#### 第22章:
#### 系統架構
PHP集成環境也能跑程序,為什么要做系統架構?都是服務端服務,為什么說根據不同的場景系統架構不一樣?
開發一個系統,通常會經過需求分析、系統分析、設計、建模、測試等過程。經過這些過程將程序上線,有時又會出現各種情況,比如由計算機硬件指標不夠、計算機系統移植性不夠、帶寬不足、數據庫設計不足、等導致的軟件崩潰、客戶請求超時、CPU拉滿、I/O緩慢等等情況。于是我們重新設計系統架構,重寫應用程序代碼,重構系統,嘗試找到合適的架構方案使系統能夠在低成本的情況下做到高可用、高性能、數據安全。所以一個優秀的系統架構一定是精準合適而且性能良好的。
這里我們引出系統架構目的是為了解決具體問題并具備邏輯性。
#### 22.1 系統架構難點
對于新手來講,優秀的系統架構設計基本上是做不出來的。設計系統架構需要完善的計算機知識體系以及各種軟硬件使用、運維經驗,以及對業務深入理解的程度并擁有依據業務選擇選擇合適的技術棧的能力。所以設計系統架構是需要一定要求的。
系統架構設計有技術難點和業務難點。
對于大型系統來說,有以下高頻場景:
- 高并發場景:需要在短時間里快速處理密集型大量請求,保證高性能。
- 高可用場景:需要在極端條件下,系統可用。
- 高擴展場景:流量及系統變化,以最少的代價支撐業務擴展。
- 分布式一致性場景:需要在分布式保證數據的正確性、一致性,比如在數據庫的分布式場景中有些會采取`補償`。
......
系統架構的技術難點在于如何在代價合適的情況下關聯硬件技術、軟件技術使系統具備高可用性、高性能、可擴展、數據安全、高容災性等特性。
系統架構的業務難點在于如何熟悉理解復雜的業務調用鏈路并創建合適的具備高可用性、高性能、可擴展、數據安全、高容災性等特性的控制流代碼。
#### 22.2 設計系統架構需要考慮全局
單機硬件指標從來不是一個系統的性能指標。就像是一個籃球隊有一個兩米高籃球水平一般的男生(硬件滿配,軟件能力一般),四個一米六高籃球水平一般的男生(硬件一般、軟件一般),打區域比賽時它們輸給了另一個由五個一米七籃球水平很高的男生組成的籃球隊。