[TOC]
## **機器學習、人工智能、深度學習是什么關系?**
* 機器學習研究和構建的是一種特殊算法(**而非某一個特定的算法**),能夠讓計算機自己在數據中學習從而進行預測。
所以,**機器學習不是某種具體的算法,而是很多算法的統稱。**
* 機器學習包含了很多種不同的算法,深度學習就是其中之一,其他方法包括決策樹,聚類,貝葉斯等。
*
* 深度學習的靈感來自大腦的結構和功能,即許多神經元的互連。人工神經網絡(ANN)是模擬大腦生物結構的算法。
*
* 不管是機器學習還是深度學習,都屬于人工智能(AI)的范疇。所以人工智能、機器學習、深度學習可以用下面的圖來表示:
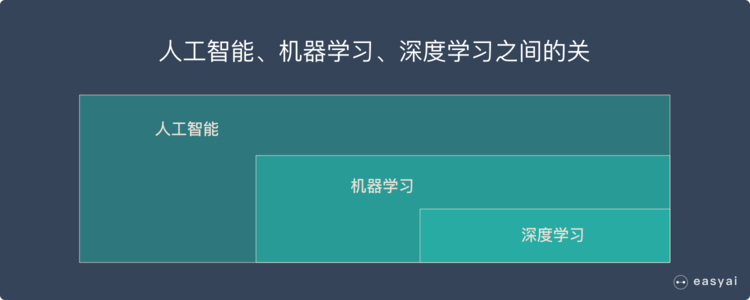
人工智能、機器學習、深度學習的關系
## **什么是機器學習?**
### **機器學習的基本思路**
1. 把現實生活中的問題抽象成數學模型,并且很清楚模型中不同參數的作用
2. 利用數學方法對這個數學模型進行求解,從而解決現實生活中的問題
3. 評估這個數學模型,是否真正的解決了現實生活中的問題,解決的如何?
**無論使用什么算法,使用什么樣的數據,最根本的思路都逃不出上面的3步!**
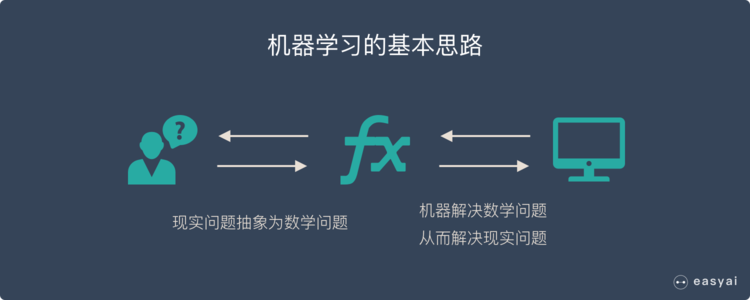
機器學習的基本思路
* 當我們理解了這個基本思路,我們就能發現:
* 不是所有問題都可以轉換成數學問題的。那些沒有辦法轉換的現實問題 AI 就沒有辦法解決。同時最難的部分也就是把現實問題轉換為數學問題這一步。
### **機器學習的原理**
* 下面以監督學習為例,講解一下機器學習的實現原理。
*
