
## 引言
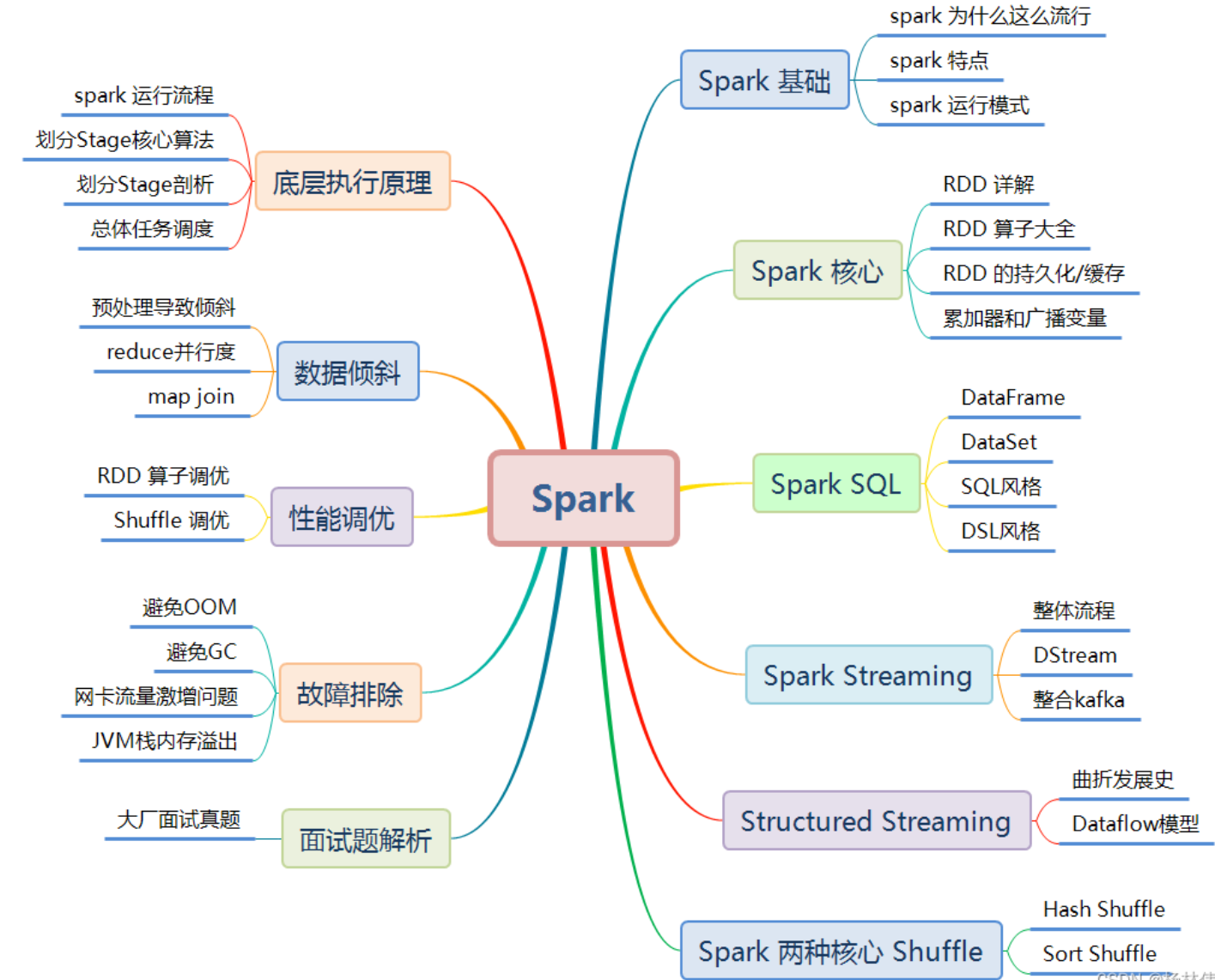
## 1. Spark基礎
### 1.1 Spark 為何物
**Spark 是(flink出現之前)當今大數據領域最活躍、最熱門、最高效的大數據通用計算平臺之一**。
Hadoop 之父 Doug Cutting 指出:Use of MapReduce engine for Big Data projects will decline, replaced by Apache Spark (大數據項目的 MapReduce 引擎的使用將下降,由 Apache Spark 取代)。
### 1.2 Spark VS Hadoop
盡管 `Spark` 相對于 `Hadoop` 而言具有較大優勢,但 `Spark` 并不能完全替代 `Hadoop`,`Spark` 主要用于替代`Hadoop`中的 `MapReduce` 計算模型。存儲依然可以使用 `HDFS`,但是中間結果可以存放在內存中;調度可以使用 `Spark` 內置的,也可以使用更成熟的調度系統 `YARN` 等。
| | *Hadoop* | *Spark* |
| --- | --- | --- |
| **類型** | 分布式基礎平臺, 包含計算, 存儲, 調度 | 分布式計算工具 |
| **場景** | 大規模數據集上的批處理 | 迭代計算, 交互式計算, 流計算 |
| **價格** | 對機器要求低, 便宜 | 對**內存**有要求, 相對較貴 |
| **編程范式** | Map+Reduce, API 較為底層, 算法適應性差 | RDD 組成 DAG 有向無環圖, API 較為頂層, 方便使用 |
| **數據存儲結構** | MapReduce **中間計算結果存在 HDFS 磁盤上, 延遲大** | RDD 中間**運算結果存在內存中 , 延遲小** |
| **運行方式** | Task 以進程方式維護, 任務啟動慢 | Task 以線程方式維護, 任務啟動快 |
實際上,`Spark` 已經很好地融入了 `Hadoop` 生態圈,并成為其中的重要一員,它可以借助于 `YARN` 實現資源調度管理,借助于 `HDFS` 實現分布式存儲。
此外,`Hadoop` 可以使用廉價的、異構的機器來做分布式存儲與計算,但是,`Spark` 對硬件的要求稍高一些,對內存與 `CPU` 有一定的要求。
### 1.3 Spark 優勢及特點
#### 1.3.1 優秀的數據模型和豐富計算抽象
首先看看`MapReduce`,它提供了對數據訪問和計算的抽象,但是對于數據的復用就是簡單的將中間數據寫到一個穩定的**文件系統**中 (例如 `HDFS`),所以會產生數據的復制備份,磁盤的`I/O`以及數據的序列化,所以在遇到需要在多個計算之間復用中間結果的操作時效率就會非常的低。而這類操作是非常常見的,例如迭代式計算,交互式數據挖掘,圖計算等。
因此 `AMPLab` 提出了一個新的模型,叫做 **RDD**。