試想以下,某個高并發場景調用鏈有五個節點,第一個節點擁有強大的處理能力所以吞吐量高,它將它二十毫秒處理完的大量信息發送給第二個節點處理,第二個節點從接收到信息那一刻由于運算能力不足就開始阻塞,然后花了2秒處理完后將更大量信息交由第三個節點,第三個節點又開始阻塞,直到信息到第四個節點再傳到最后第五個節點完成時已經過了很長一段時間。
設計一個系統應當從整體能力考慮,并且應該注意所有指標的最低能力。對于一個大部分硬件、軟件、網絡、容災、高可用等指標都良好的系統,調用鏈出現一個低于整體平均能力過多的節點將是災難性的。
:-: 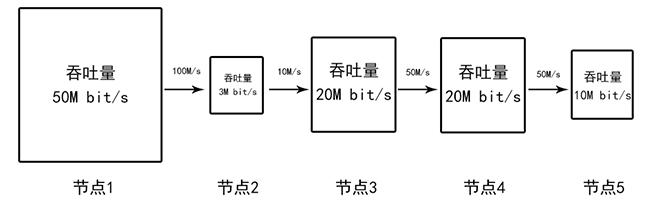
? 由某一最低能力節點導致整個系統性能變差的調用鏈
#### 22.3 系統設計需要考慮使用場景和需求
對于一個需要即時響應的系統,整個系統架構的硬件、軟件、網絡配置都應該在合適的代價下資源達標并創建良好的控制流代碼使程序盡力使用這些資源良好運行。
對于不需要即使響應的系統或者業務,可以視情況不增加代價或者降低代價。比如白天負責收集,晚上可以花一整晚出結果的系統,再比如一個請求到來可以在5分鐘內(長時間)響應的系統。
#### 22.4 幾種技術架構案例
在以PHP語言為主的后端服務器架構里,高并發和高負載的約束條件通常是:
1. 硬件
2. 部署
3. 操作系統
4. Web 服務器
5. PHP
6. MySQL
##### 22.4.1 最簡單架構
:-: 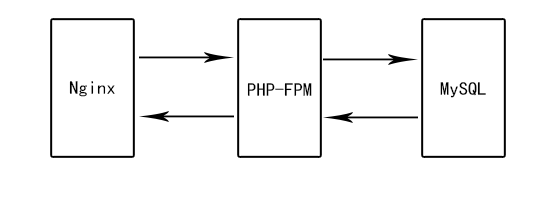
這是以PHP為后端語言系統的最基礎架構。對于并發要求不高的網站系統或者公司管理系統,在這樣架構的基礎上,做好MySQL的數據安全,選擇適當的網絡帶寬和硬件配置,就可以應對日常系統使用。適當的情況下可以分離WebServer、后端程序、數據庫程序,比如可以使用代價小的云存儲MySQL,其穩定高效。對于WebServer,如果是靜態頁面較多使用資源少的情況推薦使用Nginx,如果追求WebServer穩定的情況下可以使用Apache。
##### 22.4.2 最簡單架構的延申架構
- 注重負載均衡的架構
