
# Kafka 術語
* 消息(Record)
* Kafka 中發布訂閱的對象是 `Topic`,可以為每個業務、應用、數據類型定義 Topic。
* 生產者(Producer)
* 消費者(Consumer)
* 客戶端(Clients):生產者、消費者統稱為客戶端
* 服務端
* Kafka 的服務器端:Broker 服務進程
* 一個 Kafka 集群由多個 Broker 組成
* Broker:負責接收和處理客戶端發送過來的請求 & 消息持久化
* 多個 Broker 進程能夠運行在同一臺機器上
* 但常見做法:將不同的 Broker 分散運行在不同的機器上
* 備份機制(Replication)
* 備份思想:把相同的數據拷貝到多臺機器上
* 副本(Replica):Kafka 中稱這些相同的數據為副本
* 副本保存相同的數據
* 但有不通的角色和作用
* 領導者副本(Leader Replica)
* 對外提供服務(i.e. 與客戶端進程交互)
* 追隨者副本(Follower Replica)
* 只追隨領導者副本數據
* 不對外提供服務
* 副本的工作機制
* Producer
* 向 Leader Replica 寫消息
* Consumer
* 從Leader Replica 讀消息
* Follower Replica
* 向 Leader Replica 發送請求,獲取最新生產的消息
* 目的:與 Leader 保持同步
* 副本的優缺點
* 優點
* 保證數據的持久化 / 消息不丟失
* 缺點
* 不能解決伸縮性問題
* 伸縮性(Scalability)
* 伸縮性問題:當 Leader Replica 副本積累太多以至于單臺 Broker 機器無法容納的問題
* 考慮將數據分割成多份保存在不同的 Broker 上
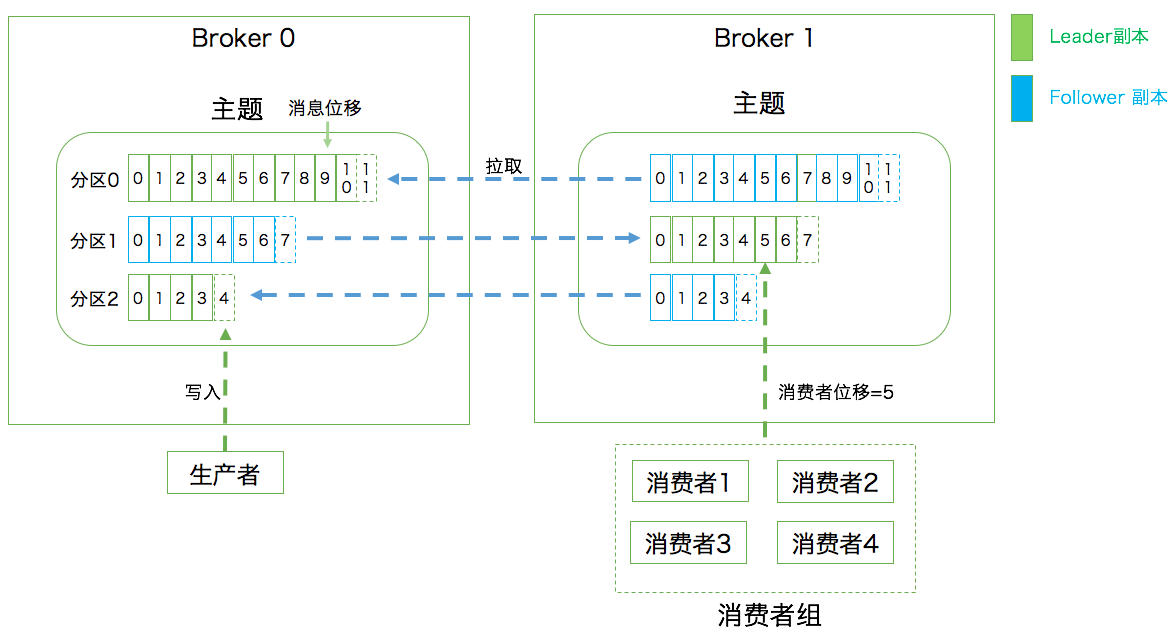
* 分區機制(Partitioning)
* Kafka 將每個 Topic 劃分為多個分區(Partition)
* 每個分區是一組有序的消息日志
* Producer 生產的每條消息只會發送到一個分區中
* Kafka 分區編號從 0 開始
* 副本是分區這個層級定義的,即對 Partition 實現副本機制
* 每個 Partition 可以配置 N 個副本,其中 1 個 Leader Replica,N-1 個 Follower Replica
* Producer 向分區寫消息,每條消息在分區中的位置信息由一個叫`位移(Offset)`的數據來表征
* 分區位移從 0 開始
* 日志
* 追加寫
* 日志段
* 通過日志段進行回收
### Broker 持久化數據
* Kafka 使用消息日志(Log)保存數據
* 一個日志
* 定義:磁盤上一個只能追加寫(Append-only)消息的物理文件
* Apped-only 避免了緩慢的隨機 IO 操作,改為性能更好的順序 IO 寫
* 回收磁盤
* 通過日志段(Log Segment)機制
* 當寫滿了一個日志段后,Kafka 會自動切分出一個新的日志段
* 同時將老日志段封存
* Kafka 在后臺通過定時任務,定期檢查老日志段是否可以刪除,從而回收磁盤
### P2P 模式的實現
* P2P 指消息只能被下游一個消費者消費
* 消費者組(Consumer Group)
* 通過飲用消費者組來實現 P2P
* 定義:多個 Consumer 共同組成一個組來消費一組 Topic
* 這組 Topic 中的每個 Partition 都只會被組內的一個 Consumer 消費
