
raft是一個共識算法(consensus algorithm),所謂共識,就是多個節點對某個事情達成一致的看法,即使是在部分節點故障、網絡延時、網絡分割的情況下。這些年最為火熱的加密貨幣(比特幣、區塊鏈)就需要共識算法,而在分布式系統中,共識算法更多用于提高系統的容錯性,比如分布式存儲中的復制集(replication),在帶著問題學習分布式系統之中心化復制集一文中介紹了中心化復制集的相關知識。raft協議就是一種leader-based的共識算法,與之相應的是leaderless的共識算法。
為了達到易于理解的目標,raft做了很多努力,其中最主要是兩件事情:
問題分解
狀態簡化
?? 問題分解是將"復制集中節點一致性"這個復雜的問題劃分為數個可以被獨立解釋、理解、解決的子問題。在raft,子問題包括,leader election, log replication,safety,membership changes。而狀態簡化更好理解,就是對算法做出一些限制,減少需要考慮的狀態數,使得算法更加清晰,更少的不確定性(比如,保證新選舉出來的leader會包含所有commited log entry)
raft會先選舉出leader,leader完全負責replicated log的管理。leader負責接受所有客戶端更新請求,然后復制到follower節點,并在“安全”的時候執行這些請求。如果leader故障,followes會重新選舉出新的leader。所有節點啟動時都是follower狀態;在一段時間內如果沒有收到來自leader的心跳,從follower切換到candidate,發起選舉;如果收到majority的造成票(含自己的一票)則切換到leader狀態;如果發現其他節點比自己更新,則主動切換到follower。
?? 總之,系統中最多只有一個leader,如果在一段時間里發現沒有leader,則大家通過選舉-投票選出leader。leader會不停的給follower發心跳消息,表明自己的存活狀態。如果leader故障,那么follower會轉換成candidate,重新選出leader。
如果follower在election timeout內沒有收到來自leader的心跳,(也許此時還沒有選出leader,大家都在等;也許leader掛了;也許只是leader與該follower之間網絡故障),則會主動發起選舉。步驟如下:
增加節點本地的 current term ,切換到candidate狀態
投自己一票
并行給其他節點發送 RequestVote RPCs
等待其他節點的回復
?? 在這個過程中,根據來自其他節點的消息,可能出現三種結果
收到majority的投票(含自己的一票),則贏得選舉,成為leader
被告知別人已當選,那么自行切換到follower
一段時間內沒有收到majority投票,則保持candidate狀態,重新發出選舉
?? 第一種情況,贏得了選舉之后,新的leader會立刻給所有節點發消息,廣而告之,避免其余節點觸發新的選舉。在這里,先回到投票者的視角,投票者如何決定是否給一個選舉請求投票呢,有以下約束:
在任一任期內,單個節點最多只能投一票
候選人知道的信息不能比自己的少(這一部分,后面介紹log replication和safety的時候會詳細介紹)
first-come-first-served 先來先得
?? 第二種情況,比如有三個節點A B C。A B同時發起選舉,而A的選舉消息先到達C,C給A投了一票,當B的消息到達C時,已經不能滿足上面提到的第一個約束,即C不會給B投票,而A和B顯然都不會給對方投票。A勝出之后,會給B,C發心跳消息,節點B發現節點A的term不低于自己的term,知道有已經有Leader了,于是轉換成follower。
第三種情況,沒有任何節點獲得majority投票,比如下圖這種情況:
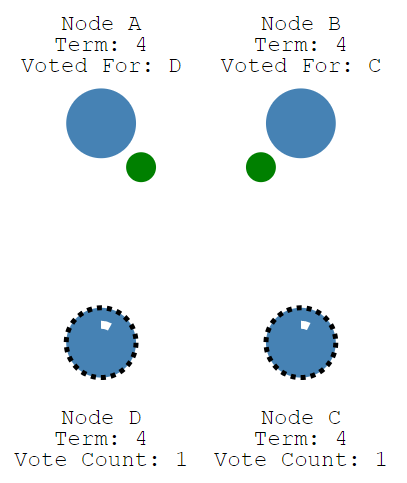
?? 總共有四個節點,Node C、Node D同時成為了candidate,進入了term 4,但Node A投了NodeD一票,NodeB投了Node C一票,這就出現了平票 split vote的情況。這個時候大家都在等啊等,直到超時后重新發起選舉。如果出現平票的情況,那么就延長了系統不可用的時間(沒有leader是不能處理客戶端寫請求的),因此raft引入了randomized election timeouts來盡量避免平票情況。同時,leader-based 共識算法中,節點的數目都是奇數個,盡量保證majority的出現。
- 說明
- 排序
- java實現
- 二分歸并排序
- 快速排序
- js實現
- 冒泡排序 (Bubble Sort)
- 快速排序-js
- ES6-rest參數
- 比較排序
- 堆排序
- 插入排序
- 歸并排序
- 選擇排序
- shellSort
- 排序基礎知識
- 其他
- Rabbit
- chickenProblem
- 漢諾塔
- 取出兩個字符串中開頭相同的部分
- 兩個七進制輸入,輸出七進制
- 二維數組(矩陣)對角線輸出
- 根據概率取值
- 最小編輯距離算法
- 列劃分算法
- 數組去重
- 數組去重1
- 在一天里,鐘表的時針和分針會重合多少次?
