
## Java線程池概念
顧名思義,管理線程的池子,相比于手工創建、運行線程,使用線程池,有如下優點
* 降低線程創建和銷毀線程造成的開銷
* 提高響應速度。任務到達時,相對于手工創建一個線程,直接從線程池中拿線程,速度肯定快很多
* 提高線程可管理性。線程是稀缺資源,如果無限制地創建,不僅會消耗系統資源,還會降低系統穩定性,使用線程池可以進行統一分配、調優和監控
## Java線程池創建
無論是創建何種類型線程池(`FixedThreadPool`、`CachedThreadPool`...),均會調用`ThreadPoolExecutor`構造函數,下面詳細解讀各個參數的作用
```
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), defaultHandler);
}
```
* **corePoolSize**:核心線程最大數量,通俗點來講就是,線程池中**常駐線程**的最大數量
* **maximumPoolSize**:線程池中運行最大線程數(包括核心線程和非核心線程)
* **keepAliveTime**:線程池中空閑線程(僅適用于非核心線程)所能存活的最長時間
* **unit**:存活時間單位,與keepAliveTime搭配使用
* **workQueue**:存放任務的阻塞隊列
* **handler**:線程池飽和策略
## 線程池執行流程
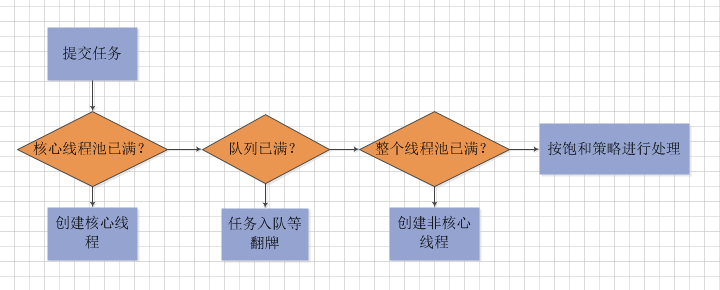
當提交一個新任務,線程池的處理流程如下:
* 判斷線程池中核心線程數是否已達閾值`corePoolSize`,若否,則創建一個新核心線程執行任務
* 若核心線程數已達閾值`corePoolSize`,判斷阻塞隊列`workQueue`是否已滿,若未滿,則將新任務添加進阻塞隊列
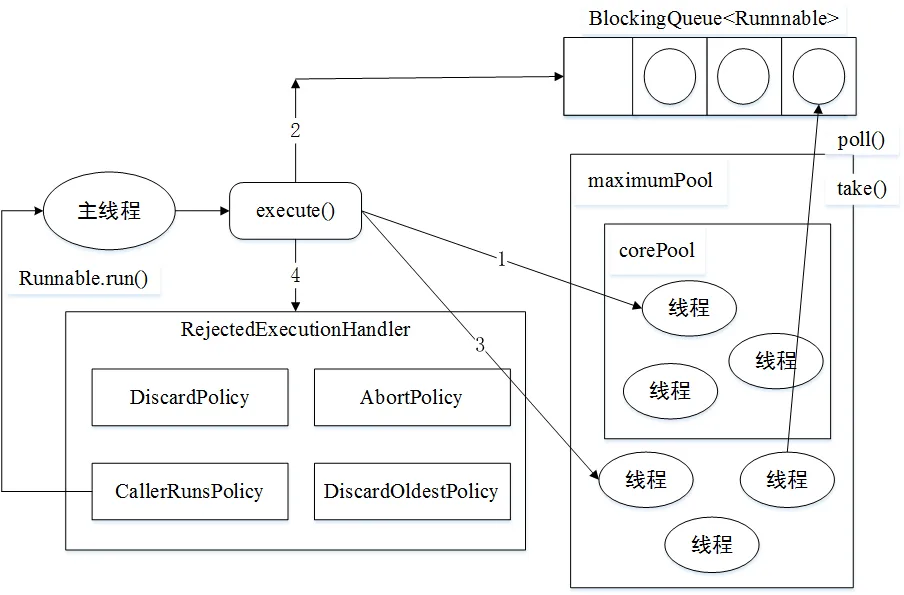
* 若滿,再判斷,線程池中線程數是否達到閾值`maximumPoolSize`,若否,則新建一個非核心線程執行任務。若達到閾值,則執行**線程池飽和策略**。
線程池飽和策略分為一下幾種:
1. AbortPolicy:直接拋出一個異常,**默認策略**
2. DiscardPolicy: 直接丟棄任務
3. DiscardOldestPolicy:拋棄下一個將要被執行的任務(**最舊任務**)
4. CallerRunsPolicy:主線程中執行任務
從流程角度,更形象的圖:
從結構角度,更形象的圖:
## 幾種典型的工作隊列
* **ArrayBlockingQueue**:使用數組實現的有界阻塞隊列,特性**先進先出**
* **LinkedBlockingQueue**:使用鏈表實現的阻塞隊列,特性先進先出,可以設置其容量,默認為`Interger.MAX_VALUE`,特性**先進先出**
* **PriorityBlockingQueue**:使用平衡二叉樹**堆**,實現的具有**優先級**的無界阻塞隊列
