#### 第20章:
#### MongoDB
#### 20.1 MongoDB 基礎
MongoDB是由C++編寫的高性能、高可用性且易擴展的內存數據庫。其特點:
- 數據存儲格式BSON({"name":"tom"})。
- 面向集合存儲,易于存儲對象類型和JSON形式的數據。
- 模式自由:一個集合可以存儲一個鍵值對文檔,也可以存儲多個鍵值對文檔。例如:
```
{
"name":"tom"
}
{
"name":tom,
"classNum":3
}
```
以上是兩個文檔,每個文檔可以有一個或者多個鍵值對
- 支持動態查詢:豐富的查詢表達式。
- 完整的索引支持:文檔內嵌對象和數據都可以創建索引。
- 支持復制和故障恢復:支持主從復制和節點之間的故障恢復。
- 二進制數據存儲:MongoDB使用二進制數據存儲方式。
- 自動分片:用于支持負載均衡、讀寫分離。
- 支持多種語言:有多種語言的API。
- MongoDB使用內存映射存儲引擎:是一個高效的內存數據庫。
- mongodb不支持事務。
##### MongoDB和傳統關系型數據庫的差別
- MongoDB`不支持事務`。
- 以JSON類型的方式進行數據查詢。
- 文檔數據的鍵值對不固定。例如在MySQL創建表時會先設計每行數據需要的數據列,像名字、年齡、班級等,之后就固定了只能在這些設計了的列范圍內操作數據。而MongoDB可以添加只要名字的文檔,也可以添加要名字、年齡、班級、體重、身高等不限制條件數量的文檔。
- MongoDB會占用一切能占用的內存用于符合它自己邏輯的操作。所以盡量不要把MongoDB和其他服務放在一起。
##### MongoDB的存儲結構
MongoDB的存儲結構層次是:數據庫包含集合,集合包含文檔,文檔就是一個或者多個鍵值對的一條數據。
##### 數據庫
一個MongoDB服務器實例可承載多個數據庫,數據庫之間完全獨立,擁有獨立的控制權限,并且在磁盤上不同的數據庫放置在不同的文件中。數據庫由分為自定義數據庫和自帶數據庫:自定義數據庫是開發者用來存儲業務數據的,自帶數據庫是MongoDB服務自身運行所需數據庫。
##### 集合
集合就是一組文檔,且是無模式的。無模式指文檔可以是五花八門沒有條件限制的,比如鍵值對數量,鍵的名稱、值的名稱都可以隨意組成。集合里的值還可以是集合,稱為`子集合` 。
集合又分為`普通集合`和`固定集合Capped` 。
固定集合是固定大小的性能出色的集合。如果文檔超過了其固定空間,則會刪除最早的文檔為新文檔騰出空間。
當第一個文檔插入時,集合就會被創建。
合法的集合名:
- 集合名不能是空字符串""。
- 集合名不能含有\0字符(空字符),這個字符表示集合名的結尾。
- 集合名不能以"system."開頭,這是為系統集合保留的前綴。
- 用戶創建的集合名字不能含有保留字符。有些驅動程序的確支持在集合名里面包含,這是因為某些系統生成的集合中包含該字符。除非你要訪問這種系統創建的集合,否則千萬不要在名字里出現$。
##### 文檔
文檔是MongoDB數據的基本單元,可以看作是一條數據。
需要注意的是:
1. 文檔中的鍵/值對是有序的。
2. 文檔中的值不僅可以是在雙引號里面的字符串,還可以是其他幾種數據類型(甚至可以是整個嵌入的文檔)。
3. MongoDB區分類型和大小寫。
4. MongoDB的文檔不能有重復的鍵。
5. 文檔的鍵是字符串。除了少數例外情況,鍵可以使用任意UTF-8字符。
6. 每個文檔都有一個特殊的鍵"_id",在所在文檔中是唯一的。
7. 鍵、值區分大小寫。
文檔鍵命名規范:
- 鍵不能含有\0 (空字符)。這個字符用來表示鍵的結尾。
- .和$有特別的意義,只有在特定環境下才能使用。
- 以下劃線"_"開頭的鍵是保留的(不是嚴格要求的)。
##### 元數據
數據庫的信息是存儲在集合中。它們使用了系統的命名空間:
```
dbname.system.*
```
在MongoDB數據庫中名字空間 <dbname>.system.* 是包含多種系統信息的特殊集合(Collection),如下:
| 集合命名空間 | 描述 |
| ------------------------ | ----------------------------------------- |
| dbname.system.namespaces | 列出所有名字空間。 |
| dbname.system.indexes | 列出所有索引。 |
| dbname.system.profile | 包含數據庫概要(profile)信息。 |
| dbname.system.users | 列出所有可訪問數據庫的用戶。 |
| dbname.local.sources | 包含復制對端(slave)的服務器信息和狀態。 |
對于修改系統集合中的對象有如下限制。
在{{system.indexes}}插入數據,可以創建索引。但除此之外該表信息是不可變的(特殊的drop index命令將自動更新相關信息)。
{{system.users}}是可修改的。 {{system.profile}}是可刪除的。
##### MongoDB 數據類型
下表為MongoDB中常用的幾種數據類型。
| 數據類型 | 描述 |
| ------------------ | ------------------------------------------------------------ |
| String | 字符串。存儲數據常用的數據類型。在 MongoDB 中,UTF-8 編碼的字符串才是合法的。 |
| Integer | 整型數值。用于存儲數值。根據你所采用的服務器,可分為 32 位或 64 位。 |
| Boolean | 布爾值。用于存儲布爾值(真/假)。 |
| Double | 雙精度浮點值。用于存儲浮點值。 |
| Min/Max keys | 將一個值與 BSON(二進制的 JSON)元素的最低值和最高值相對比。 |
| Array | 用于將數組或列表或多個值存儲為一個鍵。 |
| Timestamp | 時間戳。記錄文檔修改或添加的具體時間。 |
| Object | 用于內嵌文檔。 |
| Null | 用于創建空值。 |
| Symbol | 符號。該數據類型基本上等同于字符串類型,但不同的是,它一般用于采用特殊符號類型的語言。 |
| Date | 日期時間。用 UNIX 時間格式來存儲當前日期或時間。你可以指定自己的日期時間:創建 Date 對象,傳入年月日信息。 |
| Object ID | 對象 ID。用于創建文檔的 ID。 |
| Binary Data | 二進制數據。用于存儲二進制數據。 |
| Code | 代碼類型。用于在文檔中存儲 JavaScript 代碼。 |
| Regular expression | 正則表達式類型。用于存儲正則表達式。 |
##### ObjectId
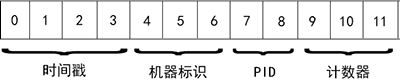
ObjectId 類似唯一主鍵,可以很快的去生成和排序,包含 12 bytes(字節,不是比特位),含義是:
- 前 4 個字節表示創建 **unix** 時間戳,格林尼治時間 **UTC** 時間,比北京時間晚了 8 個小時
- 接下來的 3 個字節是機器標識碼
- 緊接的兩個字節由進程 id 組成 PID
- 最后三個字節是隨機數
:-: 
MongoDB 中存儲的文檔必須有一個 _id 鍵。這個鍵的值可以是任何類型的,默認是個 ObjectId 對象
由于 ObjectId 中保存了創建的時間戳,所以你不需要為你的文檔保存時間戳字段,你可以通過 getTimestamp 函數來獲取文檔的創建時間:
```
> var newObject = ObjectId()
> newObject.getTimestamp()
ISODate("2017-11-25T07:21:10Z")
```
ObjectId 轉為字符串
```
> newObject.str
5a1919e63df83ce79df8b38f
```
##### 字符串
BSON 字符串都是 UTF-8 編碼。
##### 時間戳
BSON 有一個特殊的時間戳類型用于 MongoDB 內部使用,與普通的日期類型不相關。 時間戳值是一個64位的值。其中:
- 前32位是一個 time_t 值(與Unix新紀元相差的秒數)
- 后32位是在某秒中操作的一個遞增的`序數`
在單個mongod實例中,時間戳值通常是唯一的。
在復制集中,oplog 有一個 ts 字段。這個字段中的值使用BSON時間戳表示了操作時間。
`BSON 時間戳類型主要用于 MongoDB 內部使用。在大多數情況下的應用開發中,你可以使用 BSON 日期類型。`。
##### 日期
表示當前距離 Unix新紀元(1970年1月1日)的毫秒數。日期類型是有符號的, 負數表示1970年之前的日期。
```
> var mydate1 = new Date() //格林尼治時間
> mydate1
ISODate("2018-03-04T14:58:51.233Z")
> typeof mydate1
object
> var mydate2 = ISODate() //格林尼治時間
> mydate2
ISODate("2018-03-04T15:00:45.479Z")
> typeof mydate2
object
```
這樣創建的時間是日期類型,可以使用 JS 中的 Date 類型的方法。
返回一個時間類型的字符串:
```
> var mydate1str = mydate1.toString()
> mydate1str
Sun Mar 04 2018 14:58:51 GMT+0000 (UTC)
> typeof mydate1str
string
```
或者
```
> Date()
Sun Mar 04 2018 15:02:59 GMT+0000 (UTC)
```
#### 20.2 MongoDB的日志
- 系統日志:系統日志在MongoDB數據庫中很重要,它記錄著MongoDB啟動和停止的操作,以及服務器在運行過程中發生的任何異常信息。
- Journal日志:用于數據恢復,記錄了所有的寫操作。
- oplog日志(主從日志):Replica Sets復制集用于在多臺服務器之間備份數據。MongoDB的復制功能是使用操作日志oplog實現的,操作日志包含了主節點的每一次寫操作。oplog是主節點的local數據庫中的一個固定集合。備份節點通過查詢這個集合就可以知道需要進行復制的操作。
- 慢查詢日志:MongoDB中使用系統分析器來查找耗時過長的操作。默認情況下,系統分析器處于關閉狀態,不會進行任何記錄。可以在shell中運行db.setProfilingLevel()開啟分析器。
```
db.setProfilingLevel(level,<slowms>) 0=off 1=slow 2=all
```
第一個參數是指定級別,不同的級別代表不同的意義,0表示關閉,1表示默認記錄耗時大于100毫秒的操作,2表示記錄所有操作。第二個參數則是自定義“耗時過長"標準,比如記錄所有耗時操作500ms的操作:
```
db.setProfilingLevel(1,500);
```
#### 20.3 MongoDB的啟動關閉
##### 安裝及啟動
將MongoDB的壓縮文件從官網上下載下來后解壓。
:-: 
1. 使用MongoDB的二進制文件啟動:
- 在使用二進制啟動MongoDB服務
```
/usr/bin/mongod --path=/mongodb/data
```
其中/usr/bin/mongod是mongoDB解壓文件的二進制運行程序路徑。--path指定數據庫文件路徑。
2. 通過環境變量啟動:
- 將MongoDB的二進制運行文件加入環境變量。
- 使用環境變量啟動。
```
mongod --path=/mongodb/data
```
其中mongod是加入到環境變量的MongoDB的二進制運行文件。--path指定數據庫文件路徑。
3. 將MongoDB加入服務,通過systemctl命令控制MongoDB服務的啟動。
4. MongoDB服務可以通過配置文件方式啟動,當修改了配置文件mongod.conf后:
```
mongod --config /etc/mongod.conf
```
或
```
mongod -f /etc/mongod.conf
```
##### 關閉
1. 不是后臺運行的情況下使用Ctrl+C命令在Shell界面結束MongoDB服務。
2. 運行MongoDB的客戶端,使用admin用戶,再使用shutdownServer關閉。
```
cd /usr/bin/
mongo
use admin
shutdownServer();
```
3. kill 命令停止進程。
4. 如果MongoDB服務注冊了服務,可以使用systemctl命令關閉。
```
service mongod stop; //centos7以下
```
```
systemctl stop mongod;//centos7以上
```
#### 20.4 連接MongoDB
啟動MongoDB服務后,其他端需要連接MongoDB服務進行操作。
標準 URI 連接語法:
```
mongodb://[username:password@]host1[:port1][,host2[:port2],...[,hostN[:portN]]][/[database][?options]]
```
- **mongodb://** 這是固定的格式,必須要指定。
- **username:password@** 可選項,如果設置,在連接數據庫服務器之后,驅動都會嘗試登錄這個數據庫
- **host1** 必須的指定至少一個host, host1 是這個URI唯一要填寫的。它指定了要連接服務器的地址。如果要連接復制集,請指定多個主機地址。
- **portX** 可選的指定端口,如果不填,默認為27017
- **/database** 如果指定username:password@,連接并驗證登錄指定數據庫。若不指定,默認打開 test 數據庫。