- 找第二大問題
- Raft算法
- B-tree
- Leetcode JAVA實現
- leetcode1. 2 Sum
- leetcode2. Add Two Numbers
- leetcode7. Reverse Integer
- leetcode8. String to Integer (atoi)
- leetcode12. Integer to Roman
- leetcode13. Roman to Integer
- leetcode15. 3Sum
- leetcode18. 4Sum
- leetcode20. Valid Parentheses
- leetcode26. Remove Duplicates from Sorted Array
- leetcode27. Remove Element
- leetcode58. Length of Last Word
- leetcode66. Plus One
- leetcode67. Add Binary
- leetcode80. Remove Duplicates from Sorted Array II
- leetcode 88. Merge Sorted Array
- leetcode101. Symmetric Tree
- leetcode104. Maximum Depth of Binary Tree
- leetcode110. Balanced Binary Tree
- leetcode118. Pascal's Triangle
- leetcode119. Pascal's Triangle II
- leetcode121. Best Time to Buy and Sell Stock
- leetcode125. Valid Palindrome
- leetcode136. Single Number
- leetcode144. Binary Tree Preorder Traversal
- leetcode145. Binary Tree Postorder Traversal
- leetcode155. Min Stack
- leetcode169. Majority Element
- leetcode171. Excel Sheet Column Number
- leetcode172. Factorial Trailing Zeroes
- leetcode189. Rotate Array
- leetcode191. Number of 1 Bits
- leetcode202. Happy Number
- leetcode203. Remove Linked List Elements
- leetcode204. Count Primes
- leetcode225. Implement Stack using Queues
- leetcode226. Invert Binary Tree
- leetcode231. Power of Two
- leetcode232. Implement Queue using Stacks
- leetcode234. Palindrome Linked List
- leetcode237. Delete Node in a Linked List
- leetcode242. Valid Anagram
- leetcode258. Add Digits
- leetcode263. Ugly Number
- leetcode283. Move Zeroes
- leetcode292. Nim Game
- leetcode344. Reverse String
- leetcode371. Sum of Two Integers
- leetcode804. Unique Morse Code Words
- Leetcode JS 實現
- Js-leetcode 1. Two Sum
- Js-leetcode 2. Add Two Numbers
- Js-leetcode 10. Regular Expression Matching
- Js-leetcode 14. Longest Common Prefix
- Js-leetcode 17.Letter Combinations of a Phone Number
- Js-leetcode 20. Valid Parentheses
- Js-leetcode 27. Remove Element
- Js-leetcode 30. Substring with Concatenation of All Words
- Js-leetcode 35. Search Insert Position
- Js-leetcode 41. First Missing Positive
- Js-leetcode 48. Rotate Image
- Js-leetcode 53. Maximum Subarray
- Js-leetcode 54. Spiral Matrix
- Js-leetcode 73. Set Matrix Zeroes
- Js-leetcode 75. Sort Colors
- Js-leetcode 85. Maximal Rectangle
- Js-leetcode 89. Gray Code
