選取所有擁有名為 lang 屬性的 title 元素。 |
|//title[@lang='eng'] |選取所有 title 元素,且這些元素擁有值為 eng 的 lang 屬性。 |
|/bookstore/book[price>35.00] |選取 bookstore 元素的所有 book 元素,且其中的 price 元素的值須大于 35.00。 |
|/bookstore/book[price>35.00]/title |選取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值須大于 35.00。 |
### 選取通配符
|通配符 |描述 |
| :----| :----|
|* |匹配任何元素節點。 |
|@* |匹配任何屬性節點。 |
|node() |匹配任何類型的節點。 |
示例:
|路徑表達式 |結果 |
| :----| :----|
|/bookstore/* |選取 bookstore 元素的所有子元素。 |
|//* |選取文檔中的所有元素。 |
### 多個節點選取方法
> 過在路徑表達式中使用“|”運算符,您可以選取若干個路徑。
|路徑表達式 |結果 |
| :----| :----|
|//book/title \| //book/price |選取 book 元素的所有 title 和 price 元素。 |
|//title \| //price |選取文檔中的所有 title 和 price 元素。 |
## XPath軸(Axes)
軸可定義相對于當前節點的節點集。
|軸名稱(axisname) |含義 |
| :----| :----|
|ancestor |選取當前節點的所有先輩(父、祖父等)。 |
|ancestor-or-self |選取當前節點的所有先輩(父、祖父等)以及當前節點本身。 |
|attribute |選取當前節點的所有屬性。 |
|child |選取當前節點的所有子元素。 |
|descendant |選取當前節點的所有后代元素(子、孫等)。 |
|descendant-or-self |選取當前節點的所有后代元素(子、孫等)以及當前節點本身。 |
|following |選取文檔中當前節點的結束標簽之后的所有節點。 |
|namespace |選取當前節點的所有命名空間節點。 |
|parent |選取當前節點的父節點。 |
|preceding |選取文檔中當前節點的開始標簽之前的所有節點。 |
|preceding-sibling |選取當前節點之前的所有同級節點。 |
|self |選取當前節點。 |
實際上軸的這些名稱可以通過:`.` , `..` , `@` , `//` 表達出來,很少會使用這些名稱。
### 節點測試(nodetest)
> 想了解更多,可以來了解[w3中關于note-tests詳細說明](https://www.w3.org/TR/2017/REC-xpath-31-20170321/#node-tests)
定義:節點測試的另一種形式稱為 種類測試,可以根據節點的種類,名稱和類型注釋選擇節點。
種類測試的語法和語義在2.5.4 SequenceType語法和2.5.5 SequenceType中進行了描述。
在節點測試中使用同類測試時,僅選擇指定軸上與種類測試匹配的那些節點。
下面顯示的是可能在路徑表達式中使用的種類測試的幾個示例:
|節點測試名 | 含義|
| :----| :----|
|node() |匹配任何節點。 |
|text() |匹配任何文本節點。 |
|comment() |匹配任何評論節點。 |
|namespace-node() |匹配任何名稱空間節點。 |
|element() |匹配任何元素節點。 |
|schema-element(person)|匹配,其名稱是任何元素節點 person(或者是中置換組 為首person),其類型標注相同(或衍生自)聲明的類型的的person 元素中的在范圍內的元素聲明。|
|element(person)|匹配名稱為的任何元素節點 person,無論其類型注釋如何。|
|element(person, surgeon)|匹配任何名稱為person,類型注釋為 surgeon或從中派生的非空元素節點surgeon。|
|element(*, surgeon)|匹配其類型注釋為surgeon(或從中派生surgeon)的任何非修剪元素節點,無論其名稱如何。|
|attribute() |匹配任何屬性節點。 |
|attribute(price) |匹配屬性名為price的屬性節點,無論其類型注釋如何。 |
|attribute(*,xs:decimal) |匹配任何類型注釋為xs:decimal(或從中派生xs:decimal)的屬性,無論其名稱如何。 |
|document-node() |匹配任何文檔節點。 |
|document-node(element(book)) |匹配任何內容由滿足種類測試的 元素元素組成的文檔節點,該元素元素element(book)與零個或多個注釋和處理指令交織在一起。|
其中我們比較常用的可能就是`text()`,提取節點文本信息返回結果為`列表格式`(保留文本的空白符)。
另外需要說明的是`XPath`的`string(arg)`函數,這個函數返回節點內部的字符串信息,也就是返回了`字符串類型數據`。
我們來說下`text()`和`fn:string(arg)`的區別:
1. 含義不同: `text()`是`種類測試`,`string(arg)`是`XPath函數`,所以可以在`XPath`表達式中使用結合使用`text()`,而`string()`不能。
2. 返回結果集類型不同: `text()`返回的是文本列表類型(一個節點也會返回一個元素的列表),`string()`返回的是字符串類型。
### 位置路徑表達式
位置路徑可以是絕對的,也可以是相對的。
絕對路徑起始于正斜杠( / ),而相對路徑不會這樣。在兩種情況中,位置路徑均包括一個或多個步,每個步均被斜杠分割:
絕對位置路徑:
```
/step/step/...