:-: 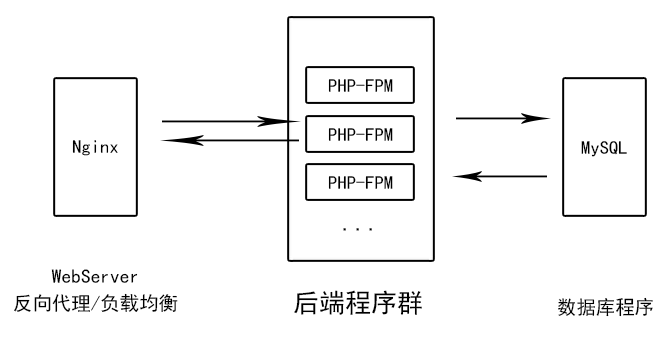
如果WebServer傳到后端程序的數據量較大,而后端程序處理能力不夠導致數據排隊甚至丟包、超時,后端程序和數據庫交互沒有問題的情況下,可以增加后端程序節點做負載均衡。這樣可以按需分配后端程序群算例,便于彈性伸縮。
- 注重負載均衡和數據庫數據響應的架構
:-: 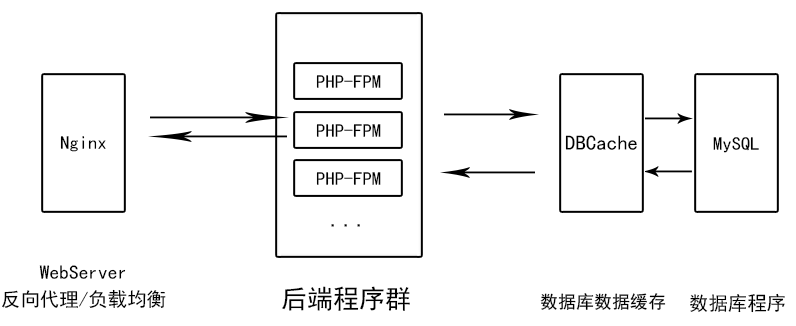
如果需要后端程序與數據庫交互速度更快,可以考慮將長期數據進行數據緩存,增加一層緩存并創建良好的緩存控制流代碼防止緩存穿透、擊穿。
- 注重負載均衡、數據庫響應、NoSQL數據庫安全、緩存數據能力的架構
:-: 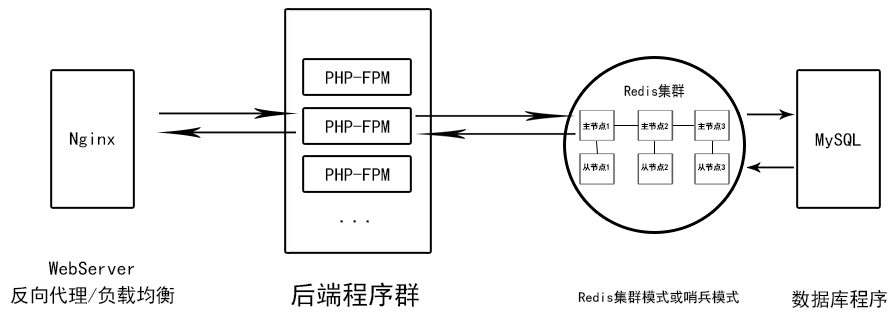
如果需要讓數據庫之前有一層`緩存--數據庫`層加快響應且做內存數據庫,并希望緩存層的容災能力、并發能力強,數據安全,可以在MySQL之前將DBCache層用Redis集群或者Redis哨兵替代。
Redis哨兵模式的優勢:主從節點是全量數據庫,所有的鍵值全部都會保存在主從節點,做主從復制能力強。
Redis哨兵模式的劣勢:在大量讀/寫請求事件到來時并發能力稍弱。由于全量化存儲浪費內存導致容量有限。
Redis集群的優勢:分布式每個節點分片存儲鍵值數據,節點之間互相監控并轉發請求事件。解決了Redis單機容量問題。
Reids集群的劣勢:數據量小的情況下部署復雜。集群模式沒有讀寫分離,客戶端請求任何一臺集群里的節點會被計算鍵是否在本節點的槽中,如果在直接執行命令,如果沒有轉發給對應槽節點執行命令。Redis集群一共有16384個槽,可以任意分配給各節點。
特別說明:不是Redis層與MySQL層交互,它們之間沒有對應的交互API,上圖Redis與MySQL之間的箭頭是抽象的邏輯交互。實際上是控制代碼由后端程序與Redis交互,后端程序與MySQL交互。只是通常控制后端程序先查詢Redis緩存,沒有數據的情況下再控制后端程序查詢MySQL,并且將MySQL的數據放入Redis緩存以便下次快速查詢。當然,也可以根據需要直接控制后端程序使用Redis作為NoSQL。