- **?options** 是連接選項。如果不使用/database,則前面需要加上/。所有連接選項都是鍵值對name=value,鍵值對之間通過&或;(分號)隔開。
標準的連接格式包含了多個選項(options):
| 選項 | 描述 |
| ------------------- | ------------------------------------------------------------ |
| replicaSet=name | 驗證replica set的名稱。 Impliesconnect=replicaSet. |
| slaveOk=true\|false | true:在connect=direct模式下,驅動會連接第一臺機器,即使這臺服務器不是主。在connect=replicaSet模式下,驅動會發送所有的寫請求到主并且把讀取操作分布在其他從服務器。false: 在 connect=direct模式下,驅動會自動找尋主服務器. 在connect=replicaSet 模式下,驅動僅僅連接主服務器,并且所有的讀寫命令都連接到主服務器。 |
| safe=true\|false | true: 在執行更新操作之后,驅動都會發送getLastError命令來確保更新成功。(還要參考 wtimeoutMS).false: 在每次更新之后,驅動不會發送getLastError來確保更新成功。 |
| w=n | 驅動添加 { w : n } 到getLastError命令. 應用于safe=true。 |
| wtimeoutMS=ms | 驅動添加 { wtimeout : ms } 到 getlasterror 命令. 應用于 safe=true. |
| fsync=true\|false | true: 驅動添加 { fsync : true } 到 getlasterror 命令.應用于 safe=true.false: 驅動不會添加到getLastError命令中。 |
| journal=true\|false | 如果設置為 true, 同步到 journal (在提交到數據庫前寫入到實體中). 應用于 safe=true |
| connectTimeoutMS=ms | 可以打開連接的時間。 |
| socketTimeoutMS=ms | 發送和接受sockets的時間。 |
例子:
```
mongodb://admin:123456@localhost/test
```
賬號admin,密碼123456,連接到localhost的test數據庫。
#### 20.5 PHP7操作MongoDB
首先安裝適合PHP7的MongoDB擴展(注意自己的路徑):
```
/usr/local/php7/bin/pecl install mongodb
```
接下來我們打開 php.ini 文件,添加 **extension=mongodb.so** 配置。
##### 連接
```
$manager = new MongoDB\Driver\Manager("mongodb://localhost:27017"); //對應標準URI鏈接語法
```
##### 插入數據
```
<?php
$bulk = new MongoDB\Driver\BulkWrite;
$document = ['_id' => new MongoDB\BSON\ObjectID, 'name' => '測試數據1'];
$_id= $bulk->insert($document);
$manager = new MongoDB\Driver\Manager("mongodb://localhost:27017");
$writeConcern = new MongoDB\Driver\WriteConcern(MongoDB\Driver\WriteConcern::MAJORITY, 1000);
$result = $manager->executeBulkWrite('collec1.test1', $bulk, $writeConcern);
?>
```
##### 讀取數據
```
<?php
$manager = new MongoDB\Driver\Manager("mongodb://localhost:27017");
// 插入數據
$bulk = new MongoDB\Driver\BulkWrite;
$bulk->insert(['x' => 1, 'name'=>'baidu', 'url' => 'http://www.baidu.com']);
$bulk->insert(['x' => 2, 'name'=>'Google', 'url' => 'http://www.google.com']);
$bulk->insert(['x' => 3, 'name'=>'taobao', 'url' => 'http://www.taobao.com']);
$manager->executeBulkWrite('collec1.test1', $bulk);
$filter = ['x' => ['$gt' => 1]];
$options = [
'projection' => ['_id' => 0],
'sort' => ['x' => -1],
];
// 查詢數據
$query = new MongoDB\Driver\Query($filter, $options);
$cursor = $manager->executeQuery('collec1.test1', $query);
foreach ($cursor as $document) {
print_r($document);
}
?>
```
輸出結果為:
```
stdClass Object
(
[x] => 3
[name] => taobao
[url] => http://www.taobao.com
)
stdClass Object
(
[x] => 2
[name] => Google
[url] => http://www.google.com
)
```
##### 更新數據
```
<?php
$bulk = new MongoDB\Driver\BulkWrite;
$bulk->update(
['x' => 2],
['$set' => ['name' => 'baidu', 'url' => 'www.baidu.com']],
['multi' => false, 'upsert' => false]
);
$manager = new MongoDB\Driver\Manager("mongodb://localhost:27017");
$writeConcern = new MongoDB\Driver\WriteConcern(MongoDB\Driver\WriteConcern::MAJORITY, 1000);
$result = $manager->executeBulkWrite('collec1.test1', $bulk, $writeConcern);
