#### 第19章:
#### Redis設計與實現
#### 19.1 事件
Redis服務器是一個事件驅動程序。分為兩類事件:
- 文件事件:Redis服務器與客戶端(或其他服務器)的通信產生文件事件,Redis服務器監聽并處理這些事件。
- 時間事件:Redis服務器需要在給定的時間完成一些特定操作。
#### 文件事件
Redis實現了自己的文件事件處理器:
- 文件處理器使用I/O多路復用監聽多個套接字,并根據套接字目前執行的任務的為套接字關聯不同的事件處理器。
- 當被監聽的套接字準備執行應答、讀取、寫入、關閉等操作時,與之對應的文件事件就會產生,這時文件處理器就會調用套接字之前關聯好的事件處理器來處理這些事件。
文件處理器以單線程方式運行,但通過I/O多路復用來監聽多個套接字。所以文件處理器既實現了高性能的網絡通信模型,又可以很好地與Redis服務器中其他同樣以單線程運行的模塊進行對接,這樣保持了Redis內部單線程設計的簡單性。
##### 文件事件處理器的構成
可以分配套接字、I/O多路復用程序、文件事件分派器、文件事件處理器。
文件事件是對套接字操作的抽象,當套接字準備執行應答、寫入、讀取、關閉就會產生一個文件事件。一個服務器可能會連接多個套接字,所以多個文件事件可能會并發出現。
首先,I/O多路復用程序負責監聽多個套接字的,并把產生事件的套接字放入隊列有序地向文件事件分派器傳送套接字。
然后,文件事件分派器根據套接字產生的事件調用相應的文件事件處理器。且每次只處理一個事件,處理之后I/O多路復用程序會將隊列里的套接字取一個傳送給文件事件分派器,再由文件事件分派調用響應的文件事件處理器處理,以此往復。
:-: 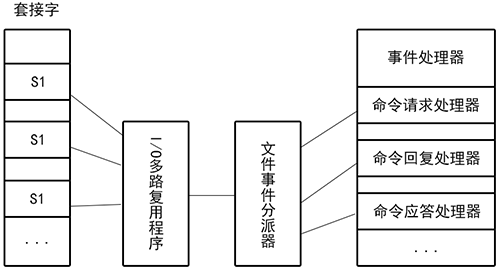
? 文件事件處理器組成
##### I/O多路復用程序的事件
Redis的I/O多路復用程序的功能是通過包裝select、epoll、evport和kqueue等函數庫實現的。
##### 事件類型
- 當套接字變得可讀或者有新的可應答套接字出現時,套接字產生AE_READABLE事件。
- 當套接字變得可寫時,套接字產生AE_WRITABLE事件。
文件事件器對于一個同時出現兩種事件的套接字會優先處理AE_READABLE事件。也就是會先讀再寫。
##### API
Redis實現了一套API接收事件描述符、事件類型、事件處理器,將給定套接字給定事件加入到I/O多路復用程序
的監聽范圍內,并將給定事件和事件處理器進行關聯以及取消監聽、取消關聯等操作。
##### 文件事件的處理器
Redis為文件事件設計了多個處理器,分別用于實現不同的網絡通信需求:
- 連接應答處理器:為了對連接服務器的各個客戶端進行應答。
- 命令請求處理器:為了接收客戶端傳來的命令請求。
- 命令回復處理器:為了向客戶端返回執行結果。
- 復制處理器:為了主服務器和從服務器進行復制操作。
例子:
1. 客戶端向服務器發送連接請求,服務端執行連接應答處理器。
2. 客戶端向服務器發送命令請求,服務端執行命令請求處理器。
3. 服務器向客戶端發送命令回復,服務器執行命令回復處理器。
##### 時間事件
Redis的時間事件分為:
- 定時事件:讓程序再指定事件之后執行一次。
- 周期性事件:讓一段程序每隔指定時間就執行一次。
Redis服務器將所有時間事件放在一個無序鏈表中,時間事件處理器執行時會遍歷鏈表查找已到達的時間事件調用相應事件處理器。