- 注重負載均衡、數據庫響應、NoSQL數據庫安全、緩存數據能力、數據庫能力、數據庫安全的架構
:-: 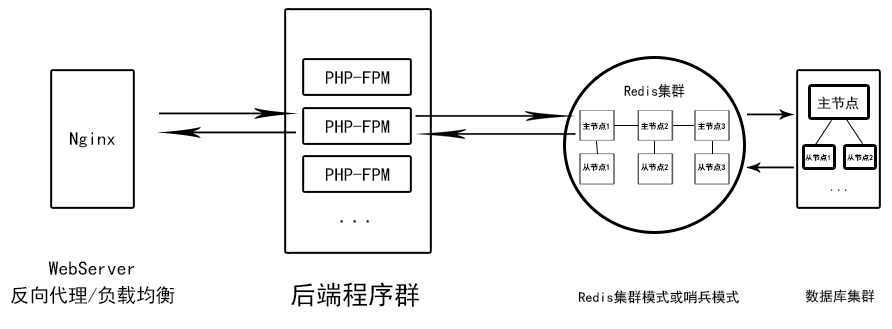
如果需要再讓數據庫能力提高,可以部署MySQL集群。
MySQL集群的優勢:數據安全,容災能力強,讀寫分離帶來的效率。后端程序可以控制MySQL集群讓某從節點某庫的只負責某功能,增加了MySQL查詢的伸縮性。
#### 不同業務面對的架構
- 即時響應的服務分離架構
:-: 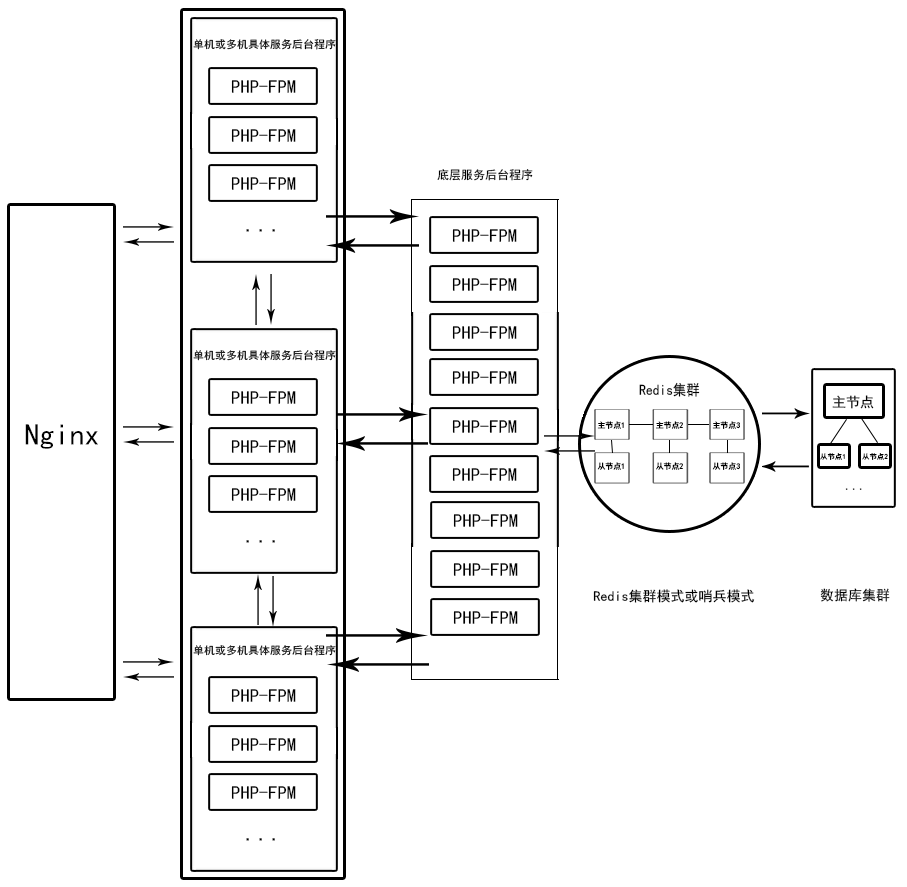
如果需要將服務獨立出來單獨處理,可以使用這樣的架構設計,可以看作是服務分離架構(微服務架構)。適當的情況可以增減某項服務部署的主機數量,再利用Nginx Review指向某項具體服務。多機服務的情況下需要注意Session共享問題,可以使用Redis等再做一層Session服務器。
- 非即時響應的服務分離架構
:-: 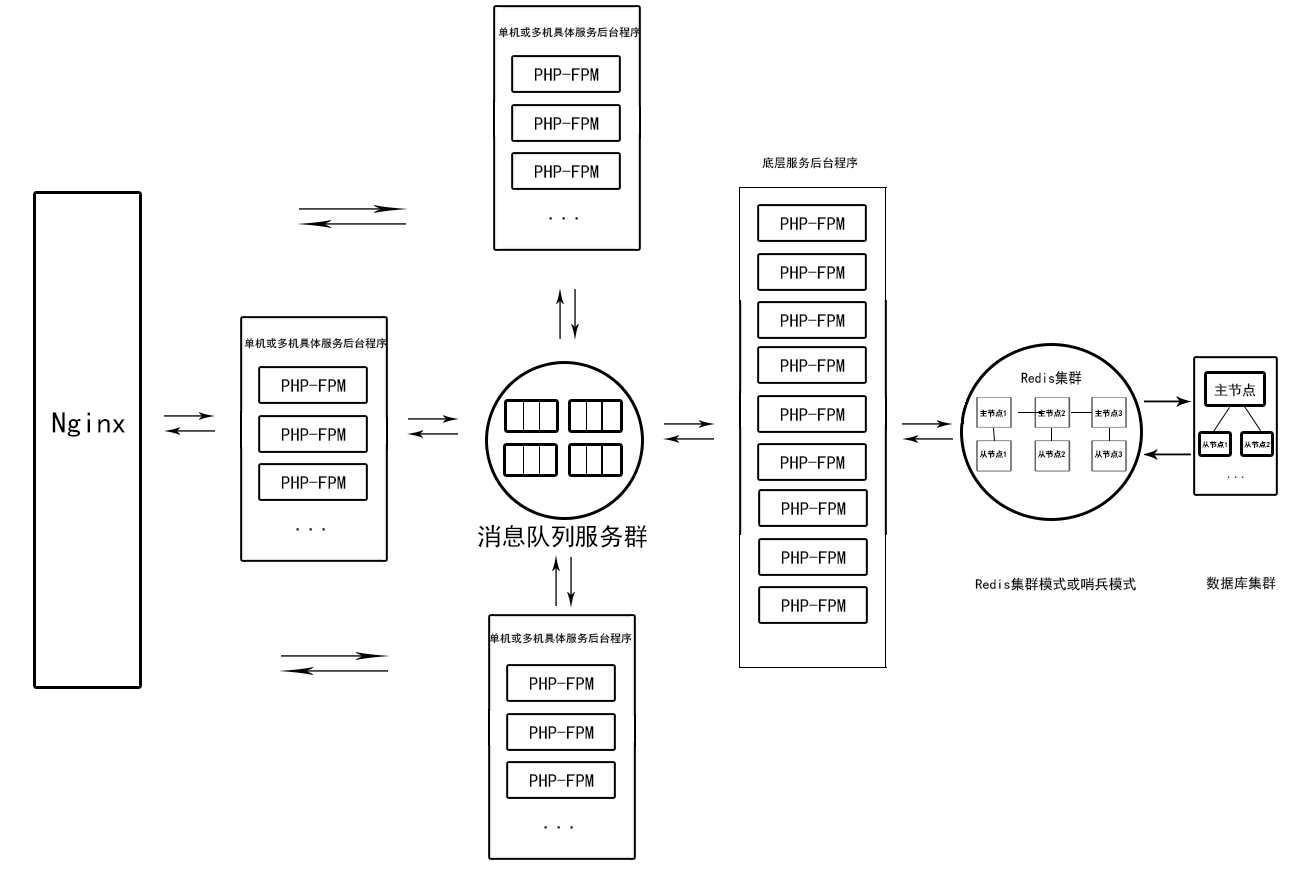
筆者曾經在某一家非即使響應的業務分離的技術架構為主的公司工作,并且對此架構印象比較深。這個系統解決餐飲行業的一系列問題,比如點單,數據統計等。其中在中午的時候點單量特別大,但是打印訂單并不需要馬上響應,20秒內就可以,如果同一時刻訂單量小的情況馬上打印訂單也是可以的。還有比如盤點業績的時候可以打印統計報表、營業報表等信息,也不需要馬上響應,20秒左右通過打印機打印出來就可以。值得深思的是,對于這套系統,接收的總的流量很大,但是公司所花的代價卻很小。這是為什么呢?原因是在分離了服務,加強了平時壓力大的服務集群,并且所有服務之間的調用全部使用策略合適的消息訂閱的推送模式。服務之間是生產者和消費者的關系,服務與基礎服務之間也是生產者和消費者的關系。這樣避免了某一個服務鏈路集中吞吐造成堵塞,而且可以集中強化高吞吐的鏈路節點(包括消息隊列服務器節點),甚至分離消息隊列服務器獨立于某一項服務。
