
# Kafka 副本機制
副本機制(Replication) aka. 備份機制:指分布式系統在多臺互聯的機器上保存有相同的數據拷貝
副本優勢
* 提供數據冗余
* 提供高伸縮性
* 支持橫向擴展
* 增加機器即可提升讀性能
* 改善數據局部性
* 允許數據放入用戶地理位置相近的地方從而降低延時
> Apache Kafka 只實現了第一點
## Kafka 副本定義
* 副本的定義是在分區(Partition)層下定義的,i.e. 每個分區有多個副本
* 副本(Replica):本質是只能追加寫消息的提交日志
* 副本分散保存在不同的 Broker 上
## Kafka 副本角色
Q:如何確保副本中所有的數據都是一致的?
A:基于領導者(Leader-based)的副本機制
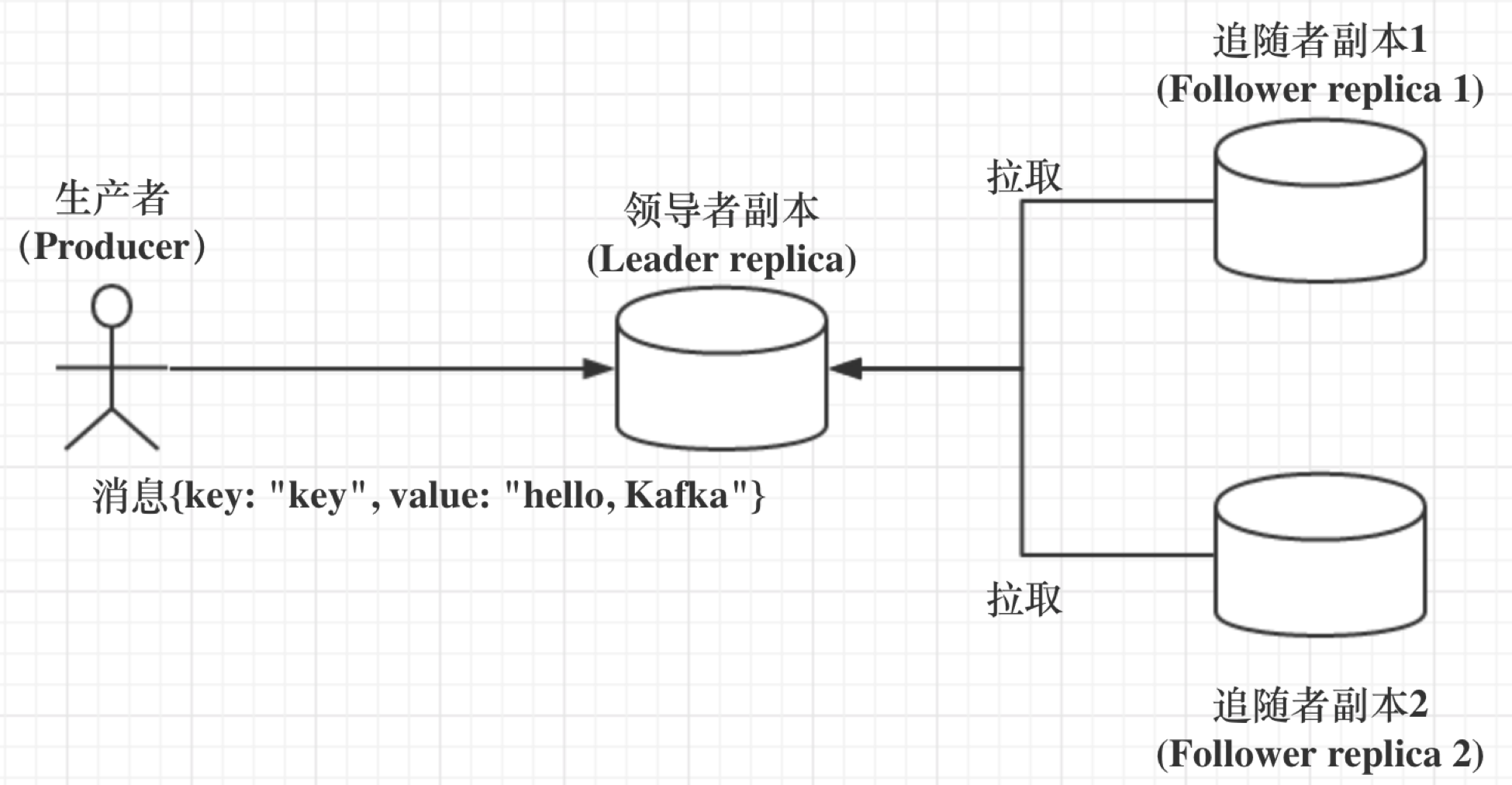
* Kafka 中副本分為領導者副本(Leader Replica) & 追隨者副本(Follower Replica)
* 每個 Partition 創建時都要選舉一個副本,稱為 Leader Replica,其余副本為 Follower Replica
* Kafka 中 Follower Replica 不對外提供服務
* 所有讀寫請求均發生在 Leader Replica 所在的 Broker,由該 Broker 負責
* Follower Replica 的唯一職責:從 Leader Replica 異步拉取消息,寫入到自己的提交日志中
* Leader Replica / Broker 宕機時,Kafka 依靠 ZK 提供的監控功能開啟新一輪 Leader Election
* 從 Follower Replica 中選取
* 老 Leader Replica 恢復后會作為 Follower Replica 加入集群
這種副本機制設計的優勢
* 方便實現 Read-your-writes
* Read-your-writes:當你使用 Producer API 寫消息后,馬上使用 Consumer API 去消費
* 如果允許 Follower 對外提供服務,由于異步,因此不能實現 Read-your-writes
* 方便實現單調讀(Monotonic Reads)
* 單調讀:對于一個 Consumer,多次消費時,不會看到某條消息一會存在一會不存在
* 問題案例
* 如果允許 Follower 提供服務,假設有兩個 Follower F1、F2
* 如果 F1 拉取了最新消息而 F2 還沒有
* 對于 Consumer 第一次消費時從 F1 看到的消息,第二次從 F2 則可能看不到
* 這種場景是非單調讀
* 所有讀請求通過 Leader 則可以實現單調讀
* In-sync Replicas(ISR)
* 對于 Follower 存在與 Leader 不同步的風險
* Kafka 要明確 Follower 在什么條件下算與 Leader 同步,因此引入 ISR 副本集合
* Q:什么副本算作 ISR?
