
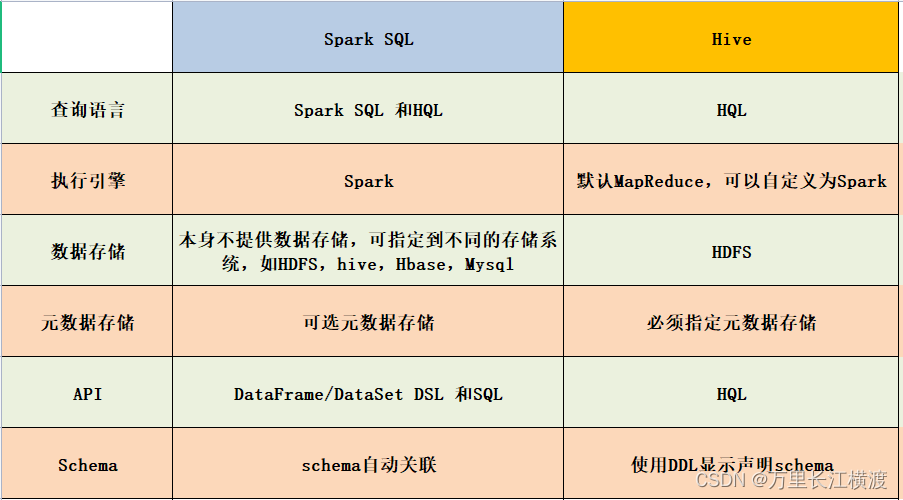
### 一、SparkSQL 和Hive對比
### 二、HiveSQL 和 SparkSQL 的對比
sql 生成 mapreduce 程序必要的過程:解析(Parser)、優化(Optimizer)、執行(Execution)

### 三、hive、hive on spark、spark on hive 三者的比較
* **Hive 引擎包括:默認 MR、tez、spark**
* **Hive on Spark:Hive 既作為存儲元數據又負責 SQL 的解析優化,語法是 HQL 語法,執行引擎變成了 Spark,Spark 負責采用 RDD 執行。**
* **Spark on Hive : Hive 只作為存儲元數據,Spark 負責 SQL 解析優化,語法是 Spark SQL 語法,Spark 負責采用 RDD 執行。**
**【spark on hive 】**
hive 只作為存儲角色,spark 負責 sql 解析優化,底層運行的還是 sparkRDD
具體可以理解為 spark 通過 sparkSQL 使用 hive 語句操作 hive 表,底層運行的還是 sparkRDD,
步驟如下:
1. 通過 sparkSQL,加載 Hive 的配置文件,獲取 Hive 的元數據信息
2. 獲取到 Hive 的元數據信息之后可以拿到 Hive 表的數據
3. 通過 sparkSQL 來操作 Hive 表中的數據
**【hive on spark】**
hive 既作為存儲又負責 sql 的解析優化,spark 負責執行
這里 Hive 的執行引擎變成了 spark,不再是 MR。
這個實現較為麻煩,必須重新編譯 spark 并導入相關 jar 包
目前大部分使用 spark on hive
- Introduction
- 快速上手
- Spark Shell
- 獨立應用程序
- 開始翻滾吧!
- RDD編程基礎
- 基礎介紹
- 外部數據集
- RDD 操作
- 轉換Transformations
- map與flatMap解析
- 動作Actions
- RDD持久化
- RDD容錯機制
- 傳遞函數到 Spark
- 使用鍵值對
- RDD依賴關系與DAG
- 共享變量
- Spark Streaming
- 一個快速的例子
- 基本概念
- 關聯
- 初始化StreamingContext
- 離散流
- 輸入DStreams
- DStream中的轉換
- DStream的輸出操作
- 緩存或持久化
- Checkpointing
- 部署應用程序
- 監控應用程序
- 性能調優
- 減少批數據的執行時間
- 設置正確的批容量
- 內存調優
- 容錯語義
- Spark SQL
- 概述
- SparkSQLvsHiveSQL
- 數據源
- RDDs
- parquet文件
- JSON數據集
- Hive表
- 數據源例子
- join操作
- 聚合操作
- 性能調優
- 其他
- Spark SQL數據類型
- 其它SQL接口
- 編寫語言集成(Language-Integrated)的相關查詢
- GraphX編程指南
- 開始
- 屬性圖
- 圖操作符
- Pregel API
- 圖構造者
- 部署
- 頂點和邊RDDs
- 圖算法
- 例子
- 更多文檔
- 提交應用程序
- 獨立運行Spark
- 在yarn上運行Spark
- Spark配置
- RDD 持久化