#### 19.2 客戶端
Redis的所有命令都是由客戶端執行,甚至沒有的連接的客戶端的情況會啟動偽客戶端。
Redis通過使用I/O多路復用技術實現文件事件處理器,使得Redis服務器使用單線程單進程的方式來處理命令請求,與多個客戶端進行網絡通信。
而每個與服務器進行連接的客戶端,服務器都為這些客戶端建立了相應的redis.h/redisClient結構,用于保存客戶端當前的狀態。并且新連接的客戶端添加到Clients客戶端鏈表中。
##### 客戶端屬性
客戶端狀態包含的屬性分為兩類:
- 通用屬性:各種通用信息。
- 特定功能屬性:用于特定操作。
##### 套接字描述符
客戶端狀態的fd屬性用于記錄客戶端正在使用的套接字描述符。
##### 名字
默認情況下一個連接到服務器的客戶端沒有名字。
name屬性用于記錄連接到服務器的客戶端的名字。
##### 標志
flags屬性記錄了客戶端的角色,以及客戶端目前的狀態。例子:
REDIS_MASTER:表示客戶端是一個主服務器。
REDIS_BLOCKED:表示客戶端正在被命令阻塞。
REDIS)MULTI:表示客戶端正在執行事務,單事務的安全性已被破壞。
....
##### 輸入緩沖區
客戶端的輸入緩沖區用于保存客戶端發送的命令請求。緩沖區的作用一般用以應對高并發的處理情況。
##### 命令與參數
客戶端的命令會保存在客戶端狀態的querybuf屬性后。
客戶端的命令參數以及命令參數的會保存在argv屬性和argc屬性。
```
typedef struct redisClient{
//...
robj **argv;
int argc;
//...
}
```
##### 客戶端的創建和關閉
Redis服務器使用不同的方式創建和關閉不同類型的客戶端。
##### 關閉普通客戶端
關閉普通客戶端的原因:
- 客戶端進程退出或者被殺死。
- 客戶端發送不符合協議格式的命令請求。
- 客戶端稱為CLIENT KILL 命令的目標。
- 客戶端有timeout選項并且操作其設置的值。
- 客戶端發送的命令請求大小超過了輸入緩沖區大小。
- 服務器發送的命令回復的大小超過了輸出緩沖區大小。
服務器采用兩種模式限制客戶端輸出緩沖區的大小:
1. 硬性限制:如果輸出緩沖區數據大小超過硬性限制大小立即關閉客戶端。
2. 軟性限制:如果輸出緩沖區數據大小超過軟性限制大小但沒超過硬性限制,客戶端狀態中obuf_soft_limit_reached_time屬性會記錄到達軟性限制的時間;之后Redis服務器會監視客戶端,如果一直超過軟性限制且超過服務器設置的定時時長會關閉客戶端。
##### Lua腳本的偽客戶端
所有的Redis命令都要由客戶端執行,所以執行Lua腳本時會建立偽客戶端執行Lua腳本。
##### AOF的偽客戶端
服務器載入AOF文件時會執行AOF文件包含的Redis命令,會創建Redis偽客戶端。
#### 19.3 服務器
Redis服務器負責與客戶端建立連接,處理命令請求,保存數據等。
##### 命令請求的執行過程
1. 客戶端向服務器發送命令請求。
2. 服務器接收并處理客戶端發來的命令請求,在數據庫中進行設置操作,并產生命令回復ok。
3. 服務器將命令回復ok發送給客戶端。
4. 客戶端接收服務器返回的命令回復ok,并標準輸出給客戶。
##### 發送命令請求的過程
1. 用戶鍵入命令請求給Redis客戶端。
2. Redis客戶端將命令轉換成協議格式然后發送給已通過建立套接字連接的Redis服務器。