?>
```
##### 刪除數據
```
<?php
$bulk = new MongoDB\Driver\BulkWrite;
$bulk->delete(['x' => 1], ['limit' => 1]); // limit 為 1 時,刪除第一條匹配數據
$bulk->delete(['x' => 2], ['limit' => 0]); // limit 為 0 時,刪除所有匹配數據
$manager = new MongoDB\Driver\Manager("mongodb://localhost:27017");
$writeConcern = new MongoDB\Driver\WriteConcern(MongoDB\Driver\WriteConcern::MAJORITY, 1000);
$result = $manager->executeBulkWrite('collec1.test1', $bulk, $writeConcern);
?>
```
#### 20.6 命令
##### 數據庫命令
切換數據庫
```
use dbname;
```
切換時沒有數據庫會創建數據庫。
查詢顯示所有數據庫:
```
show dbs;
```
刪除當前使用數據庫:
```
db.dropDatabase();
```
從指定主機克隆數據庫:
```
db.cloneDatabase("192.168.200.1");
```
會克隆指定主機的同名數據庫到當前數據庫。
從指定主機上復制數據庫數據到某個數據庫:
```
db.copyDatabase('db1','test1',192,168,200,1);
```
將192.168.200.1的db1數據庫數據復制到本機test1數據庫中。
查看當前使用的數據庫:
```
db.getName();
```
顯示當前db狀態:
```
db.status();
```
db版本:
```
db.version();
```
查看當前db的鏈接機器地址:
```
db.getMongo();
```
查看之前的錯誤信息:
```
db.getPrevError();
```
清除錯誤信息:
```
db.resetError();
```
##### 集合命令
創建集合
```
db.createCollection("t1");
```
或創建固定集合:
```
db.createCollection("t2",{size:30,capped:true,max:100});
```
上面創建了固定集合t2,固定大小30,限制空間大小為30,最大條數為100。
- capped:設置是否為固定集合。
- size:設置使用的空間大小,沒有不限制。
- max:設置最大文檔條數。
- autoIndexId:是否使用`_id`作為索引。
size優先級高于max。
顯示當前數據庫集合:
```
show collections;
```
使用集合:
```
db.getCollection('coll1');
db.coll1; //數字集合不能使用這種方式
```
查詢集合的數據條數:
```
db.collname.count();
```
查看集合數據字節大小:
```
db.collname.dataSize();
```
查看集合索引大小:
```
db.collname.totalIndexSize();
```
為集合分配的空間大小:
```
db.collname.storageSize();
```
顯示結合總大小,包括索引、數據、分配的空間大小:
```
db.collname.totalSize();
```
顯示當前集合所在的db:
```
db.collname.getDB();
```
顯示當前集合狀態:
```
db.collname.status();
```
顯示當前db所有集合的狀態信息:
```
db.printCollectionsStatus();
```
刪除當前集合:
```
db.collname.drop();
```
重命名集合:
```
db.collname1.renameCollection('collname2');
```
##### 文檔命令
寫入文檔:
```
db.user.insert({"name":"tom"});
```
或者:
```
db.user:save({"name":"tom"});
```
save比insert多一項寫入功能。
查看文檔:
```
db.user.find();
```
更新文檔:
MongoDB使用sava()和update()來更新集合中的文檔。
save():
```
db.user.save({"_id":Object('56321315464asdz5x4caqhg354432d'),"name":"tom","age":18});
```
update():
```
db.collection.update(
查詢條件,
整個文檔或修改器,
upsert:boolean,
multi:boolean或multi文檔,
writeConcern:異常信息等級
);
```
參數說明:
參數一:查詢條件用于定位到需要修改的文檔,與find語句使用方式一樣。
參數二:文檔或修改器。參數為文檔時,傳入的文檔會替代現有文檔。參數是修改其時,會根據修改器文檔做相應改動。
參數三:upsert設置如果不存在記錄的情況是否寫入新文檔。可選參數,默認不寫入。
參數四:multi設置false只更新找到的第一條記錄,設置true更新根據條件查找到的所有記錄,默認false。
參數五:可選,拋出異常的級別。保障更新操作可靠性。
例子:
```
db.user.update(
{"name":"tom"},
{$set:{"age":20,"company":"baidu"}},
true,
{multi:true},
WriteConnern.SAFE
);
```
刪除文檔:
```
db.collection.remove(
查詢條件,
justOne:boolean,
wriconcern:異常信息等級
);
```
參數說明:
參數一:查詢條件用于定位到需要刪除的文檔,與find語句使用方式一樣。
參數二:是否只刪除一條。默認false,刪除所有匹配的。
參數三:拋出異常級別。
```
db.user.remove({"name":"tom"},1);
db.user.remove({"name":"tom"});
```
更新文檔并返回文檔:
```
db.user.findAndModify({
query:{age:{$gte:25}},
sort:{age:1},
update:{$set:{name:'a2'},$inc:{age:2}}
});
```
刪除文檔并返回文檔:
```
db.user.findAndModify({
query:{age:{$gte:25}},
sort:{age:1},
remove:true
});
```
查詢滿足條件的文檔數量:
```
db.user.count({