* 假如我們正在教小朋友識字(一、二、三)。我們首先會拿出3張卡片,然后便讓小朋友看卡片,一邊說“一條橫線的是一、兩條橫線的是二、三條橫線的是三”。
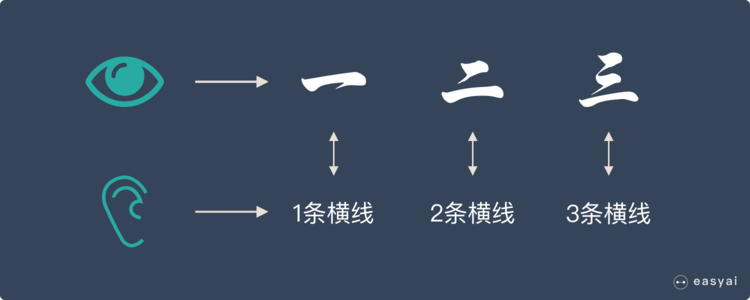
* 不斷重復上面的過程,小朋友的大腦就在不停的學習。
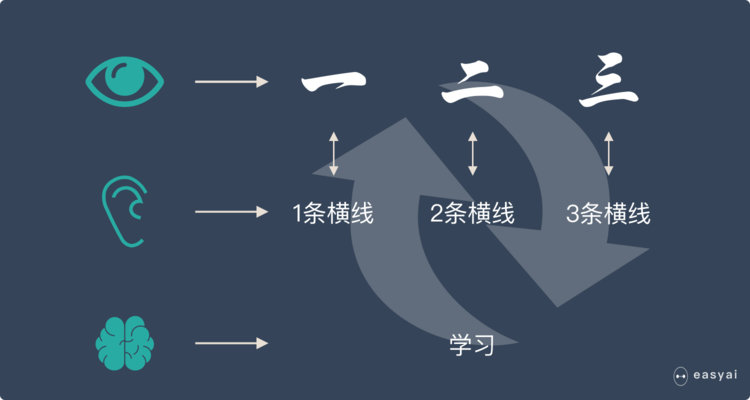
* 當重復的次數足夠多時,小朋友就學會了一個新技能——認識漢字:一、二、三。
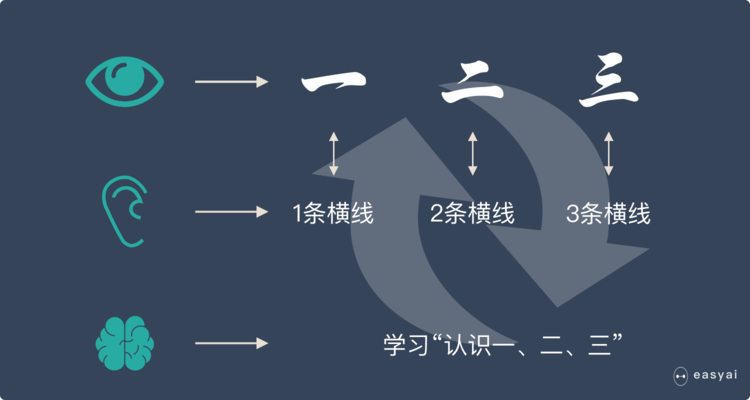
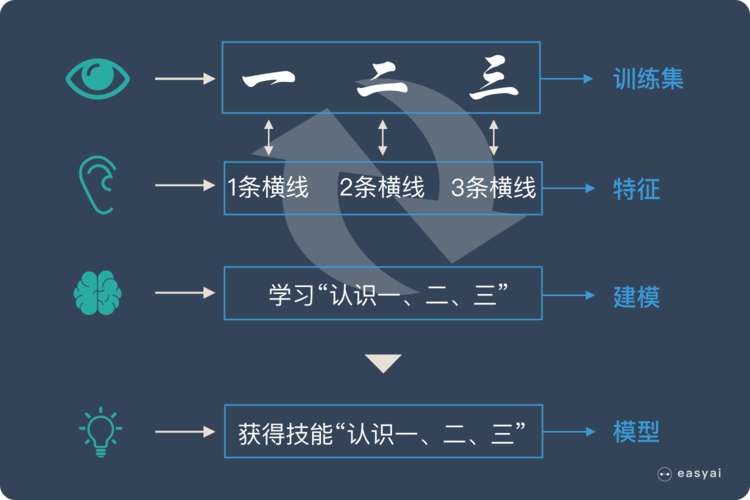
* 我們用上面人類的學習過程來類比機器學習。機器學習跟上面提到的人類學習過程很相似。
* * 上面提到的認字的卡片在機器學習中叫——訓練集
* * 上面提到的“一條橫線,兩條橫線”這種區分不同漢字的屬性叫——特征
* * 小朋友不斷學習的過程叫——建模
* * 學會了識字后總結出來的規律叫——模型
* **通過訓練集,不斷識別特征,不斷建模,最后形成有效的模型,這個過程就叫“機器學習”!**
## **監督學習、非監督學習、強化學習**
* 機器學習根據訓練方法大致可以分為3大類:
*
* 1. 監督學習
* 2. 非監督學習
* 3. 強化學習
*
* 除此之外,大家可能還聽過“半監督學習”之類的說法,但是那些都是基于上面3類的變種,本質沒有改變。
### **監督學習**
* 監督學習是指我們給算法一個數據集,并且給定正確答案。機器通過數據來學習正確答案的計算方法。
*
* 舉個例子:
* 我們準備了一大堆貓和狗的照片,我們想讓機器學會如何識別貓和狗。當我們使用監督學習的時候,我們需要給這些照片打上標簽。
