
### 內存屏障\(Memory Barrier\)
內存屏障(Memory Barrier,或叫做內存柵欄,Memory Fence)是一種CPU指令,用于控制特定條件下的重排序和內存可見性問題。Java編譯器也會根據內存屏障的規則禁止重排序,內存屏障可以禁止特定類型處理器的重排序,從而讓程序按我們預想的流程去執行。
內存柵欄\(Memory Barrier\):內存柵欄可以刷新緩存,使緩存無效,刷新硬件的寫緩沖,以及停止執行管道
內存屏障是一條這樣的指令:
* 保證特定操作的執行順序;
* 影響某些數據(或是某條指令的執行結果)的內存可見性;
編譯器和CPU能夠重排序指令,保證最終相同的結果,嘗試優化性能。插入一條Memory Barrier會告訴編譯器和CPU:不管什么指令都不能和這條Memory Barrier指令重排序。
Memory Barrier所做的另外一件事是強制刷出各種CPU cache,如一個Write-Barrier(寫入屏障)將刷出所有在Barrier之前寫入 cache 的數據,因此,任何CPU上的線程都能讀取到這些數據的最新版本。
```
“這和java有什么關系?上面java內存模型中講到的volatile是基于Memory Barrier實現的”
```
如果一個變量是volatile修飾的,JMM會在寫入這個字段之后插進一個Write-Barrier指令,并在讀這個字段之前插入一個Read-Barrier指令。這意味著,如果寫入一個volatile變量,就可以保證:
* 一個線程寫入變量a后,任何線程訪問該變量都會拿到最新值。
* 在寫入變量a之前的寫入操作,其更新的數據對于其他線程也是可見的。因為Memory Barrier會刷出cache中的所有先前的寫入。
### 內存屏障類型
* LoadLoad屏障:對于這樣的語句Load1; LoadLoad; Load2,在Load2及后續讀取操作要讀取的數據被訪問前,保證Load1要讀取的數據被讀取完畢。
* StoreStore屏障:對于這樣的語句Store1; StoreStore; Store2,在Store2及后續寫入操作執行前,保證Store1的寫入操作對其它處理器可見。
* LoadStore屏障:對于這樣的語句Load1; LoadStore; Store2,在Store2及后續寫入操作被刷出前,保證Load1要讀取的數據被讀取完畢。
* StoreLoad屏障:對于這樣的語句Store1; StoreLoad; Load2,在Load2及后續所有讀取操作執行前,保證Store1的寫入對所有處理器可見。它的開銷是四種屏障中最大的。在大多數處理器的實現中,這個屏障是個萬能屏障,兼具其它三種內存屏障的功能
基于保守策略的JMM內存屏障插入策略:
* 在每個volatile寫操作的前面插入一個StoreStore屏障;
* 在每個volatile寫操作的后面插入一個StoreLoad屏障;
* 在每個volatile讀操作的后面插入一個LoadLoad屏障;
* 在每個volatile讀操作的后面插入一個LoadStore屏障;
### volatile寫
基于保守策略下,volatile寫插入內存屏障后生成的指令序列示意圖
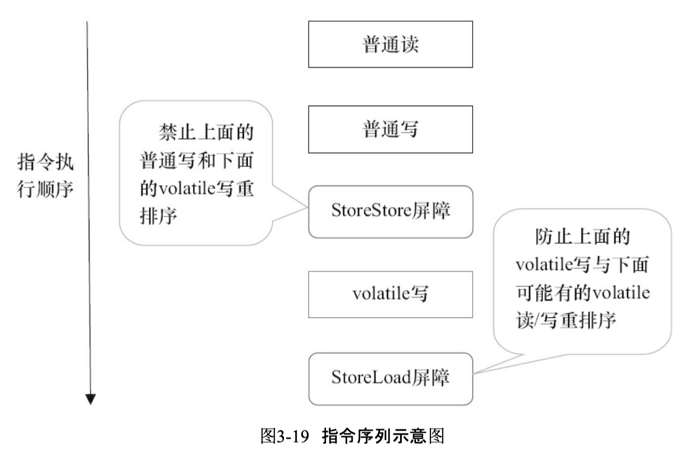
