
### 前言
主從復制是哨兵`sentinel`和`cluster`的基礎,知其然知其所以然,所以,了解了其中的細節原理和每一步都執行了什么操作,對以后的調試也是很有幫助的。
### 為什么要使用主從
在實際的場景當中單一節點的`redis`容易面臨風險,比如只有一臺`redis`,然后掛了,本來要經過`緩存層`的東西直接把壓力轉到`數據庫`上了,即使數據庫扛得住,響應速度可能也不是很快,這樣業務受影響了,如果有主從復制,一臺從機掛了還可以在其他從機獲取數據,所以,主從復制可以很好的解決`單機器故障`的問題,也就是`高可用`問題,但是其實還存在`故障轉移問題`,后面我會寫文章解決這個。
### 主從復制的簡單流程
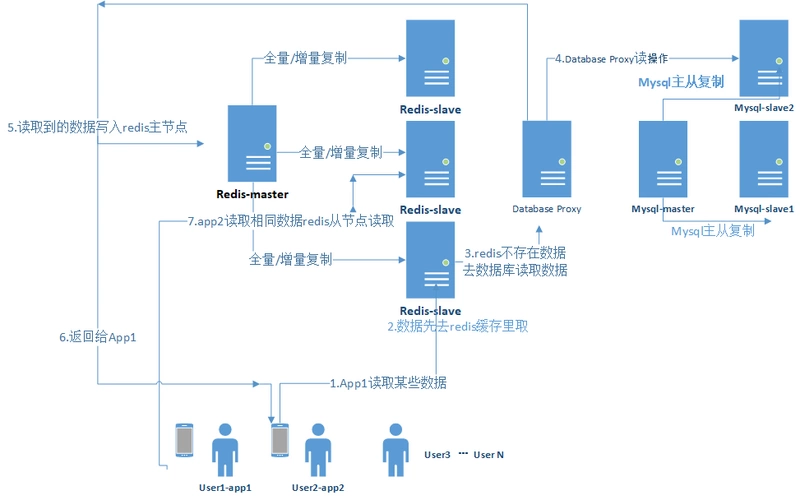
1.這里我把一系列操作舉例放到實際業務流程中,比如有`N`多用戶在頻繁的讀取數據。
2.如果用戶1先去`redis-slave`緩存里取數據。
3.緩存中沒有數據,去數據庫里取。
4.`database proxy`分發讀取數據操作,請求落在`mysql`從節點上。
5.`database proxy`將獲取到的數據(這里假如獲取到了,沒有獲取到直接返回給app)寫入`redis-master` 主節點。
6.同時把獲取到的數據返回給用戶。
7.后面的`N`個用戶獲取相同的數據,壓力被分散在不同的`redis-slave`上面,即使,某一個`redis-slave`宕機了,其他`redis-slave`還可以繼續提供服務。
**注:**
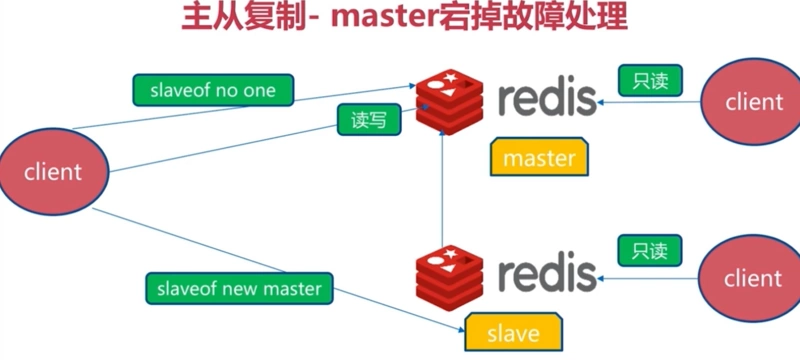
主從復制數據的復制是`單向的`,只能由主節點到從節點默認情況下,每臺`redis`服務器都是主節點,也就是`主節點掛了其他從節點可以變成主節點`(這個切換過程我附在下面);且一個主節點可以有多個從節點(或沒有從節點),但**一個從節點只能有一個主節點**。
### 主從復制搭建
**從節點開啟主從復制,有3種方式:**
#### 1、配置文件啟用
在從服務器的配置文件中加入:`slaveof masterip masterport`
#### 2、啟動命令啟用
redis-server啟動命令后加入 `--slaveof masterip masterport`
#### 3、客戶端命令啟用
redis服務器啟動后,直接通過客戶端執行命令:`slaveof masterip masterport`,則該redis實例成為從節點。
**通過 `info replication` 命令可以看到復制的一些信息**
注 : `Log` 文件位置 `vi /var/log/redis/redis.log`
### 主從復制原理
主從復制過程大體可以分為3個階段:**連接建立階段(即準備階段)、數據同步階段、命令傳播階段。**
在從節點執行 `slaveof` 命令后,復制過程便開始運作,復制過程大致分為6個過程。

對照日志看一下日志如下
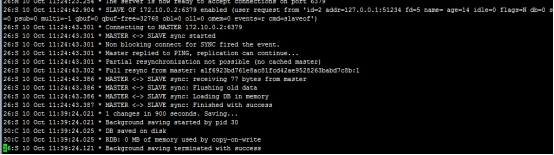
`1`保存主節點(master)信息。
`2`從節點(slave)內部通過每秒運行的定時任務維護復制相關邏輯,當定時任務發現存在新的主節點后,會嘗試與該節點建立網絡連接從節點會建立一個 `socket` 套接字,從節點建立了一個端口為`xxxxx`的套接字,專門用于接受主節點發送的復制命令。從節點連接成功后打印如下日志:

如果從節點無法建立連接,定時任務會無限重試直到連接成功或者執行 `slaveof no one` 取消復制
關于連接失敗,可以在從節點執行 `info replication` 查看 `master_link_down_since_seconds` 指標,它會記錄與主節點連接失敗的系統時間。從節點連接主節點失敗時也會每秒打印如下日志,方便發現問題:
Error condition on socket for SYNC: {socket_error_reason}
`3`發送 `ping` 命令
連接建立成功后從節點發送 ping 請求進行首次通信,ping 請求主要目的如下:
檢測主從之間網絡套接字是否可用。
檢測主節點當前是否可接受處理命令。
如果發送 ping 命令后,從節點沒有收到主節點的 pong 回復或者超時,比如網絡超時或者主節點正在阻塞無法響應命令,從節點會斷開復制連接,下次定時任務會發起重連。
我估計好多人的學軟件的第一課 都`ping pong`過把,這里就不解釋了。。
`4`權限驗證。如果主節點設置了 `requirepass` 參數,則需要密碼驗證,從節點必須配置 `masterauth` 參數保證與主節點相同的密碼才能通過驗證;如果驗證失敗復制將終止,從節點重新發起復制流程。
先`ping`服務器和端口,通了肯定校驗一下密碼
`5`同步數據集。主從復制連接正常通信后,對于首次建立復制的場景,主節點會把持有的數據全部發送給從節點,這部分操作也是耗時最長的步驟。
`6`命令持續復制。當主節點把當前的數據同步給從節點后,便完成了復制的建立流程。接下來主節點會持續地把寫命令發送給從節點,保證主從數據一致性。
### 全量復制和部分復制和復制偏移量
#### 全量復制
用于初次復制或其它無法進行部分復制的情況,將主節點中的所有數據都發送給從節點,是一個非常重型的操作,當數據量較大時,會對主從節點和網絡造成很大的開銷
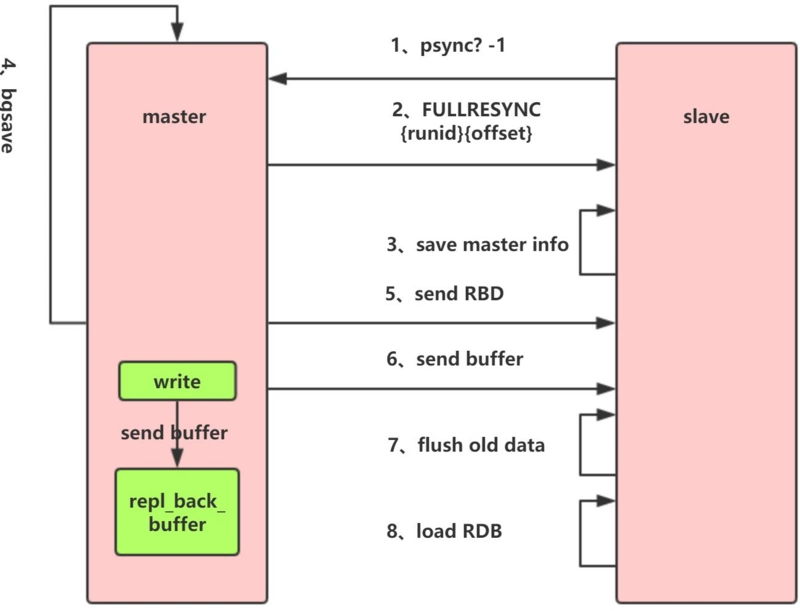
`1.Redis` 內部會發出一個同步命令,剛開始是 `Psync` 命令,Psync ? -1表示要求 `master` 主機同步數據
`2.`主機會向從機發送 `runid` 和 `offset`,因為 `slave` 并沒有對應的 `offset`,所以是`全量復制`
`3.`從機 slave 會保存 主機master 的基本信息 `save masterInfo`
`4.`主節點收到全量復制的命令后,執行`bgsave`(異步執行),在后臺生成`RDB`文件(快照),并使用一個緩沖區(稱為`復制緩沖區`)記錄從現在開始執行的所有寫命令
`5.`主機`send RDB` 發送 `RDB` 文件給從機
`6.`發送緩沖區數據
`7.`刷新舊的數據,從節點在載入主節點的數據之前要先將老數據清除
`8.`加載 `RDB` 文件將數據庫狀態更新至主節點執行`bgsave`時的數據庫狀態和緩沖區數據的加載
##### 全量復制的開銷主要如下
`1.`bgsave 時間
`2.`RDB 文件網絡傳輸時間
`3.`從節點清空數據的時間
`4.`從節點加載 RDB 的時間
#### 部分復制
用于處理在主從復制中因網絡閃斷等原因造成的數據丟失場景,當從節點再次連上主節點后,如果條件允許,主節點會補發丟失數據給從節點。因為補發的數據遠遠小于全量數據,可以有效避免全量復制的過高開銷,需要注意的是,如果網絡中斷時間過長,造成主節點沒有能夠完整地保存中斷期間執行的寫命令,則無法進行部分復制,仍使用全量復制
