
# Spark Streaming
Spark streaming是Spark核心API的一個擴展,它對實時流式數據的處理具有可擴展性、高吞吐量、可容錯性等特點。我們可以從kafka、flume、Twitter、 ZeroMQ、Kinesis等源獲取數據,也可以通過由
高階函數map、reduce、join、window等組成的復雜算法計算出數據。最后,處理后的數據可以推送到文件系統、數據庫、實時儀表盤中。事實上,你可以將處理后的數據應用到Spark的[機器學習算法](https://spark.apache.org/docs/latest/mllib-guide.html)、
[圖處理算法](https://spark.apache.org/docs/latest/graphx-programming-guide.html)中去。

在內部,它的工作原理如下圖所示。Spark Streaming接收實時的輸入數據流,然后將這些數據切分為批數據供Spark引擎處理,Spark引擎將數據生成最終的結果數據。
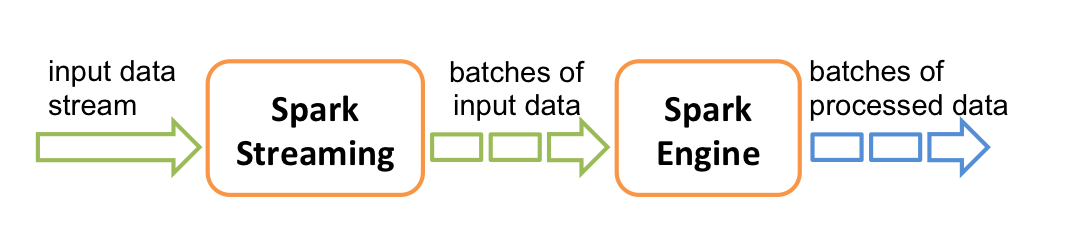
Spark Streaming支持一個高層的抽象,叫做離散流(`discretized stream`)或者`DStream`,它代表連續的數據流。DStream既可以利用從Kafka, Flume和Kinesis等源獲取的輸入數據流創建,也可以
在其他DStream的基礎上通過高階函數獲得。在內部,DStream是由一系列RDDs組成。
本指南指導用戶開始利用DStream編寫Spark Streaming程序。用戶能夠利用scala、java或者Python來編寫Spark Streaming程序。
注意:Spark 1.2已經為Spark Streaming引入了Python API。它的所有DStream transformations和幾乎所有的輸出操作可以在scala和java接口中使用。然而,它只支持基本的源如文本文件或者套接字上
的文本數據。諸如flume、kafka等外部的源的API會在將來引入。
* [一個快速的例子](a-quick-example.md)
* [基本概念](basic-concepts/README.md)
* [關聯](basic-concepts/linking.md)
* [初始化StreamingContext](basic-concepts/initializing-StreamingContext.md)
* [離散流](basic-concepts/discretized-streams.md)
* [輸入DStreams](basic-concepts/input-DStreams.md)
* [DStream中的轉換](basic-concepts/transformations-on-DStreams.md)
* [DStream的輸出操作](basic-concepts/output-operations-on-DStreams.md)
* [緩存或持久化](basic-concepts/caching-persistence.md)
* [Checkpointing](basic-concepts/checkpointing.md)
* [部署應用程序](basic-concepts/deploying-applications.md)
* [監控應用程序](basic-concepts/monitoring-applications.md)
* [性能調優](performance-tuning/README.md)
* [減少批數據的執行時間](performance-tuning/reducing-processing-time.md)
* [設置正確的批容量](performance-tuning/setting-right-batch-size.md)
* [內存調優](performance-tuning/memory-tuning.md)
* [容錯語義](fault-tolerance-semantics/README.md)
- Introduction
- 快速上手
- Spark Shell
- 獨立應用程序
- 開始翻滾吧!
- RDD編程基礎
- 基礎介紹
- 外部數據集
- RDD 操作
- 轉換Transformations
- map與flatMap解析
- 動作Actions
- RDD持久化
- RDD容錯機制
- 傳遞函數到 Spark
- 使用鍵值對
- RDD依賴關系與DAG
- 共享變量
- Spark Streaming
- 一個快速的例子
- 基本概念
- 關聯
- 初始化StreamingContext
- 離散流
- 輸入DStreams
- DStream中的轉換
- DStream的輸出操作
- 緩存或持久化
- Checkpointing
- 部署應用程序
- 監控應用程序
- 性能調優
- 減少批數據的執行時間
- 設置正確的批容量
- 內存調優
- 容錯語義
- Spark SQL
- 概述
- SparkSQLvsHiveSQL
- 數據源
- RDDs
- parquet文件
- JSON數據集
- Hive表
- 數據源例子
- join操作
- 聚合操作
- 性能調優
- 其他
- Spark SQL數據類型
- 其它SQL接口
- 編寫語言集成(Language-Integrated)的相關查詢
- GraphX編程指南
- 開始
- 屬性圖
- 圖操作符
- Pregel API
- 圖構造者
- 部署
- 頂點和邊RDDs
- 圖算法
- 例子
- 更多文檔
- 提交應用程序
- 獨立運行Spark
- 在yarn上運行Spark
- Spark配置
- RDD 持久化