$or:[{age:14},{age:15}]
});
```
##### 索引命令
索引用于加速對該鍵的查詢。索引通常能夠極大的提高查詢的效率,如果沒有索引,MongoDB在讀取數據時必須掃描集合中的每個文件并選取那些符合查詢條件的記錄。
這種掃描全集合的查詢效率是非常低的,特別在處理大量的數據時,查詢可以要花費幾十秒甚至幾分鐘,這對網站的性能是非常致命的。
索引是特殊的數據結構,索引存儲在一個易于遍歷讀取的數據集合中,索引是對數據庫表中一列或多列的值進行排序的一種結構。
創建索引:
```
db.user.ensureIndex({age:1});
db.user.ensureIndex({name:1,age:1});
```
集合可以創建單索引或復合索引。1表示數據以升序排列,-1表示數據以降序排列。并且依照從左向右排序的原則。上面的第二行表示創建復合索引先按name的升序排列,再按age的降序排列。
索引參數:
| Parameter | Type | Description |
| ------------------ | ------------- | ------------------------------------------------------------ |
| background | Boolean | 建索引過程會阻塞其它數據庫操作,background可指定以后臺方式創建索引,即增加 "background" 可選參數。 "background" 默認值為**false**。 |
| unique | Boolean | 建立的索引是否唯一。指定為true創建唯一索引。默認值為**false**. |
| name | string | 索引的名稱。如果未指定,MongoDB的通過連接索引的字段名和排序順序生成一個索引名稱。 |
| dropDups | Boolean | **3.0+版本已廢棄**。在建立唯一索引時是否刪除重復記錄,指定 true 創建唯一索引。默認值為 **false**. |
| sparse | Boolean | 對文檔中不存在的字段數據不啟用索引;這個參數需要特別注意,如果設置為true的話,在索引字段中不會查詢出不包含對應字段的文檔.。默認值為 **false**. |
| expireAfterSeconds | integer | 指定一個以秒為單位的數值,完成 TTL設定,設定集合的生存時間。 |
| v | index version | 索引的版本號。默認的索引版本取決于mongod創建索引時運行的版本。 |
| weights | document | 索引權重值,數值在 1 到 99,999 之間,表示該索引相對于其他索引字段的得分權重。 |
| default_language | string | 對于文本索引,該參數決定了停用詞及詞干和詞器的規則的列表。 默認為英語 |
| language_override | string | 對于文本索引,該參數指定了包含在文檔中的字段名,語言覆蓋默認的language,默認值為 language. |
查詢集合所有索引:
```
db.user.getIndexes();
```
查看集合總索引記錄大小:
```
db.user.totalIndexSize();
```
讀取當前集合的所有index信息:
```
db.user.reIndex();
```
刪除指定索引:
```
db.user.dropIndex("Index1");
```
刪除集合所有索引:
```
db.user.dropIndexes();
```
##### 查詢命令
MongoDB使用find()來進行文檔查詢。有兩個參數:
- 參數1:查詢條件。
- 參數2:指定返回字段。_id默認返回。
```
db.user.find({'name':'tom'},{'age':1});
```
返回name為tom的文檔,并且只按升序返回age字段。
游標用于存放find執行結果并且每次只能取一條:
```
var cursor = db.user.find();
while(cursor.hasNext()){
var temp = cursor.next();
print(temp.name);
}
```
游標實現了迭代器,可以使用foreach:
```
var cursor = db.user.find();
cursor.forEach(function(temp)){
print(temp.name);
}
```
與操作:
```
db.user.find({'name':'tom','age':18});
```
或操作$or:
```
db.user.find({$or:[{'name':'tom'},{'age':18}]});
```
大于操作$gt:
```
db.user.find({age:{$gt:18}});
```
小于操作$lt:
```
db.user.find({age:{$lt:18}});
```
大于等于操作$gte:
```
db.user.find({age:{$gte:18}});
```
小于等于操作$lte:
```
db.user.find({age:{$lte:18}});
```
類型查詢$type:
```
db.user.find({'name':{$type":2});
db.user.find({'name':{$type":'string'});
```
| Type | Number | Alias | Notes |
| ---------------------- | ------ | --------------------- | ------------------ |
| Double | 1 | "double" | |
| String | 2 | "string" | |
| Object | 3 | "object" | |
| Array | 4 | "array" | |
| Binary data | 5 | "binData" | |
| Undefined | 6 | "underfined" | Deprecated |
| ObjectId | 7 | "objectId" | |
| Boolean | 8 | "bool" | |
| Date | 9 | "date" | |
| Null | 10 | "null" | |
| Regular Expression | 11 | "regex" | |
| DBPointer | 12 | "dbPointer" | Deprecated |
| JavaScript | 13 | "javascript" | |
| Symbol | 14 | "symbol" | Deprecated |
| JavaScript(with scope) | 15 | "javascriptWithScope" | |
| 32-bit integer | 16 | "int" | |
| Timestamp | 17 | "timestamp" | |