##### 讀取命令請求的過程
客戶端與服務器之間的套接字因為客戶端寫入變得可讀,服務器調用命令請求處理器:
1. 讀取經過連接傳送過來協議里的請求數據,保存到客戶端狀態里的輸入緩沖。
2. 對請求進行分析。
3. 調用命令執行器執行命令。
#### 19.4 簡單動態字符串
Redis構建名為`簡單動態字符串(SDS)`的抽象數據類型保存Redis的字符串數據類型數據。SDS的定義,sds.h/sdshdr結構:
```
struct sdshdr{
//記錄buf數組中已經使用字節的數量
//記錄SDS所保存字符串的長度
int len;
//記錄buf數組中未使用字節的數量
int free;
//字節數組,保存字符串
char buf[];
}
```
解釋:
- len保存了這個字符串的長度(除開最后的"\0"空格)。由于保存了len,獲取字符串時知道它的長度,使得獲得字符串的復雜度僅為O(1),保持了高性能。
- buf數組保存了具體的字符串值比如`'R','e','d','i','s','\0'`。
- free保存了為這個字符串分配的空間還有多少空余量。
在Redis里所有字符串值的鍵值對都是由SDS實現。
```
redis>SET str1 "你好";
OK
```
##### 使用SDS的好處
1. 杜絕了緩沖區溢出:
當需要拼接字符串時,由于前一個字符串已經分配了固定的內存空間,而之后需要拼接的字符串所需空間大于剩余可用空間時會出現緩沖區溢出問題導致數據錯誤。使用SDS時會先檢測空間是否足夠修改所用,如果不夠的情況會將此SDS的空間擴大值執行修改所需的大小,再執行修改操作。
2. 減少了修改字符串時的內存重新分配操作
SDS的空間分配有多種策略,幫助SDS字符串進行修改時選擇是否擴大空間或者使用前面已經分配且足夠這次修改的free空閑空間。這樣減少了內存重新分配操作的資源使用。其中策略有:
- 空間預分配:修改一個SDS字符串時,程序不僅會為SDS分配所需要的空間,還會分配額外未使用空間供此SDS下次使用。
- 惰性空間釋放:用于優化SDS字符串的縮短操作,比如SDS減少其字符時并不會釋放其free未使用空間以便下次操作。當然,SDS提供了像一個的API讓我們在需要的時候釋放SDS未使用的空間。
3. 二進制安全:為了確保Redis適用于各種場景,SDS API都會以二進制的方式處理SDS存放在buf數組里的數據,寫入是什么樣讀取就是什么樣。所以SDS的buf字節數組可以保存任何數據不單是文本。
#### 19.5 列表(隊列)的實現
Redis的列表鍵數據是使用`鏈表`實現的。當列表鍵包含較多數量的元素或包含的元素都是比較長的字符串時,Redis就會用鏈表作為鏈表鍵的底層實現。鏈表的具體實現可以看數據結構章節。
#### 19.6 Redis數據庫和哈希鍵的實現
Redis的數據庫使用字典作為底層實現。對數據庫的增刪改查都是構建在對字典的操作之上。
比如:
```
redis>SET msg 'hello';
OK
```
在數據庫中創建一個鍵"msg",值為"hello"。這個鍵值對被保存到了數據庫的字典里面。
再比如哈希鍵,其底層實現也是字典:
```
redis>HLEN colors;
(integer) 10000
redis>HGETALL colors;
1)"red"
2)"1"
3)"blue"
4)"2"
5)"yellow"
6)"3"
...