##### 業務分離架構的優勢
業務分離的架構的優勢:具體服務只負責具體的業務,整個系統解耦,如果一個服務崩潰的情況其他服務不會崩潰;增強了單獨業務處理模塊的能力以及伸縮性;可以使用多語言生態,也就是說具體服務模塊可以使用PHP、Java、C#、Golang等。
業務分離的架構的劣勢:調用鏈復雜,在調用路徑中一般需要一層一層帶上許多信息,并且由于調用鏈復雜的情況下會帶來調試復雜和增加創建良好控制流代碼的難度。數據庫實現數據一致性難度增加,由于服務分離后多個服務互相調用并且都會使用到數據庫帶來的數據一致性問題、事務問題,常常需要一個繁雜的過程去保證,比如補償行為。
現在許多公司在使用微服務方向的架構,包括騰訊、阿里巴巴、美團等。
##### 使用消息隊列中間件的優勢
消息隊列帶來的好處主要是解耦、異步、削峰。
解耦:服務獨立,運行時關聯性可以解開。
異步:不用等待就可以處理其他控制流。
削峰:當大量請求到來時加入消息隊列,后端服務拉取或者得到消息推送并且一個個處理,數據庫I/O也在能夠承受的范圍,不會造成服務器性能降低甚至掛掉。
#### 其他架構
- Swoole運行模式的架構
:-: 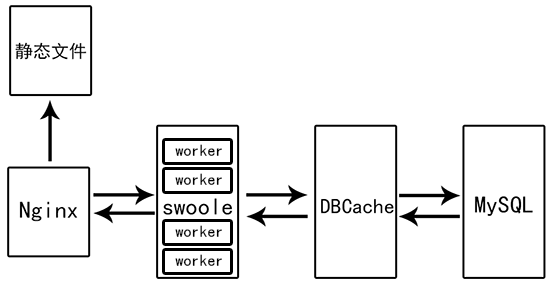
Swoole給PHP帶來一定的變革,使PHP工作進程有常駐內存的能力,更小資源消耗的協程,更豐富的socket編程方式。Swoole運行模式的架構用Nginx處理靜態文件,因為Nginx對靜態文件處理能力強大,如果是動態請求交予Swoole處理。可以適當的在Swoole層、DBCache層、MySQL層進行擴展。
當Nginx沒有找到靜態文件的情況下轉發給Swoole服務配置:
```
server{
listen:80;
server_name www.swoole1.com;
root /data/wwwroot/swoole;
location / {
if(!-e $request_filename){
proxy_pass http://127.0.0.1:9501 //Swoole服務
}
}
```
Swoole的優勢:
1. 擁有多個worker進程,由于worker進程是非阻塞的協程方式運行,所以一個worker進程能應對遠大于PHP-FPM可以應對請求數量的高并發場景。
2. 常駐內存保持運行的能力帶來的是不需要對每個請求進行初始化,減輕了初始化時創建對象的性能損耗。
3. 可以做TCP、UDP服務器。
Swoole的劣勢:
1. 編碼難度稍大。
2. 部分情況需要自行控制內存創建回收,防止內存溢出泄露。
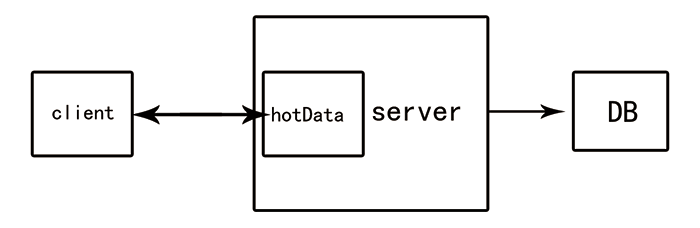
### 22.5 數據冷熱
數據冷熱處理是系統架構中的一環,是極其重要的。在高并發的場景中,數據冷熱可以使系統擁有強大的性能和篩選處理的能力。簡單來說就是:只處理冷數據,熱數據直接響應。數據冷熱處理就是我們期望將熱數據存儲在內存中,而將冷數據逐出到廉價的存儲設備中,例如SSD、硬盤。
:-: 
#### 22.5.1 為什么做數據冷熱
在生產環境中,隨著數據、訪問量增加,對服務器/數據庫I/O性能是一種考驗。在大多數情況下,常用數據庫的數據存儲在服務系統內存中,例如MySQL里InnoDB引擎的數據存儲在InnoDB_buffer_pool。當需要獲得數據時,在InnoDB_buffer_pool的數據會快速響應。但是,InnoDB_buffer_pool不是越大越好的,要考慮其整體能力,例如其數據大小、索引大小、查詢獲取成本、寫入成本等。在很多情況下,MySQL的DML操作會造成MySQL性能下降,從而使得整個系統處理能力下降。在InnoDB_buffer_pool過大的情況下,查詢能力也會下降。這時候,如果能區分冷熱數據,將熱數據查詢直接返回響應,就避免了對數據庫的查詢操作,為其他操作騰出了處理空間。
##### 所有需要DML操作通過數據庫的缺點:
- 訪問量大時的DML會造成系統性能下降。
- 數據Buffer不能無限大且太大會造成DML操作性能下降。
- 隨時隨地的讀線程將磁盤的數據讀入Buffer,寫線程將臟數據寫入磁盤會造成數據庫系統性能下降。
- 每次數據庫I/O需要有連接、數據交換、釋放的過程,占用服務系統和數據庫系統資源導致性能下降。
- .......