* e.g. 一個 Topic 被分 N 個 Partition,那么這個消費者組中可以有 N 個 Consumer,每一個 Consumer 消費一個 Partition
* 分配后的 Partition 其他 Consumer 不能消費
* 引入消費者組的目的
* 提升消費端吞吐量(TPS)
* 一個消費者實例(Consumer Instance)
* 可以是業務
* 也可以是單個進程、線程
* Kafka 重平衡(Rebalance)
* 當一個消費者組內某個 Consumer 實例掛了
* Kafka 通過自動檢測,將 Failed Consumer 實例之前負責的 Partition 轉移給其他活著的消費者
* 消費者位移(Consumer Offset)
* 每個 Consumer 在消費中通過字段記錄它當前消費到了哪個 Partition 的哪個位置
* 每個 Consumer 都是不一樣的
* 上面位移表示 Partition 內消息的位置,是不同的,因此其也稱為分區位移
* 消費者位移可能隨時變化,類似一個指針
### Kafka 的三層架構
* Topic
* 每個 Topic 配置 M 個 Partition
* Partition
* 每個 Partition 配置 N 個副本
* 1 個 Leader Replica,對外提供服務
* N-1 個 Follower Replica,只提供消息冗余作用
* Record
* 每個 Partition 包含若干 Record
* 每個 Record 的位移從 0 開始,依次遞增
### Kafka 提供高可用的手段總結
* Broker
* Kafka 集群中每臺機器都會運行多個 Broker 進程
* 一臺機器掛了,其他機器的 Broker 依然能夠對外提供服務
* 備份機制
### Follower Replica & MySQL
* Kafka 的 Follower Replica 是不會對外提供服務的
* 相反的,MySQL 的從庫會對外提供讀服務
- 概覽
- 入門
- 1. 消息引擎系統
- 2. Kafka 術語
- 3. 分布式流處理平臺
- 4. Kafka “發行版”
- 5. Kafka 版本號
- 基本使用
- 6. 生產集群部署
- 7. 集群參數配置
- 客戶端實踐與原理
- 9. Consumer 分區機制
- 10. Consumer 壓縮算法
- 11. 無消息丟失配置
- 12. 客戶端高級功能
- 13. Producer 管理 TCP
- 14. 冪等生產者和事務生產者
- 15. 消費者組
- 16. 位移主題
- 17. 消費者組重平衡(TODO)
- 18. 位移提交
- 19. CommitFailedException
- 20. 多線程開發者實例
- 21. Consumer 管理 TCP
- 22. 消費者組消費進度監控
- Kafka 內核
- 23. 副本機制
- 24. 請求處理
- 25. Rebalance 全流程
- 26. Kafka 控制器
- 27. 高水位和 Leader Epoch
- 管理與監控
- 28. Topic 管理
- 29. Kafka 動態配置
- 30. 重設消費者組位移
- 31. 工具腳本
- 32. KafkaAdminClient
- 33. 認證機制
- 34. 云下授權
- 35. 跨集群備份 MirrorMaker
- 36. 監控 Kafka
- 37. Kafka 監控框架
- 38. 調優 Kafka
- 39. 實時日志流處理平臺
- 流處理
- 40. Kafka Streams
- 41. Kafka Streams DSL
- 42. Kafka Streams 金融
- Q&A