```
color是一個包含了10000個鍵值對的哈希鍵,底層實現是字典。
##### 哈希鍵的實現
對于每個鍵值對的鍵和值是小整數值或者長度較短的字符串,且鍵值對數量較少的情況下,哈希鍵的底層實現是`壓縮列表`。
對于鍵值對數量較大,鍵和值比較復雜的情況下,哈希鍵的底層實現是`哈希表`。
且兩種底層數據實現會隨著鍵值對的變化由Redis服務器進行變化。
##### 字典的實現
字典使用哈希表(HashTable)作為底層實現,哈希表利用哈希函數和鏈表法使每一個保存鍵值對的哈希節點避開了哈希沖突形成了一個鏈表。
```
typedef strcut dictht{
//哈希數組 用于存放多個哈希節點槽,哈希節點槽用于指向存放了鍵值對的哈希節點鏈表
dictEntry **table;
//哈希表大小
unsigned long size;
//哈希大小掩碼,用于計算索引值,哈希算法時計算將哈希節點放于哪個哈希節點槽指向的哈希節點鏈表
unsigned long used;
}dictht
```
:-: 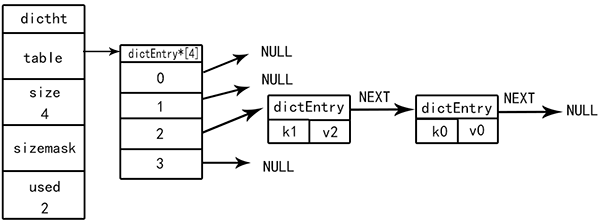
? 字典的哈希表
##### 哈希算法
將鍵值對添加到字典時需要根據鍵值對計算哈希值和索引值,再根據索引值將包含鍵值對的哈希節點放到哈希表數組指定的索引上。所以經過哈希算法鍵值對計算出來了應該保存在哪個哈希節點槽結構指向的鏈表里。例如這個dictEntry有4個槽(索引0-3),程序會計算鍵值對添加到0-3槽(索引)指向的某個鏈表中。
##### 解決哈希沖突
當有兩個以上的鍵值對被分配到相同的槽(索引)指向的鏈表里時就發生了沖突。Redis使用了鏈地址法使多個保存鍵值的哈希節點形成鏈表,而且每次將新添加的鍵值對放到鏈表的頭部以提高插入速度。如上圖(字典的哈希表),首先哈希算法將k0v0鍵值對計算到了2號槽(索引),添加進去到,然后計算了k1v1鍵值對又到2號槽(索引),然后添加到哈希節點鏈表頭部,也就是k0v0之前。
注意:Redis的哈希節點鏈表是指向后邊的單向鏈表。
##### rehash
隨著操作的不斷執行哈希表數據增多或減少。Redis會對哈希表的大小進行擴展或收縮使哈希表的負載因子維持在合理范圍,稱為rehash操作。過程大概是:
1. 分配一個新的字典空間。
2. 重新計算原字典鍵的哈希值和索引值并將所有鍵值對轉移到新的字典里。
3. 釋放原來的字典空間,將新的字典變為舊的字典空間以便下次rehash。
漸進式的rehash:
轉移過程緩慢發生直到舊空間的鍵值對數量只減不增最終為空表。
#### 19.7 有序集合實現
有序集合的底層實現是`跳躍表`。跳躍表在每個節點中維持多個指向其他節點的指針,從而達到快速訪問節點的目的。
:-: 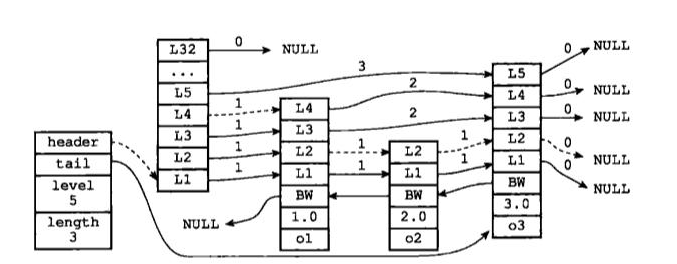
redis.h/zskiplist結構:
- header:指向跳躍表表頭節點。
- tail:指向跳躍表尾部節點。
- level:記錄跳躍表層數最大節點的層數。
- length:記錄跳躍表長度。
redis.h/zskiplistNode節點結構:
- 層:使用L1、L2等字樣表示節點各層,層中保存兩個信息:前進指針指向之后的某個節點;記錄本節點到前進指針指向節點的跨度。
- 后退指針:指向上一個節點。
- 分值:記錄節點的分值。跳躍表中節點順序按照分支大小排。
- 成員對象:節點中的o1、o2、o3等是成員對象。
##### redis.h/zskiplistNode節點結構
```
typedef struct zskiplistNode{
//后退指針
struct zskiplistNode *backward;
//分值
double score;
//成員對象
robj *obj;
//層
struct zsiplistLevel{
//前進指針
struct zskiplistNode *forward;
//跨度
unsigned int span;
}level[];
}zskiplistNode;
```