上圖中的StoreStore屏障可以保證在volatile寫之前,其前面的所有普通寫操作已經對任意處理器可見了。這是因為StoreStore屏障將保障上面所有的普通寫在volatile寫之前刷新到主內存;
注意volatile寫后面的StoreLoad屏障:此屏障的作用是避免volatile寫與后面可能有的volatile讀/寫操作重排序。因為編譯器常常無法準確判斷在一個volatile寫的后面是否需要插入一個StoreLoad屏障(比如,一個volatile寫之后方法立即return)。為了保證能正確實現volatile的內存語義,JMM在采取了保守策略:在每個volatile寫的后面,或者在每個volatile讀的前面插入一個StoreLoad屏障。從整體執行效率的角度考慮,JMM最終選擇了在每個volatile寫的后面插入一個StoreLoad屏障。因為volatile寫-讀內存語義的常見使用模式是:一個寫線程寫volatile變量,多個讀線程讀同一個volatile變量。當讀線程的數量大大超過寫線程時,選擇在volatile寫之后插入StoreLoad屏障將帶來可觀的執行效率的提升。從這里可以看到JMM在實現上的一個特點:首先確保正確性,然后再去追求執行效率
### volatile讀
volatile讀插入內存屏障后生成的指令序列示意圖
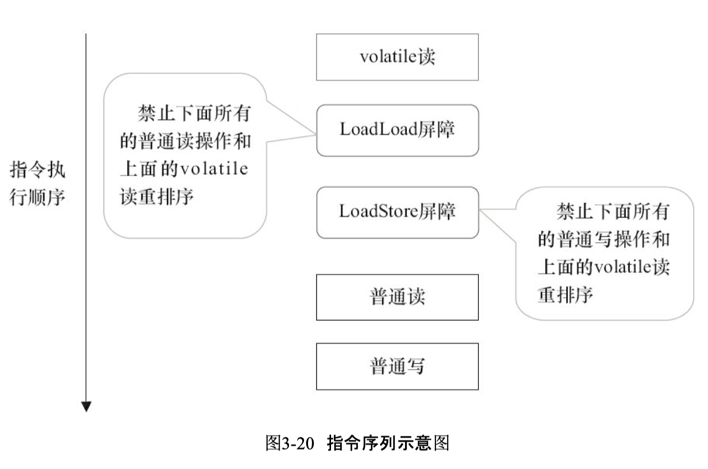
上圖中的LoadLoad屏障用來禁止處理器把上面的volatile讀與下面的普通讀重排序。LoadStore屏障用來禁止處理器把上面的volatile讀與下面的普通寫重排序。
_**參考資料**_
【Java內存模型Cookbook(二)內存屏障】[http://ifeve.com/jmm-cookbook-mb/](http://ifeve.com/jmm-cookbook-mb/)
- 前言
- Write once, run anywhere
- 概述
- JAVA虛擬機
- JVM整體結構
- JVM架構模型
- JVM虛擬機分類
- HotSpot VM
- JRockit
- IBM-J9
- Azul/zing VM
- Taobao VM
- Dalvik VM
- Graal VM
- JAVA源碼編譯機制
- Javac編譯器
- 分析和輸入到符號表
- 注解處理
- 語義分析和生成class文件
- ECJ編譯器
- 類執行機制
- 字節碼解釋執行
- 棧頂緩存
- 部分棧幀共享
- 編譯執行
- 即時編譯器
- C1 Compiler
- C2 Compiler
- Graal編譯器
- C1與C2編譯器
- AOT
- 編譯優化
- 字符串優化
- 方法內聯
- 逃逸分析
- 同步消除
- 標量替換
- 棧上分配
- 去虛擬化/逆優化
- 多層編譯
- JVM編譯策略
- OSR編譯
- 冗余削除
- CodeCache
- 常量編譯優化
- JVM運行時數據區
- 程序計數器
- JAVA虛擬機棧
- 棧幀
- 局部變量表
- 操作數棧
- 本地方法棧
- Java調用native方法
- JVM Stacks && Native Stacks
- 堆-Heap
- 方法區(Method Area)
- 運行時常量池
- 常量傳播優化
- MetaSpace
- 直接內存
- StackOverflowError
- 遞歸方法
- OutOfMemoryError
- 本地內存溢出
- 執行引擎
