
## RDD 的依賴關系
`RDD`有兩種依賴,分別為**寬依賴 (`wide dependency/shuffle dependency`) \**和\**窄依賴 (`narrow dependency`)** :

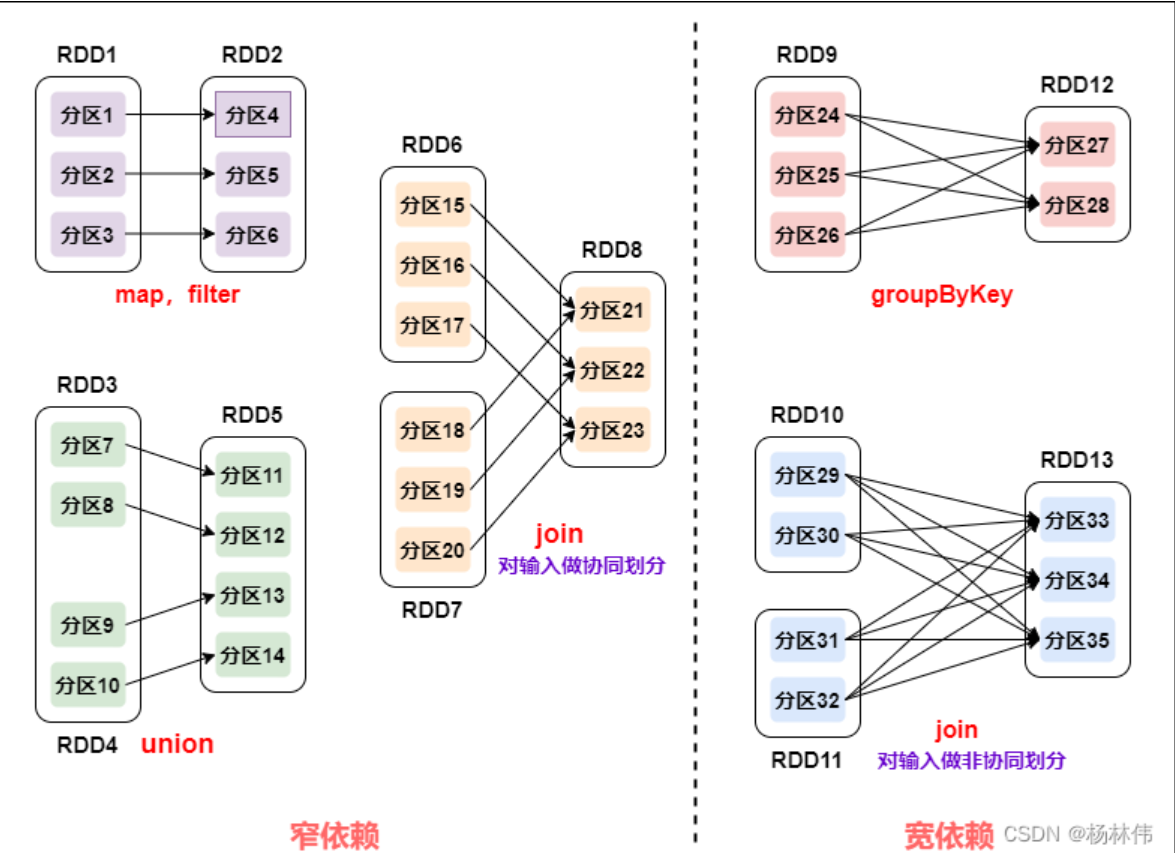
從上圖可以看到:
- **窄依賴**:父 RDD 的一個分區只會被子 RDD 的一個分區依賴;
- **寬依賴**:父 RDD 的一個分區會被子 RDD 的多個分區依賴 (涉及到 shuffle)。
**對于窄依賴:**
- 窄依賴的多個分區可以并行計算;
- 窄依賴的一個分區的數據如果丟失只需要重新計算對應的分區的數據就可以了。
**對于寬依賴:**
- 劃分 Stage(階段) 的依據: 對于寬依賴, 必須等到上一階段計算完成才能計算下一階段。
#### 2.1.7 DAG 的生成和劃分 Stage
##### 2.1.7.1 DAG
**DAG(`Directed Acyclic Graph` 有向無環圖)**:指的是數據轉換執行的過程,有方向,無閉環 (其實就是 RDD 執行的流程);
原始的 RDD 通過一系列的轉換操作就形成了 DAG 有向無環圖,任務執行時,可以按照 DAG 的描述,執行真正的計算 (數據被操作的一個過程)。
**DAG 的邊界**:
- **開始**:通過 SparkContext 創建的 RDD;
- **結束**:觸發 Action,一旦觸發 Action 就形成了一個完整的 DAG。
## DAG 劃分 Stage
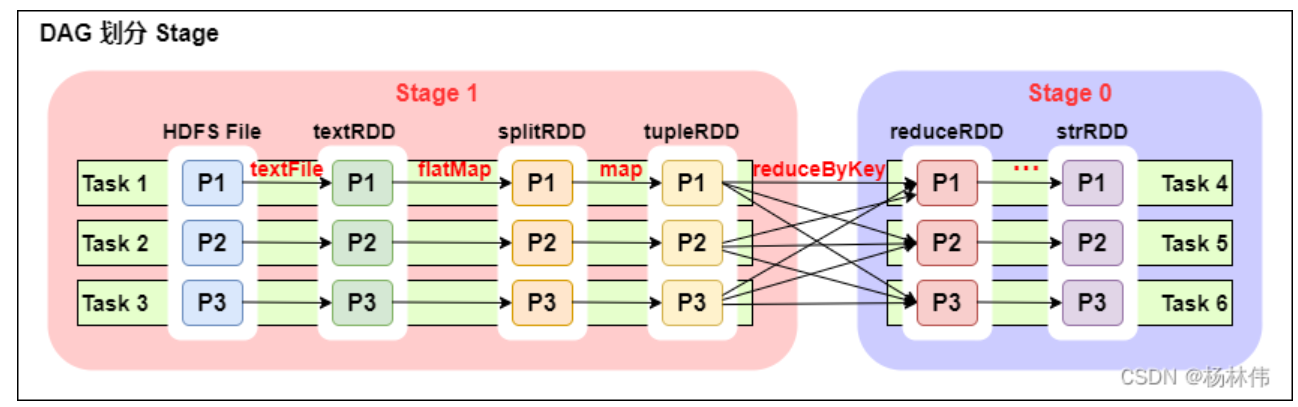
從上圖可以看出:
- 一個 Spark 程序可以有多個 DAG(有幾個 Action,就有幾個 DAG,上圖最后只有一個 Action(圖中未表現), 那么就是一個 DAG);
- 一個 DAG 可以有多個 Stage(根據寬依賴 / shuffle 進行劃分);
- 同一個 Stage 可以有多個 Task 并行執行 (task 數 = 分區數,如上圖,Stage1 中有三個分區 P1、P2、P3,對應的也有三個 Task);
- 可以看到這個 DAG 中只 reduceByKey 操作是一個寬依賴,Spark 內核會以此為邊界將其前后劃分成不同的 Stage;
- 在圖中 Stage1 中,從 textFile 到 flatMap 到 map 都是窄依賴,這幾步操作可以形成一個流水線操作,通過 flatMap 操作生成的 partition 可以不用等待整個 RDD 計算結束,而是繼續進行 map 操作,這樣大大提高了計算的效率。
為什么要劃分 Stage? -- 并行計算