部分復制是 `redis 2.8` 以后出現的,之所以要加入部分復制,是因為全量復制會產生很多問題,比如像上面的時間開銷大、無法隔離等問題, **`redis` 希望能夠在 `master` 出現抖動(相當于斷開連接)的時候,可以有一些機制將復制的損失降低到最低。**
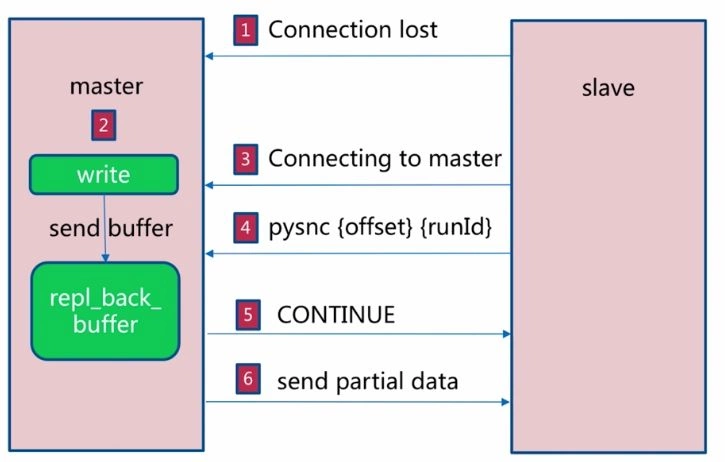
`1.`如果網絡抖動(連接斷開 `connection lost`)
`2.`主機`master` 還是會寫 `replbackbuffer`(復制緩沖區)
`3.`從機`slave` 會繼續嘗試連接主機
`4.`從機`slave` 會把自己當前 `runid` 和偏移量傳輸給主機 `master`,并且執行 `pysnc` 命令同步
`5.`如果 `master` 發現你的偏移量是在緩沖區的范圍內,就會返回 `continue` 命令
`6.`同步了 `offset` 的部分數據,所以部分復制的基礎就是偏移量 `offset`。
#### 復制偏移量
參與復制的主從節點都會維護自身復制偏移量。主節點(`master`)在處理完寫入命令后,會把命令的字節長度做累加記錄,統計信息在 `info relication` 中的 `master_repl_offset` 指標中:
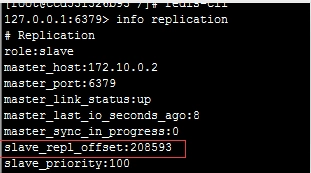
從節點(`slave`)每秒鐘上報自身的復制偏移量給主節點,因此主節點也會保存從節點的復制偏移量,統計指標如下:

從節點在接收到主節點發送的命令后,也會累加記錄自身的偏移量。統計信息在 `info relication` 中的 `slave_repl_offset` 中
### 復制積壓緩沖區
復制積壓緩沖區是保存在主節點上的一個固定長度的隊列,默認大小為`1MB`,當主節點有連接的從節點(`slave`)時被創建,這時主節點(`master`)響應寫命令時,不但會把命令發送給從節點,還會寫入復制積壓緩沖區。
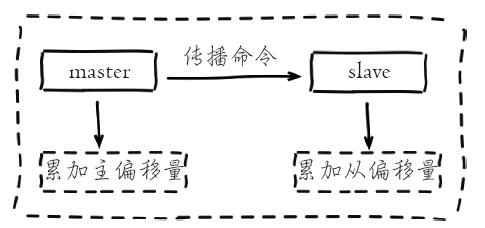
在`命令傳播階段`,主節點除了將寫命令發送給從節點,還會發送一份給復制積壓緩沖區,作為寫命令的備份;除了存儲寫命令,復制積壓緩沖區中還存儲了其中的每個字節對應的復制偏移量(`offset`) 。由于復制積壓緩沖區定長且先進先出,所以它保存的是主節點最近執行的寫命令;時間較早的寫命令會被擠出緩沖區。可以對照全量復制`redis-master`的圖理解 復制擠壓緩沖區。
### 正常情況下redis是如何決定是全量復制還是部分復制
1.從節點將`offset`發送給主節點后,主節點根據`offset`和緩沖區大小決定能否執行部分復制:
2.如果`offset`偏移量之后的數據,仍然都在復制積壓緩沖區里,則執行部分復制;
3.如果`offset`偏移量之后的數據已不在復制積壓緩沖區中(數據已被擠出),則執行全量復制。
#### 1、緩沖區大小調節:
由于緩沖區長度固定且有限,因此可以備份的寫命令也有限,當主從節點`offset`的差距過大超過緩沖區長度時,將無法執行部分復制,只能執行全量復制。反過來說,為了提高網絡中斷時部分復制執行的概率,可以根據需要增大復制積壓緩沖區的大小(通過配置`repl-backlog-size`)來設置;例如如果網絡中斷的平均時間是`60s`,而主節點平均每秒產生的寫命令(特定協議格式)所占的字節數為`100KB`,則復制積壓緩沖區的平均需求為`6MB`,保險起見,可以設置為`12MB`,來保證絕大多數斷線情況都可以使用部分復制。
