[TOC]
## **簡介**
* 說到推薦系統,我們肯定是要問它是為什么而存在的,即存在的意義是什么。
* 隨著當今技術的飛速發展,數據量也與日俱增,人們越來越感覺在海量數據面前束手無策。正是為了解決**信息過載**(Information overload)的問題,人們提出了**推薦系統**(與搜索引擎對應,人們習慣叫推薦系統為推薦引擎)。當我們提到推薦引擎的時候,經常聯想到的技術也便是**搜索引擎**。不必驚訝,因為這兩者都是為了解決信息過載而提出的兩種不同的技術,一個問題,兩個出發點,我更喜歡稱它們兩者為兄弟,親近而形象。
* 兄弟二人有共同的目標,即解決信息過載問題,但具體的做法因人而異。
* **搜索引擎**更傾向于人們有明確的目的,可以將人們對于信息的尋求轉換為精確的關鍵字,然后交給搜索引擎最后返回給用戶一系列列表,用戶可以對這些返回結果進行反饋,并且是對于用戶有主動意識的,但它會有**馬太效應**的問題,即會造成越流行的東西隨著搜索過程的迭代會越流行,使得那些越不流行的東西石沉大海。
* 而**推薦引擎**更傾向于人們沒有明確的目的,或者說他們的目的是模糊的,通俗來講,用戶連自己都不知道他想要什么,這時候正是推薦引擎的用戶之地,推薦系統通過用戶的歷史行為或者用戶的興趣偏好或者用戶的人口統計學特征來送給推薦算法,然后推薦系統運用推薦算法來產生用戶可能感興趣的項目列表,同時用戶對于搜索引擎是被動的。其中**長尾理論**(人們只關注曝光率高的項目,而忽略曝光率低的項目)可以很好的解釋推薦系統的存在,試驗表明位于長尾位置的曝光率低的項目產生的利潤不低于只銷售曝光率高的項目的利潤。推薦系統正好可以給所有項目提供曝光的機會,以此來挖掘長尾項目的潛在利潤。
* 如果說搜索引擎體現著馬太效應的話,那么長尾理論則闡述了推薦系統所發揮的價值。
## **所屬領域**
* 推薦系統是多個領域的交叉研究方向,所以會涉及機器學習以及數據挖掘方面的技巧(推薦系統==》數據挖掘/機器學習==》人工智能)。關于主流研究方向的結構圖。
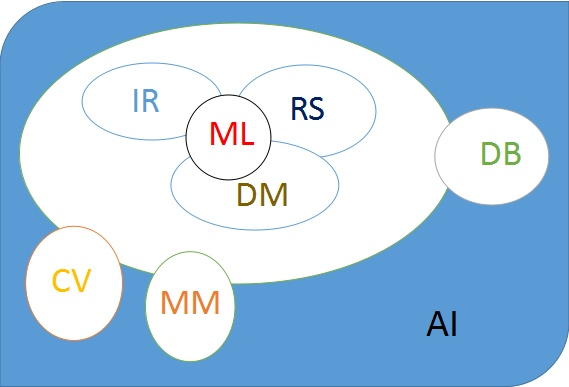
## **會議介紹**
在這里主要整理一下上圖所涉及到的研究方向相關的會議。
**RS**(Recommender System):RecSys
**IR**(Information Retrieval): SIGIR
**DM**(Data Mining): SIGKDD,ICDM, SDM
**ML**(Machine Learning): ICML, NIPS
**CV**(Computer Vision): ICCV, CVPR, ECCV
**MM**(MultiMedia): ACM MM
**DB**(Database): CIKM, WIDM
**AI**(Artificial Intelligence): IJCAI, AAAI
## **推薦系統分類**
* 說到推薦系統的分類,我還是想從簡單的方式開始,對于一些新穎的推薦系統方法,之后再介紹。根據推薦算法所用數據的不同分為基于內容的推薦、協同過濾的推薦以及混合的推薦。在這放一張第一次組會時的ppt:
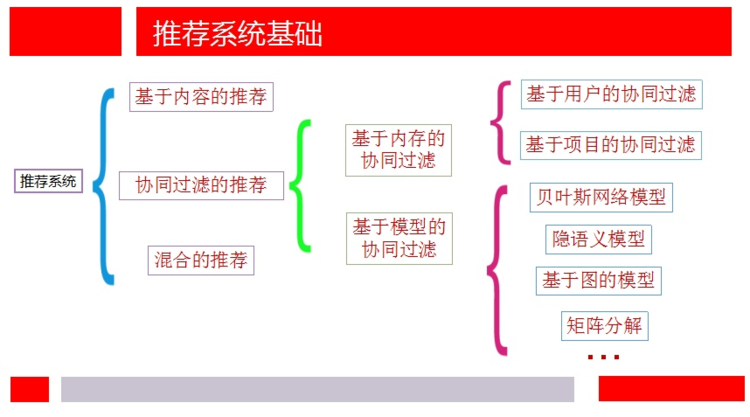
### **1. 基于內容的推薦**
* 顧名思義,它是利用項目的內在品質或者固有屬性來進行推薦,比如音樂的流派、類型,電影的風格、類別等,不需要構建UI矩陣。它是建立在項目的內容信息上作出推薦的,而不需要依據用戶對項目的評價意見,更多地需要用機器學習的方法從關于內容的特征描述的事例中得到用戶的興趣資料。