但是,數據應該落地數據庫。也就是說,新數據、舊數據、修改的數據必須進入數據庫系統,應該數據庫做數據持久化基礎。
##### 使用數據冷熱處理的優點
- 讀取熱數據不再需要再由系統服務和數據庫服務間建立I/O。
- 快速讀取,訪問速度快。
- 服務系統、數據庫系統節省資源保留能力,實現了部分高性能。
- ......
##### 使用數據冷熱的缺點
- 不能出錯,否則后果嚴重。
- 難于維護。
#### 22.5.2 業務場景中的數據冷熱
常見冷庫:關系型數據庫,數據保存在磁盤。
常見熱庫:Key-Value型數據庫,數據保存在內存,并有數據持久化策略。
常見的作熱庫的軟件在其內部都會設置逐出冷數據的策略、算法。對于它們來說何時逐出冷數據,一般看內存使用率是否超過設置的閾值,超過后則觸發冷數據的逐出流程。例如Redis,有不同的策略清理其多余的數據。不過在某些策略中,會過多消耗CPU性能,比如給每一個熱數據添加一個過期時間,過期自動清理。識別冷數據常見的方法是LRU,跟蹤每個tuple或page的訪問并記錄訪問頻率,逐出時可以選擇訪問頻率低于閾值的tuple或page進行逐出,也可以對訪問頻率做個排序,優先逐出訪問頻率最低的tuple或page。該方法的優點是對訪問頻率有個定量的分析,可以優先逐出訪問頻率最低的tuple或page,缺點是對每個tuple或page需要額外的內存開銷來記錄訪問頻率信息,內存占用較多,而且訪問頻率的記錄是在訪問的關鍵路徑上,會造成rt的增加。
一般PHP、Java等語言開發的業務場景中不需要去做LRU和內存操作。所以可以探索其他方式。比如大多數可以作為熱庫的軟件會對各種高級語言開放API。所以高級語言可以通過API,實現對熱庫數據控制。
最常見的方法就是,訪問量大的數據寫入冷庫成功時,一并寫入熱庫;如果寫入冷庫失敗,立刻回滾數據,清空熱庫數據。
簡單實例:當對訪問量大的User表寫入。(Redis熱庫、MySQL作冷庫)
```
<?php
......
$redis = $app->redis;
......
$transaction = self::$db->beginTransaction();
try {
$user = new \api\models\User();
$user->name = '張三';
$user->name = '13070000001';
$result = $user->save();
$transaction->commit();
if($result == true){
$redis->set('hot_user_'.$user->id,'time_' . time() . '_' . serialize($user));
}
} catch (\Exception $exception) {
$transaction->rollBack();
}
?>
```
注意:在大多情況下,如果寫入冷庫失敗時候需要刪除熱庫數據($redis->del)。
簡單實例:當對訪問量大的User表查詢。(Redis熱庫、MySQL作冷庫)
```
<?php
......
$redis = $app->redis;
......
$userId = 10001;
try {
if ($redis->exists('user_' . $userId)) {
$user = unserialize(substr($redis->get('user_' . $userId), 16));
} else {
$user = User::findOne(10001);
if ($user) {
$redis->set('hot_user_' . $user->id, 'time_' . time() . '_' . serialize($user));
echo '讀取時設置熱數據成功';
}
}
......