| 64-bit integer | 18 | "long" | |
| Decimal128 | 19 | "decimal" | new in version 3.4 |
| Min key | -1 | "minKey" | |
| Max key | 127 | "maxKey" | |
? 數據類型與$type參數對應表
是否存在$exists:
```
db.user.find({"age":{$exists:true}});
```
取模操作$mod:
```
db.user.find({"age":{$mod:[10,0]}});
```
不等于$ne:
```
db.user.find({"age":{$ne:18}});
```
包含$in:
```
db.user.find({"age":{$in:[18,20,21]}});
```
不包含$nin:
```
db.user.find({"age":{$nin:[18,20,21]}});
```
反匹配$not:
```
db.user.find({$not:{"age":{$in:[18,20,21]}}});
```
##### 聚合查詢
MongoDB 中聚合(aggregate)主要用于處理數據(諸如統計平均值,求和等),并返回計算后的數據結果。類似于SQL的count(*)。
語法:
```
>db.COLLECTION_NAME.aggregate(AGGREGATE_OPERATION)
```
例子:
```
{
_id: ObjectId(7df78ad8902c)
title: 'MongoDB Overview',
description: 'MongoDB is no sql database',
by_user: 'li',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 100
},
{
_id: ObjectId(7df78ad8902d)
title: 'NoSQL Overview',
description: 'No sql database is very fast',
by_user: 'li',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 10
},
{
_id: ObjectId(7df78ad8902e)
title: 'Neo4j Overview',
description: 'Neo4j is no sql database',
by_user: 'wang',
tags: ['neo4j', 'database', 'NoSQL'],
likes: 750
},
```
使用aggregate()計算結果如下:
```
> db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$sum : 1}}}])
{
"result" : [
{
"_id" : "li",
"num_tutorial" : 2
},
{
"_id" : "wang",
"num_tutorial" : 1
}
],
"ok" : 1
}
```
聚合一般和group組合使用。
一些聚合的表達式:
| 表達式 | 描述 | 實例 |
| --------- | ---------------------------------------------- | ------------------------------------------------------------ |
| $sum | 計算總和。 | db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$sum : "$likes"}}}]) |
| $avg | 計算平均值 | db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$avg : "$likes"}}}]) |
| $min | 獲取集合中所有文檔對應值得最小值。 | db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$min : "$likes"}}}]) |
| $max | 獲取集合中所有文檔對應值得最大值。 | db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$max : "$likes"}}}]) |
| $push | 在結果文檔中插入值到一個數組中。 | db.mycol.aggregate([{$group : {_id : "$by_user", url : {$push: "$url"}}}]) |
| $addToSet | 在結果文檔中插入值到一個數組中,但不創建副本。 | db.mycol.aggregate([{$group : {_id : "$by_user", url : {$addToSet : "$url"}}}]) |
| $first | 根據資源文檔的排序獲取第一個文檔數據。 | db.mycol.aggregate([{$group : {_id : "$by_user", first_url : {$first : "$url"}}}]) |
| $last | 根據資源文檔的排序獲取最后一個文檔數據 | db.mycol.aggregate([{$group : {_id : "$by_user", last_url : {$last : "$url"}}}]) |
##### 管道
管道在Unix和Linux中一般用于將當前命令的輸出結果作為下一個命令的參數。
MongoDB的聚合管道將MongoDB文檔在一個管道處理完畢后將結果傳遞給下一個管道處理。管道操作是可以重復的。
表達式:處理輸入文檔并輸出。表達式是無狀態的,只能用于計算當前聚合管道的文檔,不能處理其它的文檔。
這里我們介紹一下聚合框架中常用的幾個操作:
- $project:修改輸入文檔的結構。可以用來重命名、增加或刪除域,也可以用于創建計算結果以及嵌套文檔。
- $match:用于過濾數據,只輸出符合條件的文檔。$match使用MongoDB的標準查詢操作。
- $limit:用來限制MongoDB聚合管道返回的文檔數。
- $skip:在聚合管道中跳過指定數量的文檔,并返回余下的文檔。
- $unwind:將文檔中的某一個數組類型字段拆分成多條,每條包含數組中的一個值。
- $group:將集合中的文檔分組,可用于統計結果。
- $sort:將輸入文檔排序后輸出。
- $geoNear:輸出接近某一地理位置的有序文檔。
1、$project實例
```
db.article.aggregate(
{ $project : {
title : 1 ,
author : 1 ,
}}
);
```
這樣的話結果中就只還有_id,tilte和author三個字段了,默認情況下_id字段是被包含的,如果要想不包含_id話可以這樣:
```
