
# Redis-Sentinel簡介
[Redis Sentinel](https://redis.io/topics/sentinel)是一個分布式架構,其中包含若干個 `Sentinel` 節點和 `Redis` 數據節點,每個 `Sentinel` 節點會對數據節點和其余 `Sentinel` 節點進行監控,當它發現節點不可達時,會對節點做下線標識。如果被標識的是主節點,它還會和其他 `Sentinel` 節點進行“協商”,當大多數 `Sentinel` 節點都認為主節點不可達時,它們會選舉出一個 `Sentinel` 節點來完成自動故障轉移的工作(這個選舉機制一會介紹),同時會將這個變化實時通知給 `Redis` 應用方。整個過程完全是`自動的`,不需要人工來介入,所以這套方案很有效地解決了 `Redis` 的`高可用`問題,可以理解為:之前的主從復制中增加了幾個哨兵(這里注意是幾個而不是一個)來監控`redis`,如果主機掛了,哨兵會經過選舉在從機中選出一個`redis`作為主機,這樣就不必手動切換了。
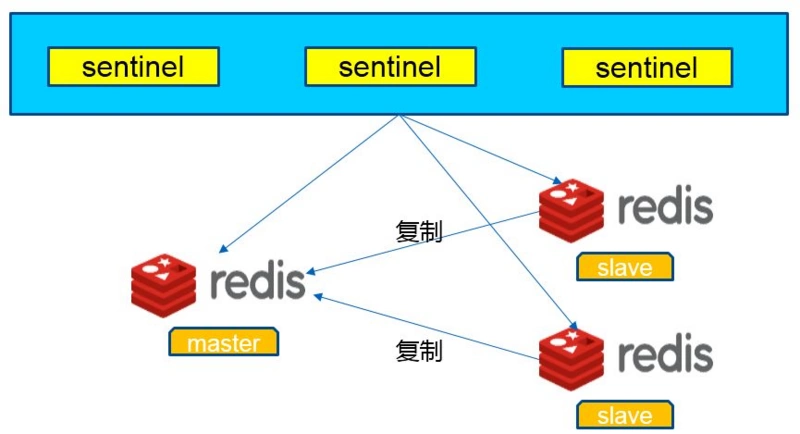
# Redis Sentinel 的功能
`1·`監控:Sentinel 節點會定期檢測 Redis 數據節點、其余 Sentinel 節點是否可達。
`2·`通知:Sentinel 節點會將故障轉移的結果通知給應用方。
`3·`主節點故障轉移:實現從節點晉升為主節點并維護后續正確的主從關系。
`4·`配置提供者:在 `Redis Sentinel` 結構中,客戶端在初始化的時候連接的是 `Sentinel` 節點集合,從中獲取主節點信息。
同時`Redis Sentinel` 包含了若個 `Sentinel` 節點,這樣做也帶來了兩個好處:
`5·`對于節點的故障判斷是由多個 `Sentinel` 節點共同完成,這樣可以有效地防止誤判。
`6·`Sentinel 節點集合是由若干個 `Sentinel` 節點組成的,這樣即使個別 `Sentinel` 節點不可用,整個 `Sentinel` 節點集合依然是健壯的。
**Sentinel 節點本身就是獨立的 `Redis` 節點,只不過它們有一些特殊,它們不存儲數據,只支持部分命令**
# 基本的故障轉移流程:
1.主節點出現故障,此時兩個從節點與主節點失去連接,主從復制失敗。
2.`每個Sentinel` 節點通過定期監控發現主節點出現了故障。
3.多個 `Sentinel` 節點對主節點的故障達成一致會選舉出其中一個節點作為領導者負責故障轉移。
4.`Sentinel` 領導者節點執行了故障轉移,整個過程基本是跟我們手動調整一致的`slaveof no one`,只不過是自動化完成的。
5.故障轉移后整個 `Redis Sentinel` 的結構,重新選舉了新的主節點,并且會通知給客戶端。
# Sentinel 的配置
1. `sentinel monitor <master-name> <ip> <port> <count>`
監控的主節點的`名字`、`IP` 和`端口`,最后一個`count`的意思是有幾臺 Sentinel 發現有問題,就會發生故障轉移,例如 配置為2,代表至少有2個 Sentinel 節點認為主節點不可達,那么這個不可達的判定才是客觀的。對于設置的越小,那么達到下線的條件越寬松,反之越嚴格。一般建議將其設置為 Sentinel 節點的一半加1
**注意:最后的參數不得大于conut(sentinel)**
2. `sentinel down-after-millseconds <master-name> 30000`
這個是超時的時間(單位為毫秒)。打個比方,當你去 ping 一個機器的時候,多長時間后仍 ping 不通,那么就認為它是有問題
3.`sentinel parallel-syncs <master-name> 1`
當 Sentinel 節點集合對主節點故障判定達成一致時,Sentinel 領導者節點會做故障轉移操作,選出新的主節點,原來的從節點會向新的主節點發起復制操作,`parallel-syncs` 就是用來限制在一次故障轉移之后,每次向新的主節點發起復制操作的從節點個數,指出 Sentinel 屬于`并發`還是`串行`。1代表每次只能復制一個,可以減輕 Master 的壓力;
4.`sentinel auth-pass <master-name> <password>`
如果 `Sentinel` 監控的主節點配置了密碼,`sentinel auth-pass` 配置通過添加主節點的密碼,防止 `Sentinel` 節點對主節點無法監控。
5.`sentinel failover-timeout mymaster 180000`
表示故障轉移的時間。
6.sentinel支持的合法命令如下:
`SENTINEL masters` 顯示被監控的所有`master`以及它們的狀態.