* **DelayQueue**:無界阻塞延遲隊列,隊列中每個元素均有過期時間,當從隊列獲取元素時,只有過期元素才會出隊列。隊列頭元素是最塊要過期的元素。
* **SynchronousQueue**:**一個不存儲元素的阻塞隊列**,每個插入操作,必須等到另一個線程調用移除操作,否則插入操作一直處于阻塞狀態
## 幾種典型的線程池
1. SingleThreadExecutor
```
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
```
創建單個線程。它適用于需要保證順序地執行各個任務;并且在任意時間點,不會有多個線程是活動的應用場景。
`SingleThreadExecutor`的`corePoolSize`和`maximumPoolSize`被設置為1,使用無界隊列`LinkedBlockingQueue`作為線程池的工作隊列。
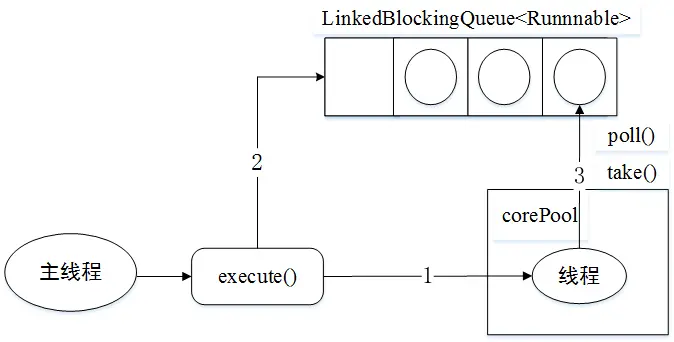
* 當線程池中沒有線程時,會創建一個新線程來執行任務。
* 當前線程池中有一個線程后,將新任務加入`LinkedBlockingQueue`
* 線程執行完第一個任務后,會在一個無限循環中反復從`LinkedBlockingQueue`獲取任務來執行。
**使用場景**:適用于串行執行任務場景
2. FixedThreadPool
```
public static ExecutorService newFixedThreadPool(int nThreads, ThreadFactory threadFactory) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(),
threadFactory);
}
```
`corePoolSize`等于`maximumPoolSize`,所以**線程池中只有核心線程**,使用無界阻塞隊列`LinkedBlockingQueue`作為工作隊列
`FixedThreadPool`是一種線程數量固定的線程池,當線程處于空閑狀態時,他們并不會被回收,除非線程池被關閉。當所有的線程都處于活動狀態時,新的任務都會處于等待狀態,直到有線程空閑出來。
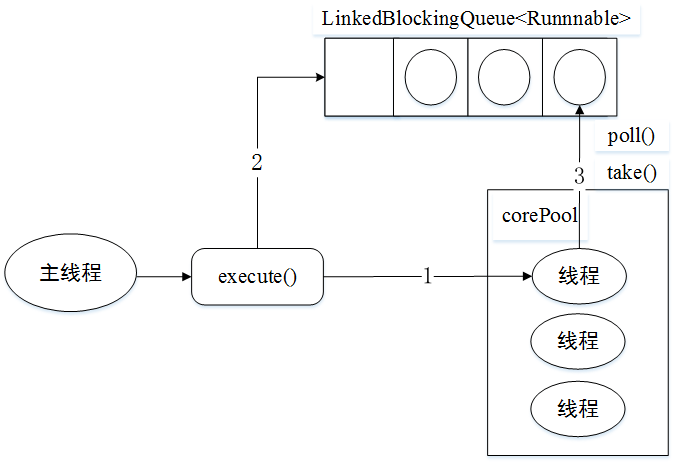
* 如果當前運行的線程數少于`corePoolSize`,則創建新線程來執行任務。
* 在線程數目達到`corePoolSize`后,將新任務放到`LinkedBlockingQueue`阻塞隊列中。
* 線程執行完(1)中任務后,會在循環中反復從`LinkedBlockingQueue`獲取任務來執行。
**使用場景**:適用于處理CPU密集型的任務,確保CPU在長期被工作線程使用的情況下,盡可能的少的分配線程,即適用執行長期的任務。
3. CachedThreadPool
```
