
# 生產者消息分區機制
## 背景需求
* 希望數據能夠均勻地分配到所有 Broker
## 為什么分區
* Kafka 消息組織結構的三層結構:Topic - Partition - Record
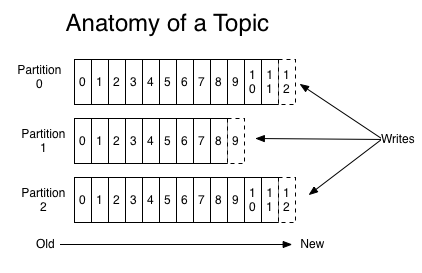
* 分區的目的:提供負載均衡的能力,i.e. 系統的高伸縮性(Scalability)
* 不同的分區能夠放在不同的節點,數據的讀寫以分區粒度進行
* 因此可以增加節點機器來增加系統吞吐
* 不同系統分區的叫法
* Kafka:Partition 分區
* MongoDB / ElasticSearch:Shard 分片
* HBase:Region
* Cassandra:vnode
* 它們底層的思想都是 Partitioning
## 分區策略
* 分區策略:決定生產者將消息發送到哪個分區的算法
* 自定義分區策略
* 配置 Producer 的參數:partitioner.class
* 實現:編寫一個具體的類實現 `org.apache.kafka.clients.producer.Partitioner` 接口
* 該接口只定義了兩個方法:partition(), close()
```
int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster);
```
* 充分利用參數對信息計算,將其發到哪個分區
### 常見分區策略
* 輪詢策略,i.e. Round-robin 策略
* 順序分配
* 默認分區策略
* 隨機策略,i.e. Randomness 策略
* 按消息鍵保序策略,i.e. Key-ordering 策略
* 每條消息定義消息鍵,i.e. Key
* 默認分區策略有兩種
* 如果沒指定 Key,則是輪詢策略
* 否則是 Key-ordering 策略
### 其他分區策略
* 基于地理位置的分區策略
* e.g. 跨城市大規模 Kafka 集群
## 其他
* Kafka 中同一個 Topic 不保證消息順序性,但是 Topic 下同一個 Partition 是保障順序性的
- 概覽
- 入門
- 1. 消息引擎系統
- 2. Kafka 術語
- 3. 分布式流處理平臺
- 4. Kafka “發行版”
- 5. Kafka 版本號
- 基本使用
- 6. 生產集群部署
- 7. 集群參數配置
- 客戶端實踐與原理
- 9. Consumer 分區機制
- 10. Consumer 壓縮算法
- 11. 無消息丟失配置
- 12. 客戶端高級功能
- 13. Producer 管理 TCP
- 14. 冪等生產者和事務生產者
- 15. 消費者組
- 16. 位移主題
- 17. 消費者組重平衡(TODO)
- 18. 位移提交
- 19. CommitFailedException
- 20. 多線程開發者實例
- 21. Consumer 管理 TCP
- 22. 消費者組消費進度監控
- Kafka 內核
- 23. 副本機制
- 24. 請求處理
- 25. Rebalance 全流程
- 26. Kafka 控制器
- 27. 高水位和 Leader Epoch
- 管理與監控
- 28. Topic 管理
- 29. Kafka 動態配置
- 30. 重設消費者組位移
- 31. 工具腳本
- 32. KafkaAdminClient
- 33. 認證機制
- 34. 云下授權
- 35. 跨集群備份 MirrorMaker
- 36. 監控 Kafka
- 37. Kafka 監控框架
- 38. 調優 Kafka
- 39. 實時日志流處理平臺
- 流處理
- 40. Kafka Streams
- 41. Kafka Streams DSL
- 42. Kafka Streams 金融
- Q&A