
[TOC]
## ASCII 表
總所周知,計算機起源于美國,英文只有26字符,算上其他所有特殊符號也不會超過128個。字節是計算機的基本存儲單位。一個字節(bytes)包括八個比特位(bit)。能夠表示出256(2^8)個二進制數字,所以美國人在這里只是用到了一個字節的前七位即127個數字來對應了127個具體字符。而這張對應表就是ASCII碼字符編碼表,簡稱ASCII表。后來為了能夠讓計算機識別拉丁文,就像一個字節的最高位也應用了。這樣就多擴展出128個二進制數字來對應新的符號。這張對應表因為是在ASCII表的基礎上擴展的最高位,因此稱為擴展ASCII表。到此位置,一個字節能表示的256個二進制數據都有了特殊的字符對應。
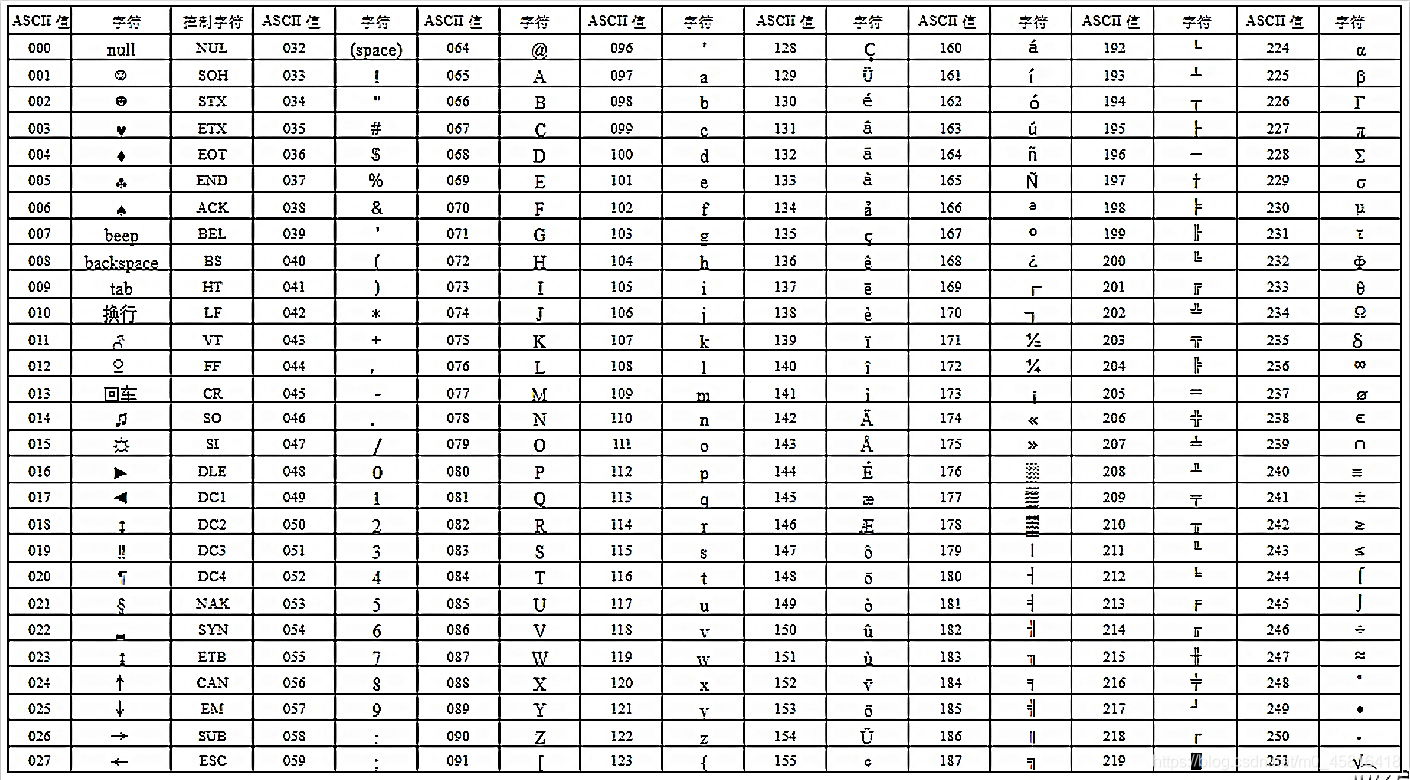
> 注:表中000-127是標準的。128-255是擴展的
## GBK 編碼
當計算機發在到東亞國家后,問題又出現了。像中文、韓文、日文等符號也需要在計算機上顯示。可是一個字節已經被西方國際占滿了。于是,中華民族自己重寫一張對應表。直接生猛地將擴展的第八位對應拉丁文全部刪掉。規定一個小于127的字符的意義與原來相同。即支持ASCII碼表。但兩個大于127的字符連在一起時,就表示一個漢字。這樣子就可以將幾千個漢字對應一個個二進制數了。而這種編碼方式就是GB2312,也稱為中文擴展ASCII碼表。再后來,我們為了對應更多的漢字規定只要第一個字節是大于127就固定表示這是一個漢字的開始。不管后面跟的是不是擴展字符串里的內容。這樣子能多出幾萬個二進制字,就算甲骨文也能夠用了。而這次擴展的編碼方式稱為GBK標準。當然,GBK標準下,一個像“曾”這樣的中文字符,必須占兩個字節才能存儲顯示。
## Unicode 與 utf8 編碼
與此同時,其他國家也都開發出一套編碼方式。即本國文字符號和二進制數字的對應表。而國家彼此間的編碼方式是互不支持的,這會導致很多問題。于是ISO國際化標準組織為了統一編碼。統計了世界上所有國家的字符,開發出了一張萬國碼字符表,用兩個字節即六萬多個二進制數字來對應。這就是 Unicode 編碼方式。這樣,每個國家都使用這套編碼方式就再也不會有計算機的編碼問題了。 