* A:
* Leader 天然在 ISR 中,某些情況 ISR 中只有 Leader
* Kafka 判斷 Follower 和 Leader 同步的標準基于 Broker 端參數 `replica.lag.time.max.ms`,i.e. Follower Replica 能夠落后 Leader Replica 的最長時間間隔,默認值是 10s
* 如果一個 Follower 落后 Leader 不超過 10s,則認為該 Follower 是同步的,即該 Follower 被認為是 ISR
* ISR 是動態調整的
## Unclean Leader Election
* 由于 ISR 是動態調整的,可能出現 ISR 為空,即 Leader 宕機,Follower 都不同步
* ISR 為空時,如何選舉新 Leader?
* `非同步副本`:Kafka 把所有不在 ISR 中的存活副本稱為非同步副本
* Broker 參數 `unclean.leader.election.enable` 控制是否允許 Unclean Leader Election
* 即如果參數為 true,ISR 為空是,會從非同步副本中選舉 Leader
---
* 優勢:提高可用性
* 缺點:數據丟失
基于 CAP,Kafka 賦予你選擇 C / A 的權利。
- 概覽
- 入門
- 1. 消息引擎系統
- 2. Kafka 術語
- 3. 分布式流處理平臺
- 4. Kafka “發行版”
- 5. Kafka 版本號
- 基本使用
- 6. 生產集群部署
- 7. 集群參數配置
- 客戶端實踐與原理
- 9. Consumer 分區機制
- 10. Consumer 壓縮算法
- 11. 無消息丟失配置
- 12. 客戶端高級功能
- 13. Producer 管理 TCP
- 14. 冪等生產者和事務生產者
- 15. 消費者組
- 16. 位移主題
- 17. 消費者組重平衡(TODO)
- 18. 位移提交
- 19. CommitFailedException
- 20. 多線程開發者實例
- 21. Consumer 管理 TCP
- 22. 消費者組消費進度監控
- Kafka 內核
- 23. 副本機制
- 24. 請求處理
- 25. Rebalance 全流程
- 26. Kafka 控制器
- 27. 高水位和 Leader Epoch
- 管理與監控
- 28. Topic 管理
- 29. Kafka 動態配置
- 30. 重設消費者組位移
- 31. 工具腳本
- 32. KafkaAdminClient
- 33. 認證機制
- 34. 云下授權
- 35. 跨集群備份 MirrorMaker
- 36. 監控 Kafka
- 37. Kafka 監控框架
- 38. 調優 Kafka
- 39. 實時日志流處理平臺
- 流處理
- 40. Kafka Streams
- 41. Kafka Streams DSL
- 42. Kafka Streams 金融
- Q&A