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
```
核心線程數為0,總線程數量閾值為`Integer.MAX_VALUE`,即**可以創建無限的非核心線程**
**執行流程**
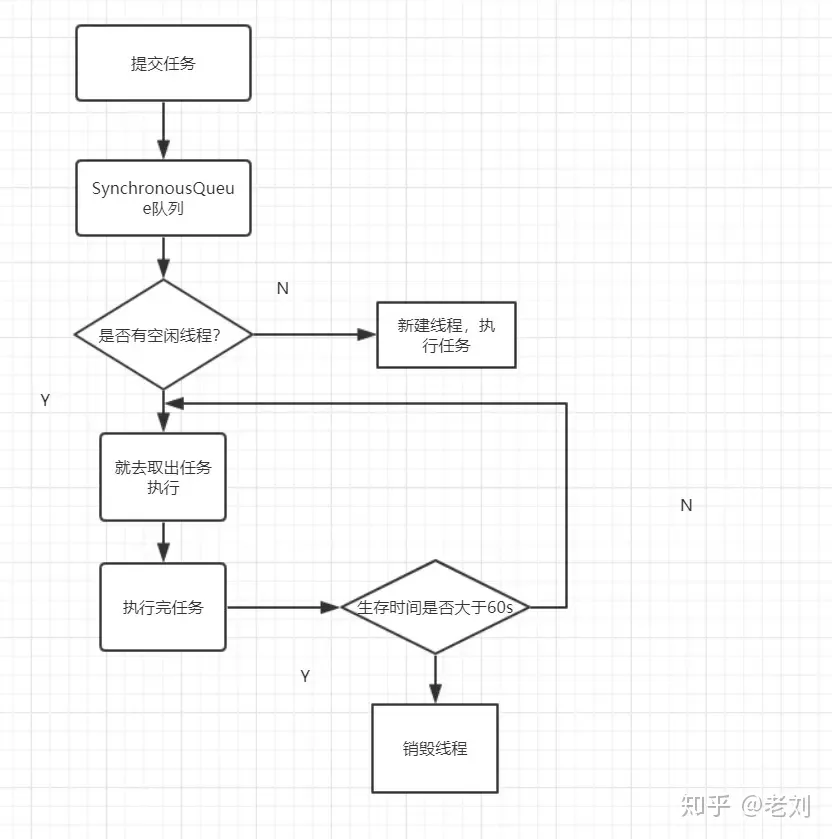
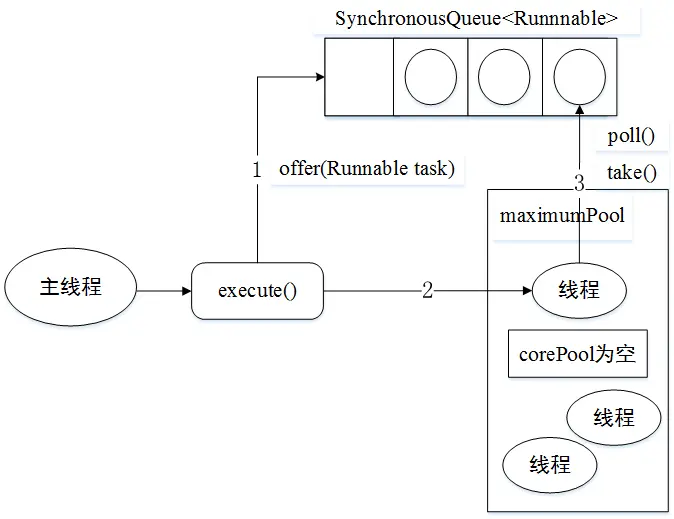
* 先執行`SynchronousQueue`的`offer`方法提交任務,并查詢線程池中是否有空閑線程來執行`SynchronousQueue`的`poll`方法來移除任務。如果有,則配對成功,將任務交給這個空閑線程
* 否則,配對失敗,創建新的線程去處理任務
* 當線程池中的線程空閑時,會執行`SynchronousQueue`的`poll`方法等待執行`SynchronousQueue`中新提交的任務。若等待超過60s,空閑線程就會終止
流程形象圖
### 結構形象圖
**使用場景**:**執行大量短生命周期任務**。因為`maximumPoolSize`是無界的,所以提交任務的速度 > 線程池中線程處理任務的速度就要不斷創建新線程;每次提交任務,都會立即有線程去處理,因此`CachedThreadPool`適用于處理大量、耗時少的任務。
4. ScheduledThreadPoolExecutor
```
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) {
return new ScheduledThreadPoolExecutor(corePoolSize);
}
public ScheduledThreadPoolExecutor(int corePoolSize) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue());
}
```
線程總數閾值為`Integer.MAX_VALUE`,工作隊列使用`DelayedWorkQueue`,非核心線程存活時間為0,所以**線程池僅僅包含固定數目的核心線程。**
兩種方式提交任務:
* scheduleAtFixedRate: 按照固定速率周期執行
* scheduleWithFixedDelay:上個任務延遲固定時間后執行
**使用場景**:周期性執行任務,并且需要限制線程數量的場景
- 開發語言
- java
- Java基礎篇
- Java多線程篇
- 進程和線程的區別,進程間如何通信
- 什么是線程上下文切換
- 什么是死鎖
- 死鎖的必要條件
- Synchrpnized和lock的區別
- 什么是AQS鎖
- 為什么AQS使用的雙向鏈表
- 有哪些常見的AQS鎖
- sleep()和wait()的區別
- yield()和join()區別
- Java線程池
- SpringBoot
- spring boot 項目開發常用目錄結構
- Mybatis-Plus