```
相對位置路徑:
```
step/step/...
```
每個步均根據當前節點集之中的節點來進行計算。
*** 步(step)包括:***
- 軸(axis) : 定義所選節點與當前節點之間的樹關系
- 節點測試(node-test) : 識別某個軸內部的節點
- 零個或者更多謂語(predicate): 更深入地提煉所選的節點集
路徑表達式中的一步(`step`)的語法:
```
軸名稱::節點測試[謂語]
axisname::nodetest[predicate]
```
**實例**
|例子 |結果 |
| :----| :----|
|child::book |選取所有屬于當前節點的子元素的 book 節點。 |
|attribute::lang |選取當前節點的 lang 屬性。 |
|child:: * |選取當前節點的所有子元素。 |
|attribute:: * |選取當前節點的所有屬性。 |
|child::text() |選取當前節點的所有文本子節點。 |
|child::node() |選取當前節點的所有子節點。 |
|descendant::book |選取當前節點的所有 book 后代。 |
|ancestor::book |選擇當前節點的所有 book 先輩。 |
|ancestor-or-self::book |選取當前節點的所有 book 先輩以及當前節點(如果此節點是 book 節點) |
|child:: */child::price |選取當前節點的所有 price 孫節點。 |
## XPath運算符
> XPath 表達式可返回節點集、字符串、邏輯值以及數字。
有了運算符就可以構建邏輯表達式來復雜化我們的匹配條件了。
|運算符 |描述 | 實例 |返回值 |
| :----| :----| :----| :----|
|\| |計算兩個節點集 |//book \| //cd |返回所有擁有 book 和 cd 元素的節點集 |
|+ |加法 |6 + 4 |10 |
|- |減法 |6 - 4 |2 |
|* |乘法 |6 * 4 |24 |
|div |除法 |8 div 4 |2 |
|= |等于 |price=9.80 |如果 price 是 9.80,則返回 true。如果 price 是 9.90,則返回 false。 |
|!= |不等于 |price!=9.80 |如果 price 是 9.90,則返回 true。如果 price 是 9.80,則返回 false。 |
|< |小于 |price<9.80 |如果 price 是 9.00,則返回 true。如果 price 是 9.90,則返回 false。 |
|<= |小于或等于 |price<=9.80 |如果 price 是 9.00,則返回 true。如果 price 是 9.90,則返回 false。 |
|> |大于 |price>9.80 |如果 price 是 9.90,則返回 true。如果 price 是 9.80,則返回 false。 |
|>= |大于或等于 |price>=9.80 |如果 price 是 9.90,則返回 true。如果 price 是 9.70,則返回 false。 |
|or |或 |price=9.80 or price=9.70 |如果 price 是 9.80,則返回 true。如果 price 是 9.50,則返回 false。 |
|and |與 |price>9.00 and price<9.90 |如果 price 是 9.80,則返回 true。如果 price 是 8.50,則返回 false。 |
|mod |計算除法的余數 |5 mod 2 |1 |
---
## XPath函數
1. 模糊查詢`fn:contains(string1,string2)` :如果 string1 包含 string2,則返回 true,否則返回 false。
2. 小寫轉換`fn:lower-case(string)` : 把 string 參數轉換為小寫。
3. 字符翻譯`fn:translate(string1,string2,string3)`, 把 string1 中的 string2 替換為 string3。 例子:translate('12:30','0123','abcd'),結果:'bc:da'。
4. 字符串替換:`fn:replace(string,pattern,replace)`, 把指定的模式替換為 replace 參數,并返回結果。例子:replace("Bella Italia", "l", "\*") 結果:'Be\*\*a Ita\*ia'。