* **RDD** 是一個可以容錯且并行的數據結構(其實可以理解成分布式的集合,操作起來和操作本地集合一樣簡單),它可以讓用戶顯式的將中間結果數據集保存在 **內存** 中,并且通過控制數據集的分區來達到數據存放處理最優化。同時 `RDD` 也提供了豐富的 `API (map、reduce、filter、foreach、redeceByKey...)`來操作數據集。
**后來 `RDD` 被 `AMPLab` 在一個叫做 `Spark` 的框架中提供并開源。**
#### 1.3.2 完善的生態圈 - fullstack
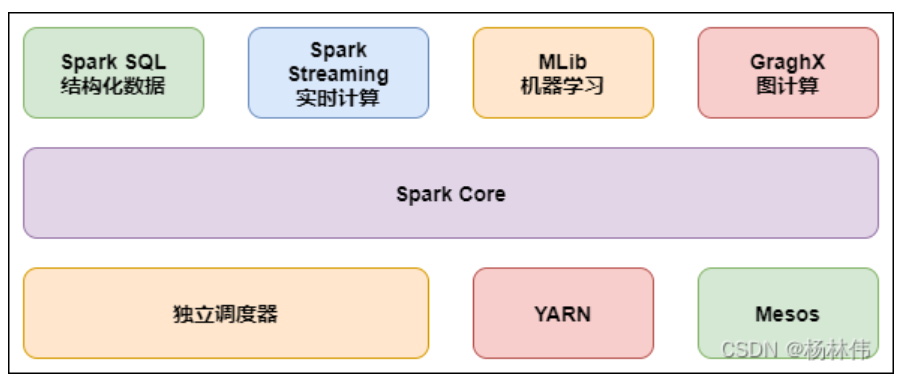
`Spark`有完善的生態圈,如下:
* **Spark Core**(重點):實現了 Spark 的基本功能,包含 RDD、任務調度、內存管理、錯誤恢復、與存儲系統交互等模塊。
* **Spark SQL**(重點):Spark 用來操作結構化數據的程序包。通過 Spark SQL,我們可以使用 SQL 操作數據。
* **Spark Streaming**(重點):Spark 提供的對實時數據進行流式計算的組件。提供了用來操作數據流的 API。
* **Spark MLlib**:提供常見的機器學習 (ML) 功能的程序庫。包括分類、回歸、聚類、協同過濾等,還提供了模型評估、數據導入等額外的支持功能。
* **GraphX(圖計算)**:Spark 中用于圖計算的 API,性能良好,擁有豐富的功能和運算符,能在海量數據上自如地運行復雜的圖算法。
* **集群管理器**:Spark 設計為可以高效地在一個計算節點到數千個計算節點之間伸縮計算。
* **Structured Streaming**:處理結構化流, 統一了離線和實時的 API。
#### 1.3.3 spark 的特點
* **快**:與 Hadoop 的 MapReduce 相比,Spark 基于內存的運算要快 100 倍以上,基于硬盤的運算也要快 10 倍以上。Spark 實現了高效的DAG 執行引擎,可以通過基于內存來高效處理數據流。
* **易用**:Spark 支持 Java、Python、R 和 Scala 的 API,還支持超過 80 種高級算法,使用戶可以快速構建不同的應用。而且 Spark 支持交互式的 Python 和 Scala 的 shell,可以非常方便地在這些 shell 中使用 Spark 集群來驗證解決問題的方法。
* **通用**:Spark 提供了統一的解決方案。Spark 可以用于批處理、交互式查詢 (Spark SQL)、實時流處理 (Spark Streaming)、機器學習(Spark MLlib) 和圖計算(GraphX),這些不同類型的處理都可以在同一個應用中無縫使用。
* **兼容性**:Spark 可以非常方便地與其他的開源產品進行融合。比如,Spark 可以使用 Hadoop 的 YARN 和 Apache Mesos 作為它的資源管理和調度器,并且可以處理所有 Hadoop 支持的數據,包括 HDFS、HBase 和 Cassandra 等。這對于已經部署 Hadoop 集群的用戶特別重要,因為不需要做任何數據遷移就可以使用 Spark 的強大處理能力。