* 以前一直覺得基于內容的推薦算法最簡單,沒有啥技術含量,直接基于項目的相似度來通過最近鄰獲取與目標項目最相似的項目列表,然后把用戶沒有行為記錄并且評分高的項目推薦給特定用戶。但后來看Andrew NG的機器學習課程中有一節對于推薦系統的介紹,他是通過機器學習的思想來通過訓練來擬合用戶的特征屬性。首先我們需要一個效用函數來評價特定用戶c對于特定項目s的評分:
* :-: 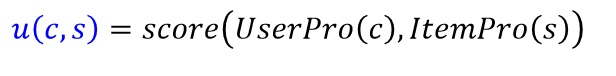
* 至于如何根據項目的內容屬性來學習到跟項目一樣維度的用戶屬性,這就涉及到另一公式:
* :-: 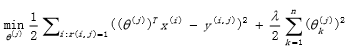
* 他是通過梯度下降法來最小化誤差的平方損失,其中θj為所要學習的用戶維度特征,Xi為項目的內容維度特征,我們所要訓練的是用戶j對于已有行為的項目j的訓練,來使得觀測數據與預測數據的誤差最小。
### **2\. 基于協同過濾的推薦**
* 顧名思義,它是通過集體智慧的力量來進行工作,過濾掉那些用戶不感興趣的項目。協同過濾是基于這樣的假設:為特定用戶找到他真正感興趣的內容的好方法是首先找到與此用戶有相似興趣的其他用戶,然后將他們感興趣的內容推薦給此用戶。
* 它一般采用最近鄰技術,利用用戶的歷史喜好信息計算用戶之間的距離,然后利用目標用戶的最近鄰居用戶對商品評價的加權評價值來預測目標用戶對特定商品的喜好程度,系統從而根據這一喜好程度來對目標用戶進行推薦,通常需要用到UI矩陣的信息。協同過濾推薦又可以根據是否運用機器學習的思想進一步劃分為基于內存的協同過濾推薦(Memory-based CF)和基于模型的協同過濾推薦(Model-based CF)。
#### **2.1 基于內存的協同過濾推薦**
其中基于內存的推薦系統(Memory-based CF)主要是通過啟發式的方法來進行推薦,主要步驟一個是相似性函數的選擇,如何選擇合適的相似性函數來更好的度量兩個項目或者用戶的相似性是關鍵;另一個主要步驟是如何進行推薦,最簡單的推薦方法是基于大多數的推薦策略,即推薦那些大多數人產生過行為而目標用戶未產生過行為的項目。
根據用戶維度和項目維度的不同而分為**Item-based CF**和**User-based CF**。
* Item-based CF:
①首先需要構建UI矩陣;
②根據UI矩陣來計算列(項目維度)的相似度;
③選擇特定項目最相似的k個項目構成推薦列表;
④推薦給特定用戶列表中還沒有發生過行為的項目。
* User-based CF:
①首先需要構建UI矩陣;
②根據UI矩陣來計算行(用戶維度)的相似度;
③選擇特定用戶最相似的k個用戶;
④推薦給特定用戶列表中還沒有發生過行為而在相似用戶列表中產生過行為的高頻項目。
#### **2.2 基于模型的協同過濾推薦**
* 基于模型的推薦系統(Model-based CF)主要是運用機器學習的思想來進行推薦,說到機器學習思想那真是不勝枚舉。記得小鄔老師提過,目前機器學習主要是研究以下幾種方式:
* **① 損失函數+正則項(**Loss Function**);**
* 通過對不同的任務來建立不同的損失函數加正則項來解決問題。比如著名的Lasso Regression、Ridge Regression以及Hinge Regression等。
* **② 神經網絡+層(**Neural Network**);**