5. 字符串轉換函數`fn:string(arg)` , 返回參數的字符串值。參數可以是`數字`、`邏輯值`或`節點集`。
更多函數可以訪問[w3schools_xsl_functions](https://www.w3schools.com/xml/xsl_functions.asp)查看。
學到這里,如果怕記不住那就多練習,還可以記住這個 [XPath cheetsheet](https://www.learnhard.cn/cheetsheet/xpath.html) 網頁,需要的時候快速查看一下。
## XPath實例練習
1. 按照節點屬性定位
```
//a[text()='登錄']
//div[contains(@class,'blog-content-box')]
//span[@id='name' or text()='name']
```
2. 提取某節點下所有文本信息
例如: `<div id="test2">美女,<font color=red>你的微信是多少?</font><div>`
```
# 獲取字符串數據("美女,你的微信是多少")
data = selector.xpath('//div[@id="test2"]')[0]
info = data.xpath('string(.)')
# 獲取字符串列表["美女,","你的微信是多少"]
info = selector.xpath('//div[@id="test2"]/text()')
```
3. 取屬性值(`@attr_name`)
```
# 獲取超鏈接的屬性href地址
value1 = html.xpath('//a/@href')
value2 = html.xpath('//img/@src')
value3 = html.xpath('//div[2]/span/@id')
```
- 課程大綱
- 入門篇
- 爬蟲是什么
- 為什么要學習爬蟲
- 爬蟲的基本原理
- TCP/IP協議族的基本知識
- HTTP協議基礎知識
- HTML基礎知識
- HTML_DOM基礎知識
- urllib3庫的基本使用
- requests庫的基本使用
- Web頁面數據解析處理方法
- re庫正則表達式的基礎使用
- CSS選擇器參考手冊
- XPath快速了解
- 實戰練習:百度貼吧熱議榜
- 進階篇
- 服務端渲染(CSR)頁面抓取方法
- 客戶端渲染(CSR)頁面抓取方法
- Selenium庫的基本使用
- Selenium庫的高級使用
- Selenium調用JavaScript方法
- Selenium庫的遠程WebDriver
- APP移動端數據抓取基礎知識
- HTTP協議代理抓包分析方法
- Appium測試Android應用基礎環境準備
- Appium爬蟲編寫實戰學習
- Appium的元素相關的方法
- Appium的Device相關操作方法
- Appium的交互操作方法
- 代理池的使用與搭建
- Cookies池的搭建與用法
- 數據持久化-數據庫的基礎操作方法(mysql/redis/mongodb)
- 執行JS之execjs庫使用
- 高級篇
- Scrapy的基本知識
- Scrapy的Spider詳細介紹
- Scrapy的Selector選擇器使用方法
- Scrapy的Item使用方法
- Scrapy的ItemPipeline使用方法
- Scrapy的Shell調試方法
- Scrapy的Proxy設置方法
- Scrapy的Referer填充策略
- Scrapy的服務端部署方法
- Scrapy的分布式爬蟲部署方法
- Headless瀏覽器-pyppeteer基礎知識
- Headless瀏覽器-pyppeteer常用的設置方法
- Headless瀏覽器-反爬應對辦法
- 爬蟲設置技巧-UserAgent設置
- 反爬策略之驗證碼處理方法
- 反爬識別碼之點擊文字圖片的自動識別方法
- 反爬字體處理方法總結
- 防止反爬蟲的設置技巧總結
- 實戰篇
- AJAX接口-CSDN技術博客文章標題爬取
- AJAX接口-拉購網職位搜索爬蟲
- 執行JS示例方法一之動漫圖片地址獲取方法
- JS執行方法示例二完整mangabz漫畫爬蟲示例
- 應用實踐-SOCKS代理池爬蟲
- 落霞小說爬蟲自動制作epub電子書
- 一種簡單的適用于分布式模式知乎用戶信息爬蟲實現示例
- 法律安全說明