- MyBatisPlus的CRUD操作
- Mybatis-Plus主鍵ID生成策略
- JVM
- JVM組成
- 字節碼文件的組成
- 類的生命周期
- JVM、JRE和JDK
- arthas
- 使用阿里arthas不停機解決線上問題
- Java IO
- php
- 安裝swoole
- composer部分
- windows安裝composer
- composer PSR-4映射
- composer 鏡像同一個版本替換
- composer官方鏡像庫
- swoole部分
- swoole安裝
- thrift部分
- linux下安裝thrift
- PHP使用Thrift
- lnmp部分
- 架構的工作原理
- tp5框架生命周期
- zookeeper部分
- zookeeper安裝
- sort
- TCP和UDP的區別
- 軟件
- xdebug
- vscode+phpstudy+xdebug無法斷點(踩坑記)
- Hyperf框架
- 注解
- 通過注解定義路由
- go
- 開發方案
- 抖音
- 抖音達人視頻發布與統計
- 安全問題
- 微信
- 微信公眾平臺怎樣實現用戶點擊鏈接向公眾號發消息
- CDN加速OSS計費說明
- 程序設計
- 正則表達式
- 面向對象
- 設計模式
- 創建型模式
- 工廠模式
- 單例模式
- 結構型模式
- 適配器模式
- 行為型模式
- 策略模式
- 觀察者模式
- 算法部分
- 位運算
- 排序算法
- 雙指針
- 貪心算法
- 動態規劃
- 二分查找
- 華為題庫
- 技術棧
- mq
- MQ 的優勢和劣勢
- rabbitmq部分
- windows安裝rabbitmq
- RabbitMQ 簡介
- 工作模式
- 高級特性-消息可靠投遞-confirm
- 高級特性-消息可靠投遞-return
- 高級特性-Consumer Ack
- 高級特性-消費端限流
- 高級特性-TTL
- 高級特性-死信隊列
- Centos7下安裝rabbitmq
- 數據庫
- MongoDB
- MongoDB 相關概念
- Mysql
- 索引總結
- MySQL架構圖
- InnoDB和MyISAM的區別
- 索引設計與優化
- 悲觀鎖和樂觀鎖
- mysql如何解除死鎖狀態
- 查詢慢
- 數據庫主鍵的優缺點
- MySQL鎖詳解
- SQL語句分類
- 開查詢賬號
- 數據庫遷移
- MySQL實戰知識點
- mysql清理binlog日志
- 面試總結
- 事務隔離
- 聚集索引與非聚集索引
- B樹和B+樹
- docker
- docker-desktop安裝的坑點
- docker在linux平臺下安裝
- Ubuntu安裝Docker
- 常用命令
- 適用于 Linux 的 Windows 子系統沒有已安裝的分發版
- docker核心架構圖
- docker安裝lnmp環境
- docker安裝redis
- dockerfile
- docker-compose