#### 2、服務器運行ID(`runid`)
每個`redis`節點(無論主從),在啟動時都會自動生成一個隨機ID(每次啟動都不一樣),由40個隨機的十六進制字符組成;runid用來唯一識別一個`redis`節點。 通過`info server`命令,可以查看節點的`runid`:
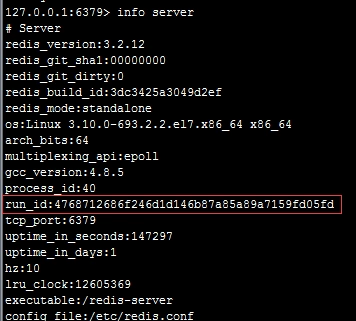
主從節點初次復制時,主節點將自己的`runid`發送給從節點,從節點將這個`runid`保存起來;當斷線重連時,從節點會將這個`runid`發送給主節點;主節點根據`runid`判斷能否進行部分復制:
如果從節點保存的`runid`與主節點現在的`runid`相同,說明主從節點之前同步過,主節點會繼續嘗試使用部分復制(到底能不能部分復制還要看`offset`和復制積壓緩沖區的情況)
如果從節點保存的`runid`與主節點現在的`runid`不同,說明從節點在斷線前同步的`Redis`節點并不是當前的主節點,只能進行全量復制。
### 主從復制進階常見問題解決
#### 1、讀寫分離
讀流量分攤到從節點。這是個非常好的特性,如果一個業務只需要讀數據,那么我們只需要連一臺 `slave` 從機讀數據。

雖然讀寫有優勢,能夠讓讀這部分分配給各個 slave 從機,如果不夠,直接加 `slave` 機器就好了。但是也會出現以下問題。
**1.復制數據延遲。**
可能會出現 `slave` 延遲導致讀寫不一致等問題,當然你也可以使用監控偏移量 offset,如果 offset 超出范圍就切換到 `master` 上,邏輯切換,而具體延遲多少,可以通過 `info replication` 的 `offset` 指標進行排查。
對于無法容忍大量延遲場景,可以編寫外部監控程序監聽主從節點的復制偏移量,當延遲較大時觸發報警或者通知客戶端避免讀取延遲過高的從節點
同時從節點的`slave-serve-stale-data`參數也與此有關,它控制這種情況下從節點的表現:如果為`yes`(默認值),則從節點仍能夠響應客戶端的命令;如果為`no`,則從節點只能響應`info`、`slaveof`等少數命令。該參數的設置與應用對數據一致性的要求有關;如果對數據一致性要求很高,則應設置為`no`。
**2.從節點故障問題**
對于從節點的故障問題,需要在客戶端維護一個可用從節點可用列表,當從節點故障時,立刻切換到其他從節點或主節點。
#### 2、主從配置不一致
主機和從機不同,經常導致主機和從機的配置不同,并帶來問題。
數據丟失:主機和從機有時候會發生配置不一致的情況,例如 `maxmemory` 不一致,如果主機配置 `maxmemory` 為`8G`,從機 `slave` 設置為`4G`,這個時候是可以用的,而且還不會報錯。但是如果要做高可用,讓從節點變成主節點的時候,就會發現數據已經丟失了,而且無法挽回。雖然錯誤很低級,但是有人會犯。。。
#### 3、規避全量復制
全量復制指的是當 `slave` 從機斷掉并重啟后,`runid` 產生變化而導致需要在 `master` 主機里拷貝全部數據。這種拷貝全部數據的過程非常耗資源。全量復制是不可避免的,例如第一次的全量復制是不可避免的,這時我們需要選擇小主節點,且maxmemory 值不要過大,這樣就會比較快。同時選擇在低峰值的時候做全量復制。