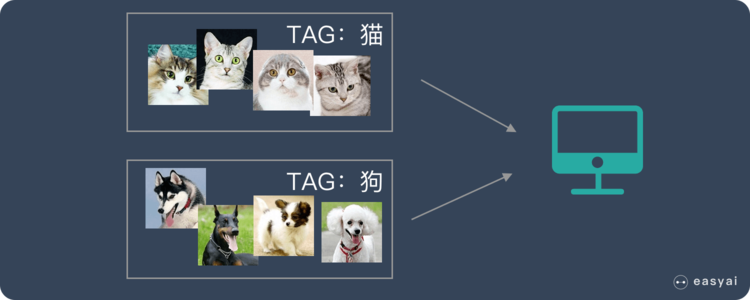
將打好標簽的照片用來訓練
* 我們給照片打的標簽就是“正確答案”,機器通過大量學習,就可以學會在新照片中認出貓和狗。
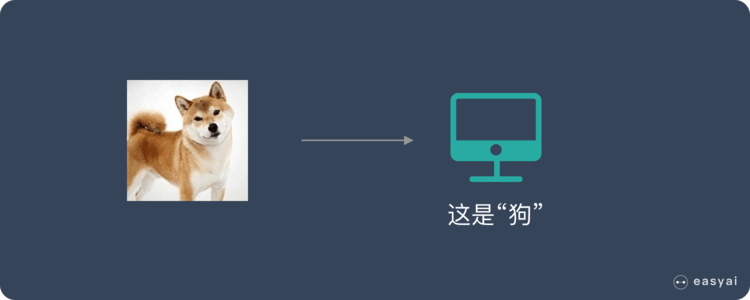
當機器遇到新的小狗照片時就能認出他
* 這種通過大量人工打標簽來幫助機器學習的方式就是監督學習。這種學習方式效果非常好,但是成本也非常高。
### **非監督學習**
*
* 非監督學習中,給定的數據集沒有“正確答案”,所有的數據都是一樣的。無監督學習的任務是從給定的數據集中,挖掘出潛在的結構。
*
* 舉個例子:
*
* 我們把一堆貓和狗的照片給機器,不給這些照片打任何標簽,但是我們希望機器能夠將這些照片分分類。

將不打標簽的照片給機器
* 通過學習,機器會把這些照片分為2類,一類都是貓的照片,一類都是狗的照片。雖然跟上面的監督學習看上去結果差不多,但是有著本質的差別:
*
* **非監督學習中,雖然照片分為了貓和狗,但是機器并不知道哪個是貓,哪個是狗。對于機器來說,相當于分成了 A、B 兩類。**
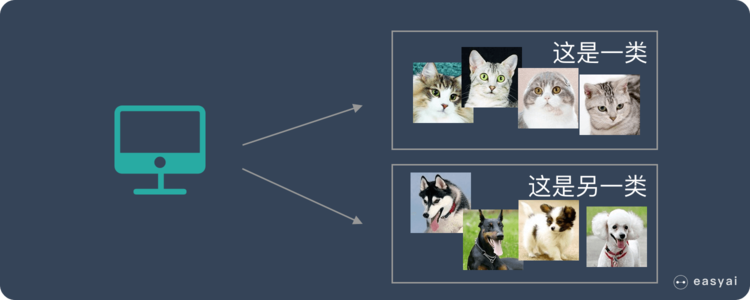
機器可以將貓和狗分開,但是并不知道哪個是貓,哪個是狗
### **強化學習**
* 強化學習更接近生物學習的本質,因此有望獲得更高的智能。它關注的是智能體如何在環境中采取一系列行為,從而獲得最大的累積回報。通過強化學習,一個智能體應該知道在什么狀態下應該采取什么行為。
*
* 最典型的場景就是打游戲。
## **機器學習實操的7個步驟**
* 通過上面的內容,我們對機器學習已經有一些模糊的概念了,這個時候肯定會特別好奇:到底怎么使用機器學習?
