
### JAVA內存模型\(JMM\)
定義:Java內存模型即Java Memory Model,簡稱JMM;
> **JMM定義了Java虛擬機\(JVM\)在計算機內存\(RAM\)中的工作方式**
Java內存模型(Java Memory Model ,JMM)就是一種符合內存模型規范的,屏蔽了各種硬件和操作系統的訪問差異的,保證了Java程序在各種平臺下對內存的訪問都能保證效果一致的機制及規范,現在最新的規范為JSR-133。
這套規范包含:
* 線程之間如何通過內存通信
* 線程之間通過什么方式通信才合法,才能得到期望的結果
JSR133為Java語言定義了一個新的內存模型,它修復了早期內存模型中的缺陷
在編譯器各種優化及多種類型的微架構平臺上,Java語言規范制定者試圖創建一個虛擬的概念并傳遞到Java程序員,讓他們能夠在這個虛擬的概念上寫出線程安全的程序來,而編譯器實現者會根據Java語言規范中的各種約束在不同的平臺上達到Java程序員所需要的線程安全這個目的
在多處理器下,為了保證各個處理器的緩存是一致的,就會實現緩存一致性協議,每個處理器通過嗅探在總線上傳播的數據來檢查自己緩存的值是不是過期了,當處理器發現自己緩存行對應的內存地址被修改,就會將當前處理器的緩存行設置成無效狀態,當處理器對這個數據進行修改操作的時候,會重新從系統內存中把數據讀到處理器緩存里;
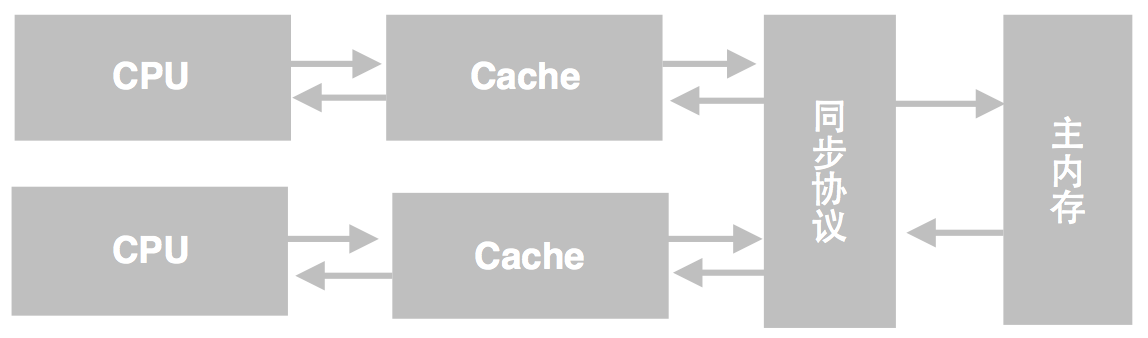
_在處理器層面上,內存模型定義了一個充要條件,“讓當前的處理器可以看到其他處理器寫入到內存的數據”以及“其他處理器可以看到當前處理器寫入到內存的數據”。有些處理器有很強的內存模型\(strong memory model\),能夠讓所有的處理器在任何時候任何指定的內存地址上都可以看到完全相同的值。而另外一些處理器則有較弱的內存模型(weaker memory model),在這種處理器中,必須使用內存屏障(一種特殊的指令)來刷新本地處理器緩存并使本地處理器緩存無效,目的是為了讓當前處理器能夠看到其他處理器的寫操作或者讓其他處理器能看到當前處理器的寫操作。這些內存屏障通常在lock和unlock操作的時候完成。內存屏障在高級語言中對程序員是不可見的_
**Java包含了幾個語言級別的關鍵字,包括:volatile, final以及synchronized,目的是為了幫助程序員向編譯器描述一個程序的并發需求**。Java內存模型定義了volatile和synchronized的行為,更重要的是保證了同步的java程序在所有的處理器架構下面都能正確的運行

從上圖來看,線程A與線程B之間如要通信的話,必須要經歷下面2個步驟:
1. 首先線程A把本地內存A中更新過的共享變量刷新到主內存中去。
2. 然后線程B到主內存中去讀取線程A之前已更新過的共享變量。
下面通過示意圖來說明這兩個步驟:

如上圖所示,本地內存A和B有主內存中共享變量x的副本。假設初始時,這三個內存中的x值都為0。線程A在執行時,把更新后的x值(假設值為1)臨時存放在自己的本地內存A中。當線程A和線程B需要通信時,線程A首先會把自己本地內存中修改后的x值刷新到主內存中,此時主內存中的x值變為了1。隨后,線程B到主內存中去讀取線程A更新后的x值,此時線程B的本地內存的x值也變為了1。
從整體來看,這兩個步驟實質上是線程A在向線程B發送消息,而且這個通信過程必須要經過主內存。JMM通過控制主內存與每個線程的本地內存之間的交互,來為java程序員提供內存可見性保證。
### Java內存模型的抽象結構
在Java中,所有實例域、靜態域和數組元素都存儲在堆內存中,堆內存在線程之間共享;局部變量(LocalVariables),方法定義參數(Java語言規范稱之為FormalMethodParameters)和異常處理器參數(ExceptionHandlerParameters)不會在線程之間共享,它們不會有內存可見性問題,也不受內存模型的影響;
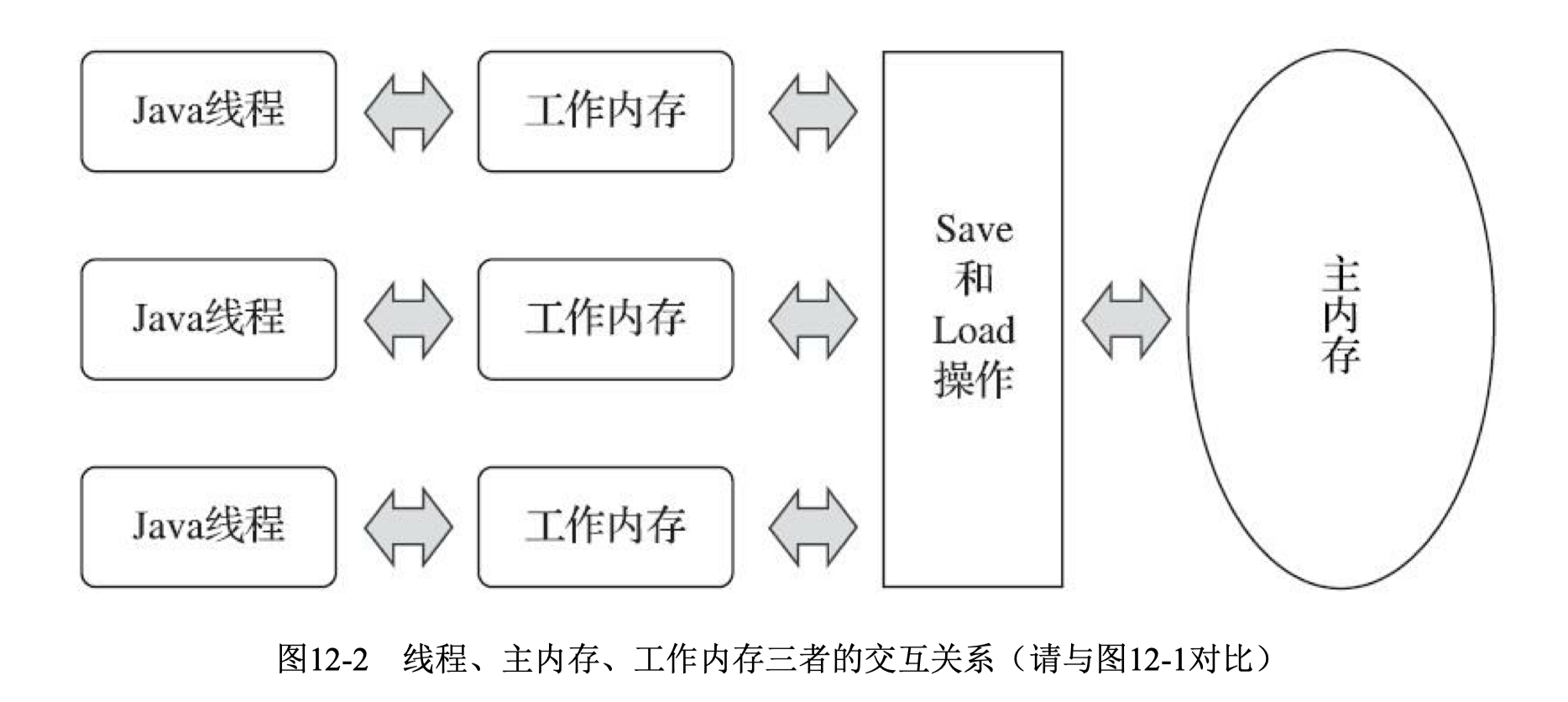
Java線程之間的通信由Java內存模型(本文簡稱為JMM)控制,JMM決定一個線程對共享變量的寫入何時對另一個線程可見。從抽象的角度來看,JMM定義了線程和主內存之間的抽象關系:線程之間的共享變量存儲在主內存(MainMemory)中,每個線程都有一個私有的本地內存(LocalMemory),本地內存中存儲了該線程以讀/寫共享變量的副本。本地內存是JMM的一個抽象概念,并不真實存在。它涵蓋了緩存、寫緩沖區、寄存器以及其他的硬件和編譯器優化;
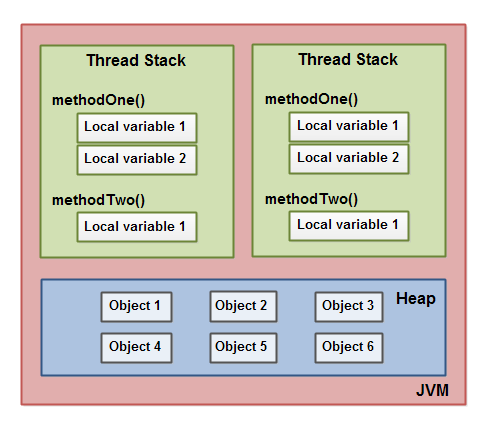
JVM中運行的每個線程都擁有自己的線程棧,線程棧包含了當前線程執行的方法調用相關信息,我們也把它稱作調用棧。隨著代碼的不斷執行,調用棧會不斷變化。
線程棧還包含了當前方法的所有本地變量信息。一個線程只能讀取自己的線程棧,也就是說,線程中的本地變量對其它線程是不可見的。即使兩個線程執行的是同一段代碼,它們也會各自在自己的線程棧中創建本地變量,因此,每個線程中的本地變量都會有自己的版本。
所有原始類型\(boolean,byte,short,char,int,long,float,double\)的本地變量都直接保存在線程棧當中,對于它們的值各個線程之間都是獨立的。對于原始類型的本地變量,一個線程可以傳遞一個副本給另一個線程,但它們之間是無法共享的。
堆區包含了Java應用創建的所有對象信息,不管對象是哪個線程創建的,其中的對象包括原始類型的封裝類(如Byte、Integer、Long等等)。不管對象是屬于一個成員變量還是方法中的本地變量,它都會被存儲在堆區。
下圖展示了調用棧和本地變量都存儲在棧區,對象都存儲在堆區:
特性
* 一個本地變量如果是原始類型,那么它會被完全存儲到棧區;
* 一個本地變量也有可能是一個對象的引用,這種情況下,這個本地引用會被存儲到棧中,但是對象本身仍然存儲在堆區。
* 對于一個對象的成員方法,這些方法中包含本地變量,仍需要存儲在棧區,即使它們所屬的對象在堆區。
* 對于一個對象的成員變量,不管它是原始類型還是包裝類型,都會被存儲到堆區。
* static類型的變量以及類本身相關信息都會隨著類本身存儲在方法區;
堆中的對象可以被多線程共享。如果一個線程獲得一個對象的引用,它便可訪問這個對象的成員變量。如果兩個線程同時調用了同一個對象的同一個方法,那么這兩個線程便可同時訪問這個對象的成員變量,但是對于本地變量,每個線程都會拷貝一份到自己的線程棧中,下圖展示了上面描述的過程:

### 支撐Java內存模型的基礎原理
* **指令重排序**
* **數據依賴性**
如果兩個操作訪問同一個變量,其中一個為寫操作,此時這兩個操作之間存在數據依賴性。 編譯器和處理器不會改變存在數據依賴性關系的兩個操作的執行順序,即不會重排序。
| 名稱 | 代碼示例 | 說明 |
| :--- | :--- | :--- |
| 寫后讀 | a = 1;b = a; | 寫一個變量之后,再讀這個位置。 |
| 寫后寫 | a = 1;a = 2; | 寫一個變量之后,再寫這個變量。 |
| 讀后寫 | a = b;b = 1; | 讀一個變量之后,再寫這個變量。 |
* **as-if-serial**
不管怎么重排序,單線程下的執行結果不能被改變,編譯器、runtime和處理器都必須遵守as-if-serial語義
```
double pi = 3.14; //A
double r = 1.0; //B
double area = pi * r * r; //C
```
```
上面三個操作的數據依賴關系如下圖所示:
```

如上圖所示,A和C之間存在數據依賴關系,同時B和C之間也存在數據依賴關系。因此在最終執行的指令序列中,C不能被重排序到A和B的前面(C排到A和B的前面,程序的結果將會被改變)。但A和B之間沒有數據依賴關系,編譯器和處理器可以重排序A和B之間的執行順序。下圖是該程序的兩種執行順序:

as-if-serial語義把單線程程序保護了起來,遵守as-if-serial語義的編譯器,runtime 和處理器共同為編寫單線程程序的程序員創建了一個幻覺:單線程程序是按程序的順序來執行的。**as-if-serial語義使單線程程序員無需擔心重排序會干擾他們,也無需擔心內存可見性問題**。
_**參考資料**_
【Java內存模型FAQ(一) 什么是內存模型】 [http://ifeve.com/memory-model](http://ifeve.com/memory-model)