- 層:層數組中可以有多個元素,每個元素中包含一個指向其他節點的指針,用于提高訪問其他節點的速度。一般層數越多訪問其他節點速度越快。層數按照冪次定律隨機生成,可以稱作節點的"高度"。
- 前進指針:每層都有向表尾方向指向下個節點的指針。如果需要遍歷跳躍表的節點則通過每一個節點指向下一個節點的層遍歷。
- 跨度:記錄兩個節點之間的距離。
- 后退指針:用于表尾向表頭方向訪問節點,且一次只能后退一個節點。
- 分值:double浮點數,記錄節點的排序。
- 成員:記錄一個SDS值。
#### 19.8 集合實現
redis的整數集合的底層實現是`整數集合`。當一個集合只包含整數值元素,并且數量不多時會使用整數集合。整數集合可以保存數據類型為int16_t,int32_t,int64_t的整數值,并且保證集合中不會出現重復值。
intest.h/intest整數集合結構:
```
typedef struct intest{
//編碼方式
uint32_t encoding;
//集合包含的元素數量
uint32_t length;
//保存元素的數組
int8_t contents[];
}
```
:-: 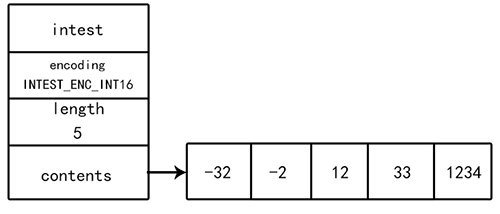
? 整數集合
整數結合的特點:
- contents中的整數結合按照從小到大的順序排序。
- 升級:如果新添加的集合元素比現在所有的元素長度要長時會進行升級。比如原本集合保存的都是unit8_t長度的整型,新添加一個uint32_t長度的整型,會將原本的其他所有元素升級成uint32_t類型,再將新元素添加進去。升級的好處是:提升整數集合的靈活性;節約內存。
#### 19.9 列表鍵和哈希鍵的實現
前面講了哈希鍵有兩種實現:壓縮列表和哈希表。列表鍵的底層實之一也是`壓縮列表`。壓縮列表是Redis為了節約內存而開發的,是`由一系列特殊編碼的連續內存塊組成的順序型`數據結構。
壓縮列表 可以包含任意多各節點,每個節點可以保存一個字節數組或者一個整數值。
:-: 
? 壓縮列表
:-: 
? 壓縮列表節點說明
##### 壓縮列表節點組成
:-: 
? 壓縮列表節點
- previous_entry_length:記錄前一個節點的長度。
- 如果前一個節點長度小于254字節,previous_entry_length屬性需要用1字節空間保存這個長度值。
- 如果前一個節點長度大于254字節,previous_entry_length屬性需要用5字節空間保存這個長度值。
- encoding:記錄content屬性保存數據的類型和長度。
- content:保存這個節點的具體數據,可以是字節數組和整數值。
##### 連鎖更新
壓縮列表中節點的previous_entry_length屬性可以記錄前一個節點的長度。如果在某一個節點前添加了一個長度大于254字節的新節點。導致后面所有的節點都無法保存上一個節點的具體長度。此時,就會發生連鎖更新,使每一個節點的previous_entry_length屬性使用5字節的空間。這樣能保證壓縮列表數據的正確性,除非有多個連續的節點長度介于250-253之間且進行連鎖更新,否則對性能影響其實不大。
#### 19.10 對象
Redis并沒有直接使用簡單動態字符串(SDS)、雙端鏈表、字典、壓縮列表、整數集合等數據結構實現鍵值對數據,而是基于這些數據結構創建了一個對象系統,包括字符串對象、列表對象、哈希對象、集合對象、有序集合對象。
對象的部分功能特點:
- 在執行命令前可以根據對象類型判斷對象是否可以執行給定的命令。
- 可以針對不同的使用場景為對象設置多種不同的數據結構實現,從而優化對象在不同場景下的使用效率。
- 實現了引用計數技術的內存回收和對象共享機制。
- 對象帶有訪問時間記錄信息,有利于服務器回收對象。
##### 對象的類型
每次在Redis數據庫創建一個鍵值對時會創建兩個對象:鍵對象、值對象。每個對象都由redisObject結構表示:
```
typedef struct redisObject{
//類型
unsigned type:4;
//編碼
unsigned encoding:4;
//指向底層實現數據結構的指針
void *ptr;
...