*
* 機器學習在實際操作層面一共分為7步:
* 1. 收集數據
* 2. 數據準備
* 3. 選擇一個模型
* 4. 訓練
* 5. 評估
* 6. 參數調整
* 7. 預測(開始使用)
* 假設我們的任務是通過酒精度和顏色來區分紅酒和啤酒,下面詳細介紹一下機器學習中每一個步驟是如何工作的。

案例目標:區分紅酒和啤酒
### **步驟1:收集數據**
* 我們在超市買來一堆不同種類的啤酒和紅酒,然后再買來測量顏色的光譜儀和用于測量酒精度的設備。
*
* 這個時候,我們把買來的所有酒都標記出他的顏色和酒精度,會形成下面這張表格。
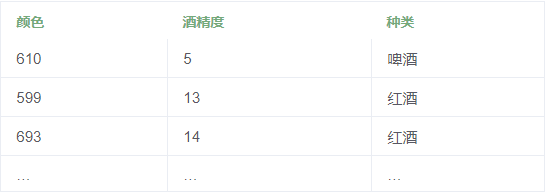
**這一步非常重要,因為數據的數量和質量直接決定了預測模型的好壞。**
### **步驟2:數據準備**
* 在這個例子中,我們的數據是很工整的,但是在實際情況中,我們收集到的數據會有很多問題,所以會涉及到數據清洗等工作。
*
* 當數據本身沒有什么問題后,我們將數據分成3個部分:訓練集(60%)、驗證集(20%)、測試集(20%),用于后面的驗證和評估工作。

數據要分為3個部分:訓練集、驗證集、測試集
### **步驟3:選擇一個模型**
* 研究人員和數據科學家多年來創造了許多模型。有些非常適合圖像數據,有些非常適合于序列(如文本或音樂),有些用于數字數據,有些用于基于文本的數據。
*
* 在我們的例子中,由于我們只有2個特征,顏色和酒精度,我們可以使用一個小的線性模型,這是一個相當簡單的模型。
### **步驟4:訓練**
* 大部分人都認為這個是最重要的部分,其實并非如此~ 數據數量和質量、還有模型的選擇比訓練本身重要更多(訓練知識臺上的3分鐘,更重要的是臺下的10年功)。
*
* 這個過程就不需要人來參與的,機器獨立就可以完成,整個過程就好像是在做算術題。因為機器學習的本質就是**將問題轉化為數學問題,然后解答數學題的過程**。
### **步驟5:評估**
* 一旦訓練完成,就可以評估模型是否有用。這是我們之前預留的驗證集和測試集發揮作用的地方。評估的指標主要有 準確率、召回率、F值。
*
* 這個過程可以讓我們看到模型如何對尚未看到的數是如何做預測的。這意味著代表模型在現實世界中的表現。
### **步驟6:參數調整**
* 完成評估后,您可能希望了解是否可以以任何方式進一步改進訓練。我們可以通過調整參數來做到這一點。當我們進行訓練時,我們隱含地假設了一些參數,我們可以通過認為的調整這些參數讓模型表現的更出色。
### **步驟7:預測**
* 我們上面的6個步驟都是為了這一步來服務的。這也是機器學習的價值。這個時候,當我們買來一瓶新的酒,只要告訴機器他的顏色和酒精度,他就會告訴你,這時啤酒還是紅酒了。
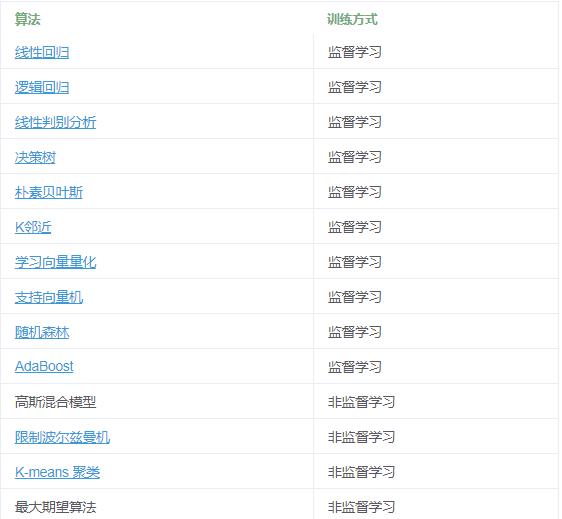
## **15種經典機器學習算法**