`SENTINEL master <master name>` 顯示指定`master`的信息和狀態;
`SENTINEL slaves <master name>` 顯示指定`master`的所有`slave`以及它們的狀態;
`SENTINEL get-master-addr-by-name <master name>` 返回指定master的ip和端口,如果正在進行`failover`或者`failover`已經完成,將會顯示被提升為`master`的`slave`的`ip`和端口。
`SENTINEL failover <master name>` 強制`sentinel`執行`failover`,并且不需要得到其他`sentinel`的同意。但是`failover`后會將最新的配置發送給其他`sentinel`。
修改配置
`sentinel monitor <master-name> <ip> <port> <count>` 添加新的監聽
`SENTINEL REMOVE <master-name>` 放棄對某個master監聽
`SENTINEL set failover-timeout <master-name> 180000` 設置配置選項
# 應用端調用
`Master`可能會因為某些情況宕機了,如果在客戶端是固定一個地址去訪問,肯定是不合理的,所以客戶端請求是請求哨兵,從哨兵獲取主機地址的信息,或者是從機的信息。可以實現一個例子
1、隨機選擇一個哨兵連接,獲取主機、從機信息
2、模擬客戶端定時訪問,實現簡單輪訓效果,輪訓從節點
3、連接失敗重試訪問
這里我簡單寫個例子,這里我用了`swoole`的定時器
```php
<?php
class Round{
static $lastIndex=0;
public function select($list){
$currentIndex=self::$lastIndex; //當前的index
$value=$list[$currentIndex];
if($currentIndex+1>count($list)-1){
self::$lastIndex=0;
}else{
self::$lastIndex++;
}
return $value;
}
}
$sentinelConf=[
['ip'=>'xxx','port'=>xxx],
['ip'=>'xxx','port'=>xxx],
['ip'=>'xxx','port'=>xxx]
];
//隨機訪問
$sentinelInfo=$sentinelConf[array_rand($sentinelConf)];
$redis=new Redis();
$redis->connect($sentinelInfo['ip'],$sentinelInfo['port']);
//rawCommand參數 1 command 2 arguments 3.
$slavesInfo=$redis->rawCommand('SENTINEL','slaves','mymaster');
$slaves=[];
foreach ($slavesInfo as $val){
$slaves[]=['ip'=>$val[3],'port'=>$val[5]];
}
//加載到緩存當中,可以記錄這次訪問的時間跟上次的訪問時間
//模擬客戶端訪問
swoole_timer_tick(600,function () use($slaves) {
//輪訓
$slave=(new Round())->select($slaves);
try{
$redis=new Redis();
$redis->connect($slave['ip'],$slave['port']);
var_dump($slave,$redis->get('username'));
}catch (\RedisException $e){
}
});
```
# Sentinel 實現原理三步驟
說完了 `Sentinel` 的代碼實現,很多人對 `Sentinel` 還不懂其原理。那么接下來就來看下 `Sentinel` 的實現原理,主要分為以下三個步驟。
## 1.檢測問題之三個定時任務
每`10`秒每個 `Sentinel` 對 `Master` 和 `Slave` 執行一次 `Info Replication`。
每`2`秒每個 `Sentinel` 通過 `Master` 節點的 `channel` 交換信息(`pub/sub`)。
每`1`秒每個 `Sentinel` 對其他 `Sentinel` 和 `Redis` 執行 `ping`。
**第一個定時任務**,指的是 `Redis Sentinel` 可以對 `Redis` 節點做失敗判斷和故障轉移,在 `Redis` 內部有三個定時任務作為基礎,來 `Info Replication` 發現 `Slave` 節點,這個命令可以確定主從關系。
**第兩個定時任務**,類似于發布訂閱,`Sentinel` 會對主從關系進行判定,通過 `_sentinel_:hello` 頻道交互。了解主從關系可以幫助更好的自動化操作 `Redis`。然后 `Sentinel` 會告知系統消息給其它 `Sentinel` 節點,最終達到共識,同時 `Sentinel` 節點能夠互相感知到對方。