##### 1.造成全量復制的原因
##### 1、是主從機的運行 `runid` 不匹配。
解釋一下,主節點如果重啟,`runid` 將會發生變化。如果從節點監控到 `runid` 不是同一個,它就會認為你的節點不安全。當發生故障轉移的時候,如果主節點發生故障,那么從機就會變成主節點。我們會在后面講解哨兵和集群。
##### 2、復制緩沖區空間不足
比如默認值`1M`,可以部分復制。但如果緩存區不夠大的話,首先需要網絡中斷,部分復制就無法滿足。其次需要增大復制緩沖區配置(`relbacklogsize`),對網絡的緩沖增強。參考之前的說明。
**解決辦法:**
在一些場景下,可能希望對主節點進行重啟,例如主節點內存碎片率過高,或者希望調整一些只能在啟動時調整的參數。如果使用普通的手段重啟主節點,會使得runid發生變化,可能導致不必要的全量復制。
為了解決這個問題,rdis提供了debug reload的重啟方式:重啟后,主節點的`runid`和`offset`都不受影響,避免了全量復制。
##### 3、`master` 主機掛了重啟
當一個主機下面掛了很多個 `slave` 從機的時候,主機 `master` 掛了,這時 `master` 主機重啟后,因為 `runid` 發生了變化,所有的 `slave` 從機都要做一次全量復制。這將引起單節點和單機器的復制風暴,開銷會非常大。
**解決辦法:**
可以采用樹狀結構降低多個從節點對主節點的消耗
從節點采用樹狀樹非常有用,網絡開銷交給位于中間層的從節點,而不必消耗頂層的主節點。但是這種樹狀結構也帶來了運維的復雜性,增加了手動和自動處理故障轉移的難度
#### 4、單機器的復制風暴
由于 `redis`的單線程架構,通常單臺機器會部署多個 `redis` 實例。當一臺機器(`machine`)上同時部署多個主節點(`master`)時,如果每個 `master` 主機只有一臺 `slave` 從機,那么當機器宕機以后,會產生大量全量復制。這種情況是非常危險的情況,帶寬馬上會被占用,會導致不可用。
**解決辦法:**
應該把主節點盡量分散在多臺機器上,避免在單臺機器上部署過多的主節點。
當主節點所在機器故障后提供故障轉移機制,避免機器恢復后進行密集的全量復制。
- 微服務
- 服務器相關
- 操作系統
- 極客時間操作系統實戰筆記
- 01 程序的運行過程:從代碼到機器運行
- 02 幾行匯編幾行C:實現一個最簡單的內核
- 03 黑盒之中有什么:內核結構與設計
- Rust
- 入門:Rust開發一個簡單的web服務器
- Rust的引用和租借
- 函數與函數指針
- Rust中如何面向對象編程
- 構建單線程web服務器
- 在服務器中增加線程池提高吞吐
- Java
- 并發編程
- 并發基礎
- 1.創建并啟動線程
- 2.java線程生命周期以及start源碼剖析
- 3.采用多線程模擬銀行排隊叫號
- 4.Runnable接口存在的必要性
- 5.策略模式在Thread和Runnable中的應用分析
- 6.Daemon線程的創建以及使用場景分析
- 7.線程ID,優先級
- 8.Thread的join方法
- 9.Thread中斷Interrupt方法學習&采用優雅的方式結束線程生命周期
- 10.編寫ThreadService實現暴力結束線程