- 運行時數據區關聯關系
- jdk8內存結構
- JMM內存模型
- JAVA內存模型
- JMM八種操作指令
- 內存屏障
- 指令重排
- as-if-serial語義
- Happen-Before規則
- 數據依賴性
- 原子性、可見性與有序性
- 偽共享
- CPU三級緩存
- 緩存行
- MESI協議
- Java中的偽共享
- ConcurrentHashMap偽共享解決方案
- 虛擬機對象
- 對象創建原理
- 對象內存布局
- 對象頭
- 實例數據
- 對象的訪問定位
- 垃圾收集器與內存分配策略
- GC相關概念
- TLAB
- JVM GC工作原理
- 內存管理
- JAVA引用分類
- 死亡標記
- 回收方法區
- 三色標記算法
- 垃圾收集算法
- 標記-清除算法
- 標記-整理算法
- 復制算法
- 分代收集算法
- HotSpot算法實現
- STW
- 垃圾收集器
- 常見的垃圾收集器
- 垃圾收集器分類
- Serial收集器
- Serial Old收集器
- ParNew收集器
- Parallel Scavenge收集器
- Parallel Old收集器
- CMS收集器
- CMS完整收集過程
- Card Table
- G1收集器
- 分代收集
- 空間整合
- 可預測的停頓時間模型
- G1&CMS
- 主要參數說明
- G1適用場景
- Remembered Set
- G1垃圾回收的過程
- G1優化建議
- Shenandoah
- ZGC
- 垃圾收集器特點
- GC日志
- GC策略的評價指標
- jvm card table數據結構
- 對象生存軌跡
- 類文件結構
- 魔數
- 版本號
- 常量池
- 訪問標志
- 父類索引
- 接口集合
- 字段集合
- 方法集合
- 屬性集合
- 類加載機制與類的初始化
- Java代碼執行流程
- 類加載過程
- 抽象類ClassLoader
- 常見類加載器
- BootstrapClassLoader
- 自定義類加載器
- 線程上下文類加載器
- 雙親委派模型
- Tomcat類加載機制
- ServiceLoader
- 類的初始化
- 常見的JVM類加載異常
- ClassNotFoundException
- NoClassDefFoundError
- LinkageError
- ClassCastException
- 虛擬機性能調優監控與故障處理工具
- CPU利用率高/飆升
- 排查及解決方案
- 上下文切換
- GC問題定位解決方案
- prommotion failed
- FullGC頻繁
- youngGC
- 內存問題
- 內存溢出和內存泄漏
- 內存溢出
- 棧溢出
- 堆溢出
- 對外內存溢出
- 內存泄漏
- 磁盤問題
- 線上問題解決方案
- 不定期出現的接口耗時現象
- 線程池異常
- 死鎖問題
- JVM調優
- jvm參考配置
- jvm-jstat
- jvm-jmap
- jvm-jstack
- jinfo
- jps
- 虛擬機的退出
- Shutdown Hook
- JVM指令
- 附錄
- 常用JVM指令
- Class文件版本號
- Class文件格式
- 方法訪問標識
- jvm常量池
- 類或接口的訪問標識
- 描述符標識字符含義
- 字段訪問標識
- Java程序與Docker容器環境
- 基準測試