**第三個定時任務**,指的是對每個節點和其它 `Sentinel` 進行心跳檢測,它是失敗判定的依據。
## 2.發現問題之主觀下線和客觀下線
當有一臺 `Sentinel` 機器發現問題時,它就會主觀對它主觀下線,但是當多個 `Sentinel` 都發現有問題的時候,才會出現客觀下線。
我們先來回顧一下 `Sentinel` 的配置。
sentinel monitor <master-name> <ip> <port> <count>
sentinel down-after-milliseconds <master-name> 30000
`Sentinel` 會 `ping` 每個節點,如果超過`30`秒,依然沒有回復的話,做下線的判斷。
### 什么是主觀下線呢?
每個 `Sentinel` 節點對 `Redis` 節點失敗的“偏見”。之所以是偏見,只是因為某一臺機器30秒內沒有得到回復。
### 如何做到客觀下線?
這個時候需要所有 `Sentinel` 節點都發現它`30`秒內無回復,才會達到共識。
## 3.找到解決問題的人之領導者選舉
1.每個做主觀下線的`sentinel`節點,會向其他的`sentinel`節點發送命令,要求將它設置成為領導者
2.收到命令`sentinel`節點,如果沒有同意通過其它節點發送的命令,那么就會同意請求,否則就會拒絕
3.如果`sentinel`節點發現自己票數超過半數,同時也超過了`sentinel monitor <master-name> <ip> <port> <count>` 超過`count`個的時候,就會成為領導者
## 4.解決問題之故障轉移
如何選擇“合適的”`Slave` 節點
`Redis` 內部其實是有一個優先級配置的,在配置文件中 `slave-priority`,這個參數是 Salve 節點的優先級配置,如果存在則返回,如果不存在則繼續。
當上面這個優先級不滿足的時候,`Redis` 還會選擇復制偏移量最大的 `Slave`節點,如果存在則返回,如果不存在則繼續。之所以選擇偏移量最大,這是因為偏移量越小,和 `Master` 的數據越不接近,現在 `Master`掛掉了,說明這個偏移量小的機器數據也可能存在問題,這就是為什么要選偏移量最大的 `Slave` 的原因。
如果發現偏移量都一樣,這個時候 `Redis` 會默認選擇 `runid` 最小的節點。
# 生產環境中部署注意事項
1.`Sentinel` 節點不應該部署在一臺物理“機器”上。
這里特意強調物理機是因為一臺物理機做成了若干虛擬機或者現今比較流行的容器,它們雖然有不同的 IP 地址,但實際上它們都是同一臺物理機,同一臺物理機意味著如果這臺機器有什么硬件故障,所有的虛擬機都會受到影響,為了實現 Sentinel 節點集合真正的高可用,請勿將 `Sentinel` 節點部署在同一臺物理機器上。
2.部署至少三個且`奇數`個的 `Sentinel` 節點。
3.個以上是通過增加 `Sentinel` 節點的個數提高對于故障判定的準確性,因為領導者選舉需要至少一半加1個節點,奇數個節點可以在滿足該條件的基礎上節省一個節點。
# 哨兵常見問題
哨兵集群在發現`master node`掛掉后會進行故障轉移,也就是啟動其中一個`slave node`為`master node`。在這過程中,可能會導致數據丟失的情況。
## 1、異步復制導致數據丟失
因為`master->slave`的復制是異步,所以可能有部分還沒來得及復制到slave就宕機了,此時這些部分數據就丟失了,這個我至今沒找到解決的辦法,希望有人更正。
## 2、集群腦裂導致數據丟失
腦裂,也就是說,某個`master`所在機器突然脫離了正常的網絡,跟其它`slave`機器不能連接,但是實際上`master`還運行著。
### 造成的問題
此時哨兵可能就會認為`master`宕機了,然后開始選舉,講其它`slave`切換成`master`。這時候集群里就會有2個`master`,也就是所謂的腦裂。
此時雖然某個`slave`被切換成了`master`,但是可能`client`還沒來得及切換成新的`master`,還繼續寫向舊的`master`的數據可能就丟失了。