### 1.4 Spark 運行模式
**① local 本地模式 (單機)**
* 學習測試使用
* 分為 local 單線程和 local-cluster 多線程。
**② standalone 獨立集群模式**
* 學習測試使用
* 典型的 Mater/slave 模式。
**③ standalone-HA 高可用模式**
* 生產環境使用
* 基于 standalone 模式,使用 zk 搭建高可用,避免 Master 是有單點故障的。
**④ on yarn 集群模式(90%以上的場景都是應用這種模式)**
* 生產環境使用
* 運行在 yarn 集群之上,由 yarn 負責資源管理,Spark 負責任務調度和計算。
* 好處:計算資源按需伸縮,集群利用率高,共享底層存儲,避免數據跨集群遷移。
**⑤ on mesos 集群模式**
* 國內使用較少
* 運行在 mesos 資源管理器框架之上,由 mesos 負責資源管理,Spark 負責任務調度和計算。
**⑥ on cloud 集群模式**
* 中小公司未來會更多的使用云服務
* 比如 AWS 的 EC2,使用這個模式能很方便的訪問 Amazon 的 S3。
- Introduction
- 快速上手
- Spark Shell
- 獨立應用程序
- 開始翻滾吧!
- RDD編程基礎
- 基礎介紹
- 外部數據集
- RDD 操作
- 轉換Transformations
- map與flatMap解析
- 動作Actions
- RDD持久化
- RDD容錯機制
- 傳遞函數到 Spark
- 使用鍵值對
- RDD依賴關系與DAG
- 共享變量
- Spark Streaming
- 一個快速的例子
- 基本概念
- 關聯
- 初始化StreamingContext
- 離散流
- 輸入DStreams
- DStream中的轉換
- DStream的輸出操作
- 緩存或持久化
- Checkpointing
- 部署應用程序
- 監控應用程序
- 性能調優
- 減少批數據的執行時間
- 設置正確的批容量
- 內存調優
- 容錯語義
- Spark SQL
- 概述
- SparkSQLvsHiveSQL
- 數據源
- RDDs
- parquet文件
- JSON數據集
- Hive表
- 數據源例子
- join操作
- 聚合操作
- 性能調優
- 其他
- Spark SQL數據類型
- 其它SQL接口
- 編寫語言集成(Language-Integrated)的相關查詢
- GraphX編程指南
- 開始
- 屬性圖
- 圖操作符
- Pregel API
- 圖構造者
- 部署
- 頂點和邊RDDs
- 圖算法
- 例子
- 更多文檔
- 提交應用程序
- 獨立運行Spark
- 在yarn上運行Spark
- Spark配置
- RDD 持久化