- 一個復雜的業務邏輯如果有 shuffle,那么就意味著前面階段產生結果后,才能執行下一個階段,即下一個階段的計算要依賴上一個階段的數據。那么我們按照 shuffle 進行劃分 (也就是按照寬依賴就行劃分),就可以將一個 DAG 劃分成多個 Stage / 階段,在同一個 Stage 中,會有多個算子操作,可以形成一個 pipeline 流水線,流水線內的多個平行的分區可以并行執行。
如何劃分 DAG 的 stage?
- 對于窄依賴,partition 的轉換處理在 stage 中完成計算,不劃分 (將窄依賴盡量放在在同一個 stage 中,可以實現流水線計算)。
- 對于寬依賴,由于有 shuffle 的存在,只能在父 RDD 處理完成后,才能開始接下來的計算,也就是說需要要劃分 stage。
**總結:**
- Spark 會根據 shuffle / 寬依賴使用回溯算法來對 DAG 進行 Stage 劃分,從后往前,遇到寬依賴就斷開,遇到窄依賴就把當前的 RDD 加入到當前的 stage / 階段中。
具體的劃分算法請參見 AMP 實驗室發表的論文:[《Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing》](http://xueshu.baidu.com/usercenter/paper/show?paperid=b33564e60f0a7e7a1889a9da10963461&site=xueshu_se)
- Introduction
- 快速上手
- Spark Shell
- 獨立應用程序
- 開始翻滾吧!
- RDD編程基礎
- 基礎介紹
- 外部數據集
- RDD 操作
- 轉換Transformations
- map與flatMap解析
- 動作Actions
- RDD持久化
- RDD容錯機制
- 傳遞函數到 Spark
- 使用鍵值對
- RDD依賴關系與DAG
- 共享變量
- Spark Streaming
- 一個快速的例子
- 基本概念
- 關聯
- 初始化StreamingContext
- 離散流
- 輸入DStreams
- DStream中的轉換
- DStream的輸出操作
- 緩存或持久化
- Checkpointing
- 部署應用程序
- 監控應用程序
- 性能調優
- 減少批數據的執行時間
- 設置正確的批容量
- 內存調優
- 容錯語義
- Spark SQL
- 概述
- SparkSQLvsHiveSQL
- 數據源
- RDDs
- parquet文件
- JSON數據集
- Hive表
- 數據源例子
- join操作
- 聚合操作
- 性能調優
- 其他
- Spark SQL數據類型
- 其它SQL接口
- 編寫語言集成(Language-Integrated)的相關查詢
- GraphX編程指南
- 開始
- 屬性圖
- 圖操作符
- Pregel API
- 圖構造者
- 部署
- 頂點和邊RDDs
- 圖算法
- 例子
- 更多文檔
- 提交應用程序
- 獨立運行Spark
- 在yarn上運行Spark
- Spark配置
- RDD 持久化