【全面理解Java內存模型】[https://blog.csdn.net/suifeng3051/article/details/52611310](https://blog.csdn.net/suifeng3051/article/details/52611310)
【深入理解Java內存模型(一)——基礎】 [http://www.infoq.com/cn/articles/java-memory-model-1](http://www.infoq.com/cn/articles/java-memory-model-1)
【Java內存模型FAQ】 [http://ifeve.com/jmm-faq/](http://ifeve.com/jmm-faq/)
- 前言
- Write once, run anywhere
- 概述
- JAVA虛擬機
- JVM整體結構
- JVM架構模型
- JVM虛擬機分類
- HotSpot VM
- JRockit
- IBM-J9
- Azul/zing VM
- Taobao VM
- Dalvik VM
- Graal VM
- JAVA源碼編譯機制
- Javac編譯器
- 分析和輸入到符號表
- 注解處理
- 語義分析和生成class文件
- ECJ編譯器
- 類執行機制
- 字節碼解釋執行
- 棧頂緩存
- 部分棧幀共享
- 編譯執行
- 即時編譯器
- C1 Compiler
- C2 Compiler
- Graal編譯器
- C1與C2編譯器
- AOT
- 編譯優化
- 字符串優化
- 方法內聯
- 逃逸分析
- 同步消除
- 標量替換
- 棧上分配
- 去虛擬化/逆優化
- 多層編譯
- JVM編譯策略
- OSR編譯
- 冗余削除
- CodeCache
- 常量編譯優化
- JVM運行時數據區
- 程序計數器
- JAVA虛擬機棧
- 棧幀
- 局部變量表
- 操作數棧
- 本地方法棧
- Java調用native方法
- JVM Stacks && Native Stacks
- 堆-Heap
- 方法區(Method Area)
- 運行時常量池
- 常量傳播優化
- MetaSpace
- 直接內存
- StackOverflowError
- 遞歸方法
- OutOfMemoryError
- 本地內存溢出
- 執行引擎
- 運行時數據區關聯關系
- jdk8內存結構
- JMM內存模型
- JAVA內存模型
- JMM八種操作指令
- 內存屏障
- 指令重排
- as-if-serial語義
- Happen-Before規則
- 數據依賴性
- 原子性、可見性與有序性
- 偽共享
- CPU三級緩存
- 緩存行
- MESI協議
- Java中的偽共享
- ConcurrentHashMap偽共享解決方案
- 虛擬機對象
- 對象創建原理
- 對象內存布局
- 對象頭
