
# 第八節:QuerySet API
# QuerySet API:
我們通常做查詢操作的時候,都是通過`模型名字.objects`的方式進行操作。其實`模型名字.objects`是一個`django.db.models.manager.Manager`對象,而`Manager`這個類是一個“空殼”的類,他本身是沒有任何的屬性和方法的。他的方法全部都是通過`Python`動態添加的方式,從`QuerySet`類中拷貝過來的。示例圖如下:
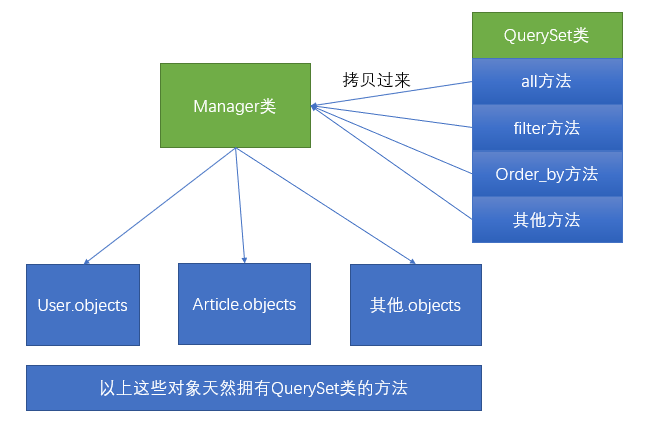
所以我們如果想要學習`ORM`模型的查找操作,必須首先要學會`QuerySet`上的一些`API`的使用。
## 返回新的QuerySet的方法:
在使用`QuerySet`進行查找操作的時候,可以提供多種操作。比如過濾完后還要根據某個字段進行排序,那么這一系列的操作我們可以通過一個非常流暢的`鏈式調用`的方式進行。比如要從文章表中獲取標題為`123`,并且提取后要將結果根據發布的時間進行排序,那么可以使用以下方式來完成:
```
<pre class="calibre12">```
articles = Article.objects.filter(title=<span class="hljs-string">'123'</span>).order_by(<span class="hljs-string">'create_time'</span>)
```
```
可以看到`order_by`方法是直接在`filter`執行后調用的。這說明`filter`返回的對象是一個擁有`order_by`方法的對象。而這個對象正是一個新的`QuerySet`對象。因此可以使用`order_by`方法。
那么以下將介紹在那些會返回新的`QuerySet`對象的方法。
1. `filter`:將滿足條件的數據提取出來,返回一個新的`QuerySet`。具體的`filter`可以提供什么條件查詢。請見查詢操作章節。
2. `exclude`:排除滿足條件的數據,返回一個新的`QuerySet`。示例代碼如下:
```
<pre class="calibre12">```
Article.objects.exclude(title__contains=<span class="hljs-string">'hello'</span>)
```
```
以上代碼的意思是提取那些標題不包含`hello`的圖書。
3. `annotate`:給`QuerySet`中的每個對象都添加一個使用查詢表達式(聚合函數、F表達式、Q表達式、Func表達式等)的新字段。示例代碼如下:
```
<pre class="calibre12">```
articles = Article.objects.annotate(author_name=F(<span class="hljs-string">"author__name"</span>))
```
```
以上代碼將在每個對象中都添加一個`author__name`的字段,用來顯示這個文章的作者的年齡。
4. `order_by`:指定將查詢的結果根據某個字段進行排序。如果要倒敘排序,那么可以在這個字段的前面加一個負號。示例代碼如下:
```
<pre class="calibre12">```
<span class="hljs-title"># 根據創建的時間正序排序</span>
articles = Article.objects.order_by(<span class="hljs-string">"create_time"</span>)
<span class="hljs-title"># 根據創建的時間倒序排序</span>
articles = Article.objects.order_by(<span class="hljs-string">"-create_time"</span>)
<span class="hljs-title"># 根據作者的名字進行排序</span>
articles = Article.objects.order_by(<span class="hljs-string">"author__name"</span>)
<span class="hljs-title"># 首先根據創建的時間進行排序,如果時間相同,則根據作者的名字進行排序</span>
articles = Article.objects.order_by(<span class="hljs-string">"create_time"</span>,<span class="hljs-string">'author__name'</span>)
```
```
一定要注意的一點是,多個`order_by`,會把前面排序的規則給打亂,而使用后面的排序方式。比如以下代碼:
```
<pre class="calibre12">```
articles = Article.objects.order_by(<span class="hljs-string">"create_time"</span>).order_by(<span class="hljs-string">"author__name"</span>)
```
```
他會根據作者的名字進行排序,而不是使用文章的創建時間。
5. `values`:用來指定在提取數據出來,需要提取哪些字段。默認情況下會把表中所有的字段全部都提取出來,可以使用`values`來進行指定,并且使用了`values`方法后,提取出的`QuerySet`中的數據類型不是模型,而是在`values`方法中指定的字段和值形成的字典:
```
<pre class="calibre12">```
articles = Article.objects.values(<span class="hljs-string">"title"</span>,<span class="hljs-string">'content'</span>)