} catch (\Exception $exception) {
echo '操作錯誤';
}
?>
```
此時,如果可以命中熱庫數據,將直接讀取熱庫數據。如果不能命中熱庫數據,將對冷庫進行查詢操作,并將冷庫數據放入熱庫便于下次熱庫查詢。
簡單實例:設置定時任務清理熱庫冷數據。
```
<?php
var_dump('開始清理熱庫數據');
$redis = $app->redis;
$hotKeys = $redis->keys("hot_*");
if(empty($hotKeys)){
var_dump('沒有需要清理的數據');
die();
}
$num = 0;
$keys = [];
foreach ($hotKeys as $item => $row) {
$keys[] = $row;
if (count($keys) >= 1000) {
$hotDatas = $redis->mget(...$keys);
$arr = [];
foreach ($hotDatas as $key => $value) {
$time = substr($value, 5, 10);
if (($time + 10080) < time()) {
$arr[] = $hotKeys[$key + $num];
}
}
if (!empty($arr)) {
$redis->del(...$arr);
}
$num += 1000;
$keys = [];
}
if (end($hotKeys) == $row) {
$hotDatas = $redis->mget(...$keys);
$arr = [];
foreach ($hotDatas as $key => $value) {
$time = substr($value, 5, 10);
if (($time + 10080) < time()) {
$arr[] = $hotKeys[$key + $num];
}
}
if (!empty($arr)) {
$redis->del(...$arr);
}
}
}
var_dump('結束清理熱庫數據');
?>
```
可以設置定時任務在指定時間清理熱庫中過期的冷數據,逐出熱庫中的過期數據,保持內存的清潔。在很多情況下,可以為DML操作量大的表設置熱庫數據減輕冷庫的負載。也可以創建熱庫字典。
定時任務:回顧12章Linux。
簡單查詢字典實例:
```
class HotData
{
//熱庫字典
public static $dictionary = [
self::HOT_B => 'hot_a_',
self::HOT_B => 'hot_b_',
];
const HOT_A = 0;
const HOT_B = 1;
/**
* 熱數據查詢方法
* @param $hotStr
* @param $param
* @param bool $isCache
* @return mixed
*/
public static function getHotCache($hotStr, $isCache = false, $param = '')
{
$redis = \App->redis;
if (empty($param)) {
if ($redis->exists($hotStr)) {
$data = unserialize(substr($redis->get($hotStr), 16));
if ($isCache && !empty($data)) {
self::setHotCache($hotStr, $data);
}
} else {
$data = '';
}
} else {
$heapHotStr = $hotStr . $param;
if ($redis->exists($heapHotStr)) {
$data = unserialize(substr($redis->get($heapHotStr), 16));
} else {
switch ($hotStr) {
//------user熱庫數據
case self::$dictionary[self::A]:
$data = A::findOne($param);
break;
case self::$dictionary[self::B]:
$data = B::findOne(['tel' => $param]);
break;
}
}
if ($isCache && !empty($data)) {
self::setHotCache($heapHotStr, $data);
}
}
return $data ?? '';
}
/**
* 熱點數據緩存固定格式
* @param $hotStr
* @param $data
*/
public static function setHotCache($hotStr, $data)
{
$redis = \App->redis;
$redis->set($hotStr, 'time_' . time() . '_' . serialize($data));
}
/**
* 刪除熱點數據熱庫緩存
* @param $hotStr
* @param $data
*/
public static function delHotCache($hotStr)
{
$redis = \App->redis;
$redis->del($hotStr);
}
}
```
有興趣的朋友自行研究。
#### 總結
架構要按需設計。選擇合適的硬件軟件技術,以合適的代價得到高可用、高性能的系統。硬件軟件不是固定的,架構設計的思路也不是固定的。還有許多軟件技術可以作為架構設計探索的方向,比如Squid、kafka、hadoop、Apache、Dooker、Memcached、zookeeper、Dapper、Zipkin等。