- 清除容器日志
- linux
- Ubuntu 更換國內源
- centos
- 常用命令
- virtualbox
- 關于VirtualBox安裝Ubuntu時界面顯示不全,沒有下一步選項
- linux復制當前目錄到其子目錄下
- 命令
- cat和>、>>
- crontab命令
- 空間大小查詢命令
- shell登錄和非shell登錄
- nginx
- 正向代理
- 反向代理
- 負載均衡
- 分割Nginx的access.log日志并保留30天一個月時長,自動刪除多余的日志
- linux安裝nginx
- git
- 生成秘鑰
- 常用命令
- Linux中git保存用戶名密碼
- git清除賬號密碼
- 設置git store 存儲賬號密碼
- git submodule 使用小結
- 微服務
- 微服務技術棧
- nacos
- Nacos服務分級存儲模型
- Nacos配置管理-配置熱更新
- Nacos集群搭建
- 微服務保護
- 初識Sentinel
- 隔離和降級
- es
- DSL查詢語法-相關性算法
- DSL查詢語法-FunctionScoreQuery
- DSL查詢語法-BooleanQuery
- 搜索結果處理-排序
- es深度分頁問題
- 自動補全
- elasticsearch 設置密碼
- redis
- redis簡介
- linux安裝redis
- 安裝redis擴展
- redis數據類型
- redis常見問題
- PHP 使用 Redis 實現分布式鎖
- 緩存更新策略
- [ Redis ] AOF 和 RDB 的相關介紹以及相關配置
- 分布式鎖的8大坑
- 分布式鎖-Redisson
- 內存回收
- UV統計
- Redis主從集群
- redis哨兵
- Redis安裝目錄下常見文件
- 通訊原理概述
- windows
- Win系統端口被占用
- Windows10 WSL2限制cpu和內存
- jekins
- 持續集成
- centos卸載gitlab
- jenkins搭配gitlab的webhook實現自動化部署
- 大數據
- Linux集群分發腳本xsync
- hadoop
- hadoop安裝
- hadoop配置文件
- clickhouse
- ClickHouse 安裝部署
- flink
- 數據倉庫
- zookeeper
- zookeeper分布式安裝
- ZK集群啟動停止腳本
- kafka
- kafka分布式安裝
- kafka集群啟動停止腳本
- flume
- flume分布式安裝
- Flume配置
- Flume使用
- maxwell
- Maxwell簡介
- Maxwell部署
- Maxwell使用
- MaxwellBootstrapUtility - Connections could not be acquired from the underlying database
- 線上事故