<span class="hljs-keyword">for</span> article <span class="hljs-keyword">in</span> articles:
print(article)
```
```
以上打印出來的`article`是類似于`{"title":"abc","content":"xxx"}`的形式。
如果在`values`中沒有傳遞任何參數,那么將會返回這個惡模型中所有的屬性。
6. `values_list`:類似于`values`。只不過返回的`QuerySet`中,存儲的不是字典,而是元組。示例代碼如下:
```
<pre class="calibre12">```
articles = Article.objects.values_list(<span class="hljs-string">"id"</span>,<span class="hljs-string">"title"</span>)
print(articles)
```
```
那么在打印`articles`后,結果為`<QuerySet [(1,'abc'),(2,'xxx'),...]>`等。
如果在`values_list`中只有一個字段。那么你可以傳遞`flat=True`來將結果扁平化。示例代碼如下:
```
<pre class="calibre12">```
articles1 = Article.objects.values_list(<span class="hljs-string">"title"</span>)
>> <QuerySet [(<span class="hljs-string">"abc"</span>,),(<span class="hljs-string">"xxx"</span>,),...]>
articles2 = Article.objects.values_list(<span class="hljs-string">"title"</span>,flat=<span class="hljs-keyword">True</span>)
>> <QuerySet [<span class="hljs-string">"abc"</span>,<span class="hljs-string">'xxx'</span>,...]>
```
```
7. `all`:獲取這個`ORM`模型的`QuerySet`對象。
8. `select_related`:在提取某個模型的數據的同時,也提前將相關聯的數據提取出來。比如提取文章數據,可以使用`select_related`將`author`信息提取出來,以后再次使用`article.author`的時候就不需要再次去訪問數據庫了。可以減少數據庫查詢的次數。示例代碼如下:
```
<pre class="calibre12">```
article = Article.objects.get(pk=<span class="hljs-params">1</span>)
>> article.author <span class="hljs-title"># 重新執行一次查詢語句</span>
article = Article.objects.select_related(<span class="hljs-string">"author"</span>).get(pk=<span class="hljs-params">2</span>)
>> article.author <span class="hljs-title"># 不需要重新執行查詢語句了</span>
```
```
`select_related`只能用在`一對多`或者`一對一`中,不能用在`多對多`或者`多對一`中。比如可以提前獲取文章的作者,但是不能通過作者獲取這個作者的文章,或者是通過某篇文章獲取這個文章所有的標簽。
9. `prefetch_related`:這個方法和`select_related`非常的類似,就是在訪問多個表中的數據的時候,減少查詢的次數。這個方法是為了解決`多對一`和`多對多`的關系的查詢問題。比如要獲取標題中帶有`hello`字符串的文章以及他的所有標簽,示例代碼如下:
```
<pre class="calibre12">```
<span class="hljs-keyword">from</span> django.db <span class="hljs-keyword">import</span> connection
articles = Article.objects.prefetch_related(<span class="hljs-string">"tag_set"</span>).filter(title__contains=<span class="hljs-string">'hello'</span>)
print(articles.query) <span class="hljs-title"># 通過這條命令查看在底層的SQL語句</span>
<span class="hljs-keyword">for</span> article <span class="hljs-keyword">in</span> articles:
print(<span class="hljs-string">"title:"</span>,article.title)
print(article.tag_set.all())
<span class="hljs-title"># 通過以下代碼可以看出以上代碼執行的sql語句</span>
<span class="hljs-keyword">for</span> sql <span class="hljs-keyword">in</span> connection.queries:
print(sql)
```
```
但是如果在使用`article.tag_set`的時候,如果又創建了一個新的`QuerySet`那么會把之前的`SQL`優化給破壞掉。比如以下代碼:
```
<pre class="calibre12">```
tags = Tag.obejcts.prefetch_related(<span class="hljs-string">"articles"</span>)
<span class="hljs-keyword">for</span> tag <span class="hljs-keyword">in</span> tags:
articles = tag.articles.filter(title__contains=<span class="hljs-string">'hello'</span>) <span class="hljs-title">#因為filter方法會重新生成一個QuerySet,因此會破壞掉之前的sql優化</span>
<span class="hljs-title"># 通過以下代碼,我們可以看到在使用了filter的,他的sql查詢會更多,而沒有使用filter的,只有兩次sql查詢</span>
<span class="hljs-keyword">for</span> sql <span class="hljs-keyword">in</span> connection.queries:
print(sql)
```
```
那如果確實是想要在查詢的時候指定過濾條件該如何做呢,這時候我們可以使用`django.db.models.Prefetch`來實現,`Prefetch`這個可以提前定義好`queryset`。示例代碼如下:
```
<pre class="calibre12">```
tags = Tag.objects.prefetch_related(Prefetch(<span class="hljs-string">"articles"</span>,queryset=Article.objects.filter(title__contains=<span class="hljs-string">'hello'</span>))).all()
<span class="hljs-keyword">for</span> tag <span class="hljs-keyword">in</span> tags:
articles = tag.articles.all()
<span class="hljs-keyword">for</span> article <span class="hljs-keyword">in</span> articles:
print(article)
<span class="hljs-keyword">for</span> sql <span class="hljs-keyword">in</span> connection.queries:
print(<span class="hljs-string">'='</span>*<span class="hljs-params">30</span>)
print(sql)
```
```
因為使用了`Prefetch`,即使在查詢文章的時候使用了`filter`,也只會發生兩次查詢操作。
10. `defer`:在一些表中,可能存在很多的字段,但是一些字段的數據量可能是比較龐大的,而此時你又不需要,比如我們在獲取文章列表的時候,文章的內容我們是不需要的,因此這時候我們就可以使用`defer`來過濾掉一些字段。這個字段跟`values`有點類似,只不過`defer`返回的不是字典,而是模型。示例代碼如下:
```
<pre class="calibre12">```
articles = list(Article.objects.defer(<span class="hljs-string">"title"</span>))
<span class="hljs-keyword">for</span> sql <span class="hljs-keyword">in</span> connection.queries:
print(<span class="hljs-string">'='</span>*<span class="hljs-params">30</span>)
print(sql)
```
```
在看以上代碼的`sql`語句,你就可以看到,查找文章的字段,除了`title`,其他字段都查找出來了。當然,你也可以使用`article.title`來獲取這個文章的標題,但是會重新執行一個查詢的語句。示例代碼如下:
```
<pre class="calibre12">```
articles = list(Article.objects.defer(<span class="hljs-string">"title"</span>))
<span class="hljs-keyword">for</span> article <span class="hljs-keyword">in</span> articles:
<span class="hljs-title"># 因為在上面提取的時候過濾了title</span>
<span class="hljs-title"># 這個地方重新獲取title,將重新向數據庫中進行一次查找操作</span>
print(article.title)
<span class="hljs-keyword">for</span> sql <span class="hljs-keyword">in</span> connection.queries:
print(<span class="hljs-string">'='</span>*<span class="hljs-params">30</span>)