- Js-leetcode 93.Restore IP Addresses
- Js-leetcode 98. Validate Binary Search Tree
- Js-leetcode 104. Maximum Depth of Binary Tree
- Js-leetcode 118. Pascal's Triangle
- Js-leetcode 121. Best Time to Buy and Sell Stock
- Js-leetcode 136. Single Number
- Js-leetcode 164. Maximum Gap
- Js-leetcode 189. Rotate Array
- Js-leetcode 215. Kth Largest Element in an Array
- Js-leetcode 217. Contains Duplicate
- Js-leetcode 258. Add Digits
- Js-leetcode 263.Ugly Number
- Js-leetcode 283. Move Zeroes
- Js-leetcode 326. Power of Three
- Js-leetcode 434. Number of Segments in a String
- Js-leetcode 459. Repeated Substring Pattern
- Js-leetcode 507. Perfect Number
- Js-leetcode 537. Complex Number Multiplication
- Js-leetcode 541. Reverse String II
- Js-leetcode 551. Student Attendance Record I
- Js-leetcode 557. Reverse Words in a String III
- Js-leetcode 605. Can Place Flowers
- Js-leetcode 606. Construct String from Binary Tree
- Js-leetcode 621. Task Scheduler
- Js-leetcode 622. Design Circular Queue
- Js-leetcode 633. Sum of Square Numbers
- Js-leetcode 657. Robot Return to Origin
- Js-leetcode 682. Baseball Game
- Js-leetcode 686. Repeated String Match
- Js-leetcode 696. Count Binary Substrings
- Js-leetcode 709.To Lower Case.md
- Js-leetcode 771 Jewels and Stones
- Js-leetcode 804.Unique Morse Code Words
- Js-leetcode 867. Transpose Matrix
- Js-leetcode 905. Sort Array By Parity
- Js-leetcode 914. X of a Kind in a Deck of Cards
- Js-leetcode 922. Sort Array By Parity II
- Js-leetcode 1221. Split a String in Balanced Strings
- Js-leetcode 3. Longest substring without repeating characters
- document
- 劉宇波老師--基礎知識
- 算法與數據結構
- 數據機構與算法介紹
- 二叉樹
- 堆
- 鏈表
- 隊列
- 并查集
- 最小生成樹
- 圖論
- 最短路徑
- 總結
- 玩轉數據結構
- 介紹
- 數組
- 棧和隊列
- 玩轉鏈表
- 鏈表與遞歸
- 二分搜索樹
- 集合與映射
- 第8章 優先隊列和堆
- 第9章 線段樹
- 第10章 Trie
- 玩轉算法面試 leetcode題庫分門別類詳細解析
- 第一章 介紹
- 第二章 時間復雜度和空間復雜度
- 第三章
- 深度實戰玩轉算法
- JS數據結構與算法
- 第一章.介紹
- 第二章.字符串
- 第三章.數組
- 第四章
- 第五章.排序
- 第六章.遞歸
- 第七章.棧
- 第八章.隊列
- 第九章.鏈表
- 第十章.矩陣
- 第十一章.二叉樹
- 第十二章.堆
- 極客時間
- 第01課丨數據結構與算法總覽
- 第02課丨訓練準備和復雜度分析
- 第03課丨數組、鏈表、跳表
- 第04課丨棧、隊列、優先隊列、雙端隊列
- 算法基礎
- 哈希表(散列表)
- 異或運算
- leetcode
- KD樹(K-Dimension Tree)
- Rtree
- B站-左神
- 一周刷爆LeetCode,算法大神左神(左程云)耗時100天打造算法與數據結構基礎到高級全家桶教程,直擊BTAJ等一線大廠必問算法面試題真題詳解
- 簡單的排序算法
- 認識Nlog(N)的算法
- 第三節:桶排序及排序算法總結
- 左程云算法課程
- 1 認識復雜度、對數器、二分法與異或運算
- 2 鏈表結構、棧、隊列、遞歸行為、哈希表和有序表
- 10道BAT必問算法面試題
- 超級水王問題
- 78節
- 04鏈表