db.article.aggregate(
{ $project : {
_id : 0 ,
title : 1 ,
author : 1
}});
```
2.$match實例
```
db.articles.aggregate( [
{ $match : { score : { $gt : 70, $lte : 90 } } },
{ $group: { _id: null, count: { $sum: 1 } } }
] );
```
$match用于獲取分數大于70小于或等于90記錄,然后將符合條件的記錄送到下一階段$group管道操作符進行處理。
3.$skip實例
```
db.article.aggregate(
{ $skip : 5 });
```
經過$skip管道操作符處理后,前五個文檔被"過濾"掉。
#### 20.7 MongoDB 關系
MongoDB 中的關系可以是:
- 1:1 (1對1)
- 1: N (1對多)
- N: 1 (多對1)
- N: N (多對多)
##### 嵌入式關系
使用嵌入式方法,我們可以把用戶地址嵌入到用戶的文檔中:
```
{
"_id":ObjectId("52ffc33cd85242f436000001"),
"contact": "987654321",
"dob": "01-01-1991",
"name": "Tom Benzamin",
"address": [
{
"building": "22 A, Indiana Apt",
"pincode": 123456,
"city": "Los Angeles",
"state": "California"
},
{
"building": "170 A, Acropolis Apt",
"pincode": 456789,
"city": "Chicago",
"state": "Illinois"
}]
}
```
嵌入式關系的缺點是當嵌入的文檔不斷增加,數據量變大會影響性能。
##### 引用式關系
MongoDB 引用有兩種:
- 手動引用(Manual References)
- DBRefs
##### 手動引用
引用式關系是設計數據庫時經常用到的方法,這種方法把用戶數據文檔和用戶地址數據文檔分開,通過引用文檔的 **id** 字段來建立關系。
```
{
"_id":ObjectId("52ffc33cd85242f436000001"),
"contact": "987654321",
"dob": "01-01-1991",
"name": "Tom Benzamin",
"address_ids": [
ObjectId("52ffc4a5d85242602e000000"),
ObjectId("52ffc4a5d85242602e000001")
]
}
```
我們可以讀取這些用戶地址的對象id(ObjectId)來獲取用戶的詳細地址信息。
這種方法需要兩次查詢,第一次查詢用戶地址的對象id(ObjectId),第二次通過查詢的id獲取用戶的詳細地址信息。這樣對性能的影響不會太大,這種是`手動引用`。
```
>var result = db.users.findOne({"name":"Tom Benzamin"},{"address_ids":1})
>var addresses = db.address.find({"_id":{"$in":result["address_ids"]}})
```
##### DBRefs引用
DBRef的形式:
```
{ $ref : , $id : , $db : }
```
三個字段表示的意義為:
- $ref:集合名稱
- $id:引用的id
- $db:數據庫名稱,可選參數
以下實例中用戶數據文檔使用了 DBRef, 字段 address:
```
{
"_id":ObjectId("53402597d852426020000002"),
"address": {
"$ref": "address_home",
"$id": ObjectId("534009e4d852427820000002"),
"$db": "runoob"},
"contact": "987654321",
"dob": "01-01-1991",
"name": "Tom Benzamin"
}
```
**address** DBRef 字段指定了引用的地址文檔是在 runoob 數據庫下的 address_home 集合,id 為 534009e4d852427820000002。
以下代碼中,我們通過指定 $ref 參數(address_home 集合)來查找集合中指定id的用戶地址信息:
```
>var user = db.users.findOne({"name":"Tom Benzamin"})
>var dbRef = user.address
>db[dbRef.$ref].findOne({"_id":(dbRef.$id)})
```
實例返回了 address_home 集合中的地址數據:
```
{
"_id" : ObjectId("534009e4d852427820000002"),
"building" : "22 A, Indiana Apt",
"pincode" : 123456,
"city" : "Los Angeles",
"state" : "California"
}
```
#### 20.8 索引
##### MongoDB 覆蓋索引查詢
官方的MongoDB的文檔中說明,覆蓋查詢是以下的查詢:
- 所有的查詢字段是索引的一部分。
- 所有的查詢返回字段在同一個索引中。
(與MySQL的索引覆蓋基本一致:如果一個索引包含(或覆蓋)所有需要查詢的字段的值,稱為‘覆蓋索引’。即只需掃描索引而無須回表。)
由于所有出現在查詢中的字段是索引的一部分, MongoDB 無需在整個數據文檔中檢索匹配查詢條件和返回使用相同索引的查詢結果。
因為索引存在于RAM中,從索引中獲取數據比通過掃描文檔讀取數據要快得多。
##### 使用覆蓋索引查詢
```
{
"_id": ObjectId("53402597d852426020000002"),
"contact": "987654321",
"dob": "01-01-1991",
"gender": "M",
"name": "Tom Benzamin",
"user_name": "tombenzamin"
}
```
我們在 users 集合中創建聯合索引,字段為 gender 和 user_name :
```
>db.users.ensureIndex({gender:1,user_name:1})
```
現在,該索引會覆蓋以下查詢:
```
>db.users.find({gender:"M"},{user_name:1,_id:0})
```
##### 數組字段索引和子文檔索引
例子(集合users):
```
{
"address": {
"city": "Los Angeles",
"state": "California",
"pincode": "123"