* 通過對不同的任務來設計不同的網絡結構來解決問題。比如RNN、CNN以及GAN等。
* **③ 圖模型+圈(**Graph Model**);**
* 通過運用圖的知識來解決不同的實際問題。比如馬爾科夫模型等。
##### **基于矩陣分解的推薦**
* 首先我們需要明確所要解決的問題,即對于一個M行(M個item),N列(N個user)的矩陣,當然這個矩陣是很稀疏的,即用戶對于項目的評分是不充分的,大部分是沒有記錄的,我們的任務是要通過分析已有的數據(觀測數據)來對未知數據進行預測,即這是一個矩陣補全(填充)任務。矩陣填充任務可以通過矩陣分解技術來實現。
**1\. Traditional SVD:**
* 當然人們首先想到的矩陣分解技術是SVD(奇異值)分解,在這我命名為traditional SVD(傳統并經典著),直接上公式:
:-: 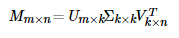
* 當然SVD分解的形式為3個矩陣相乘,中間矩陣為奇異值矩陣。如果想運用SVD分解的話,有一個前提是要求矩陣是稠密的,即矩陣里的元素要非空,否則就不能運用SVD分解。很顯然我們的任務還不能用SVD,所以一般的做法是先用均值或者其他統計學方法來填充矩陣,然后再運用SVD分解降維。
**2\. FunkSVD**
* 剛才提到的Traditional SVD首先需要填充矩陣,然后再進行分解降維,同時存在計算復雜度高的問題,所以后來提出了FunkSVD的方法,實際上是以人家的名字命名的。它不在將矩陣分解為3個矩陣,而是分解為2個**低秩**的用戶項目矩陣,在這里低秩的解釋可以是:在大千世界中,總會存在相似的人或物,即物以類聚,人以群分。在這里,筆者總是混淆稀疏矩陣與低秩矩陣的概念,所以特此說明一下:
* **稀疏矩陣**(sparse matrix):指的是矩陣中的非零元素比較少,但不一定是低秩的。比如對角矩陣,稀疏但是卻滿秩。
* **低秩矩陣**(low-rank matrix):指的是矩陣的秩比較小,但不一定是稀疏的。比如全為1的矩陣,秩雖然小僅為1,但確實稠密矩陣。
* 好像扯得有點遠,不多說了,上公式:
:-: 
* 借鑒線性回歸的思想,通過最小化觀察數據的平方來尋求最優的用戶和項目的隱含向量表示。同時為了避免過度擬合(Overfitting)觀測數據,又提出了帶有L2正則項的FunkSVD,上公式:
:-: 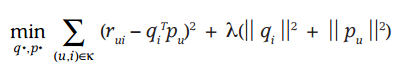
* 以上兩種最優化函數都可以通過梯度下降或者隨機梯度下降法來尋求最優解。
**3\. BiasSVD:**
* 在FunkSVD提出來之后,出現了很多變形版本,其中一個相對成功的方法是BiasSVD,顧名思義,即帶有偏置項的SVD分解,公式:
:-: 
* 它是基于這樣的假設:某些用戶會自帶一些特質,比如天生愿意給別人好評,心慈手軟,比較好說話,有的人就比較苛刻,總是評分不超過3分(5分滿分);同時也有一些這樣的項目,一被生產便決定了它的地位,有的比較受人們歡迎,有的則被人嫌棄,這也正是提出用戶和項目偏置項的原因;項亮給出的解釋是:對于一個評分系統有些固有屬性和用戶物品無關,而用戶也有些屬性和物品無關,物品也有些屬性與用戶無關。
**4\. SVD++:**
* 人們后來又提出了改進的BiasSVD,還是顧名思義,兩個加號,我想是一個加了用戶項目偏置項,另一個是在它的基礎上添加了用戶的隱式反饋信息,還是先上公式:
:-: 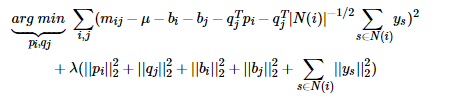
* 它是基于這樣的假設:用戶對于項目的歷史評分記錄或者瀏覽記錄可以從側面反映用戶的偏好,比如用戶對某個項目進行了評分,可以從側面反映他對于這個項目感興趣,同時這樣的行為事實也蘊含一定的信息。其中N(i)為用戶i所產生行為的物品集合;ys為隱藏的對于項目j的個人喜好偏置,是一個我們所要學習的參數;至于|N(i)|的負二分之一次方是一個經驗公式。
**5\. BiasSVDwithU:**
* 又提出了一種帶有用戶平滑項的SVD分解方法,還是先上公式吧:
:-: 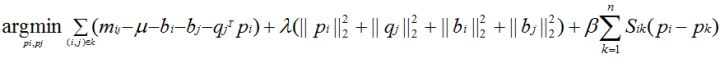
* 它是基于這樣的假設:相似的用戶所學到的用戶隱含特征向量應該更相似,即在現實空間中兩個相似的用戶投影到測度空間上仍然保持相近的距離。
### **3\. 基于混合的推薦**
* 基于混合的推薦,顧名思義,是對以上算法的融合,像淘寶既有基于內容的推薦也有協同過濾的推薦。具體怎么融合還是要結合具體的應用場景,包括是對特征的融合還是對算法層面的融合。其中說到算法的融合,想到了機器學習模型常用的三種模型融合方法:**Bagging、Boosting和Stacking**。
* Bagging(裝袋)方法:該方法通過重采樣技術生成若干個不同的子訓練集,然后在每個訓練集上訓練一個分類器,然后采用投票的方式取大多數的結果為模型的最終結果。模型更像是發揮民主作用的人民代表大會制度,還是大部分人說了算的。
* Boosting(強化提升)方法:每個訓練樣例都有權重,每次訓練新分類器的時候都著重訓練那些再上一次分類過程中分錯的樣例,權重會隨著迭代次數的變化而變化。模型更像是有了記憶能力,加大力度懲罰那些在上一輪不乖的樣例而使得他們越來越聽話。
* Stacking(堆疊)方法:每個分類器首先做一遍決策,然后將分類器們的決策送到更高一層的模型中,把他們當做特征再進行一次訓練。每個單獨分類器的輸出會作為更高層分類器的輸入,更高層分類器可以判斷如何更好的合并這些來自低層的輸出。模型更像是神經網絡中的軸突,低層的輸出作為高層的輸入。
* 【具體思路】 給定一個train數據集和一個test數據集,我們的任務是分類。
①首先需要確定基模型,在這選擇KNN,DecisionTree和SVM三個;
②其次是要把train數據集分成5折的交叉驗證,4份用來訓練,1份用來交叉驗證;
③選擇一個基模型KNN,然后在train數據集上做交叉驗證,每次用4N/5來訓練,N/5來測試,共測試5次,這樣就會得到整個train數據集上的預測;同樣用每次訓練好的模型來預測test,那么可以得到5個對于test的預測,然后取平均作為結果;
⑤重復步驟3、4,這樣會得到對于train的3列新的特征表達(每一列是一個基模型的預測結果),同理也會得到測試集的3列新的特征表達;⑥將新的3列train特征作為第二層模型(在這我們用LR)的輸入,再次進行訓練;
⑦用test上3列新的特征作為輸入,送入訓練好的模型來預測結果。
* 有幾個基模型,就會對整個train數據集生成幾列新的特征表達。同樣,也會對test有幾列新的特征表達。
## **評測指標**
* 評測指標是用來評價一個系統性能好壞的函數,可以分為對于算法復雜度的度量以及算法準確性的度量。算法復雜度主要考慮算法實現的空間以及時間復雜度,當然算法復雜度同樣重要,但這里主要討論算法的準確性度量指標。