因此舊`master`再次恢復的時候,會被作為一個`slave`掛到新的`master`上去,自己的數據會被清空,重新從新的`master`復制數據。
### 怎么解決?
min-slaves-to-write 1
min-slaves-max-lag 10
要求至少有1個`slave`,數據復制和同步的延遲不能超過`10`秒
如果說一旦所有的`slave`,數據復制和同步的延遲都超過了`10`秒鐘,那么這個時候,`master`就不會再接收任何請求了
**上面兩個配置可以減少異步復制和腦裂導致的數據丟失**
#### 1、異步復制導致的數據丟失
在異步復制的過程當中,通過`min-slaves-max-lag`這個配置,就可以確保的說,一旦`slave`復制數據和`ack`延遲時間太長,就認為可能`master`宕機后損失的數據太多了,那么就拒絕寫請求,這樣就可以把`master`宕機時由于部分數據未同步到slave導致的數據丟失降低到可控范圍內
#### 2、集群腦裂導致的數據丟失
集群腦裂因為`client`還沒來得及切換成新的`master`,還繼續寫向舊的master的數據可能就丟失了通過`min-slaves-to-write` 確保必須是有多少個從節點連接,并且延遲時間小于`min-slaves-max-lag`多少秒。
# 客戶端怎么做
對于`client`來講,就需要做些處理,比如先將數據緩存到內存當中,然后過一段時間處理,或者連接失敗,接收到錯誤切換新的`master`處理。
- 微服務
- 服務器相關
- 操作系統
- 極客時間操作系統實戰筆記
- 01 程序的運行過程:從代碼到機器運行
- 02 幾行匯編幾行C:實現一個最簡單的內核
- 03 黑盒之中有什么:內核結構與設計
- Rust
- 入門:Rust開發一個簡單的web服務器
- Rust的引用和租借
- 函數與函數指針
- Rust中如何面向對象編程
- 構建單線程web服務器
- 在服務器中增加線程池提高吞吐
- Java
- 并發編程
- 并發基礎
- 1.創建并啟動線程
- 2.java線程生命周期以及start源碼剖析
- 3.采用多線程模擬銀行排隊叫號
- 4.Runnable接口存在的必要性
- 5.策略模式在Thread和Runnable中的應用分析
- 6.Daemon線程的創建以及使用場景分析
- 7.線程ID,優先級
- 8.Thread的join方法
- 9.Thread中斷Interrupt方法學習&采用優雅的方式結束線程生命周期
- 10.編寫ThreadService實現暴力結束線程
- 11.線程同步問題以及synchronized的引入
- 12.同步代碼塊以及同步方法之間的區別和關系
- 13.通過實驗分析This鎖和Class鎖的存在
- 14.多線程死鎖分析以及案例介紹
- 15.線程間通信快速入門,使用wait和notify進行線程間的數據通信
- 16.多Product多Consumer之間的通訊導致出現程序假死的原因分析
- 17.使用notifyAll完善多線程下的生產者消費者模型
- 18.wait和sleep的本質區別
- 19.完善數據采集程序
- 20.如何實現一個自己的顯式鎖Lock
- 21.addShutdownHook給你的程序注入鉤子
- 22.如何捕獲線程運行期間的異常
- 23.ThreadGroup API介紹
- 24.線程池原理與自定義線程池一
- 25.給線程池增加拒絕策略以及停止方法
- 26.給線程池增加自動擴充,閑時自動回收線程的功能
- JVM
- C&C++
- GDB調試工具筆記
- C&C++基礎
- 一個例子理解C語言數據類型的本質
- 字節順序-大小端模式
- Php
- Php源碼閱讀筆記
- Swoole相關
- Swoole基礎
- php的五種運行模式
- FPM模式的生命周期
- OSI網絡七層圖片速查
- IP/TCP/UPD/HTTP
- swoole源代碼編譯安裝
- 安全相關
- MySql
- Mysql基礎
- 1.事務與鎖
- 2.事務隔離級別與IO的關系
- 3.mysql鎖機制與結構
- 4.mysql結構與sql執行
- 5.mysql物理文件
- 6.mysql性能問題
- Docker&K8s
- Docker安裝java8
- Redis
- 分布式部署相關
- Redis的主從復制
- Redis的哨兵
- redis-Cluster分區方案&應用場景
- redis-Cluster哈希虛擬槽&簡單搭建
- redis-Cluster redis-trib.rb 搭建&原理
- redis-Cluster集群的伸縮調優
- 源碼閱讀筆記
- Mq
- ELK
- ElasticSearch
- Logstash
- Kibana
- 一些好玩的東西
- 一次折騰了幾天的大華攝像頭調試經歷
- 搬磚實用代碼
- python讀取excel拼接sql
- mysql大批量插入數據四種方法
- composer好用的鏡像源
- ab
- 環境搭建與配置
- face_recognition本地調試筆記
- 虛擬機配置靜態ip
- Centos7 Init Shell
- 發布自己的Composer包
- git推送一直失敗怎么辦
- Beyond Compare過期解決辦法
- 我的Navicat for Mysql
- 小錯誤解決辦法
- CLoin報錯CreateProcess error=216
- mysql error You must reset your password using ALTER USER statement before executing this statement.
- VM無法連接到虛擬機
- Jetbrains相關
- IntelliJ IDEA 筆記
- CLoin的配置與使用
- PhpStormDocker環境下配置Xdebug
- PhpStorm advanced metadata
- PhpStorm PHP_CodeSniffer