},
"tags": [
"music",
"cricket",
"blogs"
],
"name": "Tom Benzamin"
}
```
以上文檔包含了 address 子文檔和 tags 數組。
##### 數組字段索引
對集合中的數組 tags 建立索引。
使用以下命令創建數組索引:
```
>db.users.ensureIndex({"tags":1})
```
創建索引后可以這樣檢索集合的 tags 字段:
```
>db.users.find({tags:"cricket"})
```
##### 子文檔索引
為子文檔創建索引,:
```
>db.users.ensureIndex({"address.city":1,"address.state":1,"address.pincode":1})
```
創建索引后可以使用子文檔的字段來檢索數據:
```
>db.users.find({"address.city":"Los Angeles"})
```
查詢表達不一定遵循指定的索引的順序,mongodb 會自動優化。所以上面創建的索引將支持以下查詢:
```
>db.users.find({"address.state":"California","address.city":"Los Angeles"})
```
同樣支持以下查詢:
```
>db.users.find({"address.city":"Los Angeles","address.state":"California","address.pincode":"123"})
```
##### MongoDB 索引限制
##### 額外開銷
每個索引占據一定的存儲空間,在進行插入,更新和刪除操作時MongoDB會維護索引對索引進行操作。所以對集合進行讀取操作建議不使用索引。
##### 內存(RAM)使用
由于索引是存儲在內存(RAM)中。如果索引的大小大于內存的限制,MongoDB會刪除一些索引,這將導致性能下降。
##### 查詢限制
索引不能被以下的查詢使用:
- 正則表達式及非操作符,如 $nin, $not, 等。
- 算術運算符,如 $mod, 等。
- $where 子句
可以用explain來查看。使用檢測語句explain是個好習慣。
##### 索引鍵限制
從2.6版本開始,如果現有的索引字段的值超過索引鍵的限制,MongoDB中不會創建索引。
##### 插入文檔超過索引鍵限制
如果文檔的索引字段值超過了索引鍵的限制,MongoDB不會將任何文檔轉換成索引的集合。
##### 最大范圍
- 集合中索引不能超過64個
- 索引名的長度不能超過128個字符
- 一個復合索引最多可以有31個字段
#### 20.9 MongoDB 查詢分析
查詢分析可以確保我們所建立的索引是否有效,是性能分析工具。
MongoDB 查詢分析常用函數有:explain() 和 hint()。
##### 使用 explain()
explain 操作提供了查詢信息,使用索引及查詢統計等。有利于我們對索引的優化。
接下來我們在 users 集合中創建 gender 和 user_name 的索引:
```
>db.users.ensureIndex({gender:1,user_name:1})
```
現在在查詢語句中使用 explain :
```
>db.users.find({gender:"M"},{user_name:1,_id:0}).explain()
```
以上的 explain() 查詢返回如下結果:
```
{
"cursor" : "BtreeCursor gender_1_user_name_1",
"isMultiKey" : false,
"n" : 1,
"nscannedObjects" : 0,
"nscanned" : 1,
"nscannedObjectsAllPlans" : 0,
"nscannedAllPlans" : 1,
"scanAndOrder" : false,
"indexOnly" : true,
"nYields" : 0,
"nChunkSkips" : 0,
"millis" : 0,
"indexBounds" : {
"gender" : [
[
"M",
"M"
]
],
"user_name" : [
[
{
"$minElement" : 1
},
{
"$maxElement" : 1
}
]
]
}
}
```
現在,我們看看這個結果集的字段:
- **indexOnly**: 字段為 true ,表示我們使用了索引。
- **cursor**:因為這個查詢使用了索引,MongoDB 中索引存儲在B樹結構中,所以這是也使用了 BtreeCursor 類型的游標。如果沒有使用索引,游標的類型是 BasicCursor。這個鍵還會給出你所使用的索引的名稱,你通過這個名稱可以查看當前數據庫下的system.indexes集合(系統自動創建,由于存儲索引信息,這個稍微會提到)來得到索引的詳細信息。
- **n**:當前查詢返回的文檔數量。
- **nscanned/nscannedObjects**:表明當前這次查詢一共掃描了集合中多少個文檔,我們的目的是,讓這個數值和返回文檔的數量越接近越好。
- **millis**:當前查詢所需時間,毫秒數。
- **indexBounds**:當前查詢具體使用的索引。
#### 使用 hint()
雖然MongoDB查詢優化器一般工作的很不錯,但是也可以使用 hint 來強制 MongoDB 使用一個指定的索引。
這種方法某些情形下會提升性能。 一個有索引的 collection 并且執行一個多字段的查詢(一些字段已經索引了)。
如下查詢實例指定了使用 gender 和 user_name 索引字段來查詢:
```
>db.users.find({gender:"M"},{user_name:1,_id:0}).hint({gender:1,user_name:1})
```
可以使用 explain() 函數來分析以上查詢:
```
>db.users.find({gender:"M"},{user_name:1,_id:0}).hint({gender:1,user_name:1}).explain()
```
#### 20.10 MongoDB 復制(副本集)
MongoDB復制是將數據同步在多個服務器的過程。主要作用:
- 主從復制。
- 數據冗余、數據安全。
- 硬件故障和服務中斷時的數據恢復。
:-: 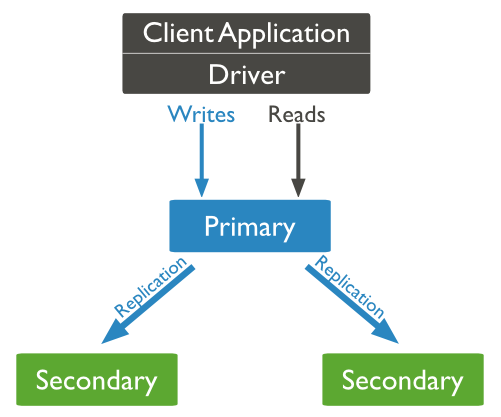
? MongoDB主從復制架構圖
MongoDB的主從復制至少是一主一從,可以一主多從。當客戶端對MongoDB服務器主節點進行寫操作oplog。從服務器節點會定時輪詢主服務器節點,將寫操作oplog同步,保證主節點與從節點的數據一致性。
#### 20.11 MongoDB其他相關
對MongoDB分片、正則表達式、監控、GridFS,Javascript使用MongoDB等相關知識有興趣的同學請自行查閱資料。