print(sql)
```
```
`defer`雖然能過濾字段,但是有些字段是不能過濾的,比如`id`,即使你過濾了,也會提取出來。
11. `only`:跟`defer`類似,只不過`defer`是過濾掉指定的字段,而`only`是只提取指定的字段。
12. `get`:獲取滿足條件的數據。這個函數只能返回一條數據,并且如果給的條件有多條數據,那么這個方法會拋出`MultipleObjectsReturned`錯誤,如果給的條件沒有任何數據,那么就會拋出`DoesNotExit`錯誤。所以這個方法在獲取數據的只能,只能有且只有一條。
13. `create`:創建一條數據,并且保存到數據庫中。這個方法相當于先用指定的模型創建一個對象,然后再調用這個對象的`save`方法。示例代碼如下:
```
<pre class="calibre12">```
article = Article(title=<span class="hljs-string">'abc'</span>)
article.save()
<span class="hljs-title"># 下面這行代碼相當于以上兩行代碼</span>
article = Article.objects.create(title=<span class="hljs-string">'abc'</span>)
```
```
14. `get_or_create`:根據某個條件進行查找,如果找到了那么就返回這條數據,如果沒有查找到,那么就創建一個。示例代碼如下:
```
<pre class="calibre12">```
obj,created= Category.objects.get_or_create(title=<span class="hljs-string">'默認分類'</span>)
```
```
如果有標題等于`默認分類`的分類,那么就會查找出來,如果沒有,則會創建并且存儲到數據庫中。
這個方法的返回值是一個元組,元組的第一個參數`obj`是這個對象,第二個參數`created`代表是否創建的。
15. `bulk_create`:一次性創建多個數據。示例代碼如下:
```
<pre class="calibre12">```
Tag.objects.bulk_create([
Tag(name=<span class="hljs-string">'111'</span>),
Tag(name=<span class="hljs-string">'222'</span>),
])
```
```
16. `count`:獲取提取的數據的個數。如果想要知道總共有多少條數據,那么建議使用`count`,而不是使用`len(articles)`這種。因為`count`在底層是使用`select count(*)`來實現的,這種方式比使用`len`函數更加的高效。
17. `first`和`last`:返回`QuerySet`中的第一條和最后一條數據。
18. `aggregate`:使用聚合函數。
19. `exists`:判斷某個條件的數據是否存在。如果要判斷某個條件的元素是否存在,那么建議使用`exists`,這比使用`count`或者直接判斷`QuerySet`更有效得多。示例代碼如下:
```
<pre class="calibre12">```
<span class="hljs-keyword">if</span> Article.objects.filter(title__contains=<span class="hljs-string">'hello'</span>).exists():
print(<span class="hljs-keyword">True</span>)
比使用count更高效:
<span class="hljs-keyword">if</span> Article.objects.filter(title__contains=<span class="hljs-string">'hello'</span>).count() > <span class="hljs-params">0</span>:
print(<span class="hljs-keyword">True</span>)
也比直接判斷QuerySet更高效:
<span class="hljs-keyword">if</span> Article.objects.filter(title__contains=<span class="hljs-string">'hello'</span>):
print(<span class="hljs-keyword">True</span>)
```
```
20. `distinct`:去除掉那些重復的數據。這個方法如果底層數據庫用的是`MySQL`,那么不能傳遞任何的參數。比如想要提取所有銷售的價格超過80元的圖書,并且刪掉那些重復的,那么可以使用`distinct`來幫我們實現,示例代碼如下:
```
<pre class="calibre12">```
books = Book.objects.filter(bookorder__price__gte=<span class="hljs-params">80</span>).distinct()
```
```
需要注意的是,如果在`distinct`之前使用了`order_by`,那么因為`order_by`會提取`order_by`中指定的字段,因此再使用`distinct`就會根據多個字段來進行唯一化,所以就不會把那些重復的數據刪掉。示例代碼如下:
```
<pre class="calibre12">```
orders = BookOrder.objects.order_by(<span class="hljs-string">"create_time"</span>).values(<span class="hljs-string">"book_id"</span>).distinct()