Unicode 的編碼特點是對應任意一個字符,都需要兩個字節來存儲。這對于美國人而言無異于吃上了世界的大鍋板,也就是說,如果用ASCII碼表,明明一個字節就可以存儲的字符現在為了兼容其他語言而需要兩個字節了。比如字母"A",本可以用 01000001 來存儲,現在要用Unicode只能是 00000000 01000001 存儲。而這將導致大量的空間被浪費掉,基于此,美國人創建了 utf8 編碼,而utf8編碼是一種針對 Unicode 的可變長字符編碼方式,根據具體不同的字符計算出需要字節,對于ASCII碼范圍的字符。就用一個字符,而且符號與數字的對應也是一致的。所以說 utf8 是兼容 ASCII 碼表的。但是對于中文,一般是用三個字節存儲的。
- Golang簡介
- 開發環境
- Golang安裝
- 編輯器及快捷鍵
- vscode插件
- 第一個程序
- 基礎數據類型
- 變量及匿名變量
- 常量與iota
- 整型與浮點型
- 復數與布爾值
- 字符串
- 運算符
- 算術運算符
- 關系運算符
- 邏輯運算符
- 位運算符
- 賦值運算符
- 流程控制語句
- 獲取用戶輸入
- if分支語句
- for循環語句
- switch語句
- break_continue_goto語法
- 高階數據類型
- pointer指針
- array數組
- slice切片
- slice切片擴展
- map映射
- 函數
- 函數定義和調用
- 函數參數
- 函數返回值
- 作用域
- 函數形參傳遞
- 匿名函數
- 高階函數
- 閉包
- defer語句
- 內置函數
- fmt
- strconv
- strings
- time
- os
- io
- 文件操作
- 編碼
- 字符與字節
- 字符串
- 讀寫文件
- 結構體
- 類型別名和自定義類型
- 結構體聲明
- 結構體實例化
- 模擬構造函數
- 方法接收器
- 匿名字段
- 嵌套與繼承
- 序列化
- 接口
- 接口類型
- 值接收者和指針接收者
- 類型與接口對應關系
- 空接口
- 接口值
- 類型斷言
- 并發編程
- 基本概念
- goroutine
- channel
- select
- 并發安全
- 練習題
- 第三方庫
- Survey
- cobra