* 推薦系統根據推薦任務的不同通常分為兩類:**評分預測**與**Top-N列表推薦**。在這里主要根據這兩者來分別討論評測指標。
* **評分預測任務:**
* 預測特定用戶對于沒有產生過行為的物品能夠打多少分。評分預測一般通過均方根誤差(RMSE)和平均絕對誤差(MAE)來計算。對于測試集中的用戶u和項目i,rui是用戶u對項目i的真實評分,r^ui是推薦算法預測出的評分,那么RMSE:
*
:-: 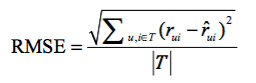
* MAE為:
:-: 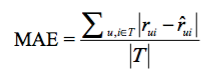
* 其中Netflix認為RMSE加大了對預測不準的用戶物品評分的懲罰(平方項的懲罰),因而對系統的評測更加苛刻,同時如果評分系統是基于整數建立的(即用戶給的評分都是整數),那么對預測結果取整會降低MAE的誤差。
* **Top-N列表推薦:**
* 評分預測只能適用于小部分的場景,比如對于電影,書籍的評分,其實Top-N推薦更加符合現在的需求,給用戶提供一個推薦的列表讓其進行選擇。Top-N推薦一般通過準確率與召回率來進行衡量。其中令R(u)是根據用戶在訓練集上的行為給用戶作出的推薦列表(指的是預測的推薦列表),而T(u)是用戶在測試集上的行為列表(指的是真實的列表GroundTruth),在這筆者總是容易混淆兩者的含義。
* 準確率的意義在于所預測的推薦列表中有多少是用戶真實感興趣的,即預測列表的準確率,那么準確率的定義為:
:-: 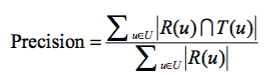
* 召回率的意義在于真正用戶感興趣的列表中有多少是被推薦算法準確預測出來的,即真實列表的召回率,那么召回率的定義為:
:-: 
* 兩個評測指標從不同的方面來衡量推薦系統的好壞,兩者呈現一個負相關的狀態,即準確率高的情況下召回率往往會比較低,反之亦然。所以人們又提出了一個結合了準確率與召回率的評測指標F1值,可以更加方便的觀察推薦系統的好壞,公式如下:
:-: 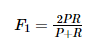
* 當談到準確率、召回率以及F值的時候,它們都是基于**混淆矩陣**(confusion matrix)來說的,見下圖:

* 這張圖是對于二分類任務來說的,真實結果中分為了正例與反例,同理預測結果肯定也會是這兩類正例與反例。所以這也是為什么橫縱坐標都是正例與反例了。至于里邊寫的T和F是針對于預測結果而言的,即預測正確了是T,預測錯誤為F,所以TP的含義為預測正確的正例。所以
* 準確率可以表示為TP/(TP+FP);
* 召回率表示為TP/(TP+FN);
* 精度(Accuracy)也可以用混淆矩陣表示(TP+TN)/(TP+FN+FP+TN)。
* 對于一般的問題,用精度(Accuracy)這個指標是可以的,預測正確的樣例個數比上總的樣例個數。但對于有偏斜(**skewed class data**,又稱unbalanced data)的數據的時候,就不那么奏效了。比如對于二分類問題,訓練集數據99%為負例,僅1%為正例。那么我用一個簡單的規則來進行預測:即無論數據的特征是什么,我都預測為負例,那么我這個帶有規則的算法的精度可以高達99%,實際上對于再厲害的機器學習算法也很難達到這樣的標準,很顯然這樣的指標在不平衡的數據上是不客觀的。那么召回率就可以比較好的進行評價了,預測為正例的個數比上實際的測試集上正例的個數,很顯然對于剛才那么一直預測為負例的規則算法,它的召回率是0。