- 實例數據
- 對象的訪問定位
- 垃圾收集器與內存分配策略
- GC相關概念
- TLAB
- JVM GC工作原理
- 內存管理
- JAVA引用分類
- 死亡標記
- 回收方法區
- 三色標記算法
- 垃圾收集算法
- 標記-清除算法
- 標記-整理算法
- 復制算法
- 分代收集算法
- HotSpot算法實現
- STW
- 垃圾收集器
- 常見的垃圾收集器
- 垃圾收集器分類
- Serial收集器
- Serial Old收集器
- ParNew收集器
- Parallel Scavenge收集器
- Parallel Old收集器
- CMS收集器
- CMS完整收集過程
- Card Table
- G1收集器
- 分代收集
- 空間整合
- 可預測的停頓時間模型
- G1&CMS
- 主要參數說明
- G1適用場景
- Remembered Set
- G1垃圾回收的過程
- G1優化建議
- Shenandoah
- ZGC
- 垃圾收集器特點
- GC日志
- GC策略的評價指標
- jvm card table數據結構
- 對象生存軌跡
- 類文件結構
- 魔數
- 版本號
- 常量池
- 訪問標志
- 父類索引
- 接口集合
- 字段集合
- 方法集合
- 屬性集合
- 類加載機制與類的初始化
- Java代碼執行流程
- 類加載過程
- 抽象類ClassLoader
- 常見類加載器
- BootstrapClassLoader
- 自定義類加載器
- 線程上下文類加載器
- 雙親委派模型
- Tomcat類加載機制
- ServiceLoader
- 類的初始化
- 常見的JVM類加載異常
- ClassNotFoundException
- NoClassDefFoundError
- LinkageError
- ClassCastException
- 虛擬機性能調優監控與故障處理工具
- CPU利用率高/飆升
- 排查及解決方案
- 上下文切換
- GC問題定位解決方案
- prommotion failed
- FullGC頻繁
- youngGC
- 內存問題
- 內存溢出和內存泄漏
- 內存溢出
- 棧溢出
- 堆溢出
- 對外內存溢出
- 內存泄漏
- 磁盤問題
- 線上問題解決方案
- 不定期出現的接口耗時現象
- 線程池異常
- 死鎖問題
- JVM調優
- jvm參考配置
- jvm-jstat
- jvm-jmap
- jvm-jstack
- jinfo
- jps
- 虛擬機的退出
- Shutdown Hook
- JVM指令
- 附錄
- 常用JVM指令
- Class文件版本號
- Class文件格式
- 方法訪問標識
- jvm常量池
- 類或接口的訪問標識
- 描述符標識字符含義
- 字段訪問標識
- Java程序與Docker容器環境
- 基準測試