```
```
那么以上代碼因為使用了`order_by`,即使使用了`distinct`,也會把重復的`book_id`提取出來。
21. `update`:執行更新操作,在`SQL`底層走的也是`update`命令。比如要將所有`category`為空的`article`的`article`字段都更新為默認的分類。示例代碼如下:
```
<pre class="calibre12">```
Article.objects.filter(category__isnull=<span class="hljs-keyword">True</span>).update(category_id=<span class="hljs-params">3</span>)
```
```
注意這個方法走的是更新的邏輯。所以更新完成后保存到數據庫中不會執行`save`方法,因此不會更新`auto_now`設置的字段。
22. `delete`:刪除所有滿足條件的數據。刪除數據的時候,要注意`on_delete`指定的處理方式。
23. 切片操作:有時候我們查找數據,有可能只需要其中的一部分。那么這時候可以使用切片操作來幫我們完成。`QuerySet`使用切片操作就跟列表使用切片操作是一樣的。示例代碼如下:
```
<pre class="calibre12">```
books = Book.objects.all()[<span class="hljs-params">1</span>:<span class="hljs-params">3</span>]
<span class="hljs-keyword">for</span> book <span class="hljs-keyword">in</span> books:
print(book)
```
```
切片操作并不是把所有數據從數據庫中提取出來再做切片操作。而是在數據庫層面使用`LIMIE`和`OFFSET`來幫我們完成。所以如果只需要取其中一部分的數據的時候,建議大家使用切片操作。
## 什么時候`Django`會將`QuerySet`轉換為`SQL`去執行:
生成一個`QuerySet`對象并不會馬上轉換為`SQL`語句去執行。
比如我們獲取`Book`表下所有的圖書:
```
<pre class="calibre12">```
books = Book.objects.all()
print(connection.queries)
```
```
我們可以看到在打印`connection.quries`的時候打印的是一個空的列表。說明上面的`QuerySet`并沒有真正的執行。
在以下情況下`QuerySet`會被轉換為`SQL`語句執行:
1. 迭代:在遍歷`QuerySet`對象的時候,會首先先執行這個`SQL`語句,然后再把這個結果返回進行迭代。比如以下代碼就會轉換為`SQL`語句:
```
<pre class="calibre12">```
<span class="hljs-keyword">for</span> book <span class="hljs-keyword">in</span> Book.objects.all():
print(book)
```
```
2. 使用步長做切片操作:`QuerySet`可以類似于列表一樣做切片操作。做切片操作本身不會執行`SQL`語句,但是如果如果在做切片操作的時候提供了步長,那么就會立馬執行`SQL`語句。需要注意的是,做切片后不能再執行`filter`方法,否則會報錯。
3. 調用`len`函數:調用`len`函數用來獲取`QuerySet`中總共有多少條數據也會執行`SQL`語句。
4. 調用`list`函數:調用`list`函數用來將一個`QuerySet`對象轉換為`list`對象也會立馬執行`SQL`語句。
5. 判斷:如果對某個`QuerySet`進行判斷,也會立馬執行`SQL`語句。
- Introduction
- 第一章:學前準備
- 第一節:虛擬環境
- 第二節:準備工作
- 第三節:Django介紹
- 第四節:URL組成部分
- 第二章:URL與視圖
- 第一節:第一個Django項目
- 第二節:視圖與URL分發器
- 第三章:模板
- 第一節:模板介紹
- 第二節:模板變量
- 第三節:常用標簽
- 第四節:常用過濾器
- 第五節:自定義過濾器
- 第七節:模版結構優化
- 第八節:加載靜態文件
- 第四章:數據庫
- 第一節:MySQL相關軟件
- 第二節:數據庫操作
- 第三節:ORM模型
- 第四節:模型常用字段
- 第五節:外鍵和表關系
- 第六節:增刪改查操作
- 第七節:查詢操作
- 第八節:QuerySet API
- 第九節:ORM模型遷移
- 第十節:ORM作業
- 第十一節:ORM作業參考答案
- 第十二節:Pycharm連接數據庫
- 第五章:視圖高級
- 第一節:限制請求method
- 第二節:頁面重定向
- 第三節:HttpRequest對象
- 第四節:HttpResponse對象
- 第五節:生成CSV文件
- 第六節:類視圖
- 第七節:錯誤處理
- 第六章:表單
- 第一節:表單概述
- 第二節:用表單驗證數據
- 第三節:ModelForm
- 第四節:文件上傳
- 第七章:cookie和session
- 第八章:上下文處理器和中間件
- 第一節:上下文處理器
- 第二節:中間件
- 第九章:安全
- 第一節:CSRF攻擊
- 第二節:XSS攻擊
- 第三節:點擊劫持攻擊
- 第四節:SQL注入
- 第十章:信號
- 第一節:什么是信號
- 第十一章:驗證和授權
- 第一節:概述
- 第二節:用戶對象
- 第三節:權限和分組
- 第十二章:Admin系統
- 第十三章:Django的緩存
- 第十四章:memcached
- 第十五章:Redis