}
```
對于Redis來說:
- 鍵對象:總是字符串對象。
- 值對象:可以是字符串對象、列表對象、哈希對象、集合對象、有序集合對象。
| 類型常量 | 對象名稱 |
| ------------ | ------------ |
| REDIS_STRING | 字符串對象 |
| REDIS_LIST | 列表對象 |
| REDIS_HASH | 哈希對象 |
| REDIS_SET | 集合對象 |
| REDIS_ZSET | 有序集合對象 |
##### 編碼和底層實現
對象的prt指針指向對象的底層實現數據結構,這些數據結構由encoding屬性決定。encoding記錄了對象所使用的編碼:
| 編碼常量 | 對應的數據結構 |
| ------------------------- | -------------------------- |
| REDIS_ENCODING_INT | long型整數 |
| REDIS_ENCODING_EMBSTR | ebsstr編碼的簡單動態字符串 |
| REDIS_ENCODING_RAW | 簡單動態字符串 |
| REDIS_ENCODING_HT | 字典 |
| REDIS_ENCODING_LINKEDLIST | 雙端鏈表 |
| REDIS_ENCODING_ZIPLIST | 壓縮列表 |
| REDIS_ENCODING_INTSET | 整數集合 |
| REDIS_ENCODING_SKIPLIST | 跳躍表和字典 |
每種類型的對象都至少使用了兩種不同的編碼:
| 類型 | 編碼 | 對象 |
| ------------ | ------------------------- | ---------------------------------------------- |
| REDIS_STRING | REDIS_ENCODING_INT | 使用整數值實現的字符串對象 |
| REDIS_STRING | REDIS_ENCODING_EMBSTR | 使用embstr編碼的簡單動態字符串實現的字符串對象 |
| REDIS_STRING | REDIS_ENCODING_RAW | 使用簡單動態字符串實現的字符串對象 |
| REDIS_LIST | REDIS_ENCODING_ZIPLIST | 使用壓縮列表實現的列表對象 |
| REDIS_LIST | REDIS_ENCODING_LINKEDLIST | 使用雙端鏈表實現的列表對象 |
| REDIS_HASH | REDIS_ENCODING_ZIPLIST | 使用壓縮列表實現的哈希對象 |
| REDIS_HASH | REDIS_ENCODING_HT | 使用字典實現的哈希對象 |
| REDIS_SET | REDIS_ENCODING_INTSET | 使用整數集合實現的集合對象 |
| REDIS_SET | REDIS_ENCODING_HT | 使用字典實現的集合對象 |
| REDIS_ZSET | REDIS_ENCODING_ZIPLIST | 使用壓縮列表實現的有序集合對象 |
| REDIS_ZSET | REDIS_ENCODING_SKIPLIST | 使用跳躍表實現的有序集合對象 |
#### 19.11 Redis 其他
對Redis的RDB持久化、AOF持久化、主從復制、哨兵、集群等底層設計實現有興趣的同學可以自行學習。