- 11.線程同步問題以及synchronized的引入
- 12.同步代碼塊以及同步方法之間的區別和關系
- 13.通過實驗分析This鎖和Class鎖的存在
- 14.多線程死鎖分析以及案例介紹
- 15.線程間通信快速入門,使用wait和notify進行線程間的數據通信
- 16.多Product多Consumer之間的通訊導致出現程序假死的原因分析
- 17.使用notifyAll完善多線程下的生產者消費者模型
- 18.wait和sleep的本質區別
- 19.完善數據采集程序
- 20.如何實現一個自己的顯式鎖Lock
- 21.addShutdownHook給你的程序注入鉤子
- 22.如何捕獲線程運行期間的異常
- 23.ThreadGroup API介紹
- 24.線程池原理與自定義線程池一
- 25.給線程池增加拒絕策略以及停止方法
- 26.給線程池增加自動擴充,閑時自動回收線程的功能
- JVM
- C&C++
- GDB調試工具筆記
- C&C++基礎
- 一個例子理解C語言數據類型的本質
- 字節順序-大小端模式
- Php
- Php源碼閱讀筆記
- Swoole相關
- Swoole基礎
- php的五種運行模式
- FPM模式的生命周期
- OSI網絡七層圖片速查
- IP/TCP/UPD/HTTP
- swoole源代碼編譯安裝
- 安全相關
- MySql
- Mysql基礎
- 1.事務與鎖
- 2.事務隔離級別與IO的關系
- 3.mysql鎖機制與結構
- 4.mysql結構與sql執行
- 5.mysql物理文件
- 6.mysql性能問題
- Docker&K8s
- Docker安裝java8
- Redis
- 分布式部署相關
- Redis的主從復制
- Redis的哨兵
- redis-Cluster分區方案&應用場景
- redis-Cluster哈希虛擬槽&簡單搭建
- redis-Cluster redis-trib.rb 搭建&原理
- redis-Cluster集群的伸縮調優
- 源碼閱讀筆記
- Mq
- ELK
- ElasticSearch
- Logstash
- Kibana
- 一些好玩的東西
- 一次折騰了幾天的大華攝像頭調試經歷
- 搬磚實用代碼
- python讀取excel拼接sql
- mysql大批量插入數據四種方法
- composer好用的鏡像源
- ab
- 環境搭建與配置
- face_recognition本地調試筆記
- 虛擬機配置靜態ip
- Centos7 Init Shell
- 發布自己的Composer包
- git推送一直失敗怎么辦
- Beyond Compare過期解決辦法
- 我的Navicat for Mysql
- 小錯誤解決辦法
- CLoin報錯CreateProcess error=216
- mysql error You must reset your password using ALTER USER statement before executing this statement.
- VM無法連接到虛擬機
- Jetbrains相關
- IntelliJ IDEA 筆記
- CLoin的配置與使用
- PhpStormDocker環境下配置Xdebug
- PhpStorm advanced metadata
- PhpStorm PHP_CodeSniffer